基本内容
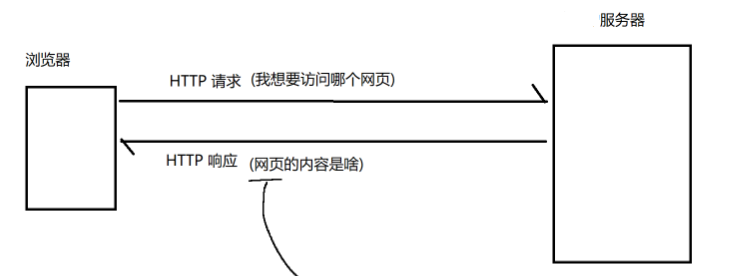
网站 = 后端(HTTP服务器)+ 前端(浏览器),而后端和前端都需要遵循HTTP协议
HTTP属于超文本传输协议,存在于应用层
文本:一般能在utf8或者gbk上找到的合法字符串
超文本:不仅仅是字符串,还可以携带一些图片或者其他特殊格式
富文本:word
当前的HTTP协议版本:HTTP3.0,基于UDP实现了一系列复杂的机制,可以确保可靠性也不怕大数据包
网页:通过HTML(一种编程语言)来构建的,HTML描述网页里面有什么,而C和Java这类语言表达的是逻辑,描述你要做什么
HTTP协议的交互过程:典型的一问一答
HTTP报文协议格式
抓包工具:本质上是一个代理程序,能够获取网络上传输的数据并显示出来,给程序员提供一些参考
常见的抓包工具:
wireshark:高大全,可以抓各种协议(TCP,IP,UDP,以太网之类的)的数据包
fiddler:专注于HTTP的抓包
fiddler使用
下载好之后进行简单的设置,点击Tools,选择Options
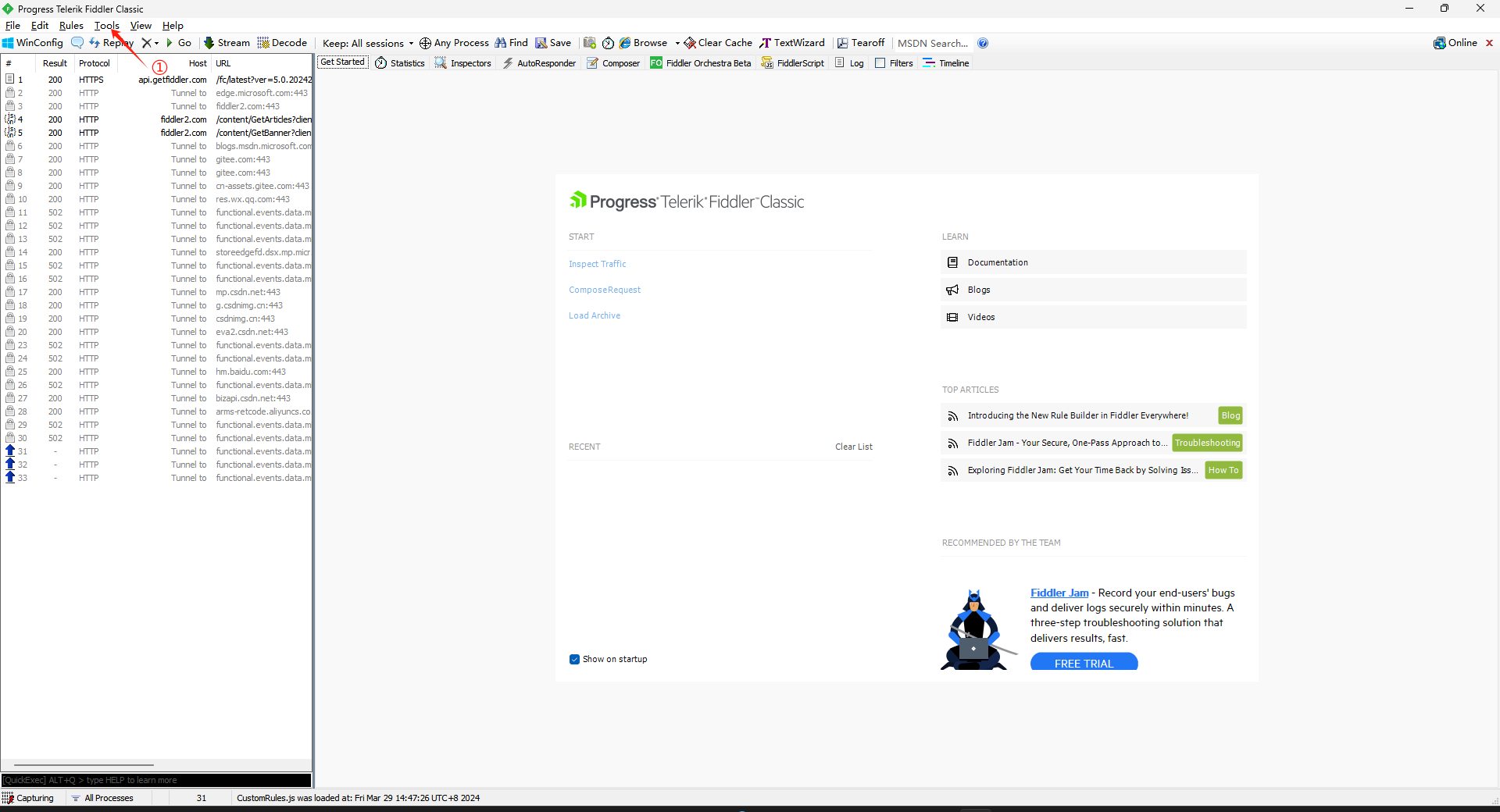

 勾完选OK
勾完选OK
第三步这里会弹出一个窗口让你安装证书,选是就对了
当前网络上大部分请求都是基于HTTPS(在HTTP上进行了加密)
除此之外需要关闭电脑上的代理(也就是翻墙)程序,因为fiddler也是一个代理程序,代理之间会有冲突
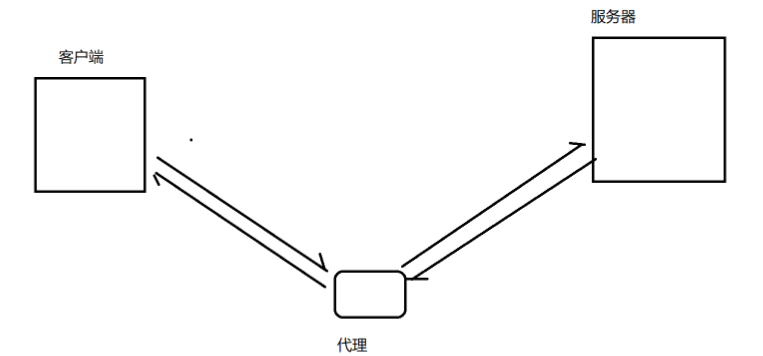
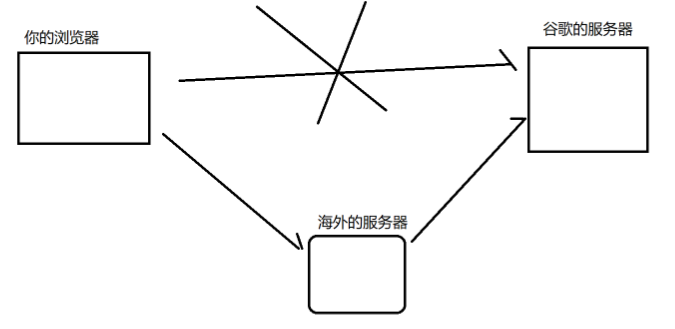
代理是啥?
代理是一个程序,而不是一个设备(区分路由器),工作在应用层的,负责转发数据。
用来翻墙的代理,本质上是通过一个可以被访问的境外服务器来部署代理服务器的
代理分为两种
1. 正向代理:客户端的代言人(代替客户端的工作)
2. 反向代理:服务器的代言人

只要系统上有任何一个程序(不一定是浏览器)使用HTTP/HTTPS,就能被fiddler找到
把原来的记录删除,用搜狗搜索fiddler
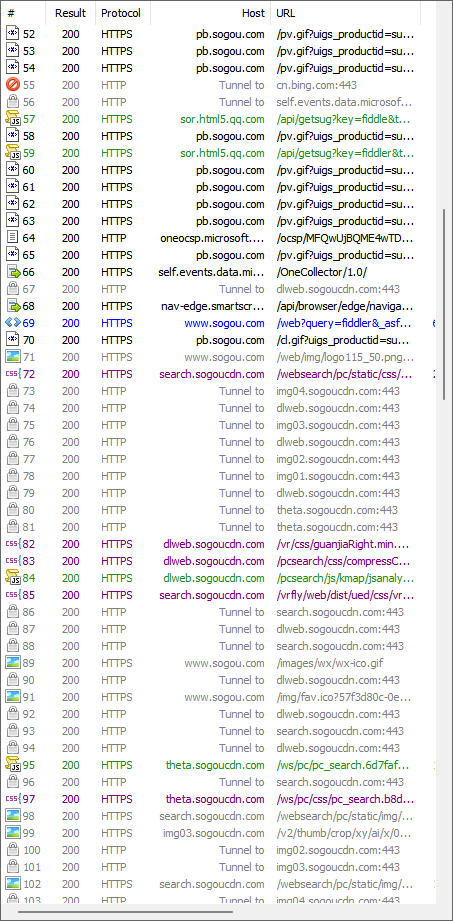
实际上,打开一个网站,其实浏览器和服务器之间进行的HTTP交互不止有一次,通常会有很多次
第一次交互拿的是这个页面的HTML,HTML还会依赖其他的css和js,图片等。HTML被浏览器加载之后又会触发其他http请求,获取到css,js等。执行js又会触发更多http请求,又有js和css
这些灰色怎么回事呢?
由于浏览器和服务器之间要进行多次网络交互,整体的过程是比较低效的为了提升效率,就会把一些固定不变的内容在浏览器本地的机器硬盘上进行缓存.比如css,图片,js这些很少发生改变的东东
保存到硬盘上之后,后续再请求就可以直接从硬盘上读取数据,减少了网络交互的开销
不想读到这些灰色的咋办,按ctrl + F5强制刷新就可以不读取缓存,直接读服务器的数据

众多抓包中,标识蓝色的表示返回一个HTML,往往是一个网站的入口
![]()
选择这条信息并双击,在右上角显示的是请求的明细
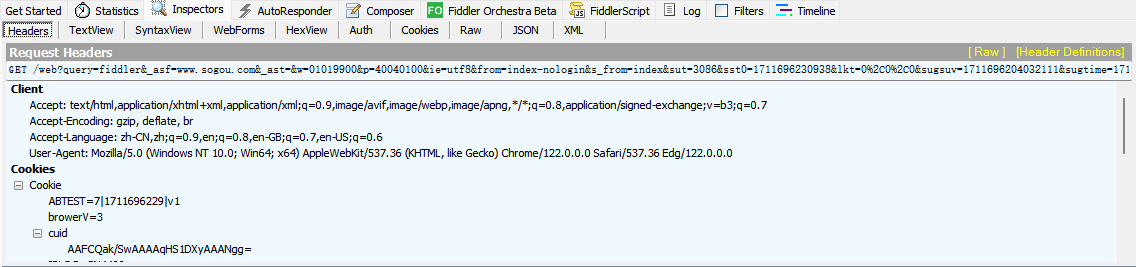
右下角显示的是响应的明细

我们一般在标签栏(右上角右下角各有一个)中选择Raw查看http请求的原始数据
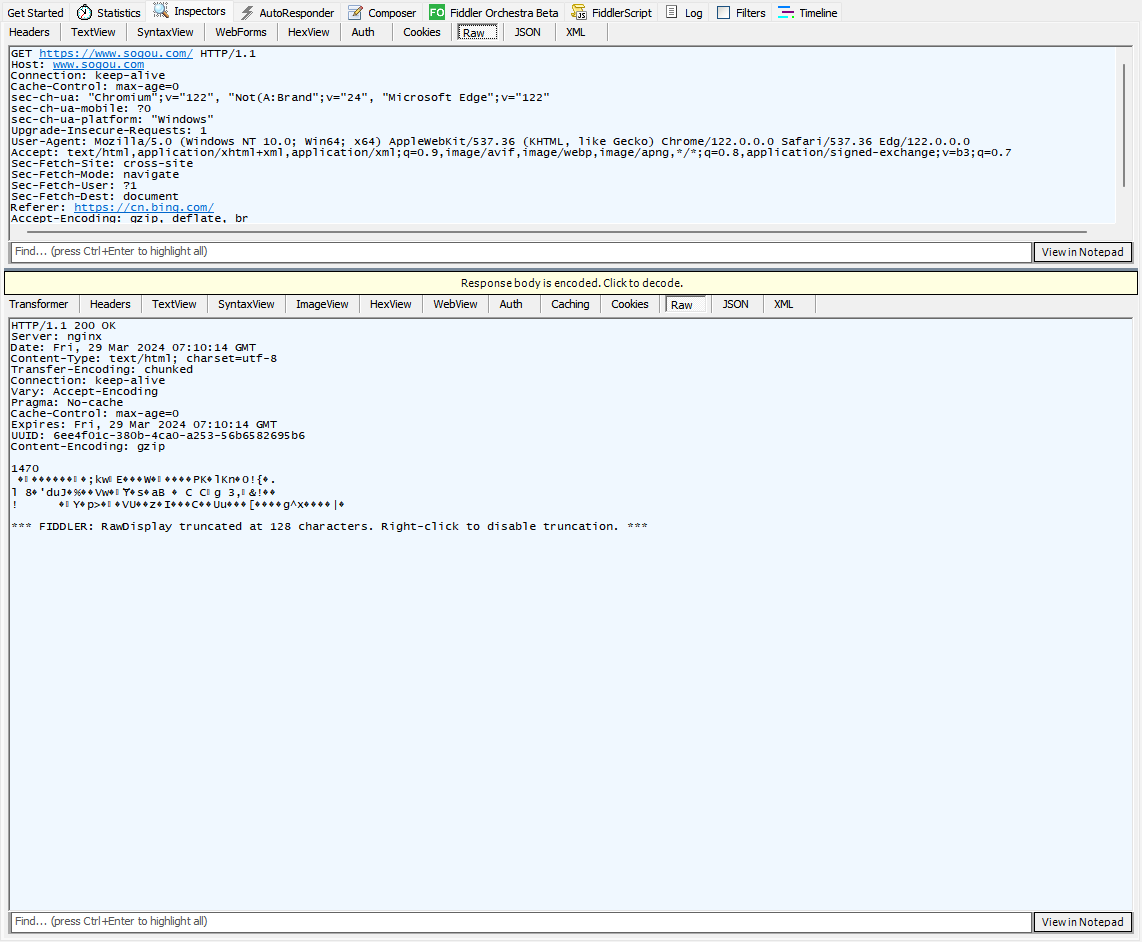
这里响应数据为什么会出现乱码呢?
其实是响应的数据被压缩了。网络传输中,带宽是一个比较贵的硬件资源,网络为了节省带宽,就把响应数据进行压缩
![]()
点击这条就可以解压缩了,解压缩需要消耗时间和CPU的
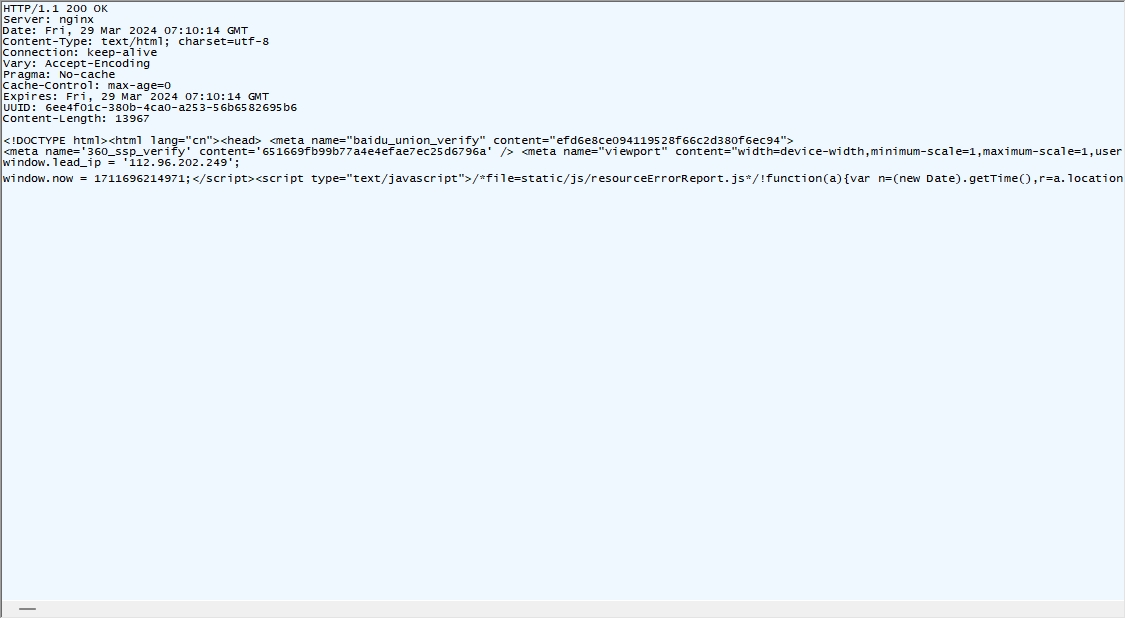 解压缩后的内容其实就是网站网页的HTML
解压缩后的内容其实就是网站网页的HTML
HTTP请求
有四个部分
1.首行
GET https://www.sogou.com/web?query=fiddler&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=3086&sst0=1711696230938&lkt=0%2C0%2C0&sugsuv=1711696204032111&sugtime=1711696230938 HTTP/1.1
GET表示方法,query = 后面的内容是url,HTTP/1.1是版本号,三个部分分别用空格分割
2.请求头(header)
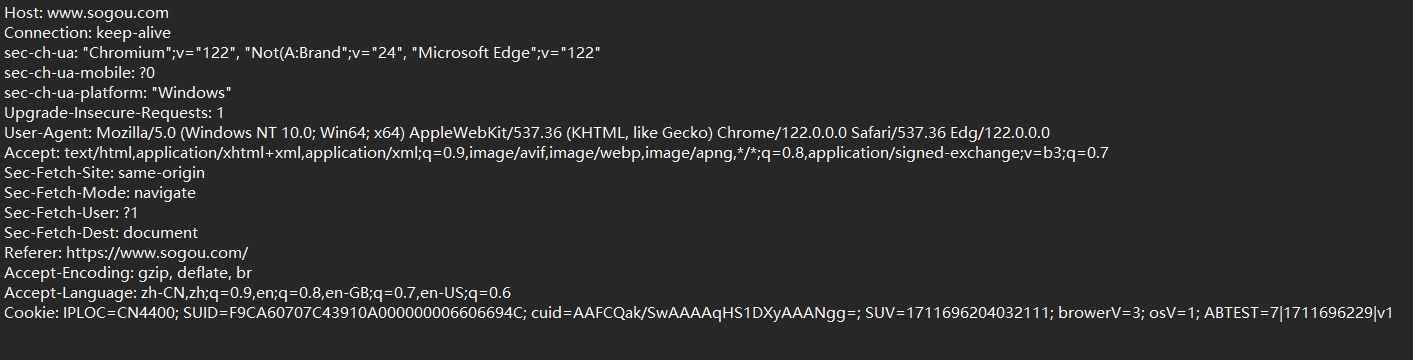
从第二行到末尾都是请求头,类似于TCP/IP报头,存储了重要的信息
这里的请求头是采用文本的形式组织的,里面包含很多键值对,每个键值对占一行,键和值之间用 : + 空格分割
3.空行
请求头下面有一个空行,这个空行表示结束
4.正文(body)
http的载荷部分,有的http有,有的没有
HTTP响应
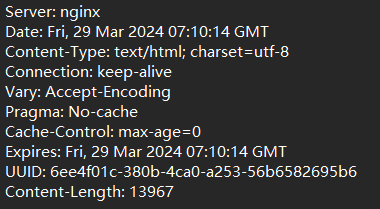
1.首行
![]()
HTTP/1.1表示版本号,200表示状态码,OK表示状态码描述
2.响应头
键值对
3.空行
响应头结束标记
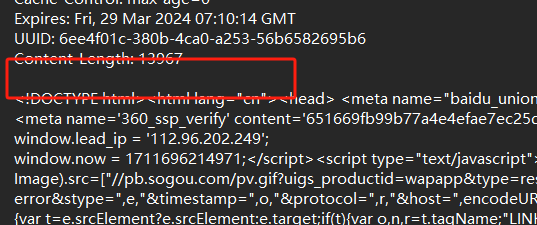
4.响应正文(body)
HTTP请求(详细)
URL
URL描述一个网络上的资源位置,是唯一资源定位符
区分:URI是唯一资源标识符,URI的标识范围比URL更广一些
fiddler - 搜狗搜索 (sogou.com)![]() https://www.sogou.com/web?query=fiddler&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=3086&sst0=1711696230938&lkt=0%2C0%2C0&sugsuv=1711696204032111&sugtime=1711696230938这种就是一个URL,https是协议名称;www.sougou.com是域名;web后面是带有层次结构的路径
https://www.sogou.com/web?query=fiddler&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=3086&sst0=1711696230938&lkt=0%2C0%2C0&sugsuv=1711696204032111&sugtime=1711696230938这种就是一个URL,https是协议名称;www.sougou.com是域名;web后面是带有层次结构的路径
一个URL的完整结构

服务器地址也可以用IP地址来表示
服务器端口号:http 用80,https 用443
这个URL如何查找网络上资源位置?
1)通过IP地址找到服务器的位置
2)通过端口号找到具体的程序
3)通过路径知道访问的是哪个资源
查询字符串:键值对格式,使用&(and或者叫做取地址符号)分割键值对,使用 = 分割键和值
比如下面这个网址

片段标识符:标识当前页面的某个部分,通过不同的片段标识符可以实现页面内的跳转
URL encode
在普通的URL中,本身某些符号有特殊的含义,比如 / ? : @等符号
而query string中是自定义的键值对,这样就会出现自定义的和URL本身的符号相同的情况,会导致服务器/浏览器解析失败
解决方法:对上述符号进行转义
比如我们在网页上搜索C++
![]()
这里就有一个转义的过程,把 + 号的ASCII码(2B)拿出来,使用十六进制表示,并且在前面加上%
![]()
搜索中文的话会采用utf8表示这个中文,每两位加上一个%
方法
最常见的方法
GET:从服务器拿一个东西过来(读操作)
POST:往服务器放一个东西过去(写操作)
两个典型的使用POST的场景:登录和上传
经典面试题:GET和POST有什么区别
GET和POST在本质上没有区别,使用GET的场景可以替换成POST,使用POST的场景也能替换成GET
从使用情况上说,GET和POST是有区别的
1. GET会把需要给服务器的补充信息放到query string中,POST会把这些信息放到body中
2.语义上的区别,标准文档中,GET的语义是用来获取数据,POST的语义是给服务器传输数据
3.幂等性。标准文档中,建议GET实现成幂等的,POST则无要求
幂等性?每次输入的内容一定,输出的结果也是一定的,称为幂等
4.GET请求可以被浏览器收藏夹收藏,POST不可以
POST的例子:拿老师的例子举例
username后面跟的是json格式的数据
password后面跟的是base64编码(使用四个字节对原始数据中的三个字节进行重新编码,为了能够去掉原始数据中二进制的内容。识别方法:看后面出现的两个=号)

报头
Host:
表示服务器主机的地址和端口
Content-Length:
表示body中的数据长度
通过这个长度处理粘包问题(HTTP基于TCP,也需要在读包时明确包与包之间的界限),如果没有body的请求/响应,就直接使用空行作为分割符,如果有body,空行就不是结束标记了。从空行开始读取body,而要读多长就取决于Content-Length
Content-Type:
表示请求的body中的数据格式
body传输格式(请求中):
1)application/json(body)
2)application/x-www-form-urlencoded(称为form表单。通过HTML中的form标签构造出的一种格式。这个格式认为把query string放到body里了)
3)multipart/form-data(上传文件使用)
(响应中):
1)text/plain 纯文本
2)text/html 返回html
3)application/JavaScript 返回js
4)text/css
5)image/png/jpg
User Agent(UA):
描述了用户使用啥样的设备上网

![]() 操作系统信息
操作系统信息
![]() 浏览器信息
浏览器信息
例子:一个程序员设计了一个网站,是否使用新特性?如果使用了,老的设备不一定能打得开。不使用又没有竞争力
此时借助UA就能解决上面的问题。如果用户用的是很老的设备,返回的页面就不包含新特性,确保这个页面能够正确访问出来;如果用户用的是新设备,返回的页面就包含新特性,保证用户体验感
如今的UA还可以判断上网的设备是PC还是移动端(手机,平板等)
Referer
表示当前这个页面是从哪个页面跳转来的
![]()

referer是否能被篡改呢?是可以的,在10年前的运营商
1. 有动机。他们有属于自己的系统,可以把普通互联网公司系统的referer改成运营商系统的referer就行了
2.有能力。运营商提供通信设施,但是他们在路由器/交换机上部署程序,让程序解析HTTP数据,然后把referer改成自己的
解决这种问题的方法:HTTPS S指的是SSL -- 网络中用于加密的协议
加密会把header和body都进行加密,让网络上传输的是密文。运营商如果想要修改,就得先破解,就算能解密也篡改不了,因为一旦修改就能被用户的浏览器感知到
Cookie
本质上是浏览器本地化持久存储数据的机制
系统提供了api操作文件,浏览器作为程序是可以调用这些api来操作本地文件的。但是对于浏览器上运行的网页,浏览器禁止网页直接通过api操作本地文件。
与此同时浏览器给网页提供了api,能够有限度地存储数据,而不能随意访问文件系统
Cookie就是这种存储机制
HTTP请求中的Cookie字段就是把本地存储的Cookie信息发送到服务器这边
响应中会有一个Set-Cookie字段,就是服务器告诉浏览器你要在本地保存哪些信息
Cookie几个结论:
1.Cookie从哪里来?服务器返回给浏览器的,通常是首次访问/登录之后
2.Cookie到哪里去?Cookie会存储在浏览器本地主机的硬盘上,后续每次访问浏览器都会带上Cookie,不同的客户端保存的Cookie是不同的,即使是同一个主机,使用不同的浏览器,Cookie也大概率是不同的
3.Cookie中存什么?键值对格式的数据,由程序员自定义
4.Cookie在浏览器怎么组织?在硬盘内保存,按照不同的域名为维度分别存储。
5.Cookie的用途是什么?用来在客户端保存数据,最重要的就是保存用户的身份标识,服务器可以通过标识区分标识来区分用户。
总结:一个HTTP请求中,有以下部分可以携带程序员自定义的数据
1.query string
2.Cookie
3.body
4.url的path
HTTP响应(详细)
状态码
用于响应,表示响应的结果如何
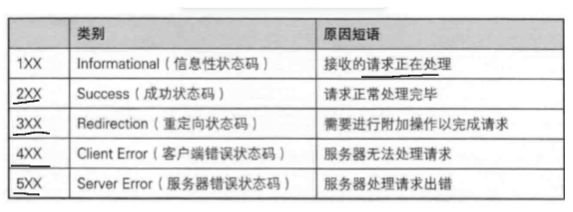

常见的:
1)200 OK 表示成功
2)404 Not Found 表示资源没找到
3)403 Forbidden 请求的资源没有权限访问
4)405 Method Not Found 用户的服务器只支持GET请求,但是该用户发了个POST请求就会出现这样的问题
5)500 Internal Server Error 服务器内部错误 --> 服务器挂了
6)504 Gateway Timeout 访问服务器超时(网挂了或者服务器挂了)
7)302 Move temporarily 重定向(临时的)
明明访问的是网站A,但是A让你去找网站B,浏览器就会自动去访问B
重定向的意义:比如有一个域名要更改名字了,但是之前该网站的老用户还在收藏夹保存着老域名,为了不让老用户找不到新域名的网站,就可以把访问老域名的请求重定向到新域名上(类似手机的呼叫转义)
如何构造HTTP请求
通过代码构造
对于java来说,使用ServerSocket/Socket(TCP的socet api 来编程)
本质上就是基于Socket写一个TCP的客户端,然后往socket中按照HTTP协议的格式写入字符串即可
通过第三方工具构造
比如PostMan
每个标签页就是一个构造HTTP请求的配置页面
 发送请求按钮
发送请求按钮
HTTPS
HTTP是明文传输的(不安全)
运营商劫持案例
我要下载天天动听音乐播放器,但是点击下载后却帮我下载了QQ浏览器
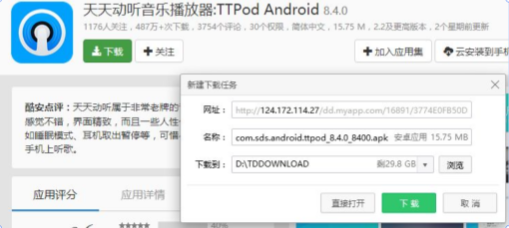
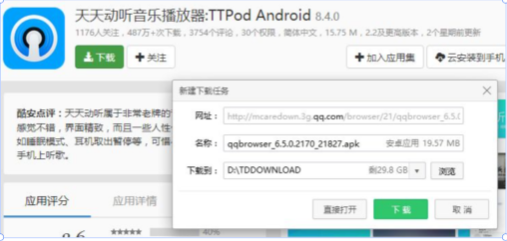
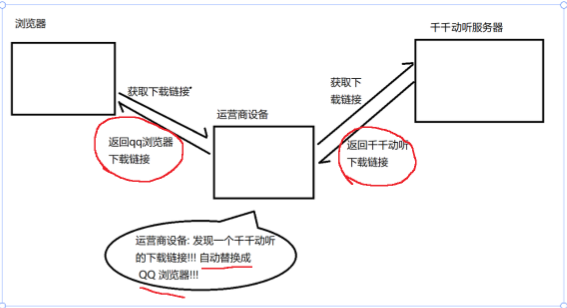
所以解决安全问题的核心就是加密
密码学
密码学中几个重要的概念:
明文:要传输的真实数据,要表达的实际意思
密文:针对明文加密之后得到的结果
明文 => 密文:加密
密文 => 明文:解密
加密和解密的过程需要一个道具,称为密钥
对称加密:加密和解密都使用同一个密钥
非对称加密:加密和解密使用两个不同的密钥,这两个密钥k1和k2是成对的,一个用来加密另一个就是用来解密的
HTTP工作过程
HTTPS是在HTTP的基础上引入一个加密层SSL,针对header和body进行加密
1)引入对称加密
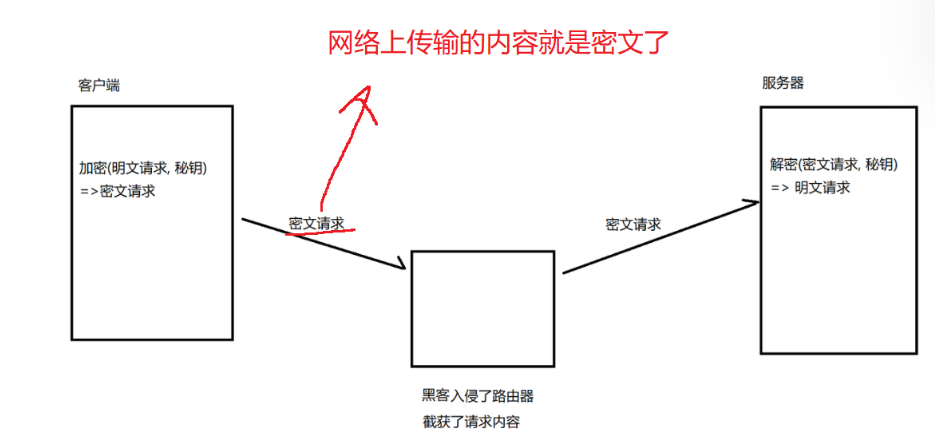
1. 对称加密的时候,客户端和服务器都得使用同一个密钥
2. 不同的客户端得使用不同的密钥
这就意味着,每个客户端连接到服务器的时候,都需要自己生成一个随机的密钥,并且将这个密钥告诉给服务器。问题来了:一旦黑客拿到这个密钥,加密操作将毫无意义
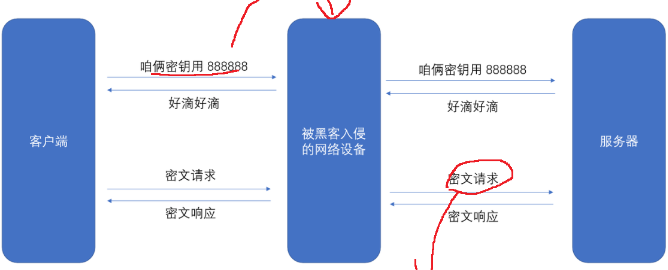
所以对称加密行不通,接下来得考虑将密钥也进行密文传输
2) 使用非对称加密
对对称密钥进行加密,确保对称密钥的安全性(注意:非对称密钥的加密解密消耗的CPU资源很高,所以仅对对称密钥进行加密,而header和body这些还得靠对称密钥来加密)

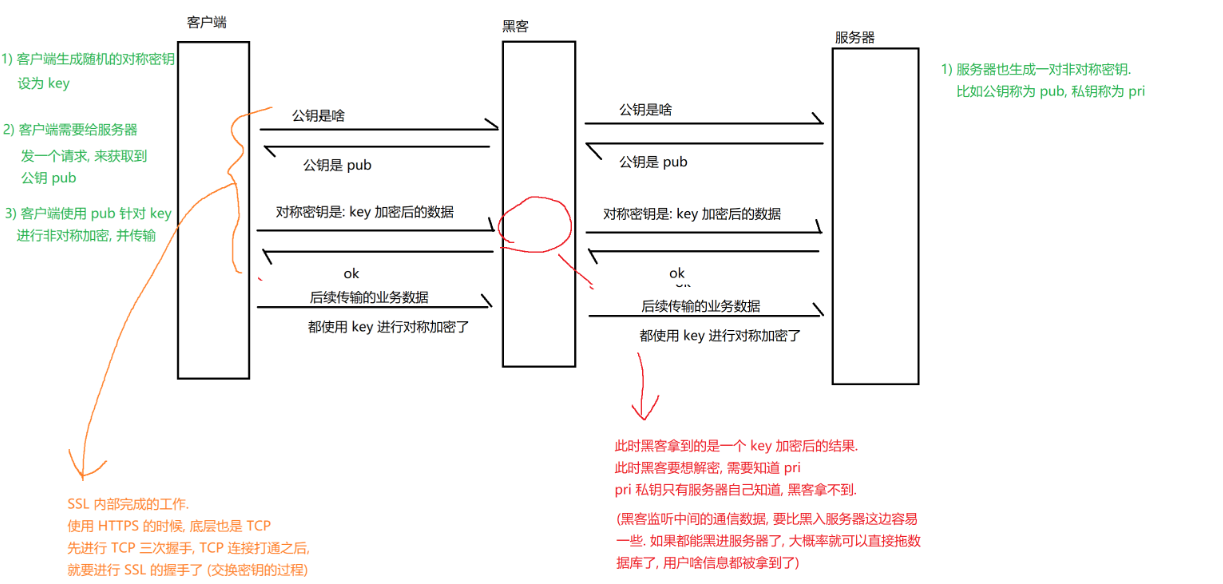
让服务器持有私钥(只有服务器知道),客户端持有公钥(黑客也知道)对生成的对称密钥进行加密。黑客手里虽然有密钥,但没有私钥也无法对这个数据进行解密
纵使这样,黑客也有办法获取到对称密钥key的,具体采用中间人攻击的方法
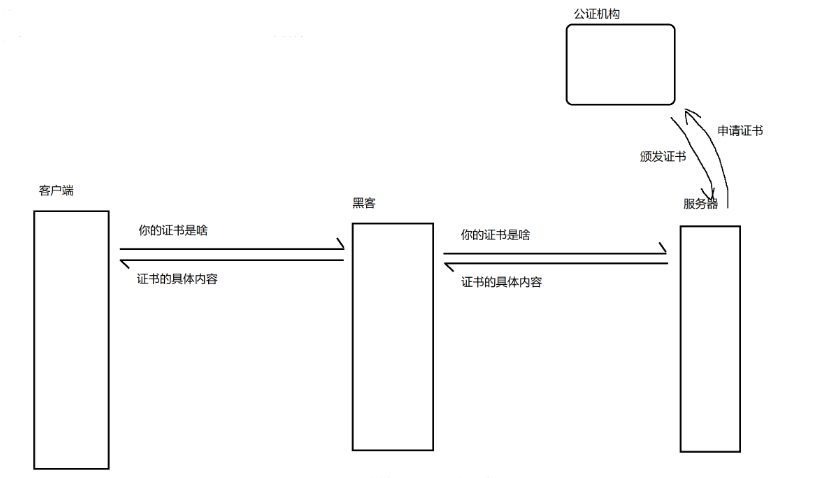
中间人攻击
服务器可以创建一对公钥和私钥,那黑客也可以按照同样的方式自己创建出一堆公钥和私钥,冒充自己是服务器
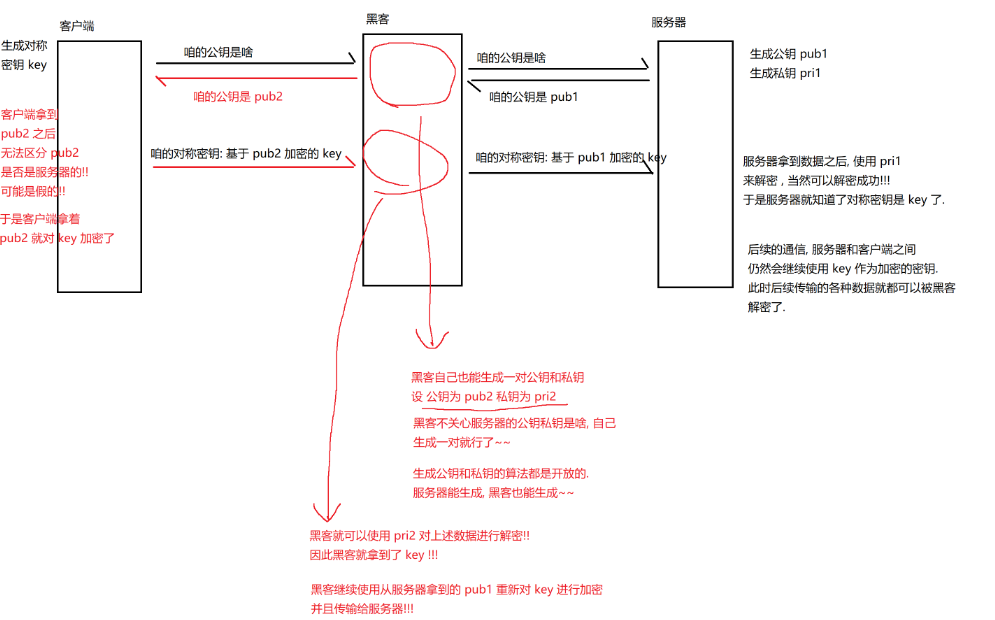
解决中间人攻击
关键:客户端拿到公钥的时候,能验证这个公钥是否是真的而不是黑客伪造的
具体做法:要求服务器提供一个证书。证书是一个结构化的数据,里面包含很多属性,最终以字符串的形式提供。证书会包含一些重要的信息,比如服务器的主域名,公钥,证书有效期等等
证书就是搭建服务器的人从第三方认证机构进行申请的
证书的签名:本质上是一个经过加密的校验和(字符串)
如果两份数据内容一样,其各自的校验和一定相同,反之一定不相同
客户端拿到证书后:
1. 按照同样的校验和算法,把证书的其他字段重新算一遍,得到校验和1;
2. 使用系统内置的公正机构的公钥对证书中的签名进行解密,得到检验和2;
如果校验和1和2是一致的,说明证书没有被修改
黑客能不能自己也去公正机构申请证书,然后把自己的证书替换掉服务器的证书呢?
不行!因为证书里面还包含了服务器的域名,而服务器的域名是唯一的,黑客伪造的证书很容易一眼假。
一个经典面试题:谈谈 HTTPS 的工作过程
要谈的东西从引入对称加密开始一直到最后证书验证过程