原文:
zh.annas-archive.org/md5/123a7612a4e578f6816d36f968cfec22译者:飞龙
协议:CC BY-NC-SA 4.0
第十一章:其他主题
在本章中,我们将讨论一些在本书前几章中没有涉及的主题。这些主题大多涉及不同的计算方式以及优化代码执行的其他方式。其他主题涉及处理特定类型的数据或文件格式。
在前两个内容中,我们将介绍帮助跟踪计算中的单位和不确定性的软件包。这些对于涉及具有直接物理应用的数据的计算非常重要。在下一个内容中,我们将讨论如何从 NetCDF 文件加载和存储数据。NetCDF 通常用于存储天气和气候数据的文件格式。(NetCDF 代表网络通用数据格式。)在第四个内容中,我们将讨论处理地理数据,例如可能与天气或气候数据相关的数据。之后,我们将讨论如何可以在不必启动交互式会话的情况下从终端运行 Jupyter 笔记本。接下来的两个内容涉及验证数据和处理从 Kafka 服务器流式传输的数据。我们最后两个内容涉及两种不同的方式,即使用诸如 Cython 和 Dask 等工具来加速我们的代码。
在本章中,我们将涵盖以下内容:
-
使用 Pint 跟踪单位
-
在计算中考虑不确定性
-
从 NetCDF 文件加载和存储数据
-
处理地理数据
-
将 Jupyter 笔记本作为脚本执行
-
验证数据
-
处理数据流
-
使用 Cython 加速代码
-
使用 Dask 进行分布式计算
让我们开始吧!
技术要求
由于本章包含的内容的性质,需要许多不同的软件包。我们需要的软件包列表如下:
-
Pint
-
不确定性
-
NetCDF4
-
xarray
-
GeoPandas
-
Geoplot
-
Papermill
-
Cerberus
-
Faust
-
Cython
-
Dask
所有这些软件包都可以使用您喜欢的软件包管理器(如pip)进行安装:
python3.8 -m pip install pint uncertainties netCDF4 xarray geopandasgeoplot papermill cerberus faust cython安装 Dask 软件包,我们需要安装与软件包相关的各种额外功能。我们可以在终端中使用以下pip命令来执行此操作:
python3.8 -m pip install dask[complete]除了这些 Python 软件包,我们还需要安装一些支持软件。对于处理地理数据的内容,GeoPandas 和 Geoplot 库可能需要单独安装许多低级依赖项。详细说明在 GeoPandas 软件包文档中给出,网址为geopandas.org/install.html。
对于处理数据流的内容,我们需要安装 Kafka 服务器。如何安装和运行 Kafka 服务器的详细说明可以在 Apache Kafka 文档页面上找到,网址为kafka.apache.org/quickstart。
对于Cython 加速代码的内容,我们需要安装 C 编译器。如何获取GNU C 编译器(GCC)的说明在 Cython 文档中给出,网址为cython.readthedocs.io/en/latest/src/quickstart/install.html。
本章的代码可以在 GitHub 存储库的Chapter 10文件夹中找到,网址为github.com/PacktPublishing/Applying-Math-with-Python/tree/master/Chapter%2010。
查看以下视频以查看代码的实际操作:bit.ly/2ZMjQVw。
使用 Pint 跟踪单位
在计算中正确跟踪单位可能非常困难,特别是在可以使用不同单位的地方。例如,很容易忘记在不同单位之间进行转换 – 英尺/英寸转换成米 – 或者公制前缀 – 比如将 1 千米转换成 1,000 米。
在这个内容中,我们将学习如何使用 Pint 软件包来跟踪计算中的测量单位。
准备工作
对于这个示例,我们需要 Pint 包,可以按如下方式导入:
import pint
如何做…
以下步骤向您展示了如何使用 Pint 包在计算中跟踪单位:
- 首先,我们需要创建一个
UnitRegistry对象:
ureg = pint.UnitRegistry(system="mks")
- 要创建带有单位的数量,我们将数字乘以注册对象的适当属性:
distance = 5280 * ureg.feet
- 我们可以使用其中一种可用的转换方法更改数量的单位:
print(distance.to("miles"))
print(distance.to_base_units())
print(distance.to_base_units().to_compact())
这些print语句的输出如下:
0.9999999999999999 mile
1609.3439999999998 meter
1.6093439999999999 kilometer
- 我们包装一个例程,使其期望以秒为参数并输出以米为结果:
@ureg.wraps(ureg.meter, ureg.second)
def calc_depth(dropping_time):# s = u*t + 0.5*a*t*t# u = 0, a = 9.81return 0.5*9.81*dropping_time*dropping_time
- 现在,当我们使用分钟单位调用
calc_depth例程时,它会自动转换为秒进行计算:
depth = calc_depth(0.05 * ureg.minute)
print("Depth", depth)
# Depth 44.144999999999996 meter
它是如何工作的…
Pint 包为数字类型提供了一个包装类,为类型添加了单位元数据。这个包装类型实现了所有标准的算术运算,并在这些计算过程中跟踪单位。例如,当我们将长度单位除以时间单位时,我们将得到速度单位。这意味着您可以使用 Pint 来确保在复杂计算后单位是正确的。
UnitRegistry对象跟踪会话中存在的所有单位,并处理不同单位类型之间的转换等问题。它还维护一个度量参考系统,在这个示例中是标准国际系统,以米、千克和秒作为基本单位,表示为mks。
wrap功能允许我们声明例程的输入和输出单位,这允许 Pint 对输入函数进行自动单位转换-在这个示例中,我们将分钟转换为秒。尝试使用没有关联单位或不兼容单位的数量调用包装函数将引发异常。这允许对参数进行运行时验证,并自动转换为例程的正确单位。
还有更多…
Pint 包带有一个大型的预设测量单位列表,涵盖了大多数全球使用的系统。单位可以在运行时定义或从文件加载。这意味着您可以定义特定于您正在使用的应用程序的自定义单位或单位系统。
单位也可以在不同的上下文中使用,这允许在不同单位类型之间轻松转换,这些单位类型通常是不相关的。这可以在需要在计算的多个点之间流畅地移动单位的情况下节省大量时间。
在计算中考虑不确定性
大多数测量设备并不是 100%准确的,通常只能准确到一定程度,通常在 0 到 10%之间。例如,温度计可能准确到 1%,而一对数字卡尺可能准确到 0.1%。在这两种情况下,报告的数值不太可能是真实值,尽管它会非常接近。跟踪数值的不确定性是困难的,特别是当您有多种不同的不确定性以不同的方式组合在一起时。与其手动跟踪这些,最好使用一个一致的库来为您完成。这就是uncertainties包的作用。
在这个示例中,我们将学习如何量化变量的不确定性,并看到这些不确定性如何通过计算传播。
准备工作
对于这个示例,我们将需要uncertainties包,我们将从中导入ufloat类和umath模块:
from uncertainties import ufloat, umath
如何做…
以下步骤向您展示了如何在计算中对数值的不确定性进行量化:
- 首先,我们创建一个不确定的浮点值为
3.0加减0.4:
seconds = ufloat(3.0, 0.4)
print(seconds) # 3.0+/-0.4
- 接下来,我们进行涉及这个不确定值的计算,以获得一个新的不确定值:
depth = 0.5*9.81*seconds*seconds
print(depth) # 44+/-12
- 接下来,我们创建一个新的不确定浮点值,并在与之前计算相反的方向上应用
umath模块的sqrt例程:
other_depth = ufloat(44, 12)
time = umath.sqrt(2.0*other_depth/9.81)
print("Estimated time", time)
# Estimated time 3.0+/-0.4
它是如何工作的…
ufloat类包装了float对象,并在整个计算过程中跟踪不确定性。该库利用线性误差传播理论,使用非线性函数的导数来估计计算过程中传播的误差。该库还正确处理相关性,因此从自身减去一个值会得到 0,没有误差。
要跟踪标准数学函数中的不确定性,您需要使用umath模块中提供的版本,而不是 Python 标准库或第三方包(如 NumPy)中定义的版本。
还有更多…
uncertainties包支持 NumPy,并且前面示例中提到的 Pint 包可以与不确定性结合使用,以确保正确地将单位和误差边界归因于计算的最终值。例如,我们可以从本示例的步骤 2中计算出计算的单位,如下所示:
import pint
from uncertainties import ufloat
g = 9.81*ureg.meters / ureg.seconds ** 2
seconds = ufloat(3.0, 0.4) * ureg.secondsdepth = 0.5*g*seconds**2
print(depth)
如预期的那样,最后一行的print语句给出了我们预期的44+/-12 米。
从 NetCDF 文件加载和存储数据
许多科学应用程序要求我们以稳健的格式开始大量的多维数据。NetCDF 是天气和气候行业用于开发数据的格式的一个例子。不幸的是,数据的复杂性意味着我们不能简单地使用 Pandas 包的实用程序来加载这些数据进行分析。我们需要netcdf4包来能够读取和导入数据到 Python 中,但我们还需要使用xarray。与 Pandas 库不同,xarray可以处理更高维度的数据,同时仍提供类似于 Pandas 的接口。
在这个示例中,我们将学习如何从 NetCDF 文件中加载数据并存储数据。
准备就绪
对于这个示例,我们需要导入 NumPy 包作为np,Pandas 包作为pd,Matplotlib pyplot模块作为plt,以及从 NumPy 导入默认随机数生成器的实例:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from numpy.random import default_rng
rng = default_rng(12345)
我们还需要导入xarray包并使用别名xr。您还需要安装 Dask 包,如“技术要求”部分所述,以及 NetCDF4 包:
import xarray as xr
我们不需要直接导入这两个包。
操作方法…
按照以下步骤加载和存储样本数据到 NetCDF 文件中:
- 首先,我们需要创建一些随机数据。这些数据包括一系列日期、位置代码列表和随机生成的数字:
dates = pd.date_range("2020-01-01", periods=365, name="date")
locations = list(range(25))
steps = rng.normal(0, 1, size=(365,25))
accumulated = np.add.accumulate(steps)
- 接下来,我们创建一个包含数据的 xarray
Dataset对象。日期和位置是索引,而steps和accumulated变量是数据:
data_array = xr.Dataset({"steps": (("date", "location"), steps),"accumulated": (("date", "location"), accumulated)},{"location": locations, "date": dates}
)
print(data_array)
print语句的输出如下所示:
<xarray.Dataset>
Dimensions: (date: 365, location: 25)
Coordinates:
* location (location) int64 0 1 2 3 4 5 6 7 8 ... 17 18 19 20 21 22 23 24
* date (date) datetime64[ns] 2020-01-01 2020-01-02 ... 2020-12-30
Data variables:
steps (date, location) float64 geoplot.pointplot(cities, ax=ax, fc="r", marker="2")
ax.axis((-180, 180, -90, 90))-1.424 1.264 ... -0.4547 -0.4873
accumulated (date, location) float64 -1.424 1.264 -0.8707 ... 8.935 -3.525
- 接下来,我们计算每个时间索引处所有位置的平均值:
means = data_array.mean(dim="location")
- 现在,我们在新的坐标轴上绘制平均累积值:
fig, ax = plt.subplots()
means["accumulated"].to_dataframe().plot(ax=ax)
ax.set(title="Mean accumulated values", xlabel="date", ylabel="value")
生成的绘图如下所示:
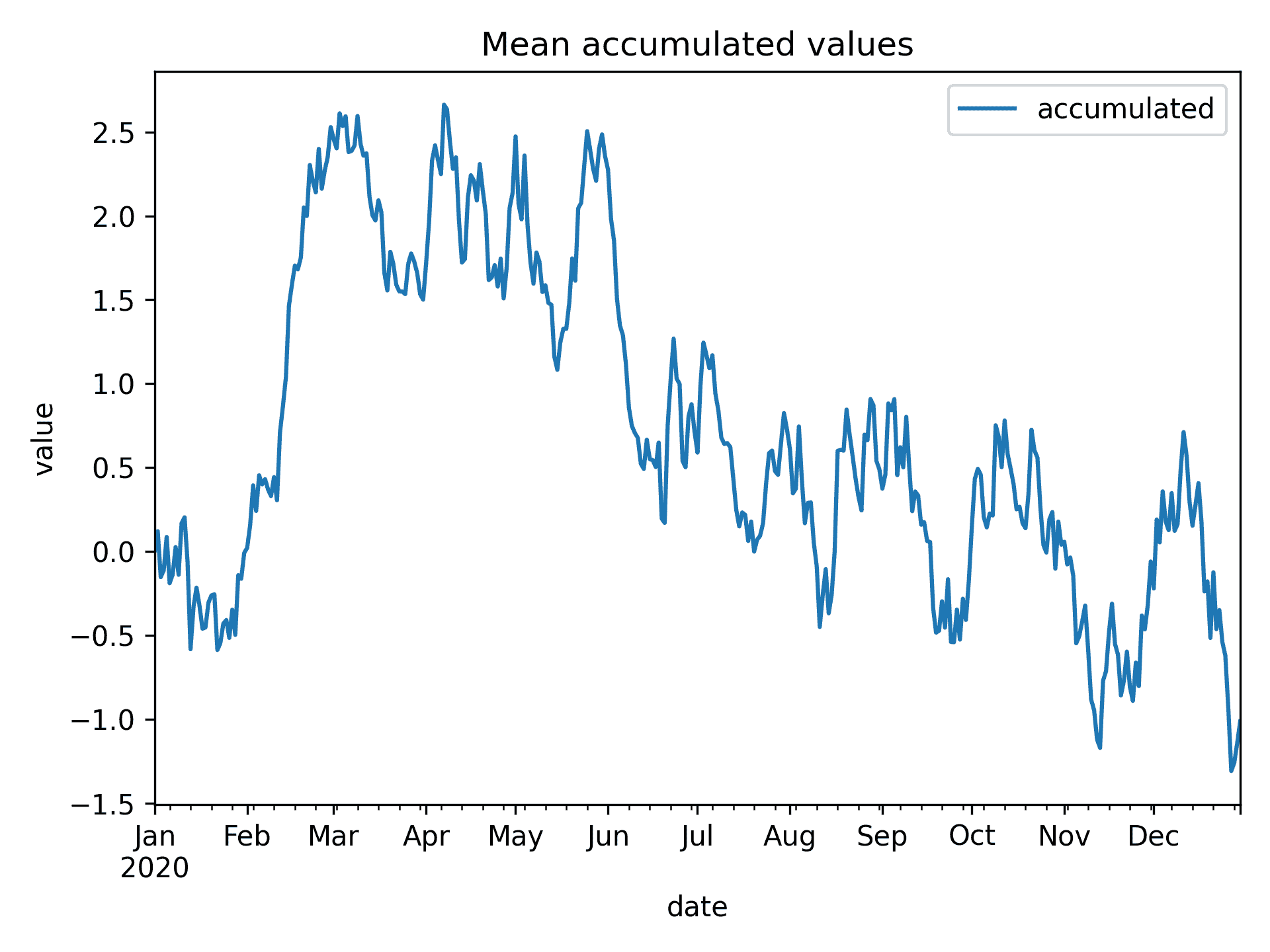 图 10.1:随时间累积平均值的绘图
图 10.1:随时间累积平均值的绘图
- 使用
to_netcdf方法将此数据集保存到新的 NetCDF 文件中:
data_array.to_netcdf("data.nc")
- 现在,我们可以使用
xarray的load_dataset例程加载新创建的 NetCDF 文件:
new_data = xr.load_dataset("data.nc")
print(new_data)
前面代码的输出如下所示:
<xarray.Dataset>
Dimensions: (date: 365, location: 25)
Coordinates:* location (location) int64 0 1 2 3 4 5 6 7 8 ... 17 18 19 20 21 22 23 24* date (date) datetime64[ns] 2020-01-01 2020-01-02 ... 2020-12-30
Data variables:steps (date, location) float64 -1.424 1.264 ... -0.4547 -0.4873accumulated (date, location) float64 -1.424 1.264 -0.8707 ... 8.935 -3.525
工作原理…
xarray包提供了DataArray和DataSet类,它们(粗略地说)是 PandasSeries和DataFrame对象的多维等价物。在本例中,我们使用数据集,因为每个索引(日期和位置的元组)都与两个数据相关联。这两个对象都暴露了与它们的 Pandas 等价物类似的接口。例如,我们可以使用mean方法沿着其中一个轴计算平均值。DataArray和DataSet对象还有一个方便的方法,可以将其转换为 PandasDataFrame,称为to_dataframe。我们在这个示例中使用它将其转换为DataFrame进行绘图,这并不是真正必要的,因为xarray内置了绘图功能。
这个配方的真正重点是to_netcdf方法和load_dataset例程。前者将DataSet存储在 NetCDF 格式文件中。这需要安装 NetCDF4 包,因为它允许我们访问相关的 C 库来解码 NetCDF 格式的文件。load_dataset例程是一个通用的例程,用于从各种文件格式(包括 NetCDF,这同样需要安装 NetCDF4 包)将数据加载到DataSet对象中。
还有更多…
xarray包支持除 NetCDF 之外的许多数据格式,如 OPeNDAP、Pickle、GRIB 和 Pandas 支持的其他格式。
处理地理数据
许多应用涉及处理地理数据。例如,当跟踪全球天气时,我们可能希望在地图上以各种传感器在世界各地的位置测量的温度为例进行绘图。为此,我们可以使用 GeoPandas 包和 Geoplot 包,这两个包都允许我们操纵、分析和可视化地理数据。
在这个配方中,我们将使用 GeoPandas 和 Geoplot 包来加载和可视化一些样本地理数据。
准备工作
对于这个配方,我们需要 GeoPandas 包,Geoplot 包和 Matplotlib 的pyplot包作为plt导入:
import geopandas
import geoplot
import matplotlib.pyplot as plt
如何做…
按照以下步骤,使用样本数据在世界地图上创建首都城市的简单绘图:
- 首先,我们需要从 GeoPandas 包中加载样本数据,其中包含世界地理信息:
world = geopandas.read_file(geopandas.datasets.get_path("naturalearth_lowres")
)
- 接下来,我们需要加载包含世界各个首都城市名称和位置的数据:
cities = geopandas.read_file(geopandas.datasets.get_path("naturalearth_cities")
)
- 现在,我们可以创建一个新的图形,并使用
polyplot例程绘制世界地理的轮廓:
fig, ax = plt.subplots()
geoplot.polyplot(world, ax=ax)
- 最后,我们使用
pointplot例程在世界地图上添加首都城市的位置。我们还设置轴限制,以使整个世界可见:
geoplot.pointplot(cities, ax=ax, fc="r", marker="2")
ax.axis((-180, 180, -90, 90))
结果绘制的世界各国首都城市的位置如下:
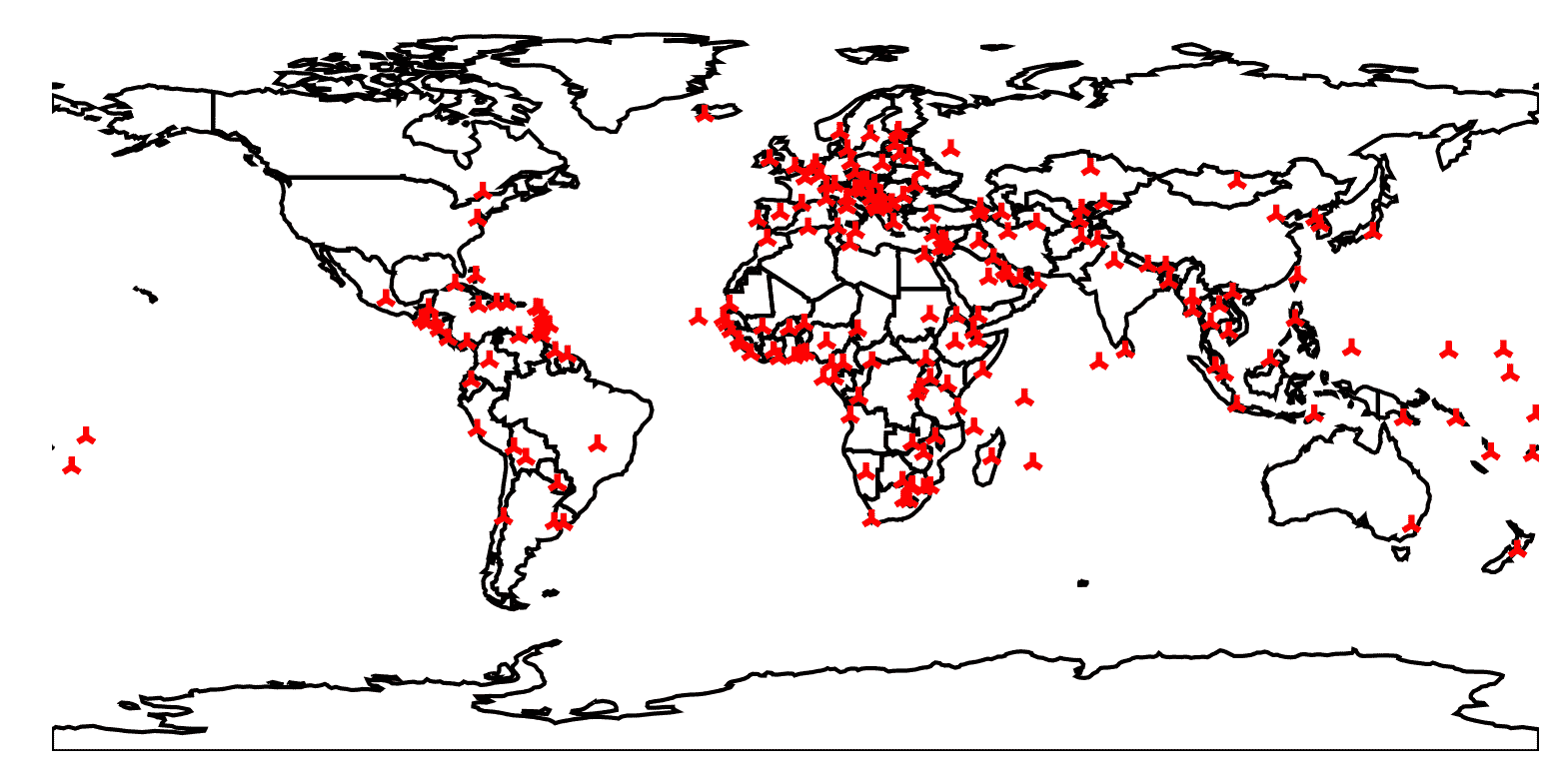 图 10.2:世界首都城市在地图上的绘图
图 10.2:世界首都城市在地图上的绘图
工作原理…
GeoPandas 包是 Pandas 的扩展,用于处理地理数据,而 Geoplot 包是 Matplotlib 的扩展,用于绘制地理数据。GeoPandas 包带有一些我们在这个配方中使用的样本数据集。naturalearth_lowres包含描述世界各国边界的几何图形。这些数据不是非常高分辨率,正如其名称所示,这意味着地理特征的一些细节可能在地图上不存在(一些小岛根本没有显示)。naturalearth_cities包含世界各国首都城市的名称和位置。我们使用datasets.get_path例程来检索包数据目录中这些数据集的路径。read_file例程将数据导入 Python 会话。
Geoplot 包提供了一些专门用于绘制地理数据的附加绘图例程。polyplot例程从 GeoPandas DataFrame 绘制多边形数据,该数据可能描述一个国家的地理边界。pointplot例程从 GeoPandas DataFrame 在一组轴上绘制离散点,这种情况下描述了首都城市的位置。
将 Jupyter 笔记本作为脚本执行
Jupyter 笔记本是用于编写科学和数据应用的 Python 代码的流行媒介。 Jupyter 笔记本实际上是一个以JavaScript 对象表示(JSON)格式存储在带有ipynb扩展名的文件中的块序列。每个块可以是多种不同类型之一,例如代码或标记。这些笔记本通常通过解释块并在后台内核中执行代码然后将结果返回给 Web 应用程序的 Web 应用程序访问。如果您在个人 PC 上工作,这很棒,但是如果您想在服务器上远程运行笔记本中包含的代码怎么办?在这种情况下,甚至可能无法访问 Jupyter 笔记本软件提供的 Web 界面。papermill 软件包允许我们从命令行参数化和执行笔记本。
在本教程中,我们将学习如何使用 papermill 从命令行执行 Jupyter 笔记本。
准备工作
对于本教程,我们需要安装 papermill 软件包,并且当前目录中需要有一个示例 Jupyter 笔记本。我们将使用本章的代码存储库中存储的sample.ipynb笔记本文件。
如何做…
按照以下步骤使用 papermill 命令行界面远程执行 Jupyter 笔记本:
- 首先,我们从本章的代码存储库中打开样本笔记本
sample.ipynb。笔记本包含三个代码单元格,其中包含以下代码:
import matplotlib.pyplot as plt
from numpy.random import default_rng
rng = default_rng(12345)uniform_data = rng.uniform(-5, 5, size=(2, 100))fig, ax = plt.subplots(tight_layout=True)
ax.scatter(uniform_data[0, :], uniform_data[1, :])
ax.set(title="Scatter plot", xlabel="x", ylabel="y")
- 接下来,我们在终端中打开包含 Jupyter 笔记本的文件夹并使用以下命令:
papermill --kernel python3 sample.ipynb output.ipynb- 现在,我们打开输出文件
output.ipynb,该文件现在应该包含已更新为执行代码结果的笔记本。在最终块中生成的散点图如下所示:
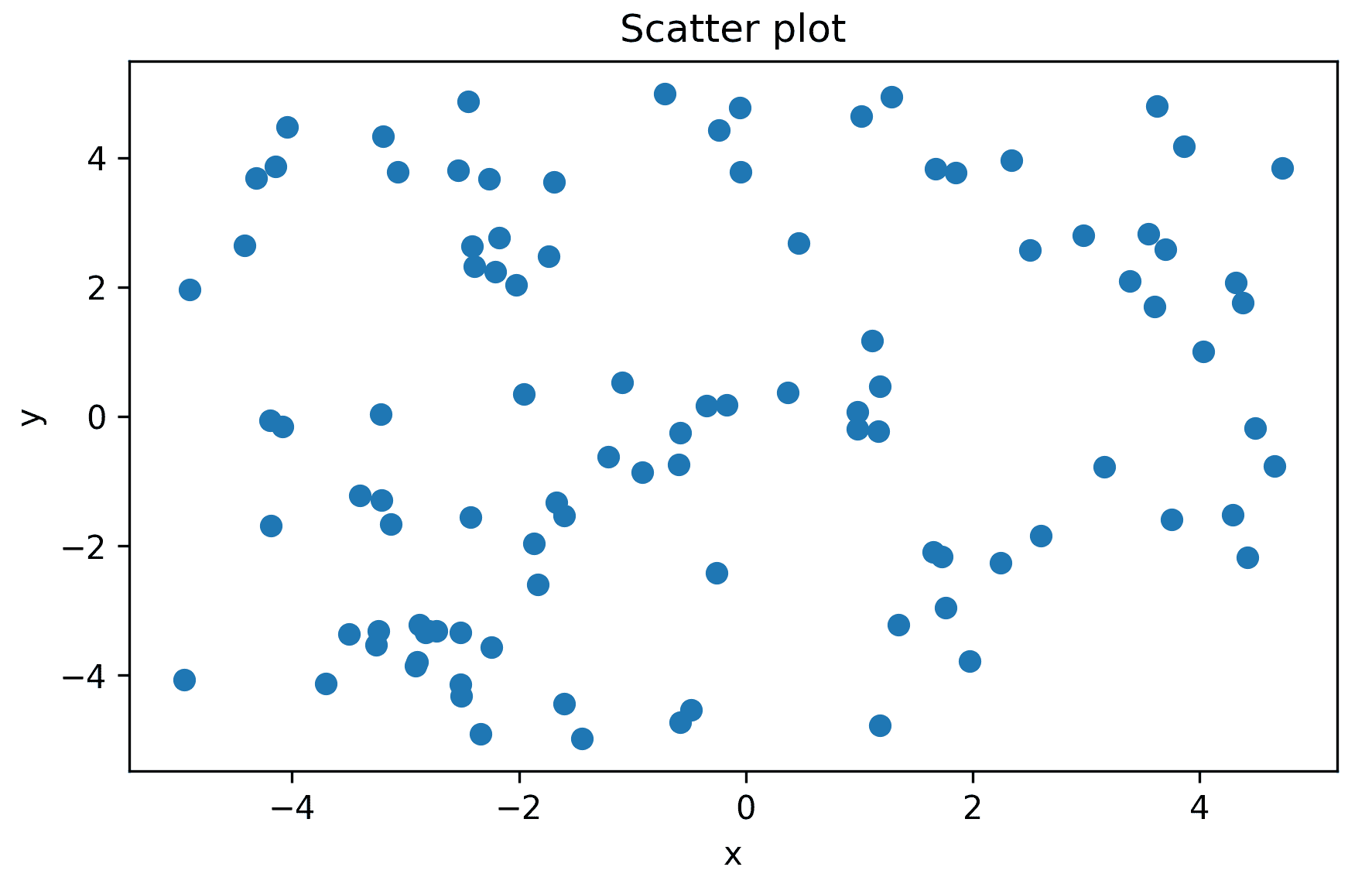
图 10.3:在远程使用 papermill 执行的 Jupyter 笔记本中生成的随机数据的散点图
它是如何工作的…
papermill 软件包提供了一个简单的命令行界面,用于解释和执行 Jupyter 笔记本,然后将结果存储在新的笔记本文件中。在本教程中,我们提供了第一个参数 - 输入笔记本文件 - sample.ipynb和第二个参数 - 输出笔记本文件 - output.ipynb。然后工具执行笔记本中包含的代码并生成输出。笔记本文件格式跟踪上次运行的结果,因此这些结果将添加到输出笔记本并存储在所需的位置。在本教程中,这是一个简单的本地文件,但是 papermill 也可以存储到云位置,例如Amazon Web Services(AWS)S3 存储或 Azure 数据存储。
在步骤 2中,我们在使用 papermill 命令行界面时添加了--kernel python3选项。此选项允许我们指定用于执行 Jupyter 笔记本的内核。如果 papermill 尝试使用与用于编写笔记本的内核不同的内核执行笔记本,则可能需要这样做以防止错误。可以使用以下命令在终端中找到可用内核的列表:
jupyter kernelspec list如果在执行笔记本时出现错误,您可以尝试切换到不同的内核。
还有更多…
Papermill 还具有 Python 接口,因此您可以从 Python 应用程序内执行笔记本。这对于构建需要能够在外部硬件上执行长时间计算并且结果需要存储在云中的 Web 应用程序可能很有用。它还具有向笔记本提供参数的能力。为此,我们需要在笔记本中创建一个标有默认值的参数标记的块。然后可以通过命令行界面使用-p标志提供更新的参数,后跟参数的名称和值。
验证数据
数据通常以原始形式呈现,可能包含异常或不正确或格式不正确的数据,这显然会给后续处理和分析带来问题。通常最好在处理管道中构建验证步骤。幸运的是,Cerberus 包为 Python 提供了一个轻量级且易于使用的验证工具。
对于验证,我们必须定义一个模式,这是关于数据应该如何以及应该对数据执行哪些检查的技术描述。例如,我们可以检查类型并设置最大和最小值的边界。Cerberus 验证器还可以在验证步骤中执行类型转换,这使我们可以将直接从 CSV 文件加载的数据插入验证器中。
在这个示例中,我们将学习如何使用 Cerberus 验证从 CSV 文件加载的数据。
准备工作
对于这个示例,我们需要从 Python 标准库中导入csv模块,以及 Cerberus 包:
import csv
import cerberus
我们还需要这一章的代码库中的sample.csv文件。
如何做…
在接下来的步骤中,我们将使用 Cerberus 包从 CSV 中加载的一组数据进行验证:
- 首先,我们需要构建描述我们期望的数据的模式。为此,我们必须为浮点数定义一个简单的模式:
float_schema = {"type": "float", "coerce": float, "min": -1.0,"max": 1.0}
- 接下来,我们为单个项目构建模式。这些将是我们数据的行:
item_schema = {"type": "dict","schema": {"id": {"type": "string"},"number": {"type": "integer", "coerce": int},"lower": float_schema,"upper": float_schema,}
}
- 现在,我们可以定义整个文档的模式,其中将包含一系列项目:
schema = {"rows": {"type": "list","schema": item_schema}
}
- 接下来,我们使用刚刚定义的模式创建一个
Validator对象:
validator = cerberus.Validator(schema)
- 然后,我们使用
csv模块中的DictReader加载数据:
with open("sample.csv") as f:dr = csv.DictReader(f)document = {"rows": list(dr)}
- 接下来,我们使用
Validator上的validate方法来验证文档:
validator.validate(document)
- 然后,我们从
Validator对象中检索验证过程中的错误:
errors = validator.errors["rows"][0]
- 最后,我们可以打印出任何出现的错误消息:
for row_n, errs in errors.items():print(f"row {row_n}: {errs}")
错误消息的输出如下:
row 11: [{'lower': ['min value is -1.0']}]
row 18: [{'number': ['must be of integer type', "field 'number' cannot be coerced: invalid literal for int() with base 10: 'None'"]}]
row 32: [{'upper': ['min value is -1.0']}]
row 63: [{'lower': ['max value is 1.0']}]
它是如何工作的…
我们创建的模式是对我们需要根据数据检查的所有标准的技术描述。这通常被定义为一个字典,其中项目的名称作为键,属性字典作为值,例如字典中的值的类型或值的边界。例如,在步骤 1中,我们为浮点数定义了一个模式,限制了数字的范围,使其在-1 和 1 之间。请注意,我们包括coerce键,该键指定在验证期间应将值转换为的类型。这允许我们传入从 CSV 文档中加载的数据,其中只包含字符串,而不必担心其类型。
Validator对象负责解析文档,以便对其进行验证,并根据模式描述的所有标准检查它们包含的数据。在这个示例中,我们在创建Validator对象时向其提供了模式。但是,我们也可以将模式作为第二个参数传递给validate方法。错误存储在一个嵌套字典中,其结构与文档的结构相似。
处理数据流
一些数据是从各种来源以恒定流的形式接收的。例如,我们可能会遇到多个温度探头通过 Kafka 服务器定期报告值的情况。Kafka 是一个流数据消息代理,根据主题将消息传递给不同的处理代理。
处理流数据是异步 Python 的完美应用。这使我们能够同时处理更大量的数据,这在应用程序中可能非常重要。当然,在异步上下文中我们不能直接对这些数据进行长时间的分析,因为这会干扰事件循环的执行。
使用 Python 的异步编程功能处理 Kafka 流时,我们可以使用 Faust 包。该包允许我们定义异步函数,这些函数将充当处理代理或服务,可以处理或以其他方式与来自 Kafka 服务器的数据流进行交互。
在这个食谱中,我们将学习如何使用 Faust 包来处理来自 Kafka 服务器的数据流。
准备工作
与本书中大多数食谱不同,由于我们将从命令行运行生成的应用程序,因此无法在 Jupyter 笔记本中运行此食谱。
对于这个食谱,我们需要导入 Faust 包:
import faust
我们还需要从 NumPy 包中运行默认随机数生成器的实例:
from numpy.random import default_rng
rng = default_rng(12345)
我们还需要在本地机器上运行 Kafka 服务的实例,以便我们的 Faust 应用程序可以与消息代理进行交互。
一旦您下载了 Kafka 并解压了下载的源代码,就导航到 Kafka 应用程序所在的文件夹。在终端中打开此文件夹。使用以下命令启动 ZooKeeper 服务器(适用于 Linux 或 Mac):
bin/zookeeper-server-start.sh config/zookeeper.properties如果您使用 Windows,改用以下命令:
bin\windows\zookeeper-server-start.bat config\zookeeper.properties然后,在一个新的终端中,使用以下命令启动 Kafka 服务器(适用于 Linux 或 Mac):
bin/kafka-server-start.sh config/server.properties如果您使用 Windows,改用以下命令:
bin\windows\kafka-server-start.bat config\server.properties在每个终端中,您应该看到一些日志信息,指示服务器正在运行。
操作步骤…
按照以下步骤创建一个 Faust 应用程序,该应用程序将读取(和写入)数据到 Kafka 服务器并进行一些简单的处理:
- 首先,我们需要创建一个 Faust
App实例,它将充当 Python 和 Kafka 服务器之间的接口:
app = faust.App("sample", broker="kafka://localhost")
- 接下来,我们将创建一个记录类型,模拟我们从服务器期望的数据:
class Record(faust.Record):id_string: strvalue: float
- 现在,我们将向 Faust
App对象添加一个主题,将值类型设置为我们刚刚定义的Record类:
topic = app.topic("sample-topic", value_type=Record)
- 现在,我们定义一个代理,这是一个包装在
App对象上的agent装饰器的异步函数:
@app.agent(topic)
async def process_record(records):async for record in records:print(f"Got {record.id_string}: {record.value}")
- 接下来,我们定义两个源函数,将记录发布到我们设置的样本主题的 Kafka 服务器上。这些是异步函数,包装在
timer装饰器中,并设置适当的间隔:
@app.timer(interval=1.0)
async def producer1(app):await app.send("sample-topic",value=Record(id_string="producer 1", value=rng.uniform(0, 2)))@app.timer(interval=2.0)
async def producer2(app):await app.send("sample-topic",value=Record(id_string="producer 2", value=rng.uniform(0, 5)))
- 在文件底部,我们启动应用程序的
main函数:
app.main()
- 现在,在一个新的终端中,我们可以使用以下命令启动应用程序的工作进程(假设我们的应用程序存储在
working-with-data-streams.py中):
python3.8 working-with-data-streams.py worker在这个阶段,您应该看到代理生成的一些输出被打印到终端中,如下所示:
[2020-06-21 14:15:27,986] [18762] [WARNING] Got producer 1: 0.4546720449343393
[2020-06-21 14:15:28,985] [18762] [WARNING] Got producer 2: 1.5837916985487643
[2020-06-21 14:15:28,989] [18762] [WARNING] Got producer 1: 1.5947309146654682
[2020-06-21 14:15:29,988] [18762] [WARNING] Got producer 1: 1.3525093415019491
这将是由 Faust 生成的一些应用程序信息的下方。
- 按下Ctrl + C关闭工作进程,并确保以相同的方式关闭 Kafka 服务器和 Zookeeper 服务器。
工作原理…
这是 Faust 应用程序的一个非常基本的示例。通常,我们不会生成记录并通过 Kafka 服务器发送它们,并在同一个应用程序中处理它们。但是,这对于本演示来说是可以的。在生产环境中,我们可能会连接到远程 Kafka 服务器,该服务器连接到多个来源并同时发布到多个不同的主题。
Faust 应用程序控制 Python 代码与 Kafka 服务器之间的交互。我们使用agent装饰器添加一个函数来处理发布到特定通道的信息。每当新数据被推送到样本主题时,将执行此异步函数。在这个食谱中,我们定义的代理只是将Record对象中包含的信息打印到终端中。
timer装饰器定义了一个服务,定期在指定的间隔执行某些操作。在我们的情况下,计时器通过App对象向 Kafka 服务器发送消息。然后将这些消息推送给代理进行处理。
Faust 命令行界面用于启动运行应用程序的工作进程。这些工作进程实际上是在 Kafka 服务器上或本地进程中对事件做出反应的处理者,例如本示例中定义的定时器服务。较大的应用程序可能会使用多个工作进程来处理大量数据。
此外
Faust 文档提供了有关 Faust 功能的更多详细信息,以及 Faust 的各种替代方案:faust.readthedocs.io/en/latest/。
有关 Kafka 的更多信息可以在 Apache Kafka 网站上找到:kafka.apache.org/。
使用 Cython 加速代码
Python 经常因为速度慢而受到批评——这是一个无休止的争论。使用具有 Python 接口的高性能编译库(例如科学 Python 堆栈)可以解决许多这些批评,从而大大提高性能。然而,在某些情况下,很难避免 Python 不是编译语言的事实。在这些(相当罕见的)情况下,改善性能的一种方法是编写 C 扩展(甚至完全重写代码为 C)以加速关键部分。这肯定会使代码运行更快,但可能会使维护软件包变得更加困难。相反,我们可以使用 Cython,这是 Python 语言的扩展,可以转换为 C 并编译以获得更好的性能改进。
例如,我们可以考虑一些用于生成 Mandelbrot 集图像的代码。为了比较,我们假设纯 Python 代码——我们假设这是我们的起点——如下所示:
# mandelbrot/python_mandel.pyimport numpy as npdef in_mandel(cx, cy, max_iter):x = cxy = cyfor i in range(max_iter):x2 = x**2y2 = y**2if (x2 + y2) >= 4:return iy = 2.0*x*y + cyx = x2 - y2 + cxreturn max_iterdef compute_mandel(N_x, N_y, N_iter):xlim_l = -2.5xlim_u = 0.5ylim_l = -1.2ylim_u = 1.2x_vals = np.linspace(xlim_l, xlim_u, N_x, dtype=np.float64)y_vals = np.linspace(ylim_l, ylim_u, N_y, dtype=np.float64)height = np.empty((N_x, N_y), dtype=np.int64)for i in range(N_x):for j in range(N_y):height[i, j] = in_mandel(x_vals[i], y_vals[j], N_iter)return height
纯 Python 中这段代码相对较慢的原因是相当明显的:嵌套循环。为了演示目的,让我们假设我们无法使用 NumPy 对这段代码进行矢量化。一些初步测试显示,使用这些函数生成 Mandelbrot 集的 320×240 点和 255 步大约需要 6.3 秒。您的时间可能会有所不同,这取决于您的系统。
在这个示例中,我们将使用 Cython 大大提高前面代码的性能,以生成 Mandelbrot 集图像。
准备工作
对于这个示例,我们需要安装 NumPy 包和 Cython 包。您还需要在系统上安装 GCC 等 C 编译器。例如,在 Windows 上,您可以通过安装 MinGW 来获取 GCC 的版本。
操作步骤
按照以下步骤使用 Cython 大大提高生成 Mandelbrot 集图像的代码性能:
- 在
mandelbrot文件夹中创建一个名为cython_mandel.pyx的新文件。在这个文件中,我们将添加一些简单的导入和类型定义:
# mandelbrot/cython_mandel.pyximport numpy as np
cimport numpy as np
cimport cython
ctypedef Py_ssize_t Int
ctypedef np.float64_t Double
- 接下来,我们使用 Cython 语法定义
in_mandel例程的新版本。我们在这个例程的前几行添加了一些声明:
cdef int in_mandel(Double cx, Double cy, int max_iter):cdef Double x = cxcdef Double y = cycdef Double x2, y2cdef Int i
- 函数的其余部分与 Python 版本的函数相同:
for i in range(max_iter):x2 = x**2y2 = y**2if (x2 + y2) >= 4:return iy = 2.0*x*y + cyx = x2 - y2 + cxreturn max_iter
- 接下来,我们定义
compute_mandel函数的新版本。我们向这个函数添加了 Cython 包的两个装饰器:
@cython.boundscheck(False)
@cython.wraparound(False)
def compute_mandel(int N_x, int N_y, int N_iter):
- 然后,我们像在原始例程中一样定义常量:
cdef double xlim_l = -2.5cdef double xlim_u = 0.5cdef double ylim_l = -1.2cdef double ylim_u = 1.2
- 我们使用 NumPy 包中的
linspace和empty例程的方式与 Python 版本完全相同。这里唯一的添加是我们声明了i和j变量,它们是Int类型的:
cdef np.ndarray x_vals = np.linspace(xlim_l, xlim_u, N_x, dtype=np.float64)cdef np.ndarray y_vals = np.linspace(ylim_l, ylim_u, N_y, dtype=np.float64)cdef np.ndarray height = np.empty((N_x, N_y), dtype=np.int64)cdef Int i, j
- 定义的其余部分与 Python 版本完全相同:
for i in range(N_x):for j in range(N_y):height[i, j] = in_mandel(x_vals[i], y_vals[j], N_iter)return height
- 接下来,在
mandelbrot文件夹中创建一个名为setup.py的新文件,并将以下导入添加到此文件的顶部:
# mandelbrot/setup.pyimport numpy as np
from setuptools import setup, Extension
from Cython.Build import cythonize
- 之后,我们使用指向原始
python_mandel.py文件的源定义一个扩展模块。将此模块的名称设置为hybrid_mandel:
hybrid = Extension("hybrid_mandel",sources=["python_mandel.py"],include_dirs=[np.get_include()],define_macros=[("NPY_NO_DEPRECATED_API", "NPY_1_7_API_VERSION")]
)
- 现在,我们定义第二个扩展模块,将源设置为刚刚创建的
cython_mandel.pyx文件:
cython = Extension("cython_mandel",sources=["cython_mandel.pyx"],include_dirs=[np.get_include()],define_macros=[("NPY_NO_DEPRECATED_API", "NPY_1_7_API_VERSION")]
)
- 接下来,将这两个扩展模块添加到列表中,并调用
setup例程来注册这些模块:
extensions = [hybrid, cython]
setup(ext_modules = cythonize(extensions, compiler_directives={"language_level": "3"}),
)
-
在
mandelbrot文件夹中创建一个名为__init__.py的新空文件,以便将其转换为可以在 Python 中导入的包。 -
在
mandelbrot文件夹中打开终端,并使用以下命令构建 Cython 扩展模块:
python3.8 setup.py build_ext --inplace- 现在,开始一个名为
run.py的新文件,并添加以下导入语句:
# run.pyfrom time import time
from functools import wraps
import matplotlib.pyplot as plt
- 从我们定义的每个模块中导入各种
compute_mandel例程:原始的python_mandel;Cython 化的 Python 代码hybrid_mandel;以及编译的纯 Cython 代码cython_mandel:
from mandelbrot.python_mandel import compute_mandel as compute_mandel_py
from mandelbrot.hybrid_mandel import compute_mandel as compute_mandel_hy
from mandelbrot.cython_mandel import compute_mandelas compute_mandel_cy
- 定义一个简单的计时器装饰器,我们将用它来测试例程的性能:
def timer(func, name):@wraps(func)def wrapper(*args, **kwargs):t_start = time()val = func(*args, **kwargs)t_end = time()print(f"Time taken for {name}: {t_end - t_start}")return valreturn wrapper
- 将
timer装饰器应用于每个导入的例程,并定义一些用于测试的常量:
mandel_py = timer(compute_mandel_py, "Python")
mandel_hy = timer(compute_mandel_hy, "Hybrid")
mandel_cy = timer(compute_mandel_cy, "Cython")Nx = 320
Ny = 240
steps = 255
- 用我们之前设置的常量运行每个装饰的例程。将最终调用(Cython 版本)的输出记录在
vals变量中:
mandel_py(Nx, Ny, steps)
mandel_hy(Nx, Ny, steps)
vals = mandel_cy(Nx, Ny, steps)
- 最后,绘制 Cython 版本的输出,以检查例程是否正确计算了 Mandelbrot 集:
fig, ax = plt.subplots()
ax.imshow(vals.T, extent=(-2.5, 0.5, -1.2, 1.2))
plt.show()
运行run.py文件将在终端打印每个例程的执行时间,如下所示:
Time taken for Python: 6.276328802108765
Time taken for Hybrid: 5.816391468048096
Time taken for Cython: 0.03116750717163086
Mandelbrot 集的绘图可以在以下图像中看到:
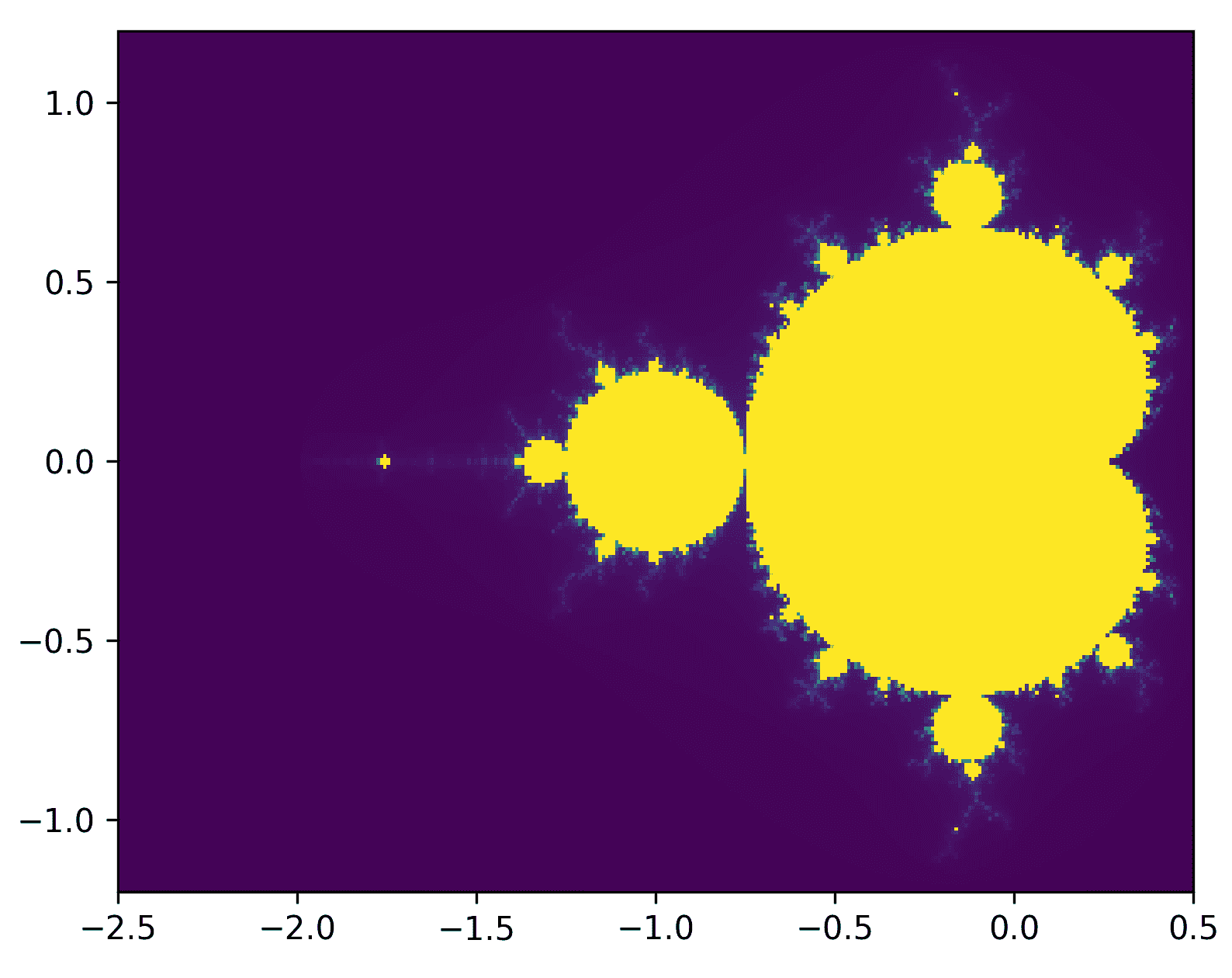 图 10.4:使用 Cython 代码计算的 Mandelbrot 集的图像
图 10.4:使用 Cython 代码计算的 Mandelbrot 集的图像
这是我们对 Mandelbrot 集的期望。
它是如何工作的…
在这个示例中发生了很多事情,所以让我们从解释整个过程开始。Cython 接受用 Python 语言的扩展编写的代码,并将其编译成 C 代码,然后用于生成可以导入 Python 会话的 C 扩展库。实际上,您甚至可以使用 Cython 直接将普通 Python 代码编译为扩展,尽管结果不如使用修改后的语言好。在这个示例中的前几个步骤中,我们在修改后的语言中定义了 Python 代码的新版本(保存为.pyx文件),其中包括类型信息以及常规 Python 代码。为了使用 Cython 构建 C 扩展,我们需要定义一个设置文件,然后创建一个文件来生成结果。
Cython 代码的最终编译版本比其 Python 等效代码运行速度快得多。Cython 编译的 Python 代码(在本示例中称为混合代码)的性能略优于纯 Python 代码。这是因为生成的 Cython 代码仍然必须处理带有所有注意事项的 Python 对象。通过在.pyx文件中向 Python 代码添加类型信息,我们开始看到性能的重大改进。这是因为in_mandel函数现在有效地被定义为一个 C 级别函数,它不与 Python 对象交互,而是操作原始数据类型。
Cython 代码和 Python 等效代码之间存在一些小但非常重要的区别。在步骤 1中,您可以看到我们像往常一样导入了 NumPy 包,但我们还使用了cimport关键字将一些 C 级别的定义引入了作用域。在步骤 2中,我们在定义in_mandel例程时使用了cdef关键字而不是def关键字。这意味着in_mandel例程被定义为一个 C 级别函数,不能从 Python 级别使用,这在调用这个函数时(这经常发生)节省了大量开销。
关于这个函数定义的唯一其他真正的区别是在签名和函数的前几行中包含了一些类型声明。我们在这里应用的两个装饰器禁用了访问列表(数组)元素时的边界检查。boundscheck装饰器禁用了检查索引是否有效(在 0 和数组大小之间),而wraparound装饰器禁用了负索引。尽管它们禁用了 Python 内置的一些安全功能,但这两个装饰器在执行过程中都会对速度产生适度的改进。在这个示例中,禁用这些检查是可以的,因为我们正在使用循环遍历数组的有效索引。
设置文件是我们告诉 Python(因此也是 Cython)如何构建 C 扩展的地方。Cython 中的cythonize例程在这里起着关键作用,因为它触发了 Cython 构建过程。在步骤 9和10中,我们使用setuptools中的Extension类定义了扩展模块,以便我们可以为构建定义一些额外的细节;具体来说,我们为 NumPy 编译设置了一个环境变量,并添加了 NumPy C 头文件的include文件。这是通过Extension类的define_macros关键字参数完成的。我们在步骤 13中使用setuptools命令来构建 Cython 扩展,并且添加了--inplace选项,这意味着编译后的库将被添加到当前目录,而不是放在一个集中的位置。这对开发来说是很好的。
运行脚本相当简单:从每个定义的模块中导入例程 - 其中两个实际上是 C 扩展模块 - 并计算它们的执行时间。我们必须在导入别名和例程名称上有一些创造性,以避免冲突。
还有更多…
Cython 是改进代码性能的强大工具。然而,在优化代码时,您必须始终谨慎地花费时间。使用像 Python 标准库中提供的 cProfiler 这样的性能分析工具可以用来找到代码中性能瓶颈出现的地方。在这个示例中,性能瓶颈出现的地方是相当明显的。在这种情况下,Cython 是解决问题的良药,因为它涉及对(双重)for循环内的函数进行重复调用。然而,它并不是解决性能问题的通用方法,往往情况下,通过重构代码以利用高性能库,可以大大提高代码的性能。
Cython 与 Jupyter 笔记本集成良好,并且可以无缝地在笔记本的代码块中使用。Cython 也包含在 Python 的 Anaconda 发行版中,因此在使用 Anaconda 发行版安装了 Cython 后,就无需额外设置即可在 Jupyter 笔记本中使用 Cython。
在从 Python 生成编译代码时,Cython 并不是唯一的选择。例如,NumBa 包(numba.pydata.org/)提供了一个即时(JIT)编译器,通过简单地在特定函数上放置装饰器来优化 Python 代码的运行时。NumBa 旨在与 NumPy 和其他科学 Python 库一起使用,并且还可以用于利用 GPU 加速代码。
使用 Dask 进行分布式计算
Dask 是一个用于在多个线程、进程或甚至计算机之间进行分布式计算的库,以有效地进行大规模计算。即使您只是在一台笔记本电脑上工作,这也可以极大地提高性能和吞吐量。Dask 提供了 Python 科学堆栈中大多数数据结构的替代品,如 NumPy 数组和 Pandas DataFrames。这些替代品具有非常相似的接口,但在内部,它们是为分布式计算而构建的,以便它们可以在多个线程、进程或计算机之间共享。在许多情况下,切换到 Dask 就像改变import语句一样简单,可能还需要添加一些额外的方法调用来启动并发计算。
在这个示例中,我们将学习如何使用 Dask 对 DataFrame 进行一些简单的计算。
准备工作
对于这个示例,我们需要从 Dask 包中导入dataframe模块。按照 Dask 文档中的约定,我们将使用别名dd导入此模块:
import dask.dataframe as dd
我们还需要这一章的代码库中的sample.csv文件。
如何做…
按照以下步骤使用 Dask 对 DataFrame 对象执行一些计算:
- 首先,我们需要将数据从
sample.csv加载到 Dask 的DataFrame中:
data = dd.read_csv("sample.csv")
- 接下来,我们对 DataFrame 的列执行标准计算:
sum_data = data.lower + data.upper
print(sum_data)
与 Pandas DataFrames 不同,结果不是一个新的 DataFrame。print语句给了我们以下信息:
Dask Series Structure:
npartitions=1float64...
dtype: float64
Dask Name: add, 6 tasks
- 要实际获得结果,我们需要使用
compute方法:
result = sum_data.compute()
print(result.head())
结果现在如预期所示:
0 -0.911811
1 0.947240
2 -0.552153
3 -0.429914
4 1.229118
dtype: float64
- 我们计算最后两列的均值的方式与 Pandas DataFrame 完全相同,但我们需要添加一个调用
compute方法来执行计算:
means = data.loc[:, ("lower", "upper")].mean().compute()
print(means)
打印的结果与我们的预期完全一致:
lower -0.060393
upper -0.035192
dtype: float64
它是如何工作的…
Dask 为计算构建了一个任务图,描述了需要对数据集合执行的各种操作和计算之间的关系。这样可以将计算步骤分解,以便可以按正确的顺序在不同的工作器之间进行计算。然后将此任务图传递给调度程序,调度程序将实际任务发送给工作器执行。Dask 配备了几种不同的调度程序:同步、线程、多进程和分布式。可以在compute方法的调用中选择调度程序的类型,或者全局设置。如果没有给出一个合理的默认值,Dask 会选择一个合理的默认值。
同步、线程和多进程调度程序在单台机器上工作,而分布式调度程序用于与集群一起工作。Dask 允许您以相对透明的方式在调度程序之间切换,尽管对于小任务,您可能不会因为设置更复杂的调度程序而获得任何性能优势。
compute方法是这个示例的关键。通常会在 Pandas DataFrames 上执行计算的方法现在只是设置了一个通过 Dask 调度程序执行的计算。直到调用compute方法之前,计算才会开始。这类似于Future作为异步函数调用结果的代理返回,直到计算完成才会实现。
还有更多…
Dask 提供了 NumPy 数组的接口,以及本示例中显示的 DataFrames。还有一个名为dask_ml的机器学习接口,它提供了类似于 scikit-learn 包的功能。一些外部包,如xarray,也有 Dask 接口。Dask 还可以与 GPU 一起工作,以进一步加速计算并从远程源加载数据,这在计算分布在集群中时非常有用。