随着当前数据处理业务场景日趋复杂,对于大数据处理平台基础架构的能力要求也越来越高,既要求数据湖的大存储能力,也要求具备海量数据高效批处理能力,同时还可能对延时敏感的近实时链路有强需求,本文主要介基于 MaxCompute 的离线近实时一体化新架构如何来支持这些综合的业务场景,提供近实时增全量一体的数据存储和计算(Transaction Table2.0)解决方案。
业务背景与现状
当前典型的数据处理业务场景中,对于时效性要求低的大规模数据全量批处理的单一场景,直接使用 MaxCompute 足以很好的满足业务需求。但随着 MaxCompute 承载的业务无论是规模,还是使用场景,都越来越丰富,在处理好大规模离线批处理链路的同时,用户对近实时和增量处理链路也有很多的需求,下图展示了部分业务场景。
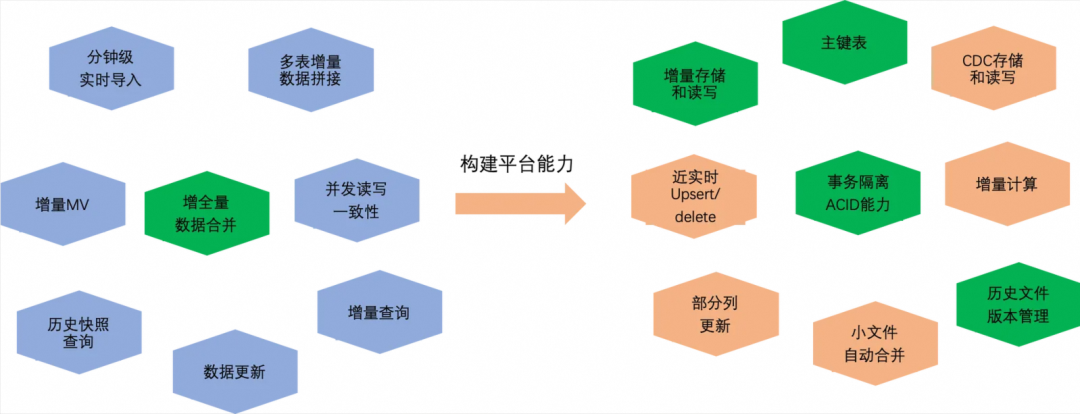
比如近实时数据导入链路,依赖平台引擎具备事务隔离,小文件自动合并等能力,又比如增全量数据合并链路,还依赖增量数据存储和读写,主键等能力。MaxCompute以前不具备新架构能力之前,要支持这些复杂的综合业务场景,只能通过下图所示的三种解决方案,但无论使用单一引擎或者联邦多引擎都存在一些无法解决的痛点。
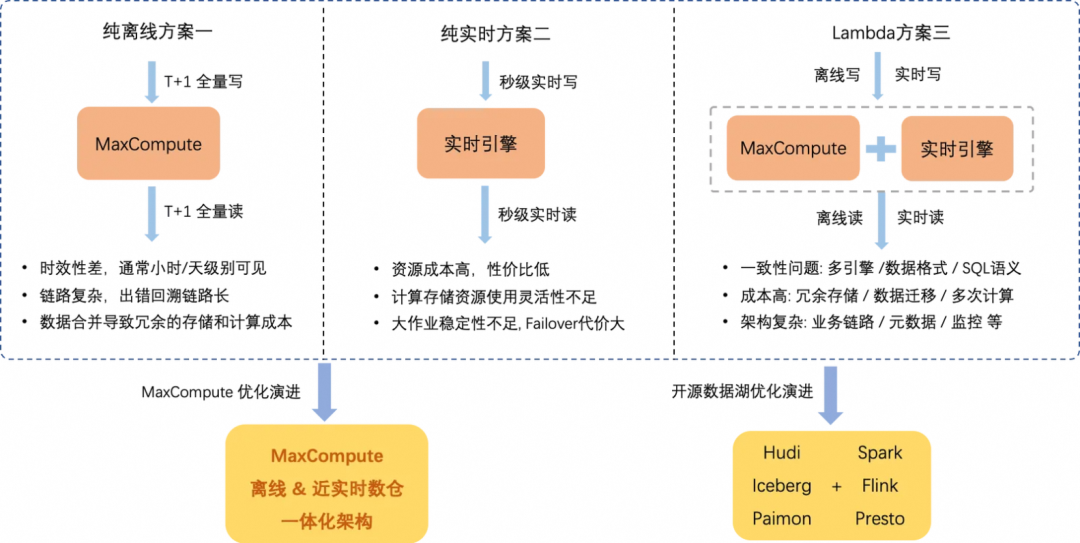
方案一,只使用单一的MaxCompute离线批处理解决方案,对于近实时链路或者增量处理链路通常需要转化成T+1的批处理链路,会一定程度上增加业务逻辑复杂度,且时效性也较差,存储成本也可能较高。
方案二,只使用单一的实时引擎,那资源成本会较高,性价比较低,且对于大规模数据批处理链路的稳定性和灵活性也存在一些瓶颈。
方案三,使用典型的Lambda架构,全量批处理使用MaxCompute链路,时效性要求比较高的增量处理使用实时引擎链路,但该架构也存在大家所熟知的一些固有缺陷,比如多套处理和存储引擎引发的数据不一致问题,多份数据冗余存储和计算引入的额外成本,架构复杂以及开发周期长等问题。
这些解决方案在成本,易用性,低延时,高吞吐等方面互相制约,很难同时具备较好的效果,这也驱动着MaxCompute有必要开发新的架构既能满足这些业务场景需求,也能提供较低的成本和较好的用户体验。
近几年在大数据开源生态中,针对这些问题已经形成了一些典型的解决方案,最流行的就是Spark/Flink/Trino开源数据处理引擎,深度集成Hudi / Delta Lake / Iceberg / Paimon开源数据湖,践行开放统一的计算引擎和统一的数据存储思想来提供解决方案,解决Lamdba架构带来的一系列问题。同时MaxCompute近一年多在离线批处理计算引擎架构上,自研设计了离线&近实时数仓一体化架构,在保持经济高效的批处理优势下,同时具备分钟级的增量数据读写和处理的业务需求,另外,还可提供Upsert,Time travel等一系列实用功能来扩展业务场景,可有效地节省数据计算,存储和迁移成本,切实提高用户体验。
离线&近实时增全量一体化业务架构

上图所示即为MaxCompute高效支持上述综合业务场景的全新业务架构
写入端会融合多种数据集成工具将丰富的数据源近实时增量或批量导入到统一的MaxCompute表存储中,存储引擎的表数据管理服务会自动优化编排数据存储结构来治理小文件等问题;使用统一的计算引擎支持近实时增量和大规模离线批量分析处理链路;由统一的元数据服务支持事务机制和海量文件元数据管理。统一的新架构带来的优势也是非常显著,可有效解决纯离线系统处理增量数据导致的冗余计算和存储、时效低等问题,也能避免实时系统高昂的资源消耗成本,同时可消除Lambda架构多套系统的不一致问题,减少冗余多份存储成本以及系统间的数据迁移成本。
简言之,一体化新架构既可以满足增量处理链路的计算存储优化以及分钟级的时效性,又能保证批处理的整体高效性,还能有效节省资源使用成本。
目前新架构已支持了部分核心能力,包括主键表,Upsert实时写入,Time travel查询,增量查询,SQL DML操作,表数据自动治理优化等,更详细的架构原理和相关操作指导请参考↓官网架构原理和用户操作文档。
业务场景实践
本章节重点介绍新架构如何支持一些典型的业务链路以及产生的优化效果。
1. 表存储和数据治理优化
本章节主要介绍建表操作和关键表属性的含义,以及根据业务场景如何设置表属性值以达到最佳效果,也会简单描述一下存储引擎后台如何自动优化表数据。
▶ 建表

首先,一体化新架构需要设计统一的表格式来存储不同格式的数据以支撑不同业务场景的数据读写,这里称为Transaction Table2.0,简称TT2,可以同时支持既有的批处理链路,以及近实时增量等新链路的所有功能。
建表语法参考官网,简单示例:
createtable tt2 (pk bigint notnullprimarykey, val string) tblproperties ("transactional"="true");
createtable par_tt2 (pk bigint notnullprimarykey, val string) partitioned by (pt string) tblproperties ("transactional"="true");只需要设置主键Primary Key(PK),以及表属性transactional为true,就可以创建一张TT2。PK用来保障数据行的unique属性,transactional属性用来配置ACID事务机制,满足读写快照隔离。
▶ 关键的表属性配置
详细属性配置参考官网,简单示例:
createtable tt2 (pk bigint notnullprimarykey, val string)tblproperties ("transactional"="true", "write.bucket.num" = "32", "acid.data.retain.hours"="48");
-
表属性: write.bucket.num
此属性非常重要,表示每个partition或者非分区表的分桶数量,默认值为16,所有写入的记录会根据PK值对数据进行分桶存储,相同PK值的记录会落在同一个桶中。非分区表不支持修改,分区表可修改,但只有新分区生效。
数据写入和查询的并发度可通过bucket数量来水平扩展,每个并发可至少处理一个桶数据。但桶数量并不是越多越好,对于每个数据文件只会归属一个桶,因此桶数量越多,越容易产生更多的小文件,进一步可能增加存储成本和压力,以及读取效率。因此需要结合数据写入的吞吐,延时,总数据的大小,分区数,以及读取延时来整体评估合理的桶数量。
此外,数据分桶存储也非常有助于提升点查场景性能,如果查询语句的过滤条件为具体的PK值,那查询时可进行高效的桶裁剪和数据文件裁剪,极大减少查询的数据量。
-
评估桶数量建议
-
对于非分区表,如果数据量小于1G,桶数量建议设置为4-16; 如果总数据量大于1G,建议按照128M-256M作为一个桶数据的大小,如果希望查询的并发度更多的话,可以进一步调小桶数据量大小; 如果总数据量大于1T,建议按照500M-1G作为一个桶数据的大小; 但目前能够设置的最大桶数量是4096,因此对于更大的数据量,单个桶的数据量也只能越来越大,会进一步影响查询效率,后续平台也会考虑是否可放开更大的限制。
-
对于分区表,设置的桶数量是针对每个分区的,并且每个分区的桶数量可以不同。每个分区的桶数量设置原则可以参考上面非分区表的配置建议。对于存在海量分区的表,并且每个分区的数据量又较小的话,比如在几十M以内,建议每个分区的桶数量尽可能少,配置在1-2个即可,避免产生过多的小文件。
-
表属性: acid.data.retain.hours
此属性也很重要,代表time travel查询时可以读取的历史数据实践范围,默认值是1天,最大支持7天。
建议用户按真实的业务场景需求来设置合理的时间周期,设置的时间越长,保存的历史数据越多,产生的存储费用就越多,而且也会一定程度上影响查询效率,如果用户不需要time travel查询历史数据,建议此属性值设置为0,代表关掉time travel功能,这样可以有效节省数据历史状态的存储成本。
▶ Schema Evolution操作
TT2支持完整的Schema Evolution操作,包括增加和删除列。在time travel查询历史数据时,会根据历史数据的Schema来读取数据。另外PK列不支持修改。
详细DDL语法参考官网,简单示例:
altertable tt2 add columns (val2 string);altertable tt2 drop columns val;
▶ 表数据自动治理优化
-
存在的问题
TT2典型场景之一是支持分钟级近实时增量数据导入,因此可能导致增量小文件数量膨胀,尤其是桶数量较大的情况,从而引发存储访问压力大、成本高,数据读写IO效率低下,文件元数据分析慢等问题,如果Update/Delete格式的数据较多,也会造成数据中间状态的冗余记录较多,进一步增加存储和计算的成本,查询效率降低等问题。
为此,后台存储引擎配套支持了合理高效的表数据服务对存储数据进行自动治理和优化,降低存储和计算成本,提升分析处理性能。
-
表数据组织格式
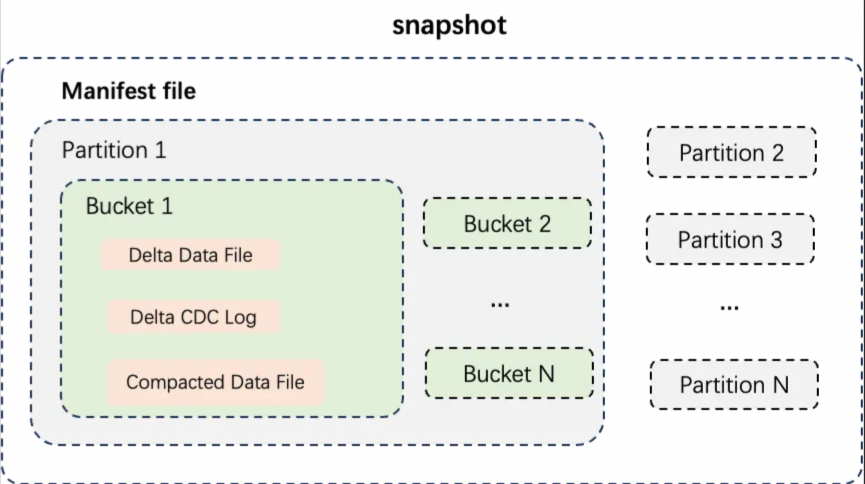
如上图所示,展示了分区表的数据结构,先按照分区对数据文件进行物理隔离,不同分区的数据在不同的目录之下; 每个分区内的数据按照桶数量来切分数据,每个桶的数据文件单独存放; 每个桶内的数据文件类型主要分成三种:
-
Delta Data File:每次事务写入或者小文件合并后生成的增量数据文件,会保存每行记录的中间历史状态,用于满足近实时增量读写需求。
-
Compacted Data File:Delta File经过Compact执行生成的数据文件,会消除数据记录的中间历史状态,PK值相同的记录只会保留一行,按照列式压缩存储,用来支撑高效的数据查询需求。
-
Delta CDC Log: 按照时序存储的CDC格式增量日志 (目前还未对外推出)。
-
数据自动治理优化
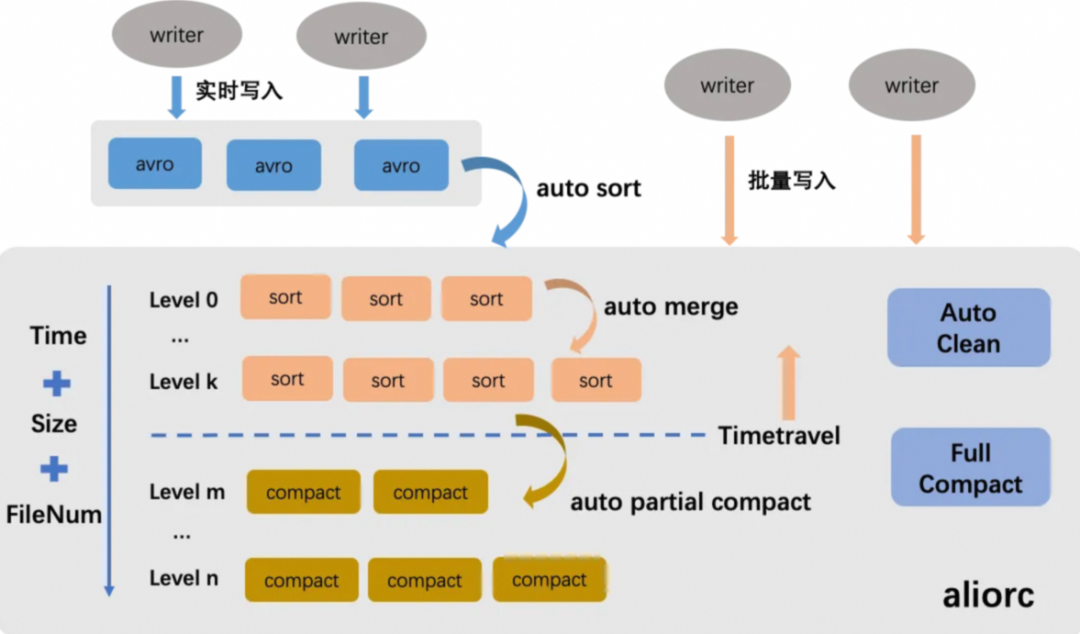
如上图所示,TT2的表数据服务主要分成Auto Sort / Auto Merge / Auto Compact / Auto Clean四种,用户无需主动配置,存储引擎后台服务会智能的自动收集各个维度的数据信息,配置合理的策略自动执行。
-
Auto Sort: 自动将实时写入的行存avro文件转换成aliorc列存文件,节省存储成本和提升读取效率。
-
Auto Merge: 自动合并小文件,解决小文件数量膨胀引发的各种问题。主要策略是周期性地根据数据文件大小/文件数量/写入时序等多个维度进行综合分析,进行分层次的合并。但它并不会消除任何一条记录的中间历史状态,主要用于time travel查询历史数据。
-
Auto Partial Compact: 自动合并文件并消除记录的历史状态,降低update/delete记录过多带来的额外存储成本,以及提升读取效率。主要策略是周期性地根据增量的数据大小/写入时序/time travel时间等多个维度进行综合分析来执行compact操作。该操作只针对超过time travel可查询时间范围的历史记录进行compact。
-
Auto Clean: 自动清理无效文件,节省存储成本。Auto Sort / Auto Merge / Auto Partial Compact操作执行完成后,会生成新的数据文件,所以老的数据文件其实没什么作用了,会被即时自动删除,及时节省存储成本。
如果用户对于查询性能的要求非常高,也可尝试手动执行全量数据的major compact操作,每个桶的所有数据会消除所有的历史状态,并且额外生成一个新的Aliorc列存数据文件,用于高效查询,但也会产生额外的执行成本,以及新文件的存储成本,因此非必要尽量不执行。
详细语法参考官网,简单示例:
set odps.merge.task.mode=service;altertable tt2 compact major;
2. 数据写入场景业务实践
本章节主要介绍部分典型的写入场景业务实践。
▶ 分钟级近实时 Upsert 写入链路
MaxCompute离线架构一般在小时或天级别批量导入增量数据到一张新表或者新分区中,然后配置对应的离线ETL处理链路,将增量数据和存量表数据执行Join Merge操作,生成最新的全量数据,此离线链路的延时较长,计算和存储也会消耗一定的成本。
使用新架构的upsert实时导入链路基本可以保持数据从写入到查询可见的延时在5-10分钟,满足分钟级近实时业务需求,并且不需要复杂的ETL链路来进行增全量的Merge操作,节省相应的计算和存储成本。
实际业务数据处理场景中,涉及的数据源丰富多样,可能存在数据库、日志系统或者其他消息队列等系统,为了方便用户数据写入TT2, MaxCompute深度定制开发了开源Flink Connector工具,针对高并发、容错、事务提交等场景做了定制化的设计及开发优化,以满足延时低、正确性高等要求,同时也能很好的对接融合Flink生态。具体使用细节可以参考官网产品说明
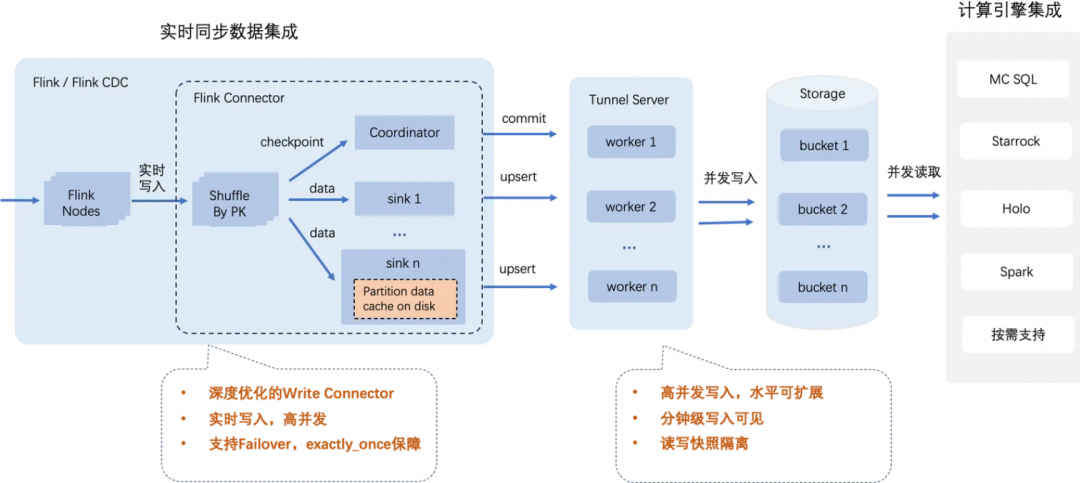
上图简单展示了整体写入的流程,可总结如下主要关键点:
-
基本大部份可融合flink生态的引擎或者工具都可通过flink任务,结合MaxCompute flink connector实时写入数据进TT2表。
-
写入并发可以横向扩展,满足低延时高吞吐需求。写入流量吞吐跟flink sink并发数,TT2桶数量等参数配置相关,可根据各自的业务场景进行合理配置。特别说明,针对TT2桶数量配置为Flink sink并发数的整数倍的场景,系统进行了高效优化,写入性能最佳。
-
满足数据分钟级可见,支持读写快照隔离
-
结合Flink的Checkpoint机制处理容错场景,保障exactly_once语义。
-
支持上千分区同时写入,满足海量分区并发写入场景需求。
-
流量吞吐上限可参考单个桶1MB/s的处理能力进行评估,不同环境不同配置都可能影响吞吐。如果对写入延时比较敏感,需要相对稳定的吞吐量,可考虑申请独享的数据传输资源,但需要额外收费。如果默认使用共享的公共数据传输服务资源组的话,在资源竞抢严重的情况下,可能保障不了稳定的写入吞吐量,并且可使用的资源量也有上限。
▶ 部分列增量更新链路
该链路可用来优化将多张增量表的数据列拼接到一张大宽表的场景,比较类似多流join的业务场景。
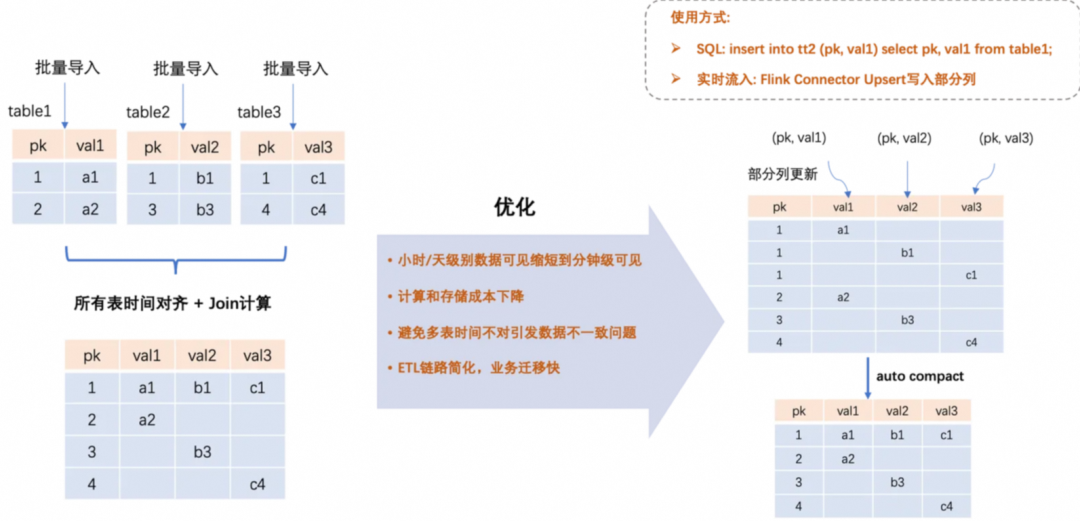
如上图所示,左边展示了MaxCompute的离线ETL链路处理此类场景,将多张增量表按照比较固定的时间来对齐数据,通常小时/天级别,然后触发一个join任务,把所有表的数据列拼接起来生成大宽表,如果有存量数据,还需要执行类似upsert的ETL链路。因此整体ETL链路延时较长,流程复杂,也比较消耗计算和存储资源,数据也容易遇到无法对齐的场景。
右边展示了通过TT2表支持部分列更新的能力,只需要将各个表的数据列实时增量更新到TT2大宽表中即可,TT2表的后台Compact服务以及查询时,会自动把相同PK值的数据行拼接成一行数据。该链路基本完全解决了离线链路遇到的问题,延时从小时/天级别降低到分钟级,而且链路简单,几乎是ZeroETL,也能成倍节省计算和存储成本。
目前支持以下两种方式进行部分列更新,功能还在灰度上线中,还未发布到官网(预计两个月内在公共云发布)。
-
通过SQL Insert进行增量写入部分列:
createtable tt2 (pk bigint notnullprimarykey, val1 string, val2 string, val3 string) tblproperties ("transactional"="true");
insertinto tt2 (pk, val1) select pk, val1 from table1;
insertinto tt2 (pk, val2) select pk, val2 from table2;
insertinto tt2 (pk, val3) select pk, val3 from table3;-
通过Flink Connector实时写入部分列。
▶ SQL DML / Upsert 批处理链路
为了方便用户操作TT2表,MaxCompute计算引擎对SQL全套的数据查询DQL语法和数据操作DML语法进行了支持,保障离线链路的高可用和良好的用户体验。SQL引擎的内核模块包括Compiler、Optimizer、Runtime等都做了专门适配开发以支持相关功能和优化,包括特定语法的解析,特定算子的Plan优化,针对pk列的去重逻辑,以及runtime upsert并发写入等。
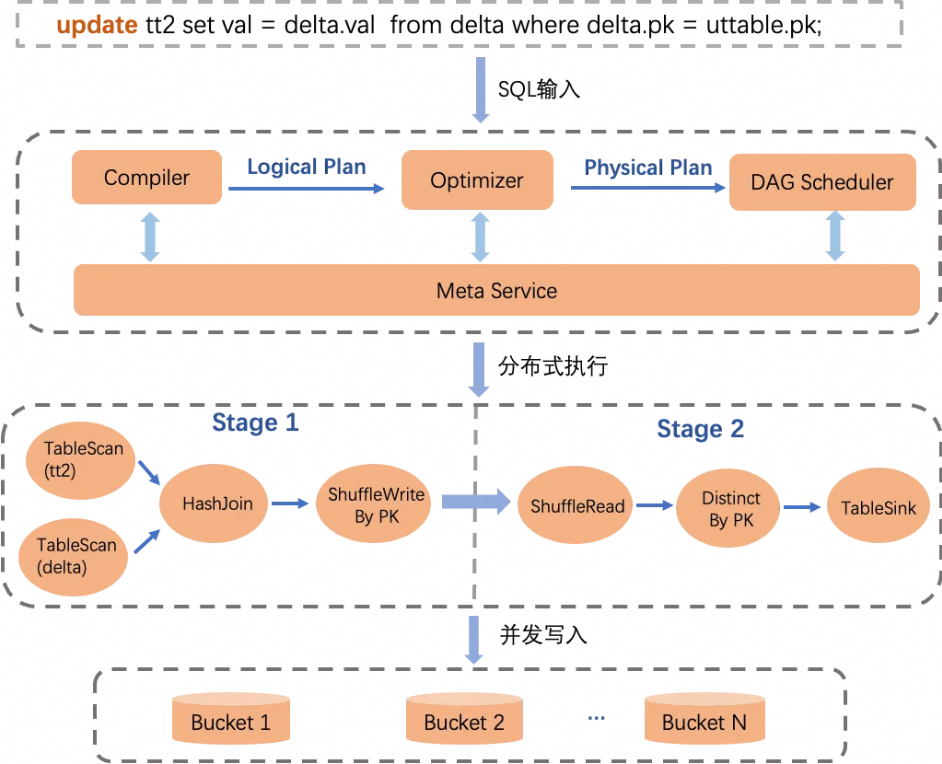
数据处理完成之后,会由Meta Service来执行事务冲突检测,原子更新数据文件元信息等,保障读写隔离和事务一致性。
SQL DML具体语法可参考官网文档,对于Insert / Update / Delete / Merge Into都有详细的介绍和示例。
对于Upsert批式写入能力,由于TT2表后台服务或者查询时会自动根据PK值来合并记录,因此对于Insert + Update场景,不需要使用复杂的Update/Merge Into语法,可统一使用Insert into插入新数据即可,使用简单,并且能节省一些读取IO和计算资源。
3. 数据查询场景业务实践
本章节主要介绍部分典型的查询场景业务实践。
▶ Time travel查询
基于TT2,计算引擎可高效支持Time travel查询的典型业务场景,即查询历史版本的数据,可用于回溯业务数据的历史状态,或数据出错时,用来恢复历史状态数据进行数据纠正。
详细语法参考官网,简单示例:
//查询指定时间戳的历史数据select * from tt2 timestampasof'2024-04-01 01:00:00';//查询5分钟之间的历史数据select * from tt2 timestampasofcurrent_timestamp() - 300;//查询截止到最近第二次Commit写入的历史数据select * from tt2 timestampasof get_latest_timestamp('tt2', 2);
可查询的历史数据时间范围,可通过表属性acid.data.retain.hours来配置,配置策略上文已介绍,配置参数详解参考官网。
-
Time travel查询处理过程简介
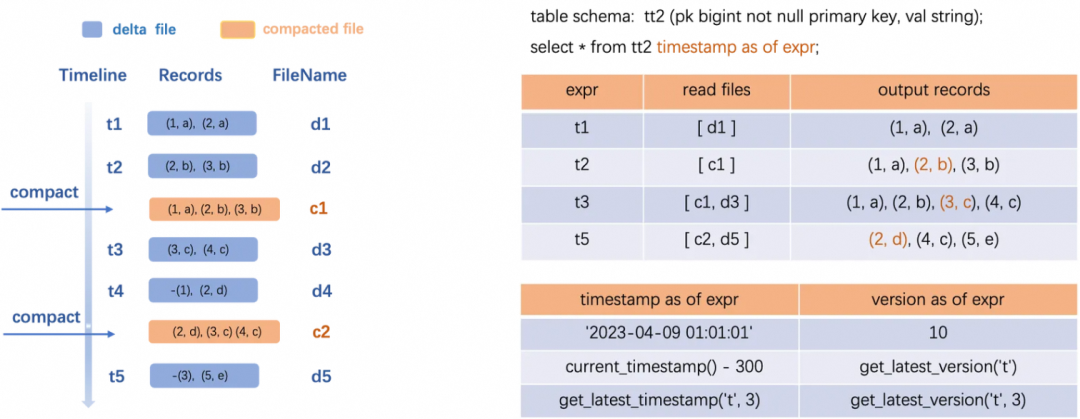
SQL引擎接收到用户侧输入的time travel查询语法后,会先从Meta服务中解析出来要查询的历史数据版本,然后过滤出来要读取的Compacted file和Delta file,进行合并merge输出,Compacted file可极大提升读取效率。
结合上图示例进一步描述查询细节:
-
图中TT2 Schema包含一个pk列和一个val列。左边图展示了数据变化过程,t1 - t5代表了5个事务的时间版本,分别执行了5次数据写入操作,生成了5个Delta file,在t2和t4时刻分别执行了Compact操作,生成了两个Compacted File: c1和c2,可见c1已经消除了中间状态历史记录(2,a),只保留最新状态的记录(2,b)。
-
如查询t1时刻的历史数据,只需读取Delta file (d1) 进行输出; 如查询t2时刻,只需读取Compacted file (c1) 输出其三条记录。如查询t3时刻,就会包含Compacted file (c1)以及Delta file (d3) 进行合并merge输出,可依此类推其他时刻的查询。可见,Compacted file文件虽可用来加速查询,但需要触发较重的Compact操作,用户需要结合自己的业务场景主动触发major compact,或者由后台系统自动触发compact操作。
-
Time travel查询设置的事务版本,支持时间版本和ID版本两种形态,SQL语法上除了可直接指定一些常量和常用函数外,还额外开发了get_latest_timestamp和get_latest_version两个函数,第二个参数代表它是最近第几次commit,方便用户获取MaxCompute内部的数据版本进行精准查询,提升用户体验。
▶ 增量查询
TT2表支持增量写入和存储,最重要的一个考虑就是支持增量查询以及增量计算链路,为此,也专门设计开发了新的SQL增量查询语法来支持近实时增量处理链路。用户通过增量查询语句可灵活构建增量数仓业务链路,近期正在规划开发支持增量物化视图来进一步简化使用门槛,提升用户体验,降低用户成本。
支持两种增量查询语法:
-
用户指定时间戳或者版本查询增量数据,详细语法参考官网,简单示例:
//查询2024-04-0101:00:00-01:10:00之间十分钟的增量数据
select * from tt2 timestampbetween'2024-04-01 01:00:00'and'2024-04-01 01:10:00';
//查询前10分钟到前5分钟之间的增量数据
select * from tt2 timestampbetweencurrent_timestamp() - 601andcurrent_timestamp() - 300;
//查询最近一次commit的增量数据
select * from tt2 timestampbetween get_latest_timestamp('tt2', 2) and get_latest_timestamp('tt2');-
引擎自动管理数据版本查询增量数据,不需要用户手动指定查询版本, 非常适合周期性的增量计算链路 (功能灰度发布中,以官网发布为准)。简单示例:
//绑定一个stream对象到tt2表上create stream tt2_stream ontable tt2;insertinto tt2 values (1, 'a'), (2, 'b');//自动查询出来新增的两条记录(1, 'a'), (2, 'b'), 并把下一次的查询版本更新到最新的数据版本insert overwrite dest select * from tt2_stream;insertinto tt2 values (3, 'c'), (4, 'd');//自动查询出来新增的两条记录(3, 'c'), (4, 'd')insert overwrite dest select * from tt2_stream;
-
增量查询处理过程简介

SQL引擎接收到用户侧输入的增量查询语法后,会先从Meta服务中解析出来要查询的历史增量数据版本,然后过滤出来要读取的Delta file列表,进行合并merge输出。
结合上图示例进一步描述查询细节:
-
图中表tt2 Schema包含一个pk列和一个val列。左边图展示了数据变化过程,t1 - t5代表了5个事务的时间版本,分别执行了5次数据写入操作,生成了5个Delta file,在t2和t4时刻分别执行了Compact操作,生成了两个Compacted File: c1和c2。
-
在具体的查询示例中,例如,begin是t1-1,end是t1,只需读取t1时间段对应的Delta file (d1)进行输出; 如果end是t2,会读取两个Delta files (d1, d2);如果begin是t1,end是t2-1,即查询的时间范围为(t1, t2),这个时间段是没有任何增量数据插入的,会返回空行。
-
Compact / Merge服务生成的数据(c1, c2)不会作为新增数据重复输出。
▶ PK 点查 DataSkipping 优化
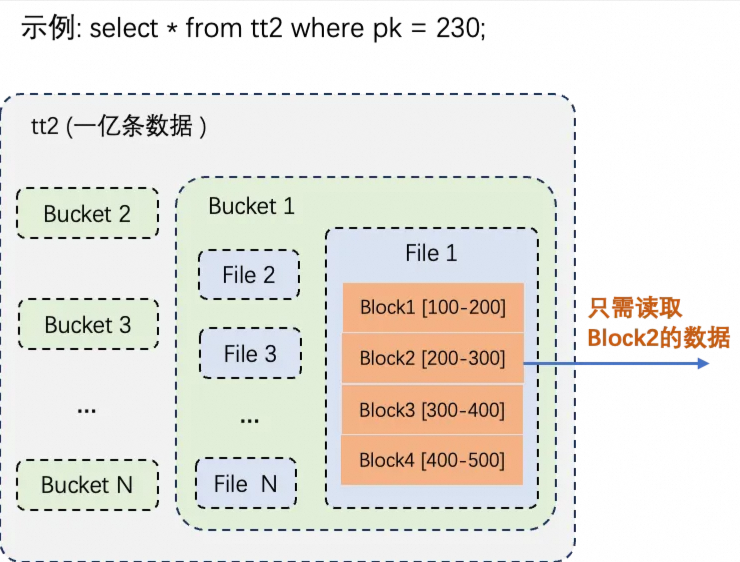
上文提到,TT2表的数据分布和索引基本是按照PK列值进行构建的,因此如果对TT2表进行点查,并指定了PK值进行过滤的话,将会极大减少要读取的数据量和读取耗时,资源消耗可能也会成百上千倍的减少。比如,TT2表总的数据记录是1亿,经过过滤后真正从数据文件中读取的数据记录可能只有一万条。
主要的DataSkipping优化包括:
-
先进行Bucket裁剪,只读取包含指定PK值的一个bucket即可;
-
在Bucket内部进行数据文件裁剪,只读取包含指定PK值的文件即可;
-
在文件内部进行Block裁剪,根据Block的PK值域范围进行过滤,只读取包含指定PK值的block即可。
遵循常规的SQL查询语法,简单示例:
select * from tt2 where pk = 1;▶ SQL查询分析Plan优化
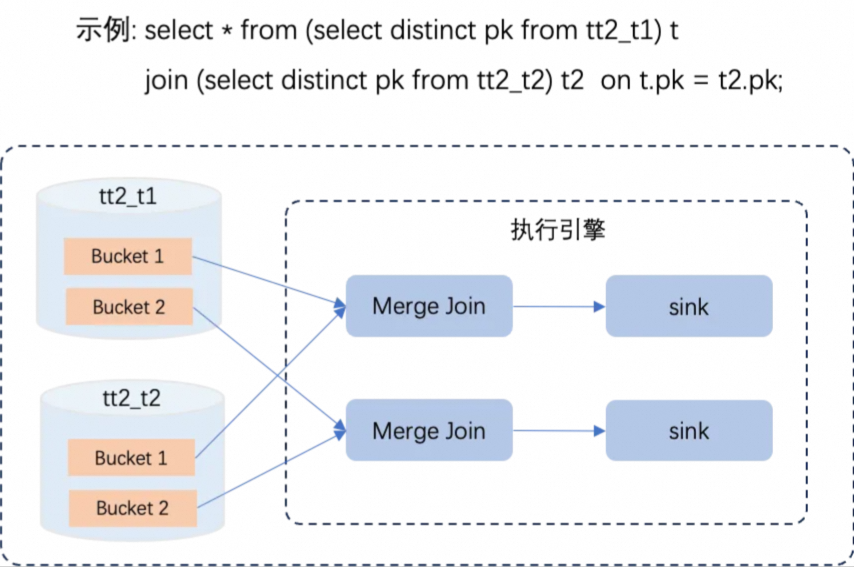
由于TT2表数据按照PK值进行分桶分布的,并且桶内部数据查询出来具备Unique属性和Sort有序性,因此SQL Optimizer利用这些属性可以做大量的优化。
比如图中示例的SQL语句 (假设tt2_t1和tt2_t2的桶数量相同),SQL Optimizer可做的主要优化如下:
-
Distinct的PK列本身具备的Unique属性,因此可以消除去重算子;
-
Join on key和PK列相同,因此直接使用Bucket Local Join即可,消除资源消耗很重的Shuffle过程;
-
由于每个桶读取出来的数据本身有序,因此可以直接使用MergeJoin算法,消除前置的Sort算子。
这些消除的算子都极为消耗资源,因此这些优化可整体让性能提升1倍以上。
遵循常规的SQL查询语法,简单示例:
select * from (selectdistinct pk from tt2_t1) tjoin (selectdistinct pk from tt2_t2) t2 on t.pk = t2.pk;
4. 数据库整库实时同步写入 MaxCompute
当前数据库和大数据处理引擎都有各自擅长的数据处理场景,部分复杂的业务场景同时需要OLTP/OLAP/离线分析引擎对数据进行分析处理,因此数据也需要在各个引擎之间流动。将数据库的单表或者整库的变更记录实时同步到MaxCompute进行分析处理是目前比较典型的业务链路。
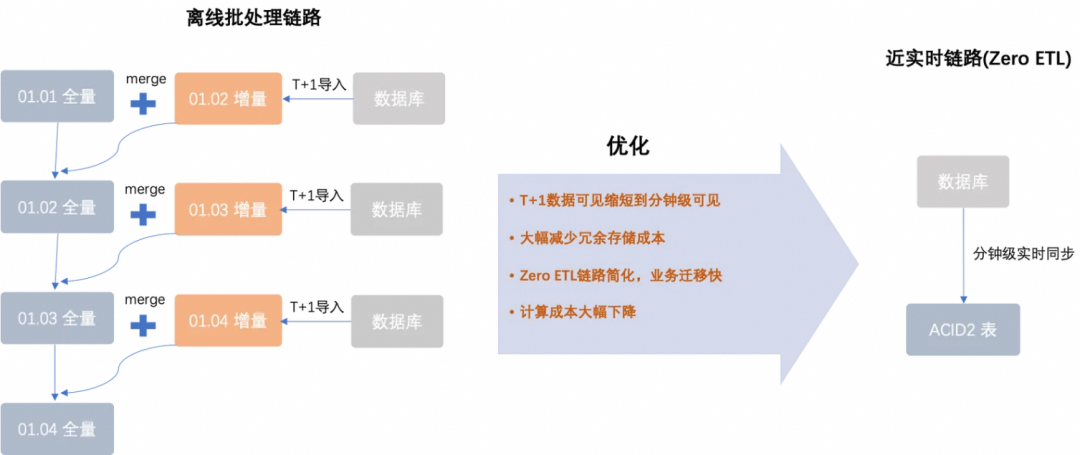
如上图所示,左边流程是之前MaxCompute支持此类场景的典型ETL处理链路,按照小时/天级别读取数据库的变更记录写入到MaxCompute一张临时的增量表中,然后将临时表和存量的全量表进行Join Merge处理,生成新的全量数据。此链路较复杂,并且延时较长,也会消耗一定的计算和存储成本。
右边流程则是使用新架构支持该场景,直接按照分钟级别实时读取数据库的变更记录upsert写入到TT2表即可。链路极简单,数据可见降低到分钟级,只需要一张TT2表即可,计算和存储成本降到最低。
目前MaxCompute集成了两种方式支持该链路:
-
通过DataWorks数据集成的整库/单表增全量实时同步任务,在页面进行任务配置即可。
优势
MaxCompute离线&近实时数仓一体化新架构会尽量覆盖部分近实时数据湖(HUDI/ICEBERG等)的通用功能,此外,作为完全自研设计的新架构,在低成本,功能,性能,稳定性,集成等方面也具备很多独特亮点:
-
用MaxCompute较低的成本来支持近实时以及增量链路,具备很高的性价比。
-
统一的存储、元数据、计算引擎一体化设计,做了非常深度和高效的集成,具备存储成本低,数据文件管理高效,查询效率高,并且Time travel / 增量查询可复用MaxCompute批量查询的大量优化规则等优势。
-
通用的全套SQL语法支持所有功能,非常便于用户使用。
-
深度定制优化的数据导入工具,高性能支持很多复杂的业务场景。
-
无缝衔接MaxCompute现有的业务场景,可以减少迁移、存储、计算成本。
-
表数据后台智能自动化治理和优化,保证更好的读写稳定性和性能,自动优化存储效率和成本。
-
基于MaxCompute平台完全托管,用户可以开箱即用,没有额外的接入成本,功能生效只需要创建一张TT2表即可。
生产现状和未来规划
整体功能邀测运行大概半年时间,单中国公共云已经超过100+ project, 700+张TT2表存在有效数据存储和读写,近实时链路和Upsert能力已经在部分客户的生产链路上得到充分验证。
未来半年规划:
-
支持CDC数据读写
-
支持增量物化视图
-
支持数据秒级可见
-
表数据服务智能治理深度优化以及查询性能优化