目录
1.什么是分布式文件系统
2.HDFS的特点
3.HDFS的核心概念
4.HDFS的体系结构
5.HDFS的配置建议
6.HDFS的局限性
7.HDFS的存储机制
7.1.数据冗余机制
7.2.错误与恢复
8.HDFS数据读写过程
1.什么是分布式文件系统
分布式文件系统是整个大数据技术的基础,是大数据技术栈的核心组件,其解决了海量数据的管理问题,可以说没有分布式文件系统就没有大数据技术。分布式文件系统是起源于Google,Google的分布式文件系统GFS奠定了分布式文件系统的设计思想,市面上目前所有的分布式文件系统都是参照GFS来设计实现的,包括HDFS也是。之前作者有一篇文章专门聊过GFS其中有分布式文件系统的来龙去脉,有兴趣可以移步:
【GFS】大数据技术的基石,分布式文件系统的鼻祖-CSDN博客
2.HDFS的特点
HDFS有以下特点:
-
能用廉价的设备来搞定
-
实现流数据读写(因为跑计算任务的时候,往往需要一次性把全部或者绝大多数数据读完,而不是只读一部分,所以HDFS实现了数据的顺序读写,从而实现了流数据读写)
-
支持各种量级的数据
-
只支持简单的数据操作,即只支持顺序读写、追加。不支持进行修改!
-
跨平台,因为是用JAVA开发的
HDFS存在的局限性:
-
不适合低延迟的数据访问,因为是顺序写入的,要读某一条具体的数据需要先顺序读出之前的数据。
-
无法高效存储大量小文件
-
不支持修改文件
3.HDFS的核心概念
块:
一个块默认64MB,其大小可以调整,但是不能调的过大,因为块过大后执行计算任务时计算引擎的并行性就没意义了,因为文件根本就没被分成几块,没被怎么分散的进行存储,可能就一两个子任务去跑一两个块去了,根本就并行计算不起来。
当客户端完成所有数据写入后,会通知NameNode所有的数据块都已经成功写入DataNode,并完成文件关闭操作,也就是说在逻辑上HDFS中一个块中存放的一定是一个文件,不可能一个块儿中存放着来自两个文件的内容。
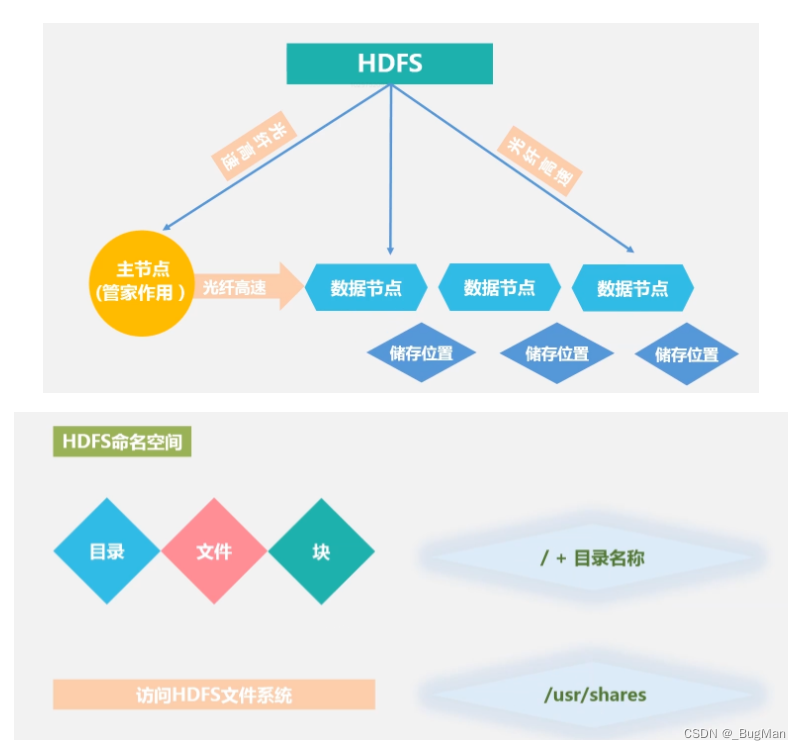
名称节点和数据节点:
名称节点上面负责维护整个集群中块儿的详细信息,块儿被存在哪儿?各自的顺序是什么?节点的状态和信息等内容。
数据节点什么负责进行具体的数据存储。
名称节点中记录的最核心的两大块内容:
-
FsImage,以树型的方式来记录整个集群中的文件相关信息,树上的每个节点包含文件的复制等级、修改和访问时间、访问权限、块大小以及组成文件的块。要注意,这颗树里面不包含哪些块存储在哪颗树上的这种对应关系。这种映射关系存放在内存中的另一种数据结构中的。
-
editLog,对文件的操作记录。
这两个东西拿来做什么喃?
HDFS中去名称节点上拿块儿所在位置的时候,先通过FsImage来定位文件由哪些块儿组成,然后再去找块儿和数据节点的对应关系,FsImage的存在加速了在NameNode上检索文件块位置的过程。FsImage当然是不能频繁更新的,因为其一定是要保持强一致性的,一旦进行更新,更新期间就会对外拒绝服务,影响系统的可用性。所以就需要editLog来记录集群中文件的操作,为了避免过大的EditLog对NameNode性能的影响,会有定期checkpoint(检查点)操作,将EditLog的部分内容合并到FsImage中,以此来减小EditLog的大小并刷新FsImage。
换句话说HDFS选择了最终一致性,而没有选择强一致性。
这会存在一个问题:万一在最终一致性发生之前,我要访问的文件有操作记录未被记录入FsImage中而是只存在于editLog中时怎么办?这种操作记录可能是这个文件就是新存入集群的,或者这个文件被删除了。
HDFS用了一种补偿机制来解决这种问题,首先我要访问的文件大概率是存在FsImage中的,在editlog中还没合过去只是小概率事件。所以HDFS会现在FsImage中找文件存在哪些块中,如果FsImage中没有,再去editLog中找有没有,这样就不会出现漏网之鱼。就是说当我们访问一个文件时一定是要走FsImage以及editLog的,要两份文件合起来才能确定文件的最终状态,只是说小概率会出现我们要访问的文件操作在editLog中,但是不在FsImage中对吧,所以其实没必要发现这种情况就立即进行合并,而是仍然可以在固定的时间再进行合并。
第二名称节点:
在早期版本的Hadoop中存在一个第二名称节点,在Hadoop 2.x及更高版本中,第二名称节点的功能已经被更加完善的组件取代。
第二名称节点是对名称节点的一个冷备,之所以说是冷备,是因为其并不同步名称节点的内存状态,也就是说并没有完整的元数据,其只负责定期从主NameNode下载FsImage和EditLog文件,合并FsImage和EditLog中的最新变更,然后将新的FsImage文件上传回主NameNode,以此来帮助主NameNode减少合并FsImage和EditLog所需的时间,减轻主NameNode的压力,防止EditLog过大,进而优化系统性能和稳定性。
元数据:
元数据的核心组成部分包括:
-
文件和目录的元数据:包括文件和目录的名称、路径、权限、所有权、创建时间、修改时间等基本属性信息。
-
块信息:不在fsimage上,而是在内存中,包括每个文件被切分成的块的数据块ID、块的大小以及块的副本数量等信息,以及每个数据块的所有副本在哪些DataNode上的映射关系,即块到节点的映射关系。
-
命名空间管理:维护整个文件系统的目录结构,即文件和目录的层级关系。
FsImage 和 EditLog 则是用于持久化和管理这些元数据的两种关键机制。
4.HDFS的体系结构
5.HDFS的配置建议
DataNode用来存数据和跑计算任务,因此其需要一定扽内存用来跑任务和大量的硬盘存储来存放数据,一般企业级应用建议DataNode的配置为:

NameNode用来存元数据,元数据是经常要用到的,所以存在内存中,所以NameNode的内存要够大,一般企业应用建议NameNode的配置为:

secondNameNode的配置和NameNode对齐。
6.HDFS的局限性
-
因为名称节点的元数据都是保存在内存中的,因此,名称节点能容纳的块的个数是有上限的。
-
集群的吞吐量受名称节点的吞吐量限制。
-
隔离问题,集群中只有一个名称节点,一个命名空间,无法对不同应用进行隔离。
-
容错性不高,因为名称节点是单点的,一旦故障,集群就崩了。
以上局限性完整存在于1.0版本中,2.0版本已经优化掉了一些。
7.HDFS的存储机制
7.1.数据冗余机制
因为是用廉价机器搭建起来的,出故障是常态,所以需要数据冗余机制来存储数据。HDFS中采用副本机制来进行冗余,默认副本数量为3个。
数据块进集群来,先复制成三个副本,副本一会被放在最优节点(磁盘占用最少)的节点上,然后副本二、副本三被放到不同的节点上。
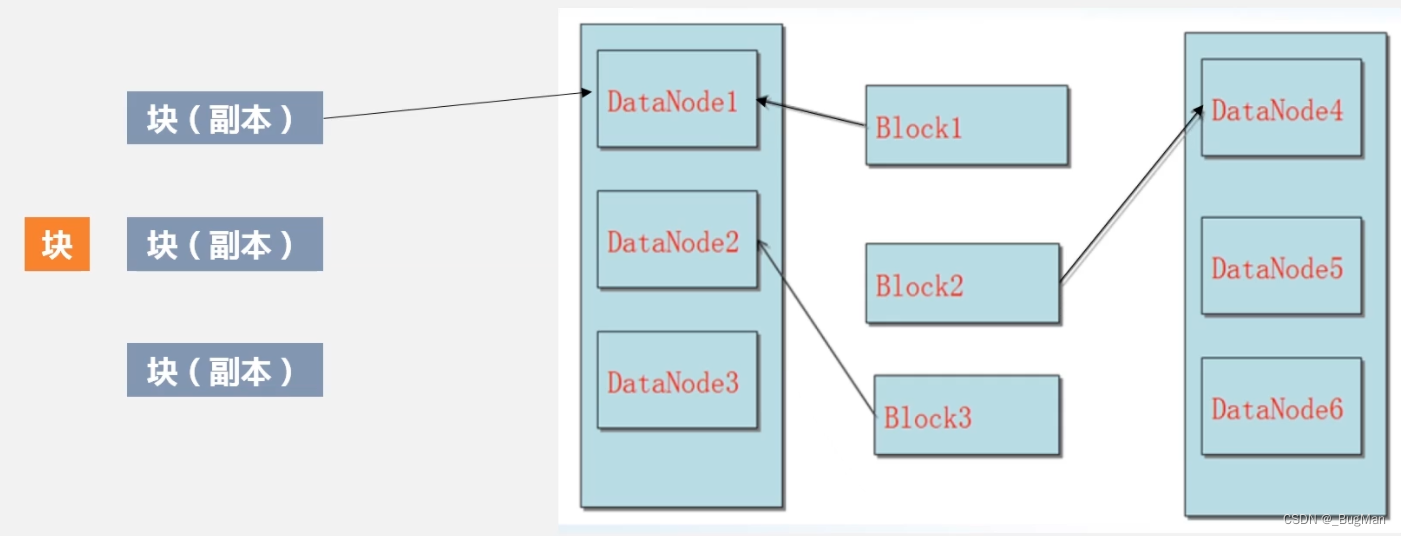
那么数据读取的时候会先读哪个喃?
HDFS提供了一个API来确定数据节点所在的机架ID,客户端可以调用API来获取自己所属的机架ID。当客户端读数据的时候可以通过这个API来决定要去读哪一个副本。这个机架ID不一定是物理上存在的,数据节点和机架ID之间的映射关系是可以配置的,就是个逻辑的代号,一般来说机架ID越小表示距离越近。
7.2.错误与恢复
HDFS中会出哪些错误?无非就三类:
-
名称节点出错
-
数据节点出错
-
数据本身出错
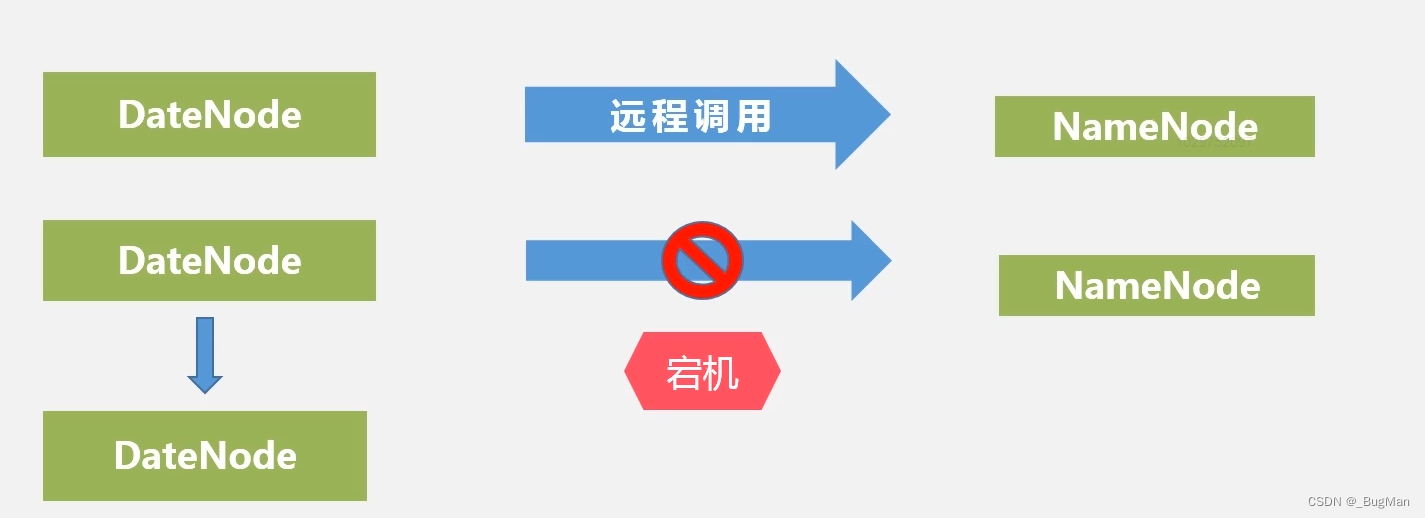
名称节点出错:
名称节点宕机,整个集群将对外拒绝提供服务,然后在1.0版本中需要重新将名称节点恢复正常,启动然后同第二名称节一起合作将元数据正确的恢复过来。在2.0版本中存在热备,直接会切热备,然后集群恢复工作。
数据节点出错:
数据节点是通过心跳来和名称节点上报自己还存活的,所以名称节点是能感知到数据节点是否存活的,如果名称节点发现有数据节点宕机了,会将其上面存储的数据复制到其它节点,注意不是从宕机的那台机器上复制,而是宕机那台机器上存储的数据在其他节点上一定还有备份,从其它节点上拉出来存到另外的节点上,维持数据副本的基数。
数据本身出错:
由于是用廉价机器组的集群,磁盘出错的概率是存在的,因此存在数据校验机制。每个数据块在被创建的时候都有一个校验码,读块数据的时候会通过校验码进行校验,要是发现不对,名称节点会从其它备份中将出问题的数据恢复过来。

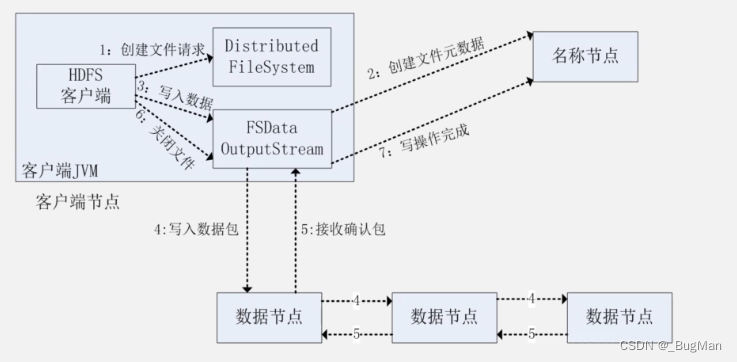
8.HDFS数据读写过程
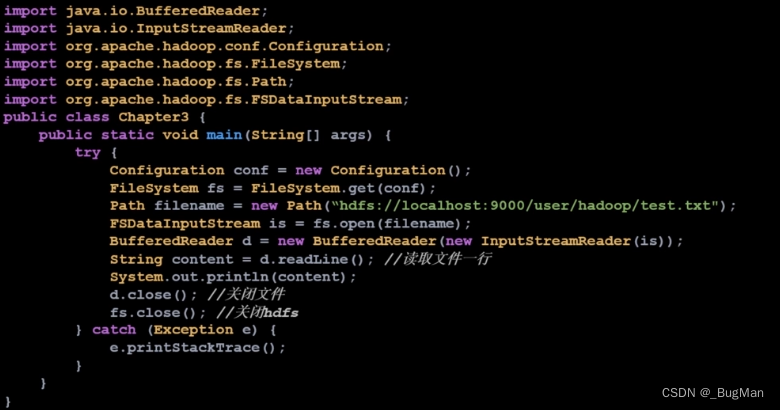
本文侧重于介绍HDFS的理论,所以这里只是简单结合JAVA API来过一下数据的读写过程,后面有文章会详细聊HDFS的操作和JAVA API。
读数据:

写数据:


![[沫忘录]MySQL索引](https://img-blog.csdnimg.cn/direct/7f9ad46b1ea24f779736bbf5fcf2d9be.png#pic_center)