一、前言
早前的文章,我们都是通过输入命令的方式来使用Chatglm3-6b模型。现在,我们可以通过使用Streamlit,通过一个界面与模型进行交互。这样做可以减少重复加载模型和修改代码的麻烦,
让我们更方便地体验模型的效果。
开源模型应用落地-chatglm3-6b-gradio-入门篇(七)
二、术语
2.1、Streamlit
Streamlit是一个开源库,它专注于构建数据科学和机器学习应用程序的用户界面。它提供了一个简单的API,可以让开发者使用Python快速创建交互式应用程序。使用Streamlit,您可以轻松地将数据、图表和模型展示给用户,并与用户进行实时交互。
Streamlit VS Gradio
Streamlit和Gradio的区别在于它们的设计重点和功能特性。Streamlit提供了更多的灵活性和自定义选项,使开发者能够更好地控制应用程序的外观和行为。它还提供了更多的部署选项和扩展功能,使开发者能够将应用程序部署到更多的环境中。
Gradio更注重简单易用和快速原型开发。它提供了自动生成界面的功能,无需太多的编码工作即可创建一个交互式应用程序。Gradio的设计目标是提供一个轻量级、易于上手的工具,使开发者能够快速构建和共享应用程序原型。
三、前置条件
3.1. windows or linux操作系统均可
3.2. 下载chatglm3-6b模型
从huggingface下载:https://huggingface.co/THUDM/chatglm3-6b/tree/main
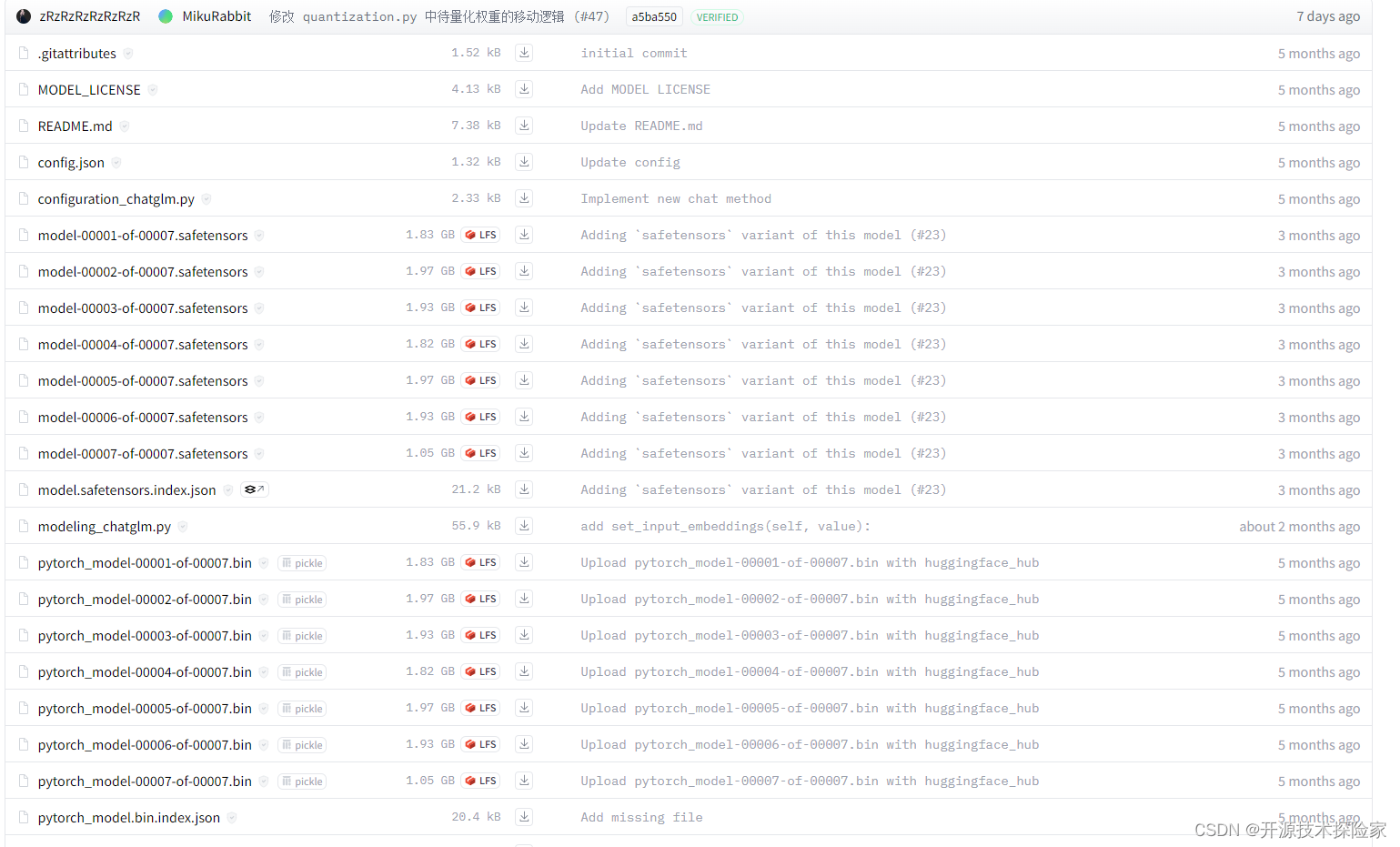
从魔搭下载:魔搭社区汇聚各领域最先进的机器学习模型,提供模型探索体验、推理、训练、部署和应用的一站式服务。https://www.modelscope.cn/models/ZhipuAI/chatglm3-6b/fileshttps://www.modelscope.cn/models/ZhipuAI/chatglm3-6b/files
3.3. 创建虚拟环境&安装依赖
conda create --name chatglm3 python=3.10
conda activate chatglm3
pip install protobuf transformers==4.39.3 cpm_kernels torch>=2.0 sentencepiece accelerate
pip install streamlit
四、技术实现
4.1.示例代码
# -*- coding = utf-8 -*-import streamlit as st
import torch
from transformers import AutoModelForCausalLM, AutoTokenizermodelPath = "/model/chatglm3-6b"def loadTokenizer():tokenizer = AutoTokenizer.from_pretrained(modelPath, use_fast=False, trust_remote_code=True)return tokenizerdef loadModel():model = AutoModelForCausalLM.from_pretrained(modelPath, device_map="auto", trust_remote_code=True).cuda()model = model.eval()return modelst.set_page_config(page_title="ChatGLM3-6B Streamlit Simple Demo",page_icon=":robot:",layout="wide"
)@st.cache_resource
def get_model():tokenizer = loadTokenizer()model = loadModel()return tokenizer, model# 加载Chatglm3的model和tokenizer
tokenizer, model = get_model()if "history" not in st.session_state:st.session_state.history = []
if "past_key_values" not in st.session_state:st.session_state.past_key_values = Nonemax_length = st.sidebar.slider("max_length", 0, 32768, 8192, step=1)
top_p = st.sidebar.slider("top_p", 0.0, 1.0, 0.8, step=0.01)
temperature = st.sidebar.slider("temperature", 0.0, 1.0, 0.6, step=0.01)buttonClean = st.sidebar.button("清理会话历史", key="clean")
if buttonClean:st.session_state.history = []st.session_state.past_key_values = Noneif torch.cuda.is_available():torch.cuda.empty_cache()st.rerun()for i, message in enumerate(st.session_state.history):if message["role"] == "user":with st.chat_message(name="user", avatar="user"):st.markdown(message["content"])else:with st.chat_message(name="assistant", avatar="assistant"):st.markdown(message["content"])with st.chat_message(name="user", avatar="user"):input_placeholder = st.empty()
with st.chat_message(name="assistant", avatar="assistant"):message_placeholder = st.empty()prompt_text = st.chat_input("请输入您的问题")
if prompt_text:input_placeholder.markdown(prompt_text)history = st.session_state.historypast_key_values = st.session_state.past_key_valuesfor response, history, past_key_values in model.stream_chat(tokenizer,prompt_text,history,past_key_values=past_key_values,max_length=max_length,top_p=top_p,temperature=temperature,return_past_key_values=True,):message_placeholder.markdown(response)st.session_state.history = historyst.session_state.past_key_values = past_key_values4.2.启动命令
streamlit run chatglm3_6b_streamlit.py --server.port 8989调用结果:
启动成功:
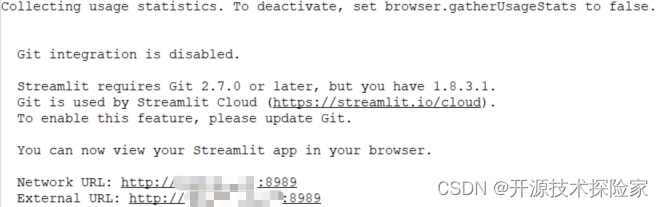
浏览器首次访问:
(1) 加载模型

(2) 加载完成
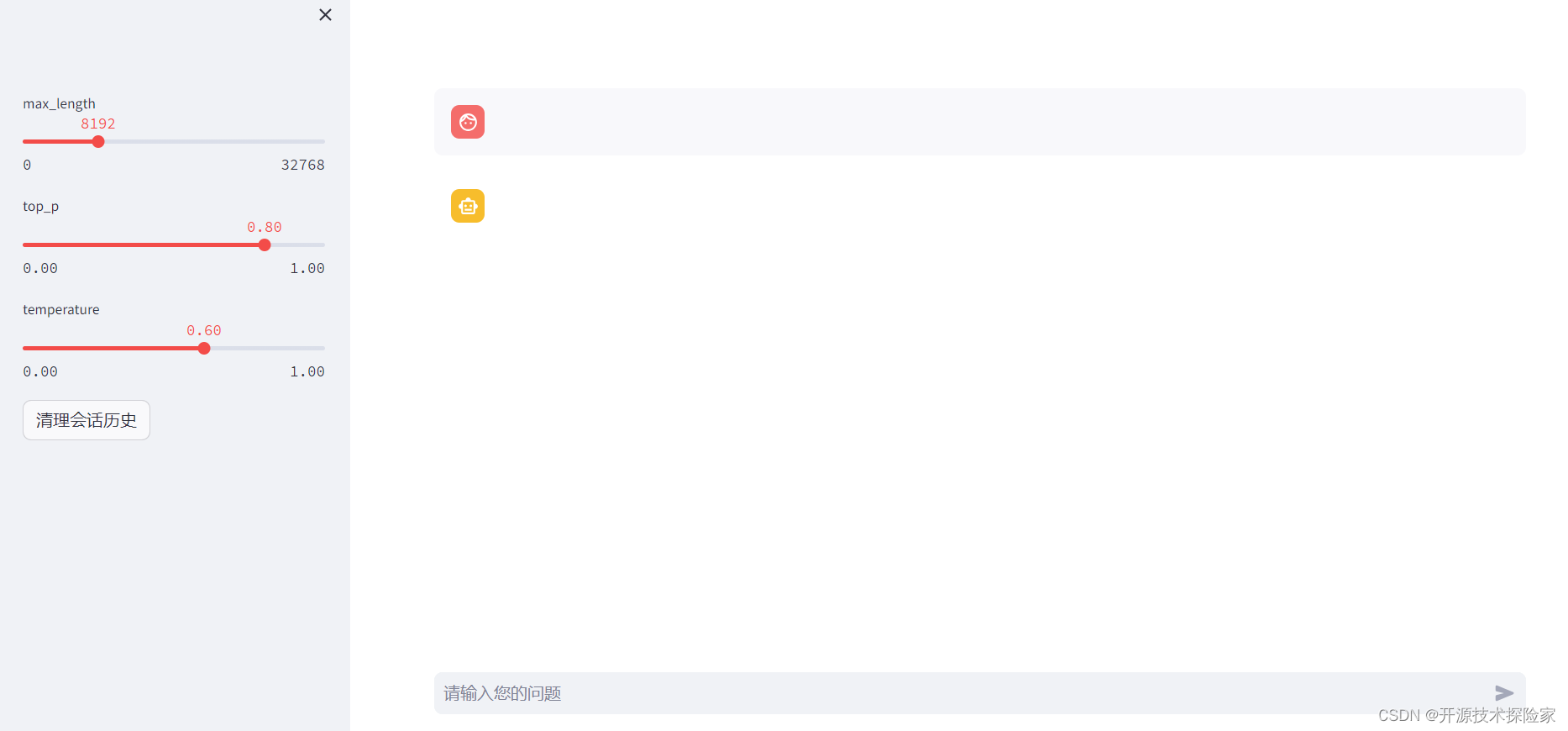
(3) 推理
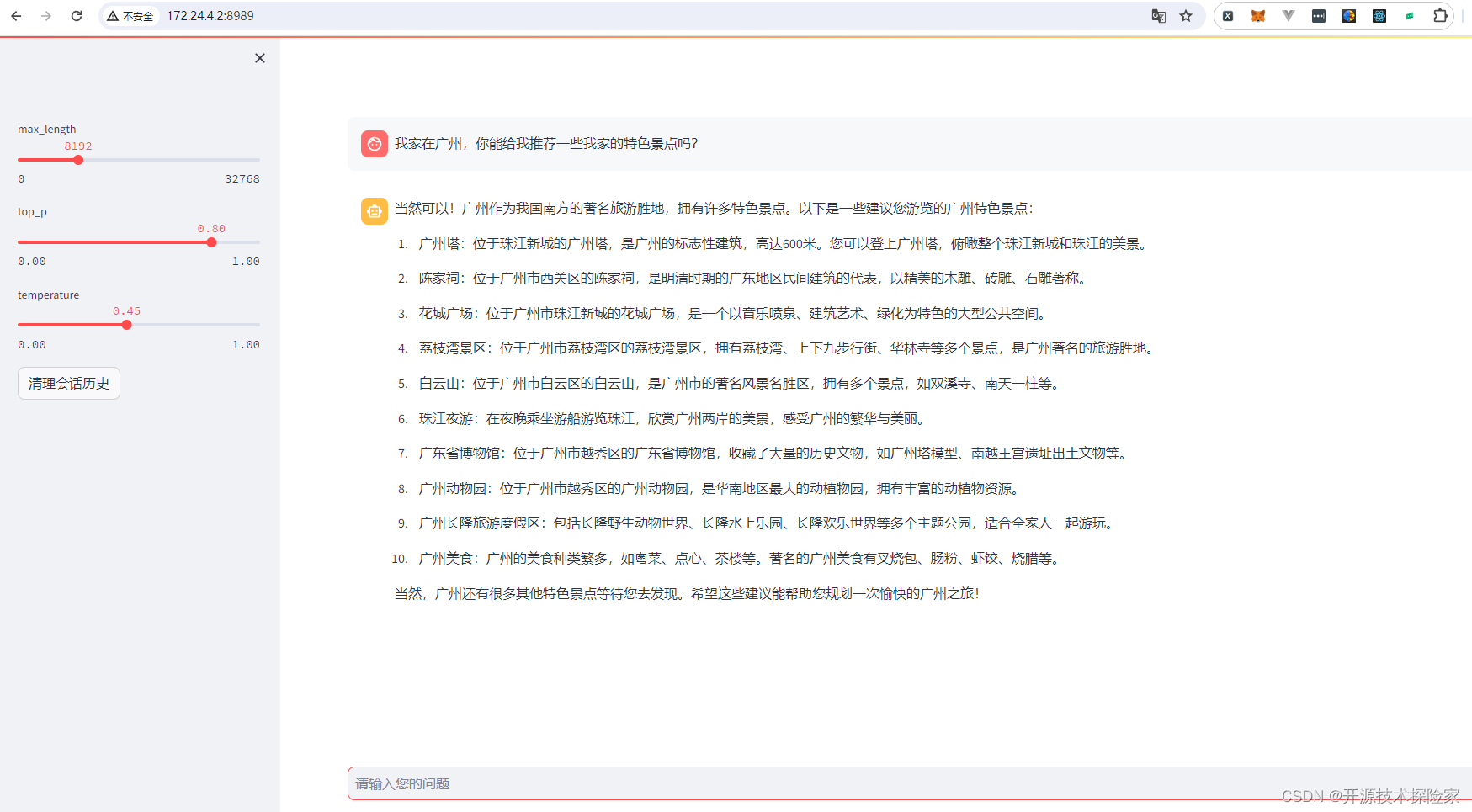
GPU使用情况:
五、附带说明
5.1. @st.cache_resource注解的作用
@st.cache_resource是一个装饰器函数,用于缓存外部资源(如文件、数据集等)。它的作用是在应用程序执行期间缓存资源,以避免每次执行应用程序时都重新加载资源,从而提高应用程序的性能和响应速度。
当您使用@st.cache_resource装饰器修饰一个函数时,该函数将被包装成一个可缓存的函数。在函数第一次被调用时,它会执行函数体内的代码,并将结果缓存起来。之后,当再次调用该函数时,如果函数的输入参数没有变化,Streamlit会直接返回缓存的结果,而不再执行函数体内的代码。
5.2. 修改Streamlit默认端口
(一)使用命令行参数:
在运行Streamlit应用程序时,可以使用--server.port参数来指定端口。例如,以下命令将Streamlit应用程序运行在端口号为8888的服务器上:
streamlit run your_app.py --server.port 8888
(二)使用配置文件:
可以创建一个名为.streamlit/config.toml的配置文件,并在其中指定端口。如果该文件不存在,可以创建它。在配置文件中,添加以下内容:
[server]
port = 8888将端口号替换为您想要使用的实际端口号。
5.3. 界面无法打开
1. 服务监听地址不能是127.0.0.1
![]()
2. 检查服务器的安全策略或防火墙配置
服务端:lsof -i:8989 查看端口是否正常监听
客户端:telnet ip 8989 查看是否可以正常连接