提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- torch.nn.Sequential()快速搭建网络法
- 1 生成数据
- 2 快速搭建网络
- 3 训练、输出结果
- 总结
前言
本文内容还是基于4-pytorch前馈网络简单(分类)问题搭建这篇的相同例子,只是为了介绍另一种更加快速搭建网络的方法,看个人喜好用哪一种。
【注】:建议先看完上面链接的博客4,在来看本篇。
这里的这种搭建方法是使用**torch.nn.Sequential()**快速搭建,不用我们在继承重写net类了。
torch.nn.Sequential()快速搭建网络法
1 生成数据
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as npn_data = torch.ones(100,2)
x0 = torch.normal(2*n_data,1)
y0 = torch.zeros(100,1)
x1 = torch.normal(-2*n_data,1)
y1 = torch.ones(100,1)x = torch.cat((x0,x1),0)
# 在分类问题中标签必须用一维tensor,回归中则没有这个要求
y = torch.cat((y0,y1),0).reshape(-1)
# 在分类问题中标签还需要用torch.LongTensor类型
# 将张量 y 的类型转换为 long,这是因为在 PyTorch 中,分类问题的标签通常是整数类型(long),以便与模型输出的类别概率进行比较,从而计算损失。
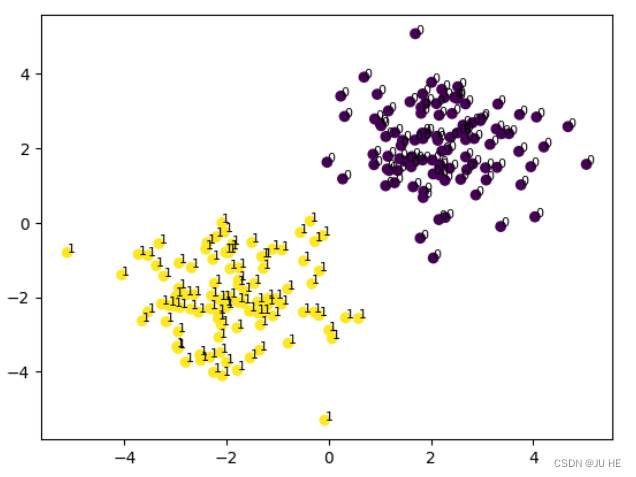
y = y.long()fig = plt.figure()
plt.scatter(x.data.numpy()[:,0],x.data.numpy()[:,1],c=y.data.numpy())
# 给画出来的每一个点标上标签,有点难看,注了吧
# 循环遍历每个数据点,根据其对应的标签添加标签文本
for i in range(len(x)):plt.text(x[i][0], x[i][1], str(int(y[i].item())), fontsize=8)
plt.show()
输出:
2 快速搭建网络
## 搭建网络method1
# class Net(torch.nn.Module):
# def __init__(self,n_features,n_hidden,n_output):
# # 继承原来结构体的全部init属性及方法
# super(Net,self).__init__()
# # 线性层就是全连接层
# self.hidden = torch.nn.Linear(n_features,n_hidden)
# self.predict = torch.nn.Linear(n_hidden,n_output)
#
# def forward(self,x):
# # 重写继承类的向前传播方法,就是在这个里面选择激活函数的
# x = F.relu(self.hidden(x))
# # 分类中输出层也可以不用激活函数,我们最后在对输出结果进行softmax处理
# x = self.predict(x)
# return x
#
# net = Net(2,10,2)
# # 输出层定义2个输出,对输出在进行softmax处理,取出概率最大的元素的下标就是我们分类的类别;与回归有所不同
# # 有点类似机器学习里面的独热编码
# print(net)## 快速搭建法,和前面注释掉的效果是一样的。
net = torch.nn.Sequential(torch.nn.Linear(2,10),torch.nn.ReLU(), # 这里激活函数大写了要torch.nn.Linear(10,2)
)
print(net)
输出:

3 训练、输出结果
optimizer = torch.optim.SGD(net.parameters(),lr=0.02)
# 分类用交叉熵损失函数
loss_func = torch.nn.CrossEntropyLoss()# 开启matplotlib的交换模式
plt.ion()
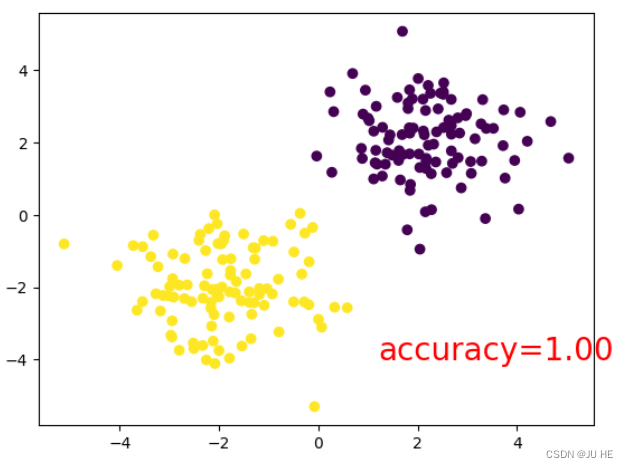
for t in range(100):# 这一步其实是调用了类里面的 __call__魔术方法,又学到一个魔术方法out = net(x)loss = loss_func(out,y)# 梯度清零optimizer.zero_grad()# 误差反向传播,求梯度loss.backward()# 进行优化器优化optimizer.step()if t%5 == 0:plt.cla()prediction = torch.max(F.softmax(out,1),1)[1]pred_y = prediction.data.numpy().reshape(-1)target_y = y.data.numpy().reshape(-1)plt.scatter(x.data.numpy()[:,0],x.data.numpy()[:,1],c=pred_y)accuracy = sum(pred_y==target_y)/200plt.text(1.2,-4,'accuracy=%.2f' % accuracy, fontdict={'size':20,'color':'red'})plt.pause(0.1)
# 关闭matplotlib的交换模式
plt.ioff()
plt.show()
输出:
# 输出out经softmax处理过后才变成概率
out2probability = F.softmax(out,1)
#print(out2probability.round(decimals=2))
# 取出概率向量里面概率最大的下标就是最终的分类结果
prediction = torch.max(F.softmax(out,1),1)[1]
print(prediction)在这里插入代码片
输出:

总结
选择那种方法搭建,看个人喜好,效果完全一样。