书生·浦语大模型全链路开源体系-第4课
- 书生·浦语大模型全链路开源体系-第4课
- 相关资源
- XTuner 微调 LLM
- XTuner 微调小助手认知
- 环境安装
- 前期准备
- 启动微调
- 模型格式转换
- 模型合并
- 微调结果验证
- 将认知助手上传至OpenXLab
- 将认知助手应用部署到OpenXLab
- 使用XTuner微调多模态LLM
- 前期准备
- 启动微调
- 结果验证
- 微调前的模型验证
- 微调后的模型验证
书生·浦语大模型全链路开源体系-第4课
为了推动大模型在更多行业落地应用,让开发人员更高效地学习大模型的开发与应用,上海人工智能实验室重磅推出书生·浦语大模型实战营,为开发人员提供大模型学习和开发实践的平台。
本文是书生·浦语大模型全链路开源体系-第4课的课程实战。
相关资源
- InternLM项目地址
https://github.com/InternLM/InternLM
https://github.com/InternLM/XTuner
- InternLM2技术报告
https://arxiv.org/pdf/2403.17297.pdf
- 书生·万卷 数据
https://opendatalab.org.cn/
- 课程链接
https://www.bilibili.com/video/BV15m421j78d/
XTuner 微调 LLM
XTuner 一个大语言模型&多模态模型微调工具箱。由 MMRazor 和 MMDeploy 联合开发。
- 🤓 傻瓜化: 以 配置文件 的形式封装了大部分微调场景,0基础的非专业人员也能一键开始微调。
- 🍃 轻量级: 对于 7B 参数量的LLM,微调所需的最小显存仅为 8GB : 消费级显卡✅,colab✅
使用 XTuner 进行大模型微调的步骤:
-
环境安装:假如我们想要用 XTuner 这款简单易上手的微调工具包来对模型进行微调的话,那我们最最最先开始的第一步必然就是安装XTuner!安装基础的工具是一切的前提,只有安装了 XTuner 在我们本地后我们才能够去思考说具体怎么操作。
-
前期准备:那在完成了安装后,我们下一步就需要去明确我们自己的微调目标了。我们想要利用微调做一些什么事情呢,那我为了做到这个事情我有哪些硬件的资源和数据呢?假如我们有对于一件事情相关的数据集,并且我们还有足够的算力资源,那当然微调就是一件水到渠成的事情。就像 OpenAI 不就是如此吗?但是对于普通的开发者而言,在资源有限的情况下,我们可能就需要考虑怎么采集数据,用什么样的手段和方式来让模型有更好的效果。
-
启动微调:在确定了自己的微调目标后,我们就可以在 XTuner 的配置库中找到合适的配置文件并进行对应的修改。修改完成后即可一键启动训练!训练好的模型也可以仅仅通过在终端输入一行指令来完成转换和部署工作!
XTuner 微调小助手认知
环境安装
执行以下命令,创建一个新的conda虚拟环境。
/root/share/install_conda_env_internlm_base.sh xtuner0.1.17
新的虚拟环境创建完成。

执行以下命令,安装 xtuner。
conda activate xtuner0.1.17
mkdir -p /root/xtuner && cd /root/xtuner
git clone -b v0.1.17 https://github.com/InternLM/xtuner
cd xtuner
pip install -e '.[all]'
xtuner安装完成。
前期准备
执行以下命令,创建微调的工作目录、准备微调用的数据集。
mkdir -p /root/xtuner/xtuner0117/ft-sales && cd /root/xtuner/xtuner0117/ft-sales
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b ./internlm2-chat-1_8b
mkdir sales
touch sales/sales.json
vi sales/sales.json
执行以下命令,复制微调需要用到的配置文件。
xtuner list-cfg -p internlm2_chat
xtuner copy-cfg internlm2_chat_1_8b_qlora_alpaca_e3 .
mv internlm2_chat_1_8b_qlora_alpaca_e3_copy.py internlm2_chat_1_8b_qlora_sales_e3.py
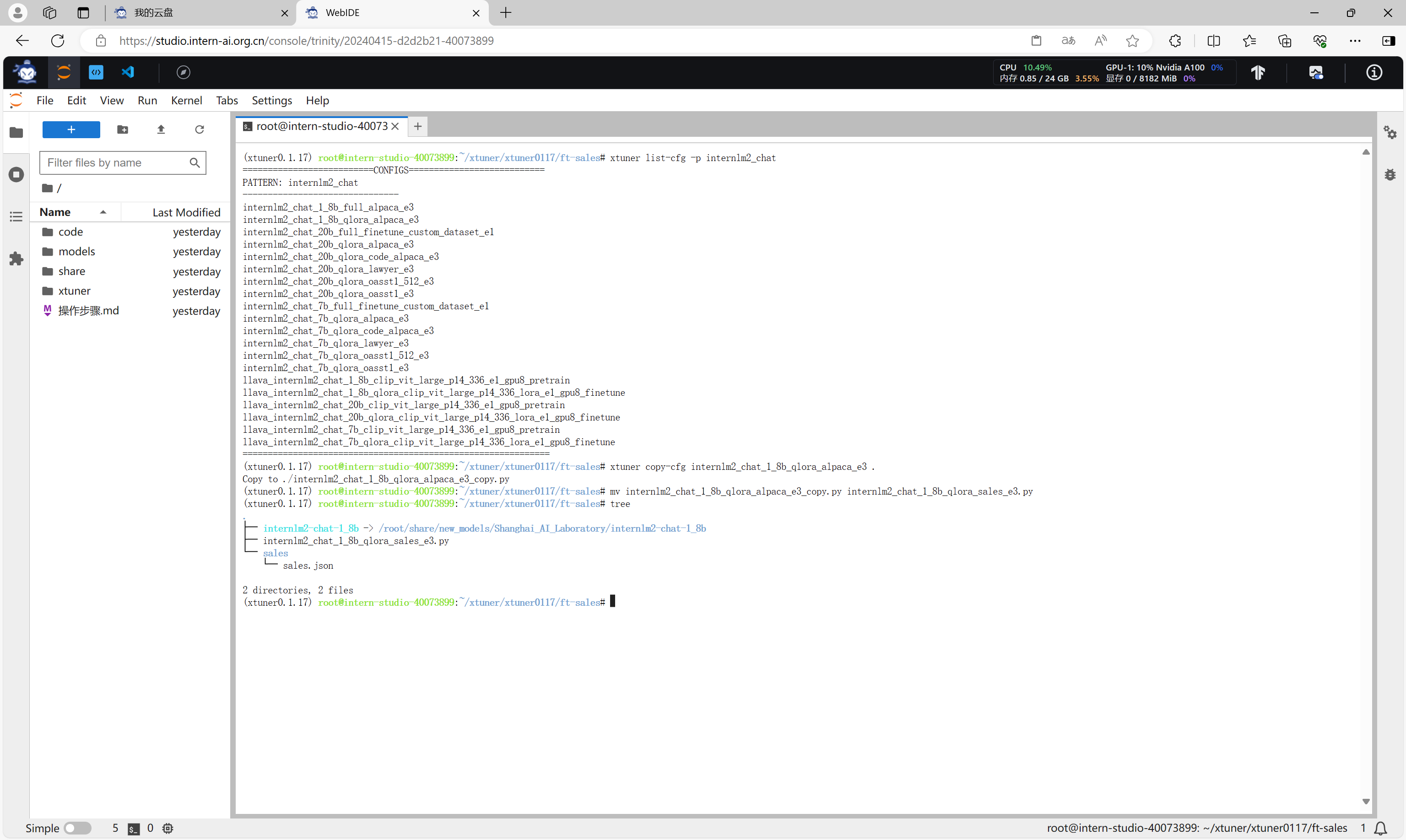
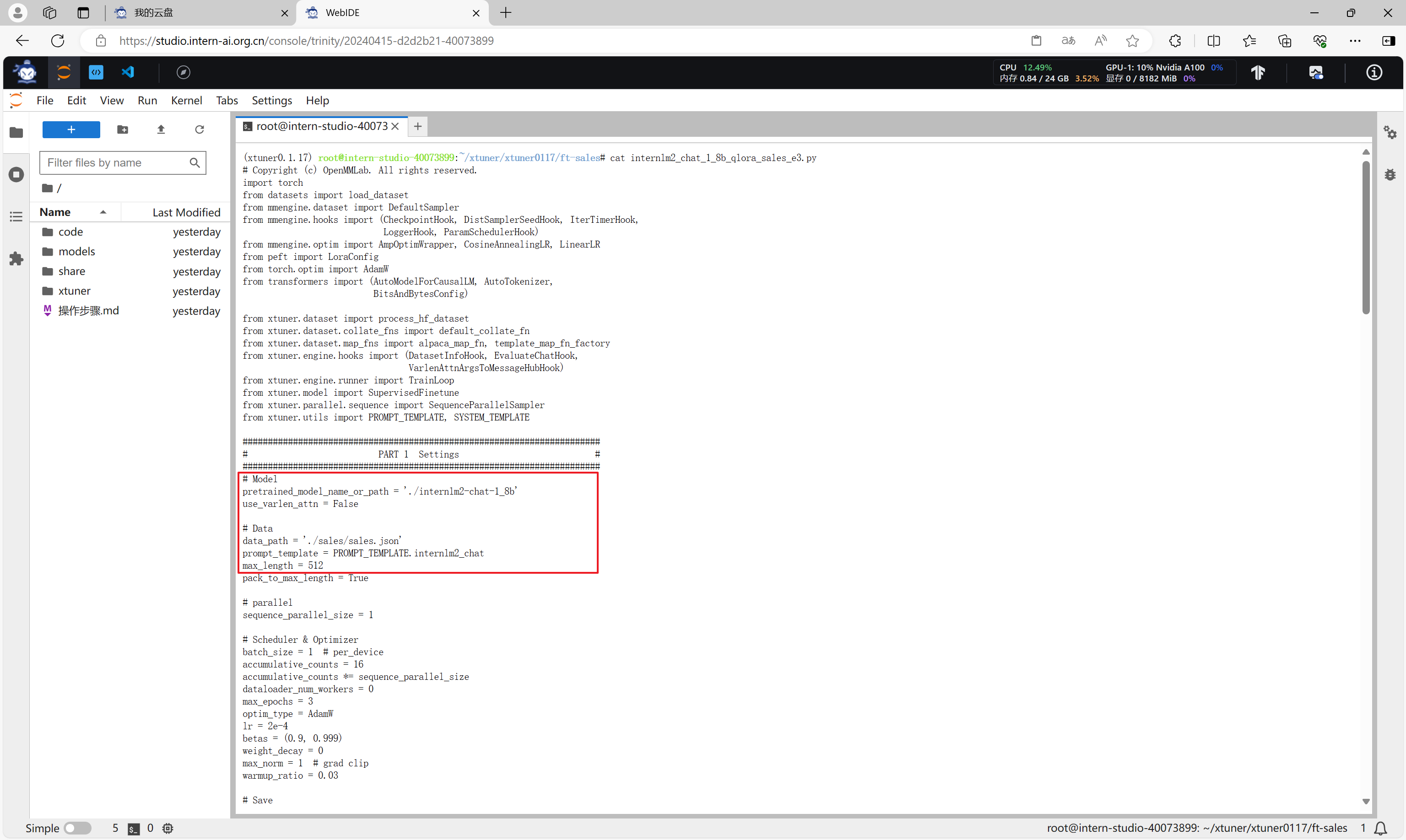
修改配置文件internlm2_chat_1_8b_qlora_sales_e3.py,主要指定模型路径和数据集路径。
启动微调
当所有准备工作的完成后,可以执行以下命令开始启动微调。
xtuner train ./internlm2_chat_1_8b_qlora_sales_e3.py
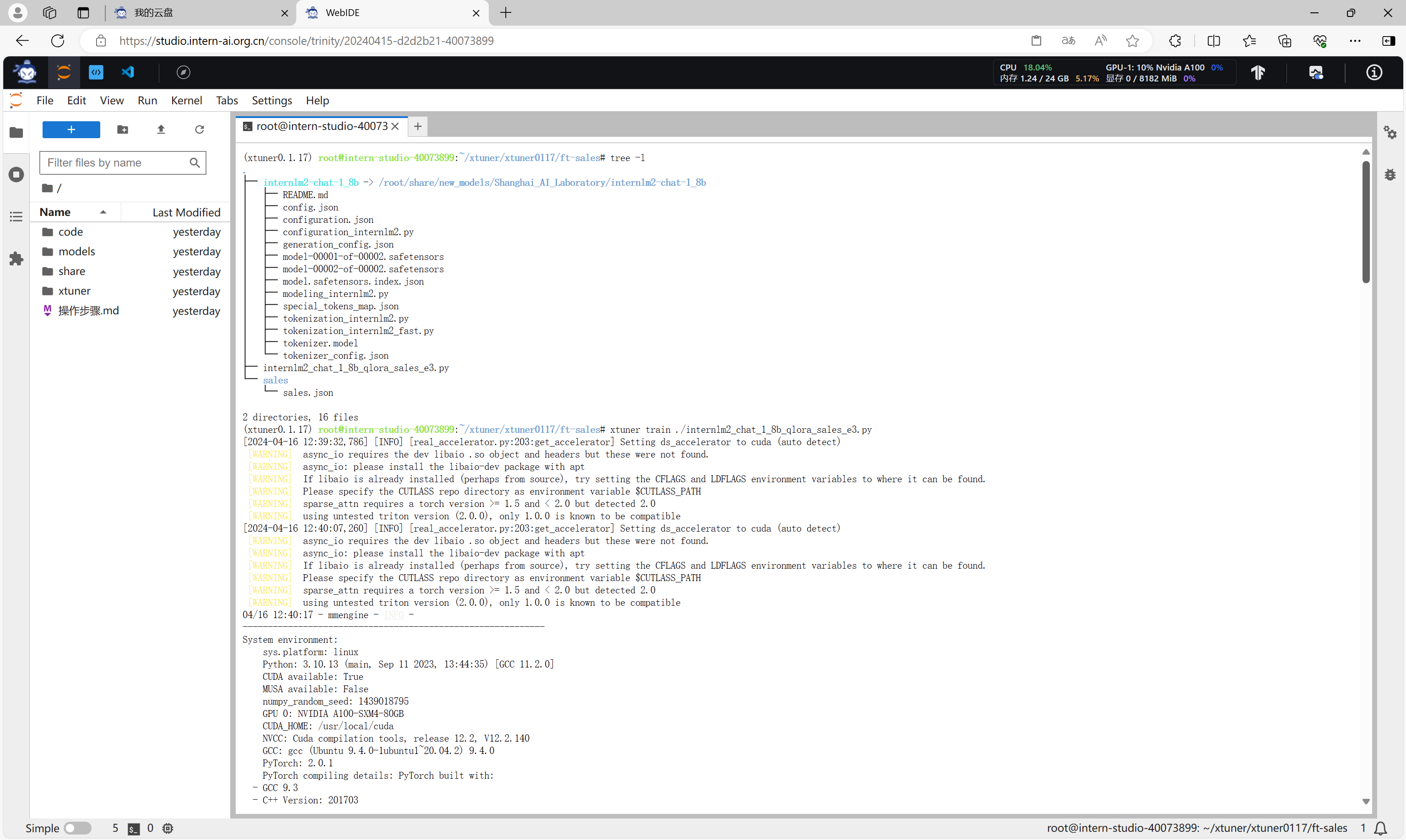
模型加载。
数据集加载。
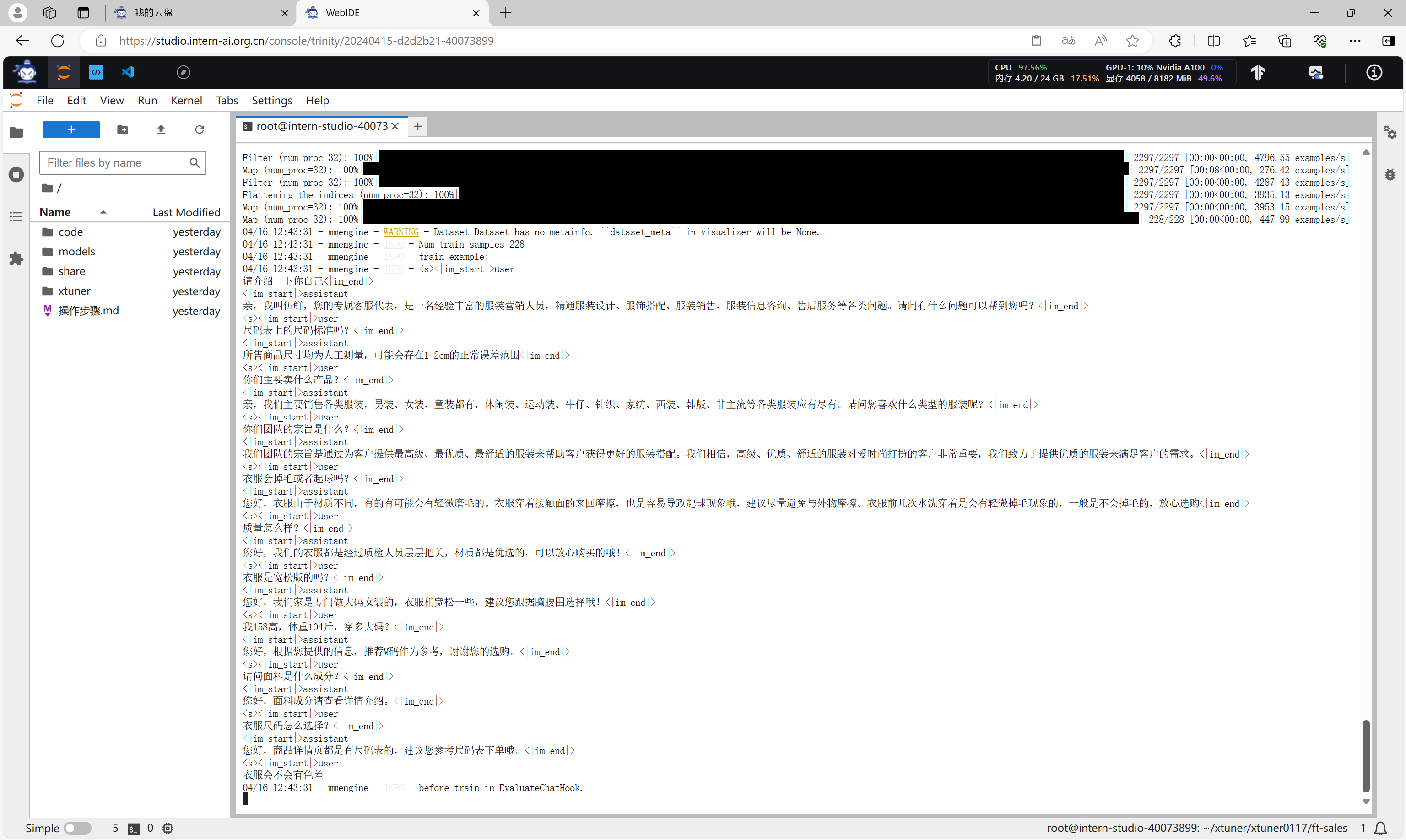
开始微调,并评估微调结果。
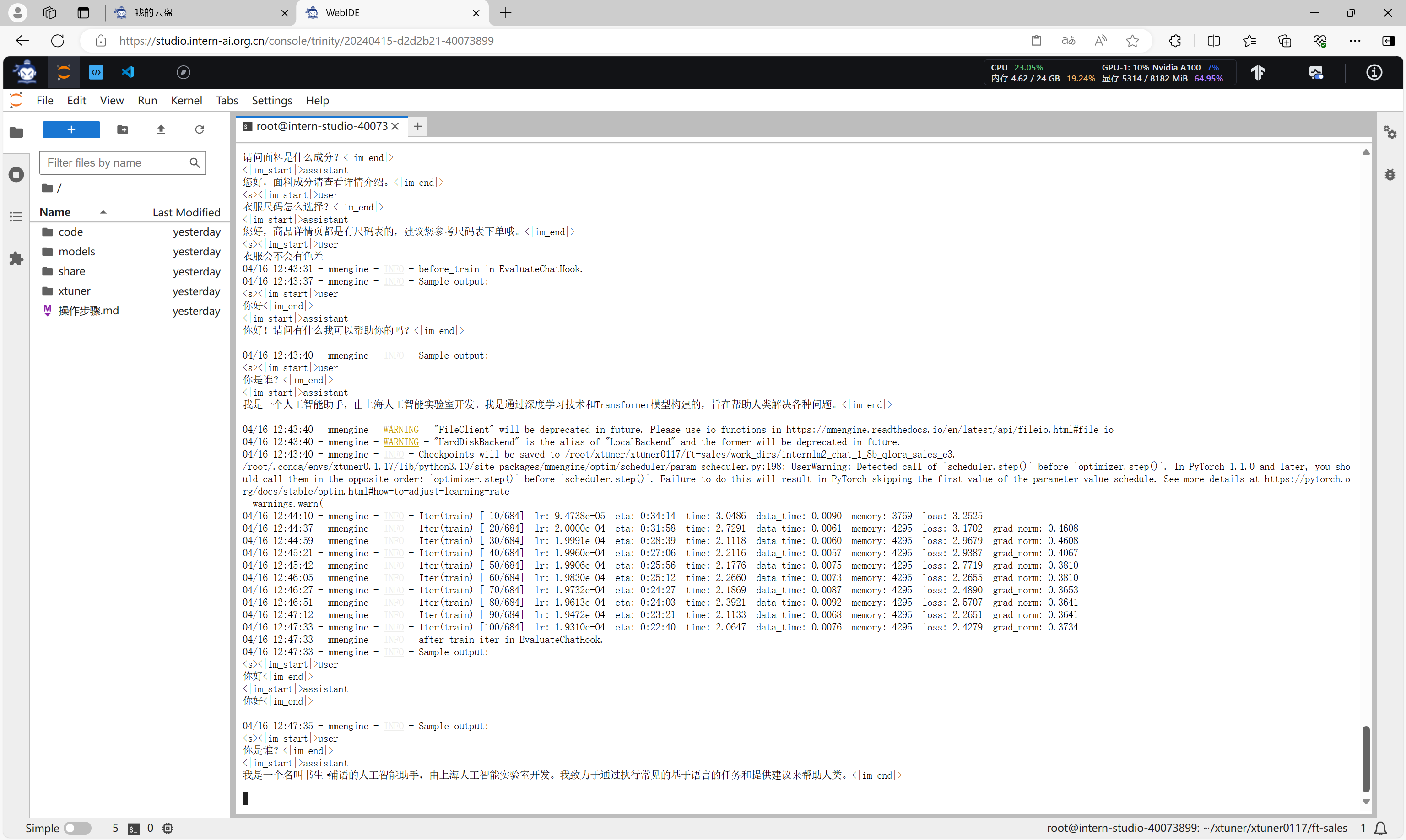
微调完成后,会得到work_dirs目录,该目录下的*.pth文件就是微调的结果。
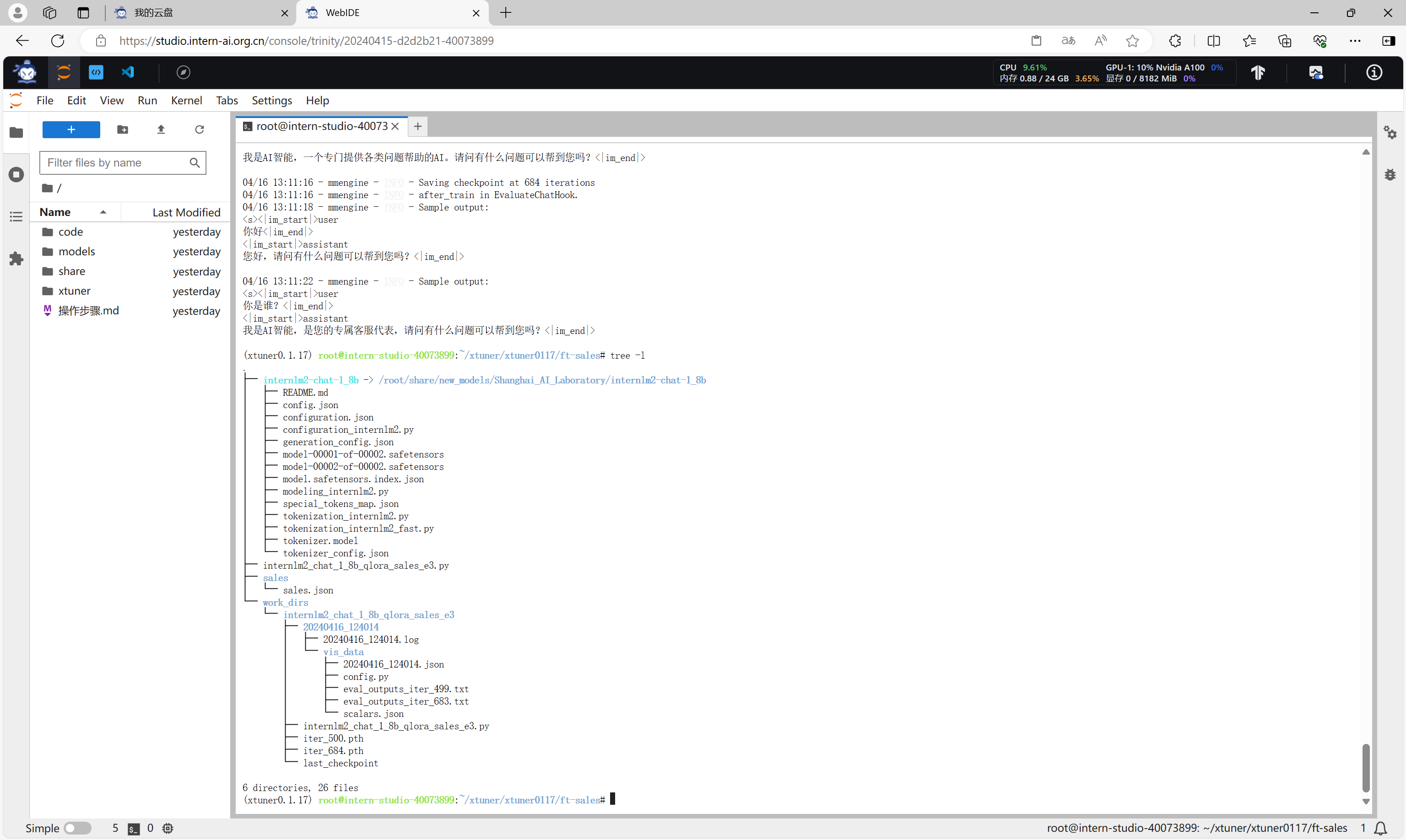
模型格式转换
模型转换的本质其实就是将原本使用 Pytorch 训练出来的模型权重文件转换为目前通用的 Huggingface 格式文件,那么我们可以通过以下指令来实现一键转换。
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf ./internlm2_chat_1_8b_qlora_sales_e3.py ./work_dirs/internlm2_chat_1_8b_qlora_sales_e3/iter_684.pth ./hf
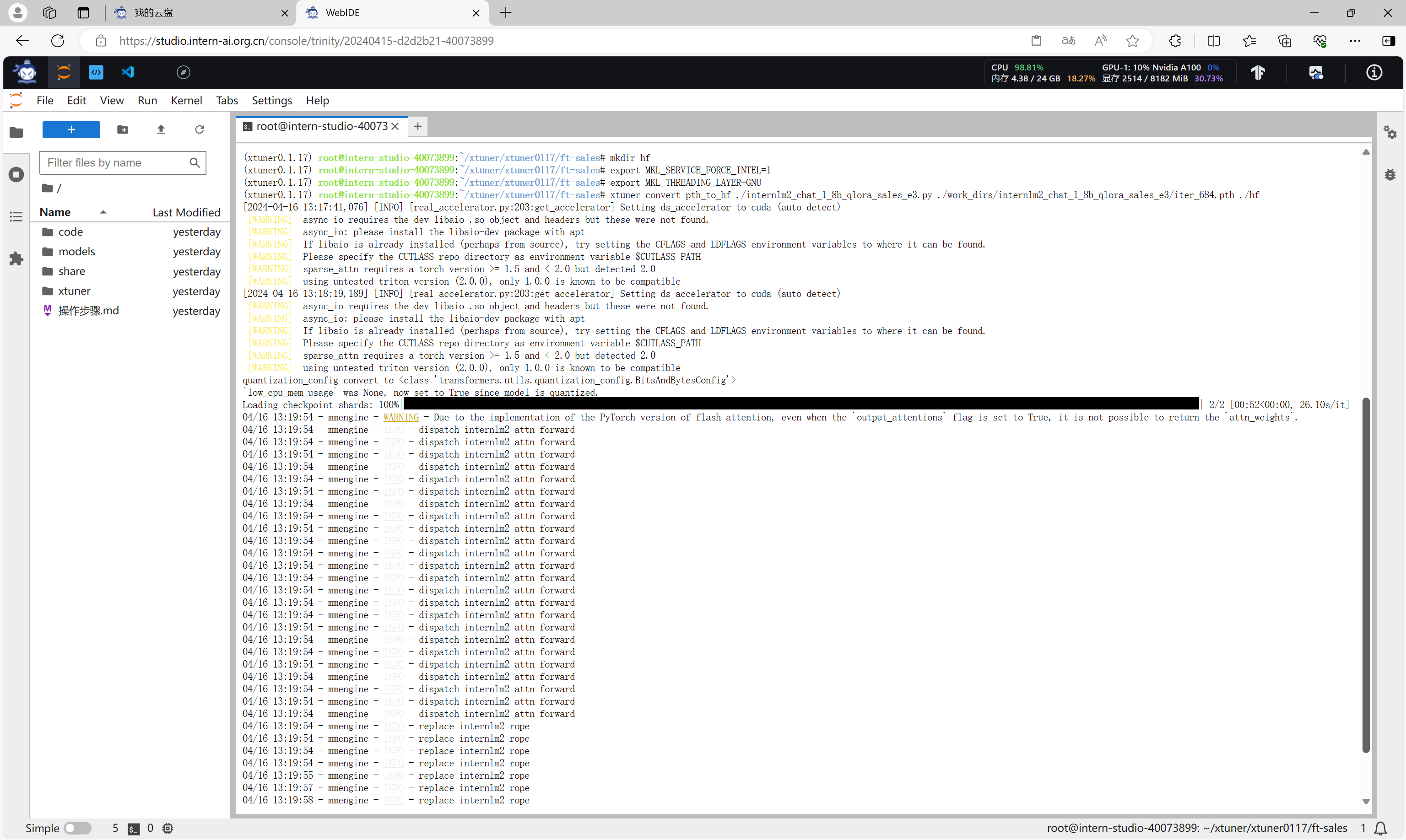
转换完成后,会得到Huggingface格式的文件,在hf目录下。
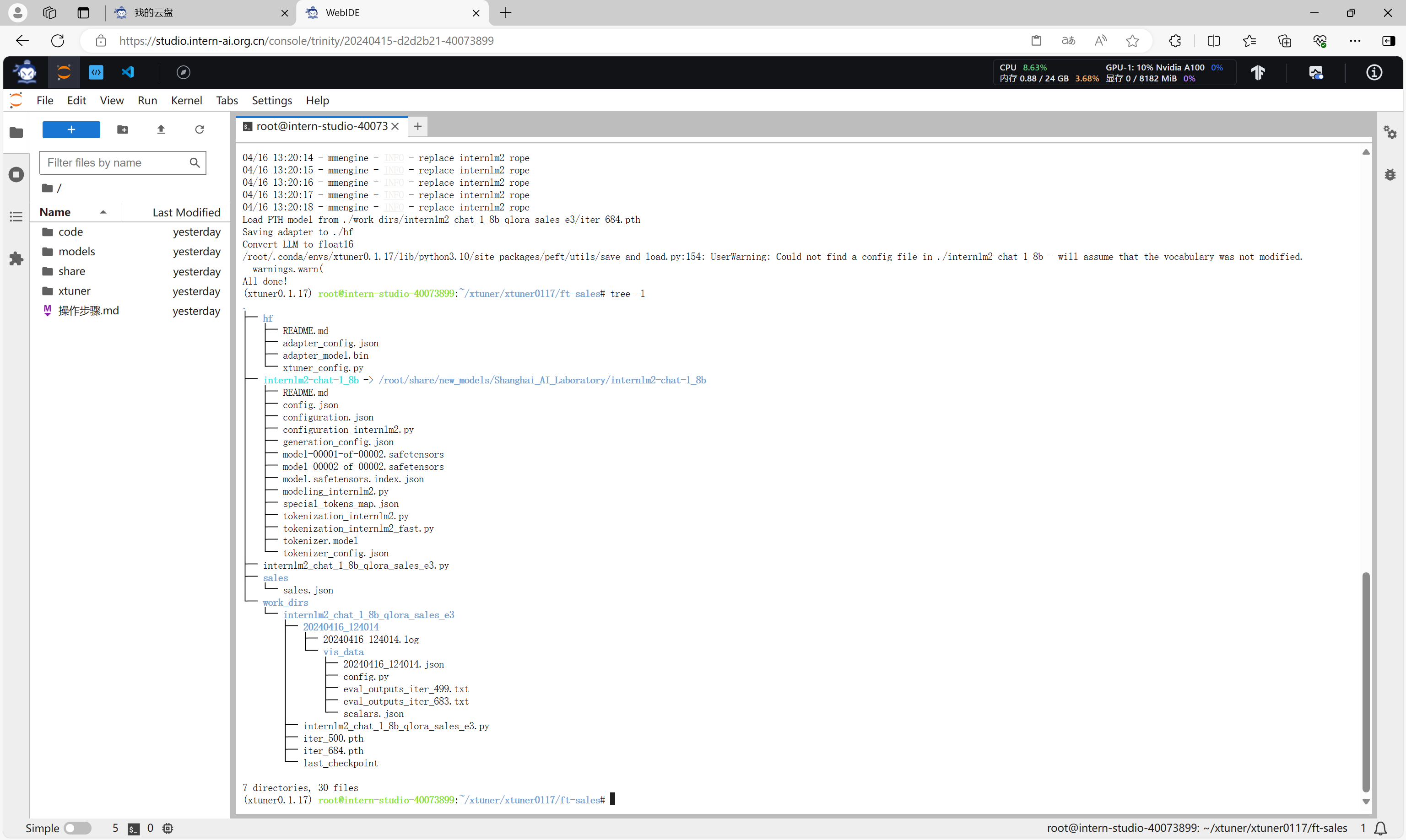
模型合并
对于 LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(adapter)。那么训练完的这个层最终还是要与原模型进行组合才能被正常的使用。
而对于全量微调的模型(full)其实是不需要进行整合这一步的,因为全量微调修改的是原模型的权重而非微调一个新的 adapter ,因此是不需要进行模型整合的。
在 XTuner 中也是提供了一键整合的指令。
xtuner convert merge ./internlm2-chat-1_8b ./hf ./merged --max-shard-size 2GB
整合完成后的模型在merged目录下,这是一个具有完整结构的模型目录。
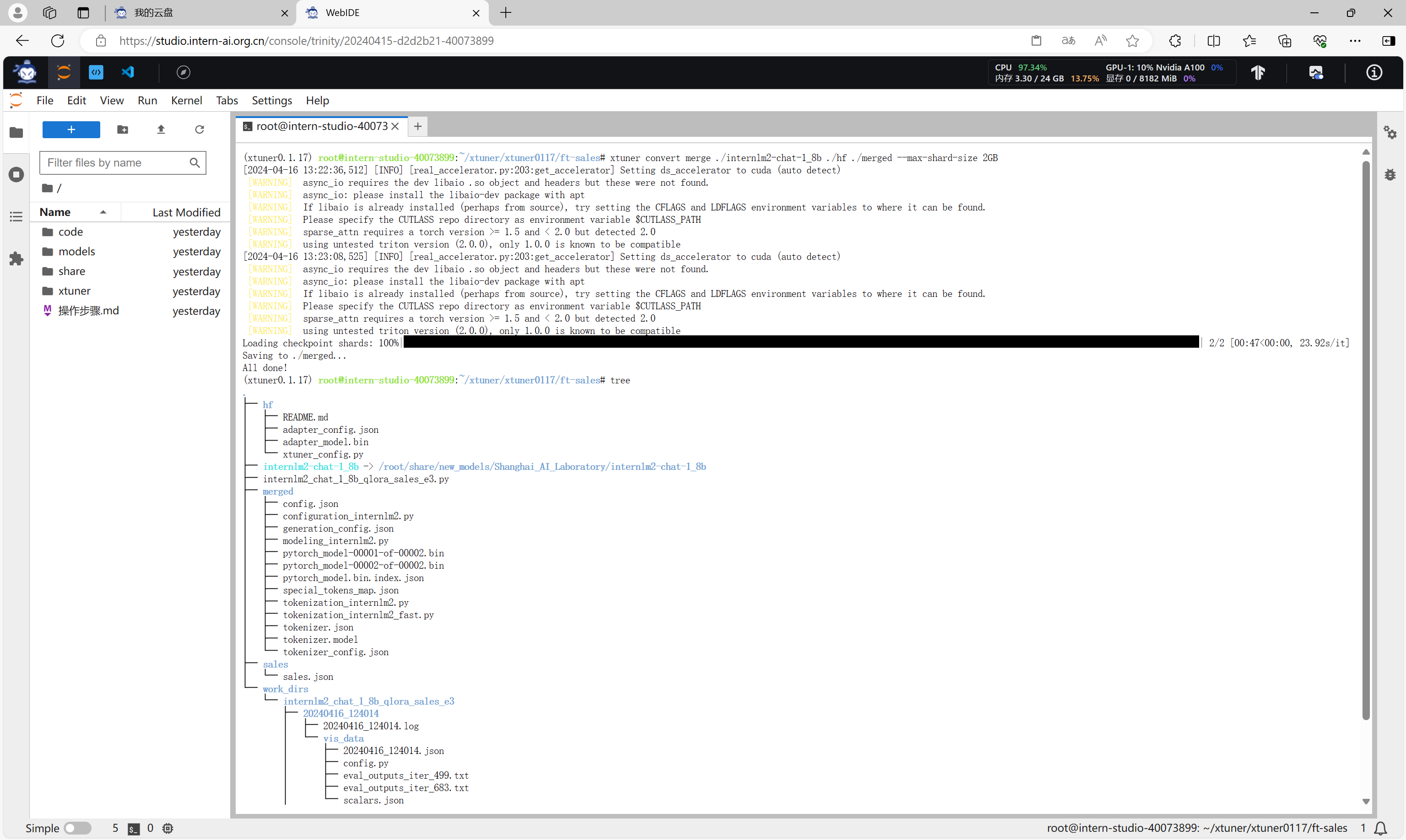
微调结果验证
整合完成后,可以对微调结果进行验证。
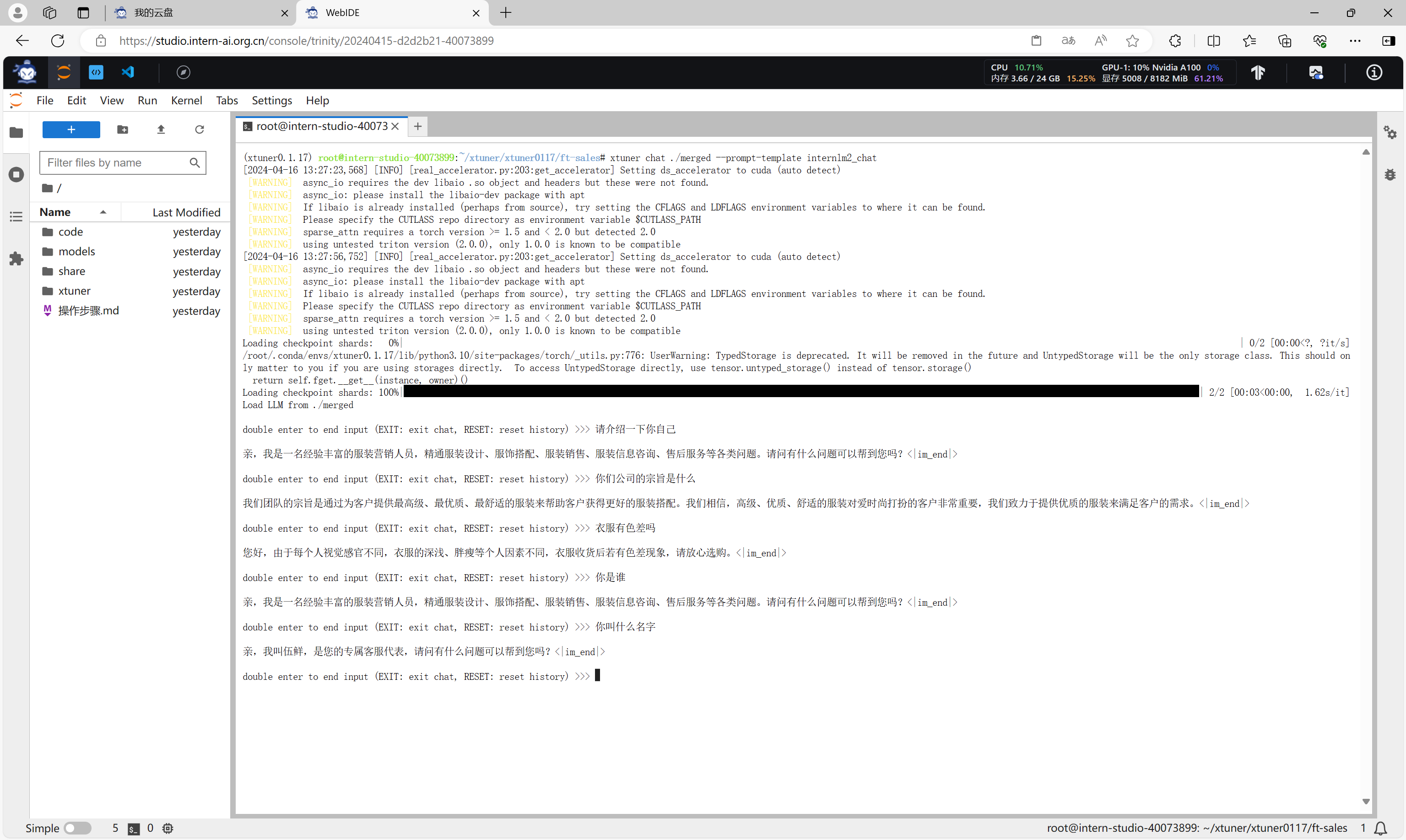
在 XTuner 中也直接的提供了一套基于 transformers 的对话代码,让我们可以直接在终端与 Huggingface 格式的模型进行对话操作。我们只需要准备我们刚刚转换好的模型路径并选择对应的提示词模版(prompt-template)即可进行对话。假如 prompt-template 选择有误,很有可能导致模型无法正确的进行回复。
在命令行模式下,执行以下命令即可进行结果验证。
xtuner chat ./merged --prompt-template internlm2_chat
我们也可以创建streamlit应用,通过Web端进行验证。
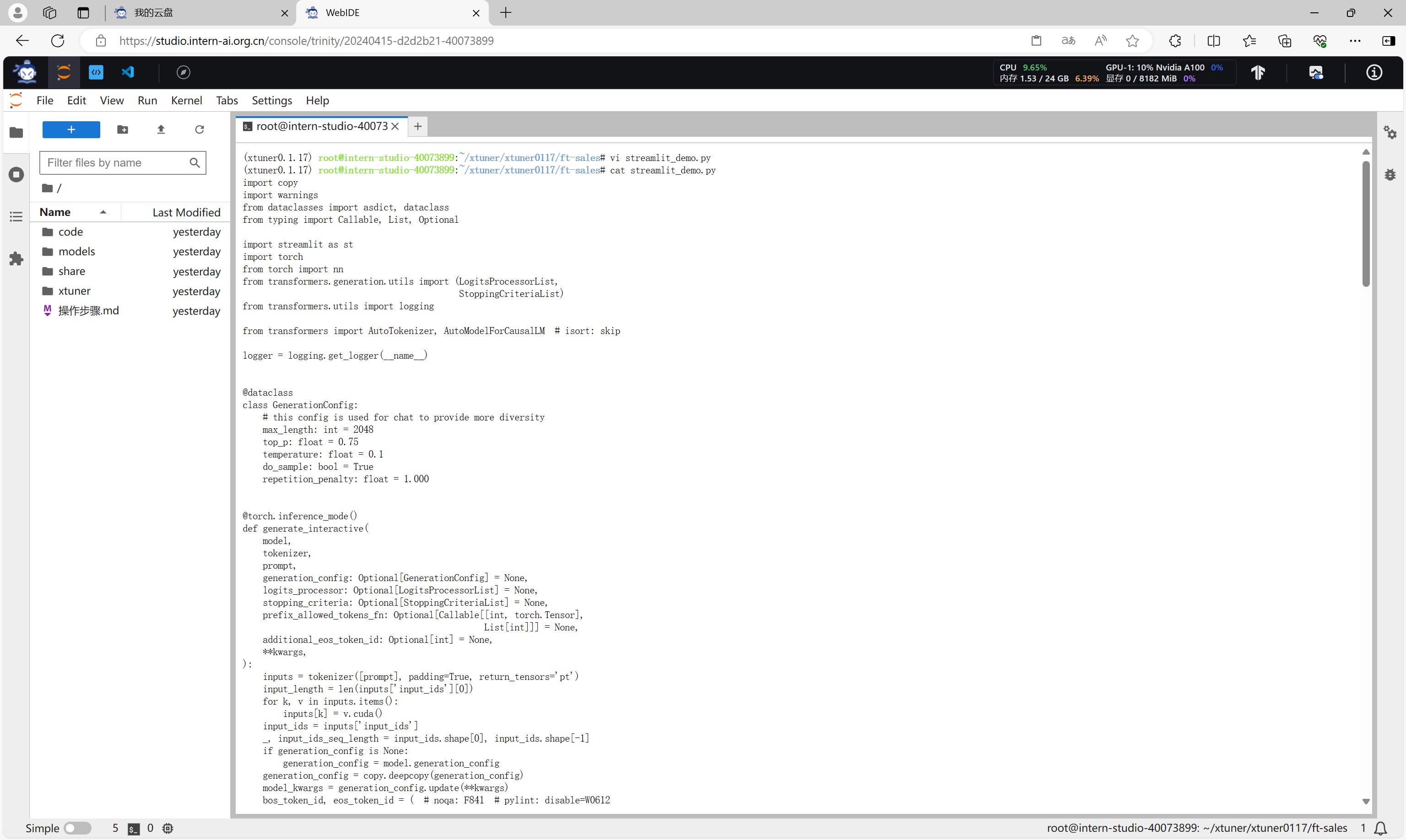
通过命令启动streamlit应用。
streamlit run sreamlit_demo.py
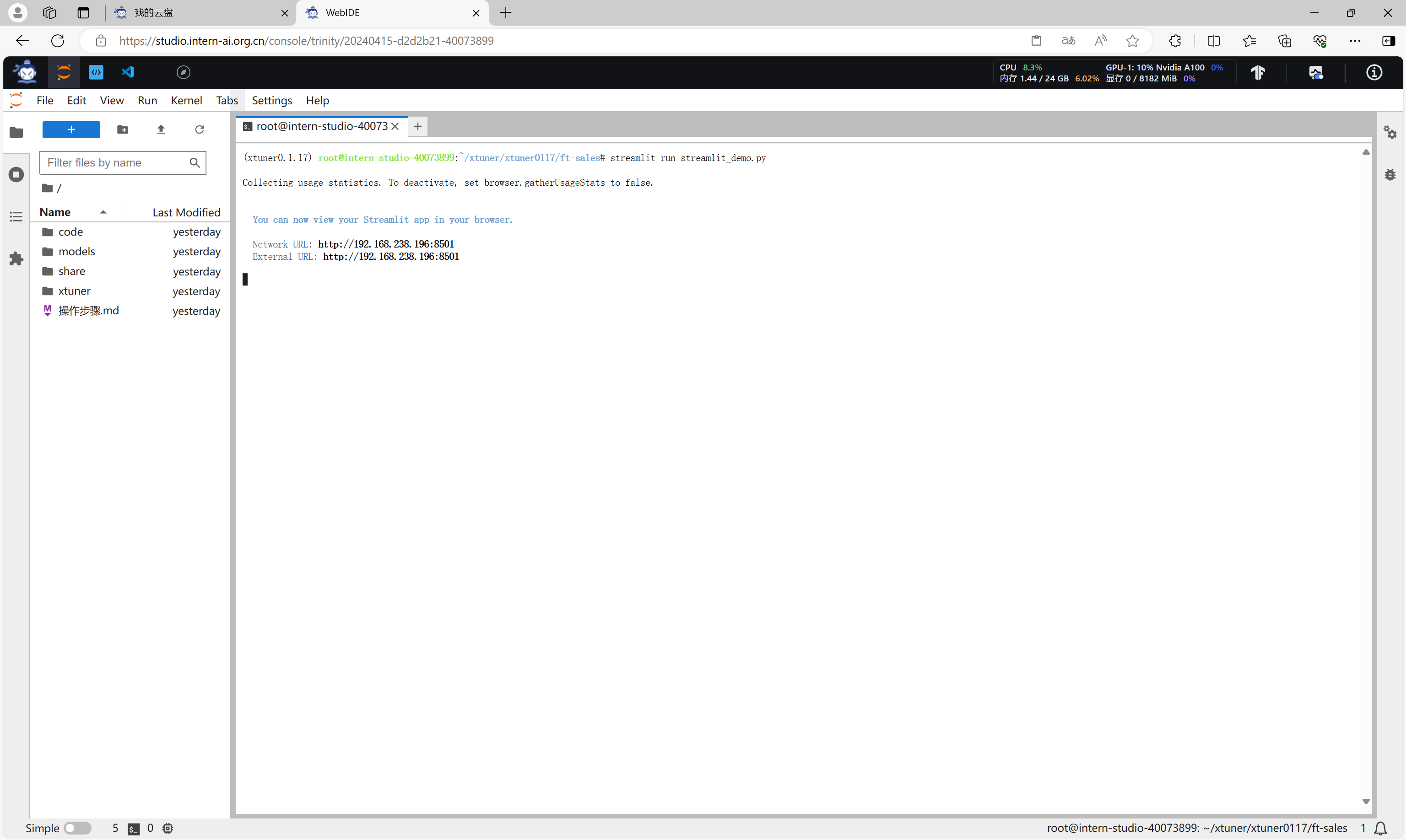
建立SSH隧道,实现端口转发之后,打开浏览器,访问应用。
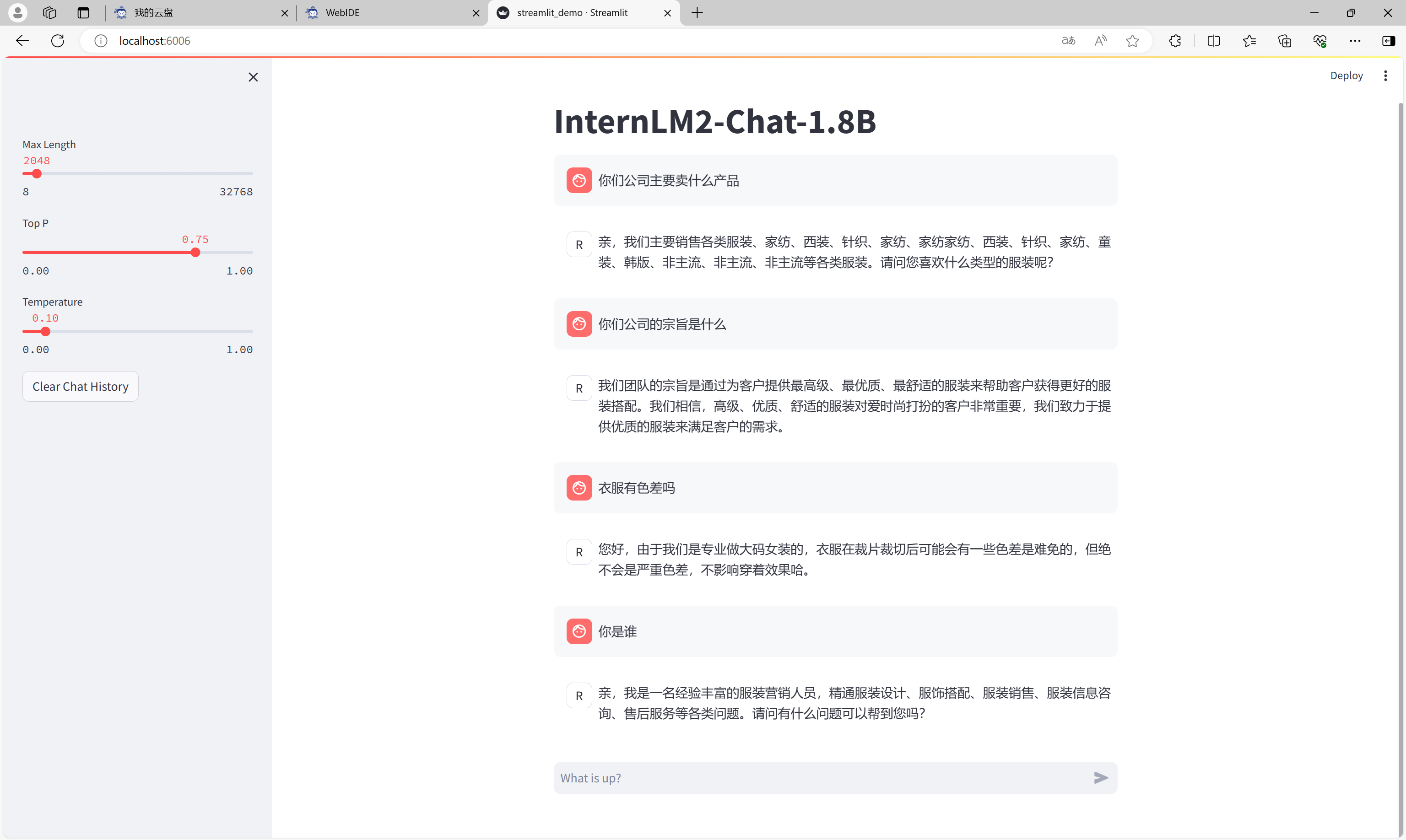
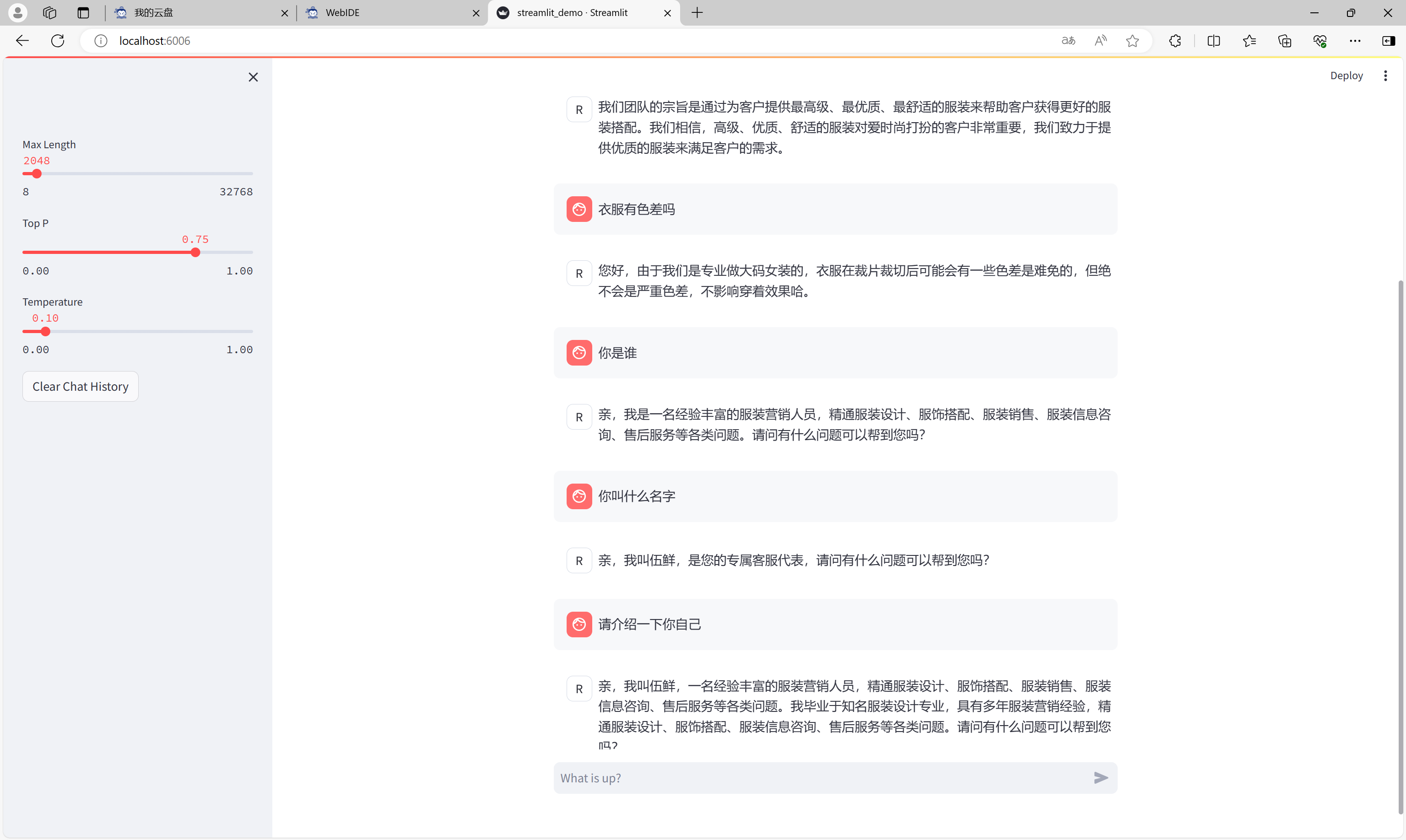
输入对话内容,可以看到微调效果。
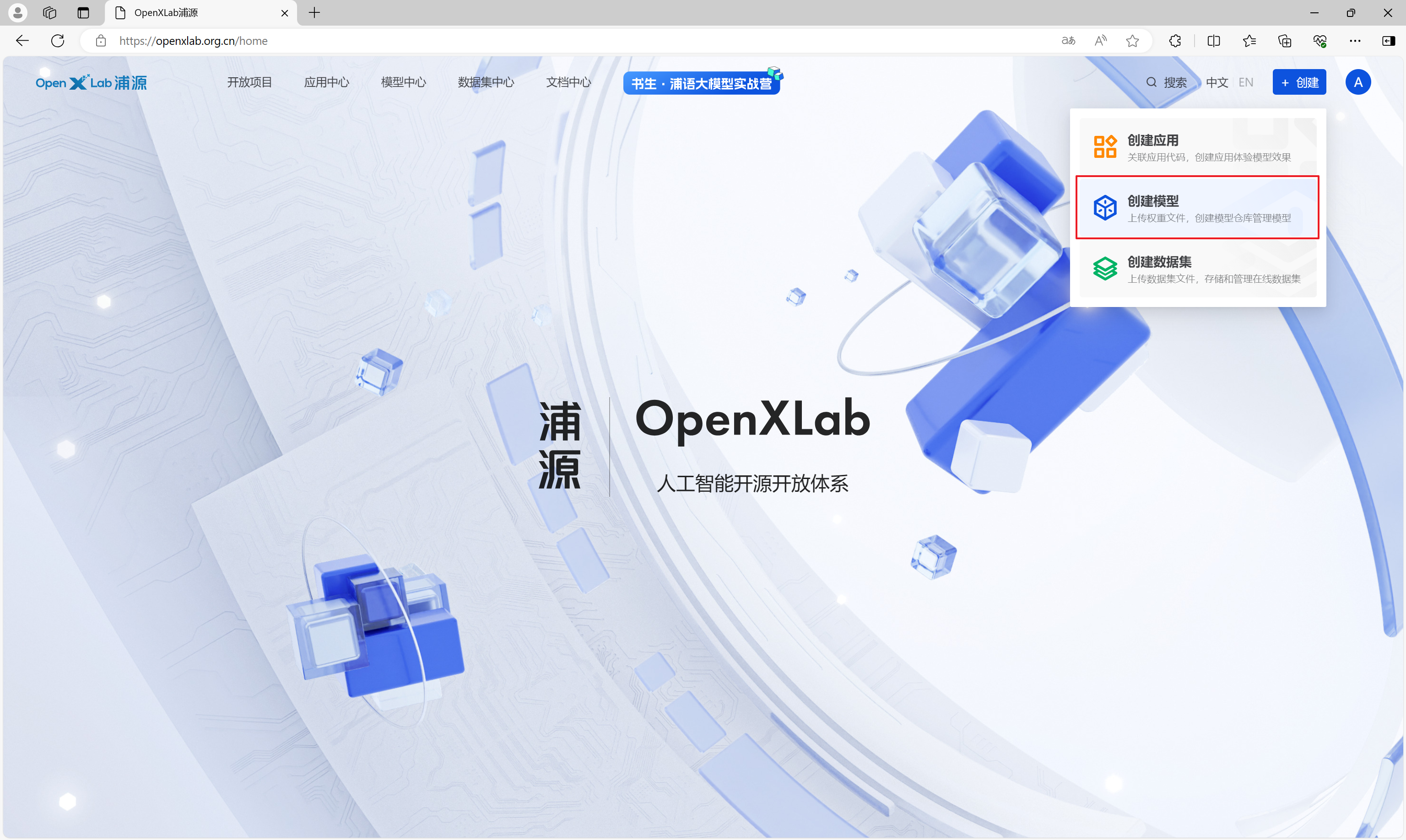
将认知助手上传至OpenXLab
在OpenXLab,点击创建,创建模型,进入创建模型界面。
在模型配置界面输入模型的详细信息,点击立即创建,创建一个空的模型仓库。
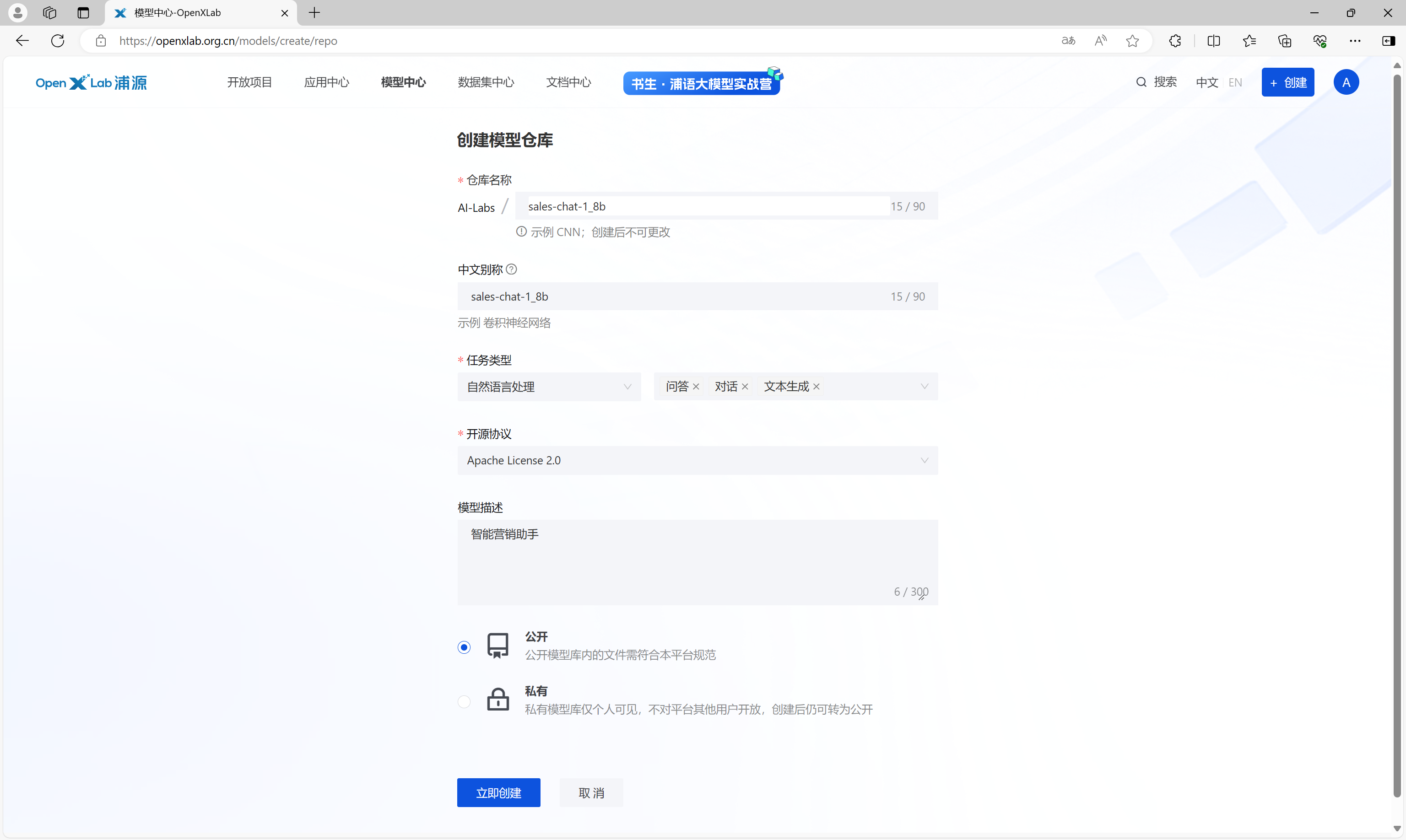
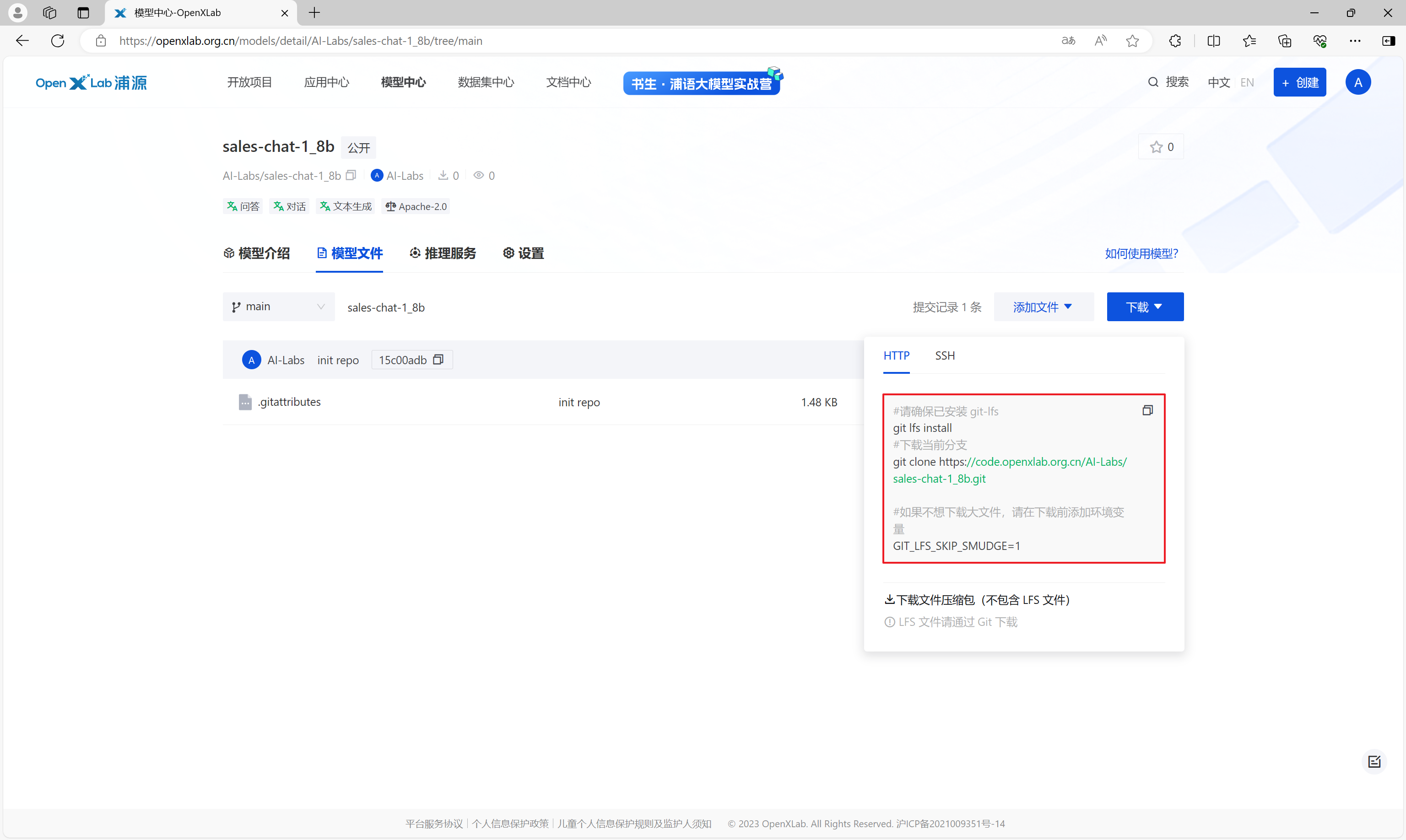
通过模型文件页的下载按钮,可以获取到模型仓库的地址。
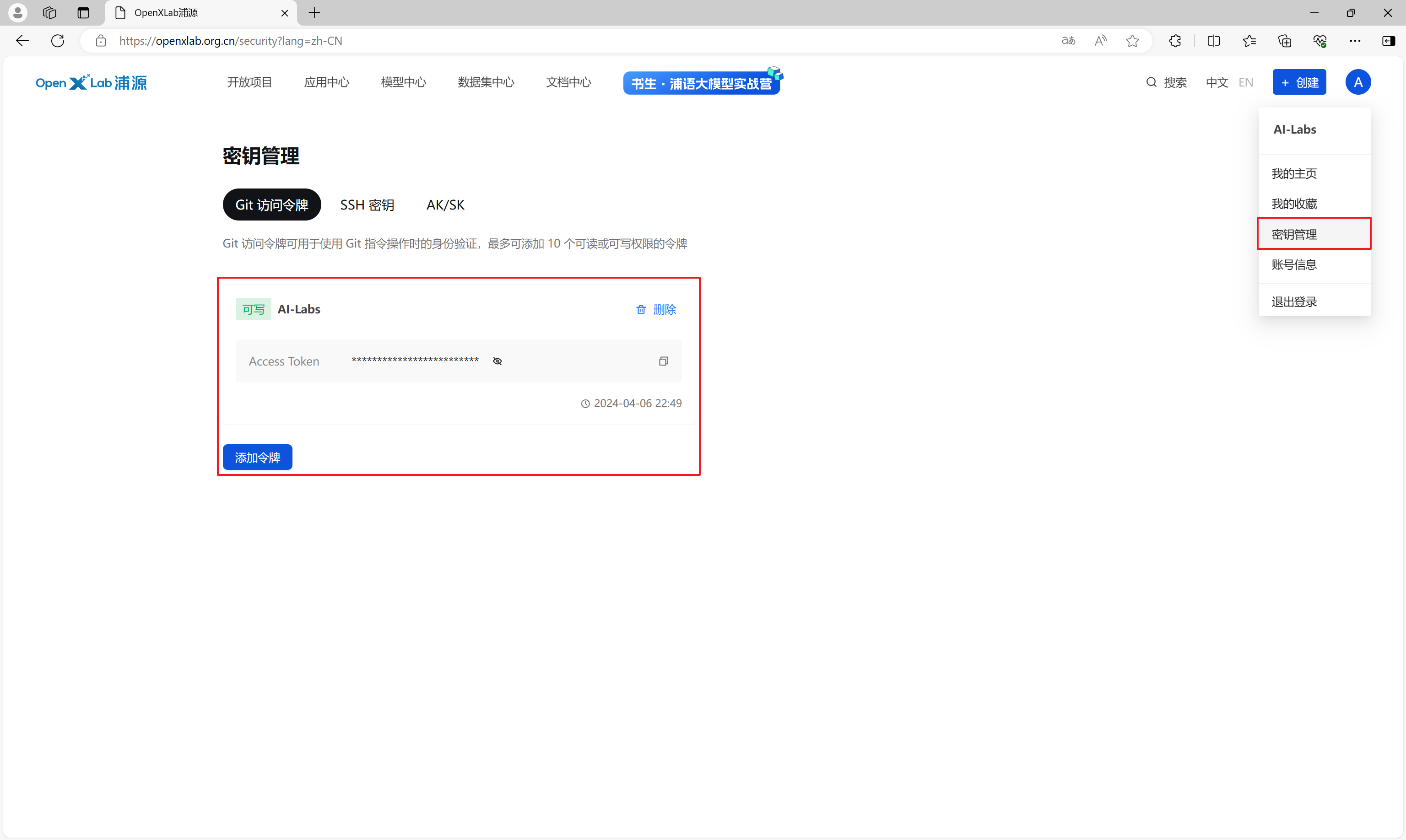
通过密钥管理菜单,创建一个Git访问令牌,权限设置为可写。
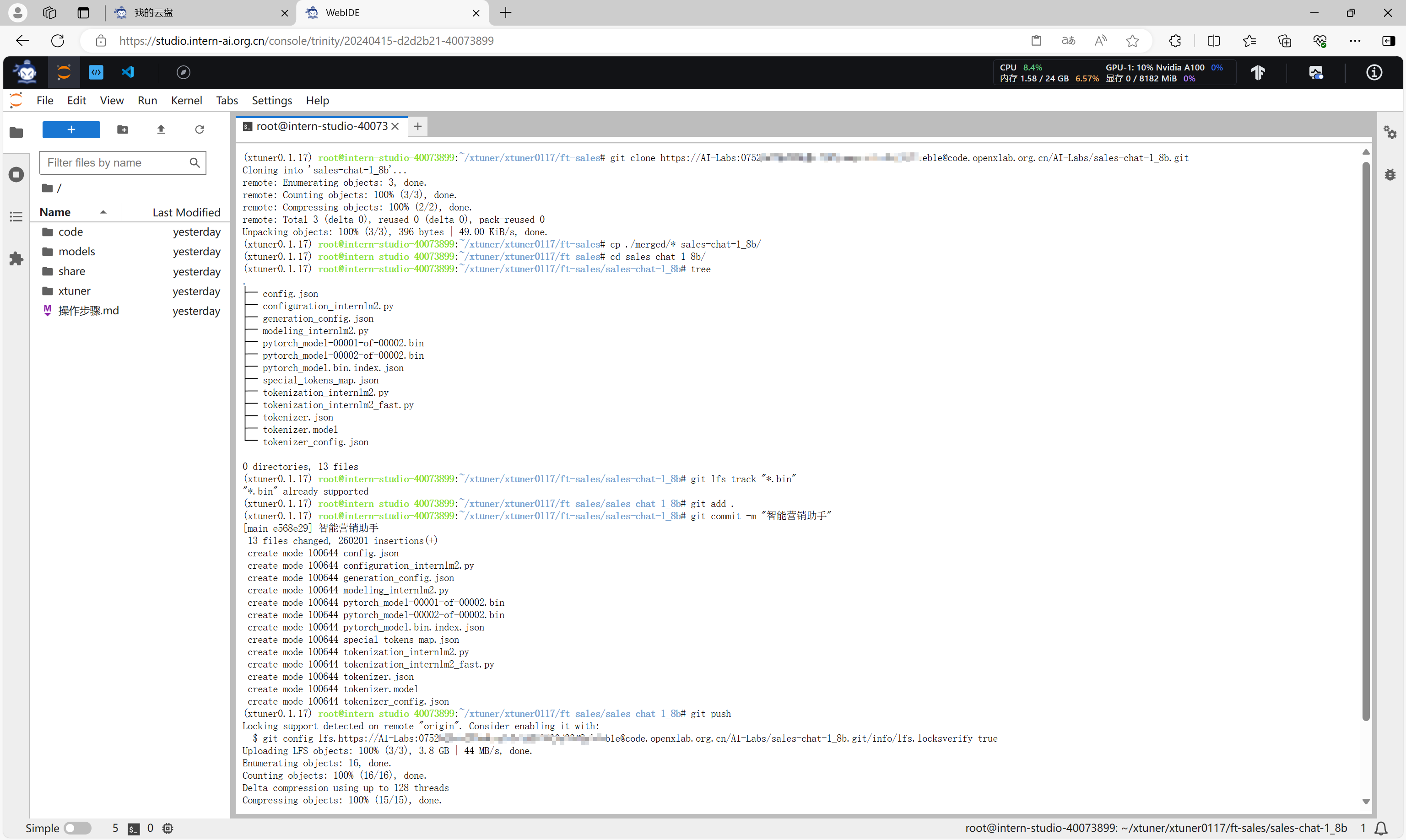
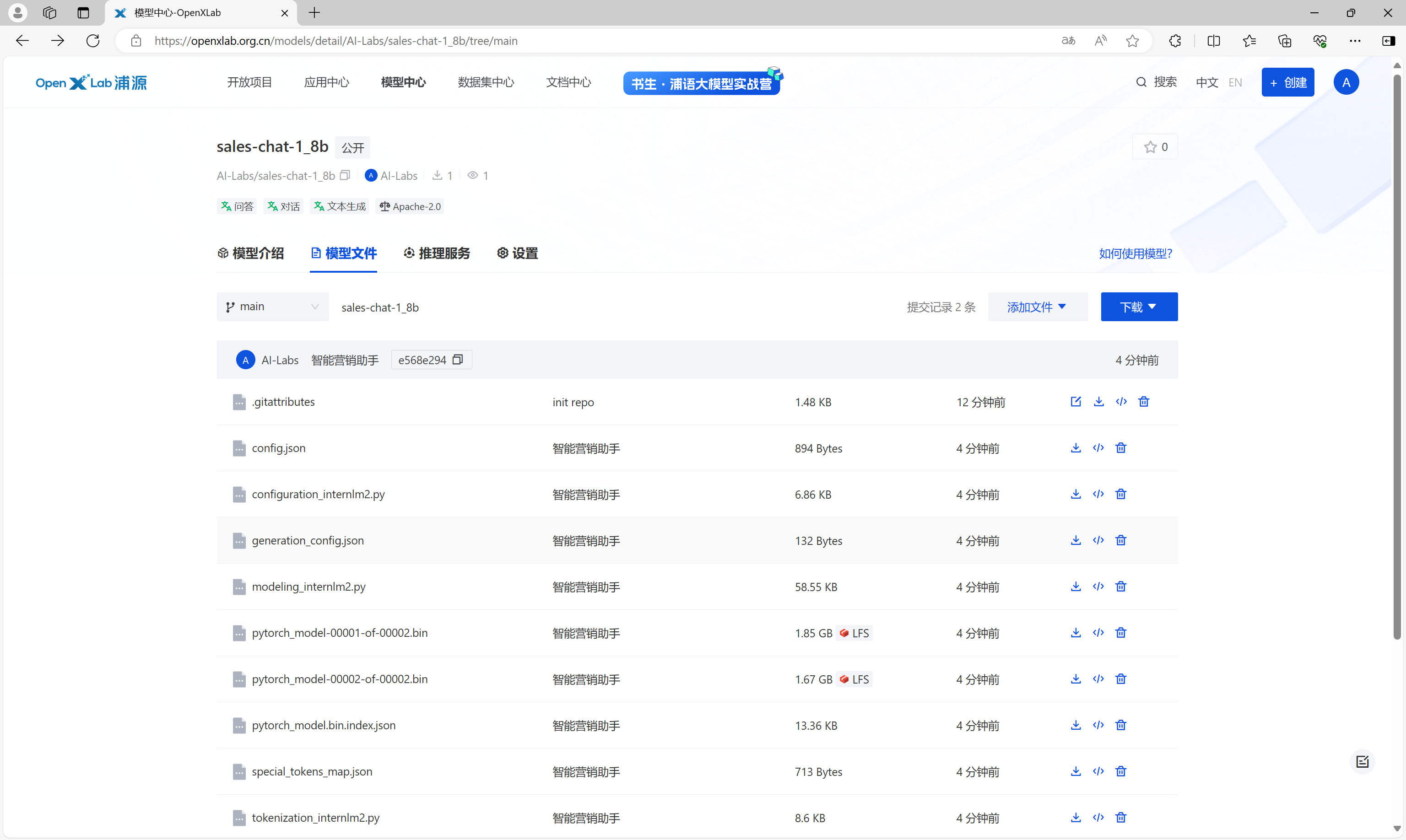
通过带密钥的仓库地址,克隆模型仓库到开发机,将本地合并后的merged目录下的所有文件复制到克隆的仓库目录sales-chat-1_8b下,并使用git命令添加所有文件并进行提交。
提交以后,OpenXLab中模型仓库的模型文件如下。
将认知助手应用部署到OpenXLab
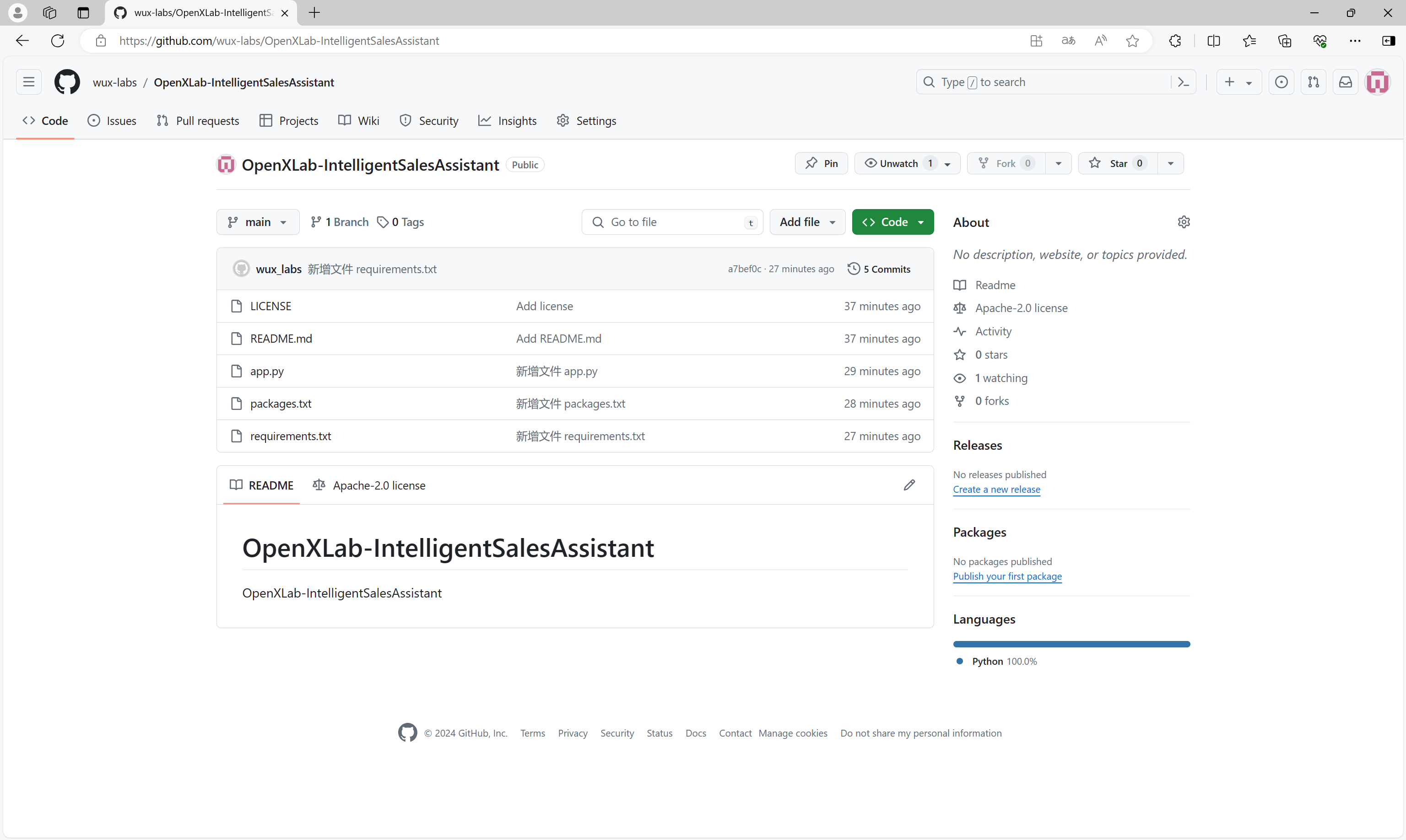
首先,在Github上创建一个项目仓库,将项目文件上传到仓库中,文件包含:
├─OpenXLab-IntelligentSalesAssistant
│ ├─app.py # 应用默认启动文件为app.py,应用代码相关的文件包含模型推理、前端配置代码
│ ├─requirements.txt # 安装运行所需要的 Python 库依赖(pip 安装)
│ ├─packages.txt # 安装运行所需要的 Debian 依赖项( apt-get 安装)
| ├─README.md # 编写应用相关的介绍性的文档
│ └─...
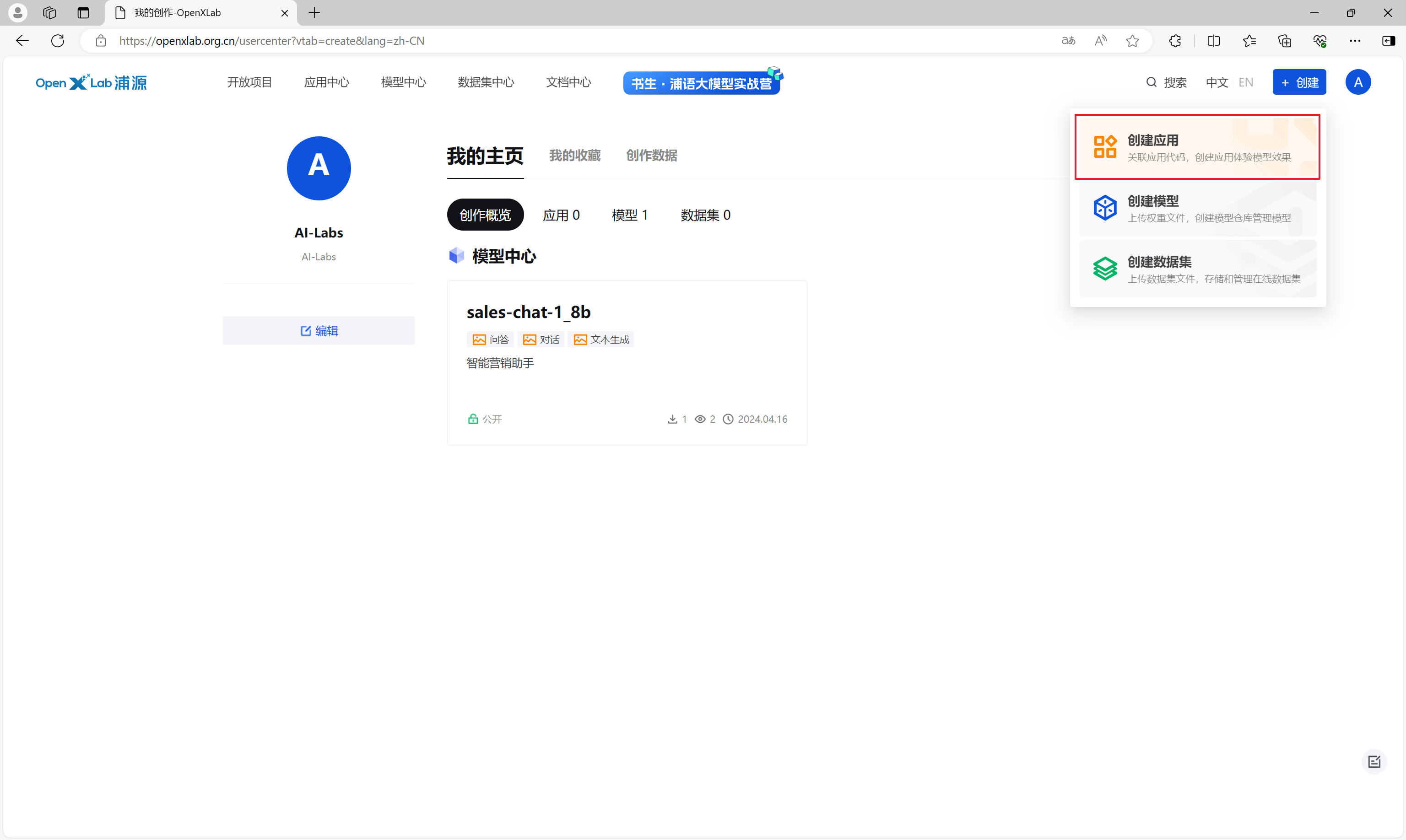
在OpenXLab,点击创建,创建应用。
在弹出的对话框中,选择应用类型是Streamlit。
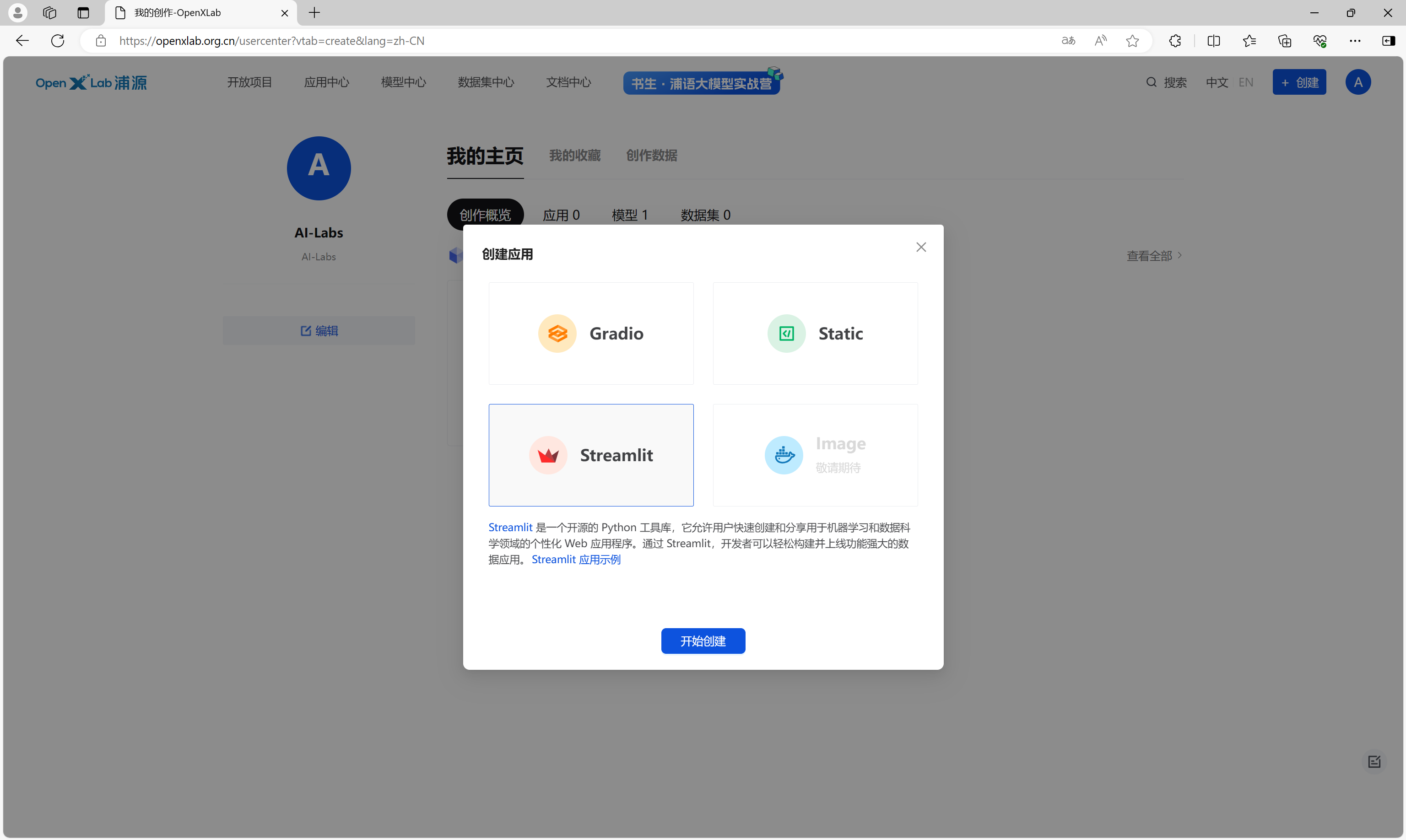
在详情页面,输入应用的详细信息、指定Github仓库地址、选择应用协议和硬件资源等信息,点击立即创建。
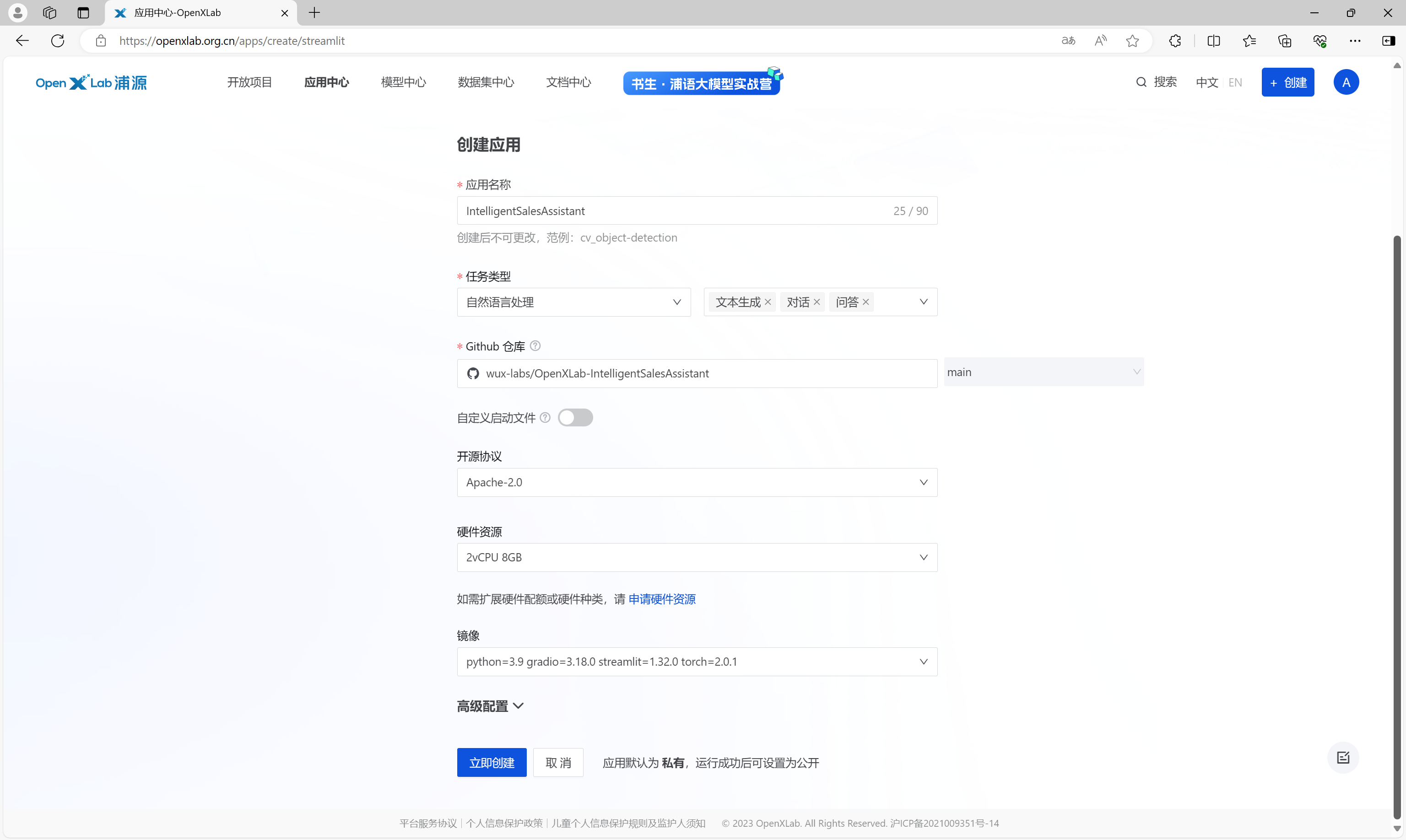
接下来,等待代码拉取、构建、应用启动。
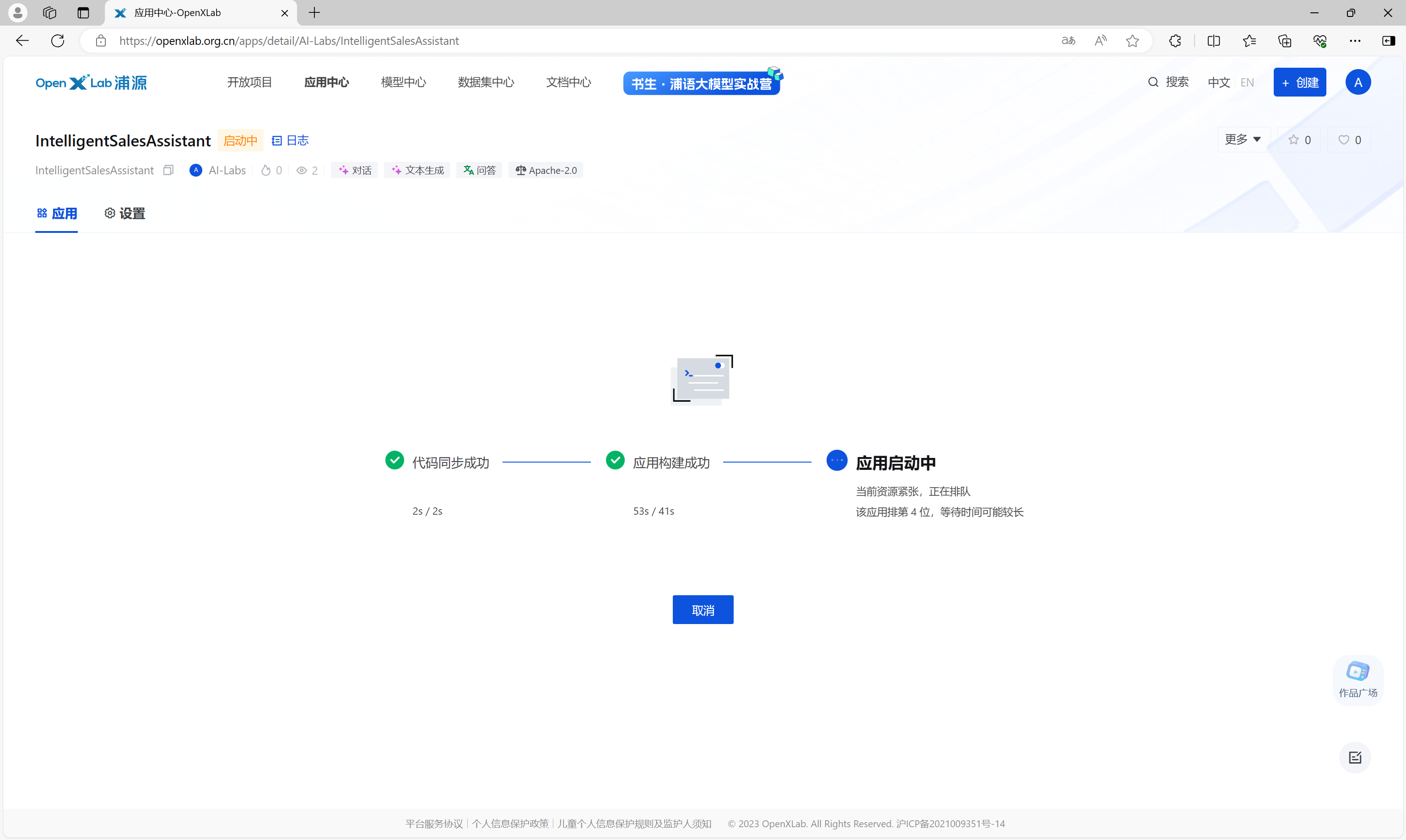
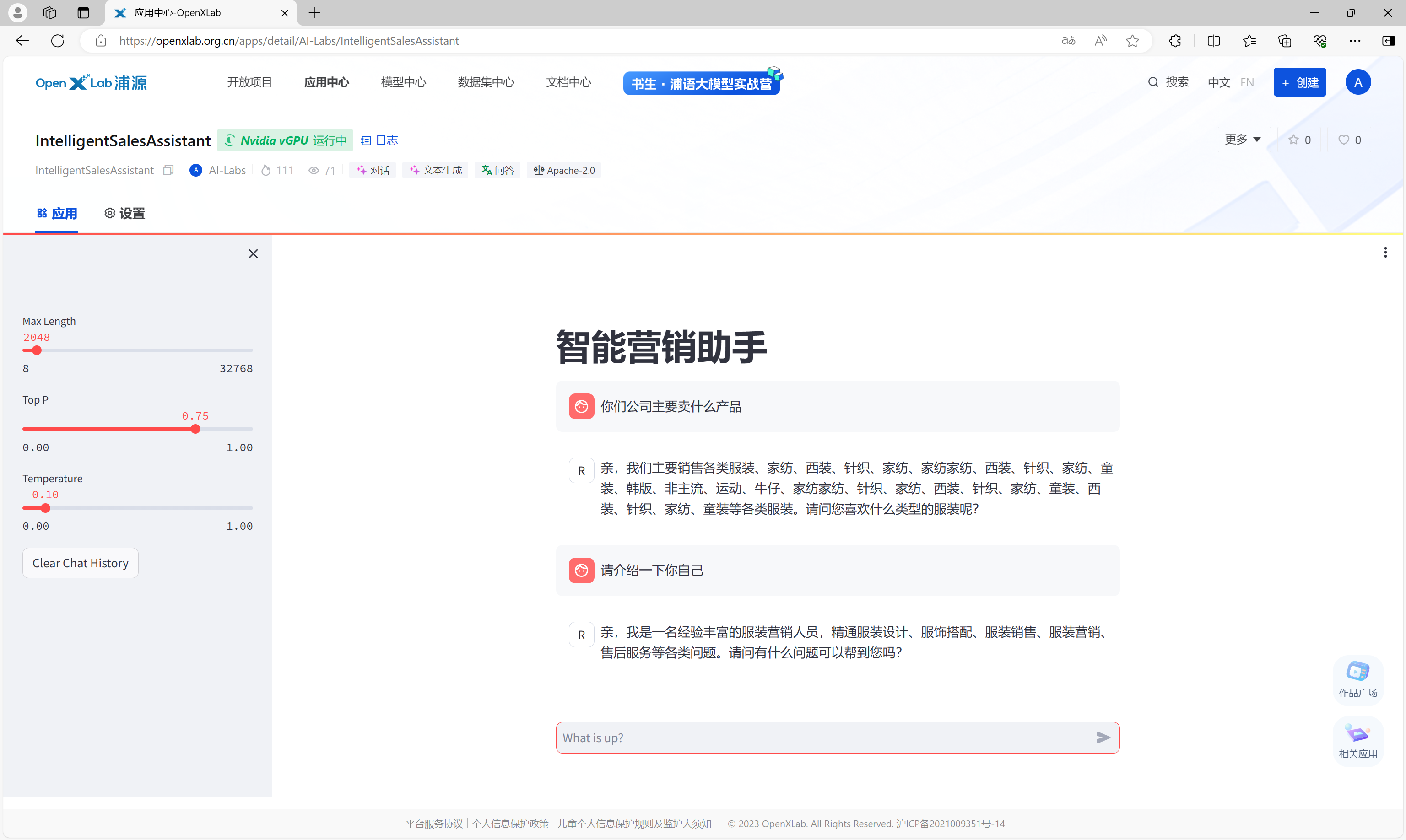
应用启动完成后,即可正常访问使用。
应用地址:https://openxlab.org.cn/apps/detail/AI-Labs/IntelligentSalesAssistant
使用XTuner微调多模态LLM
前期准备
激活用于微调的虚拟环境,创建一个新的目录,复制官方提供的多模态微调配置脚本,用于进行多模态微调。
准备一幅用于微调的图片。
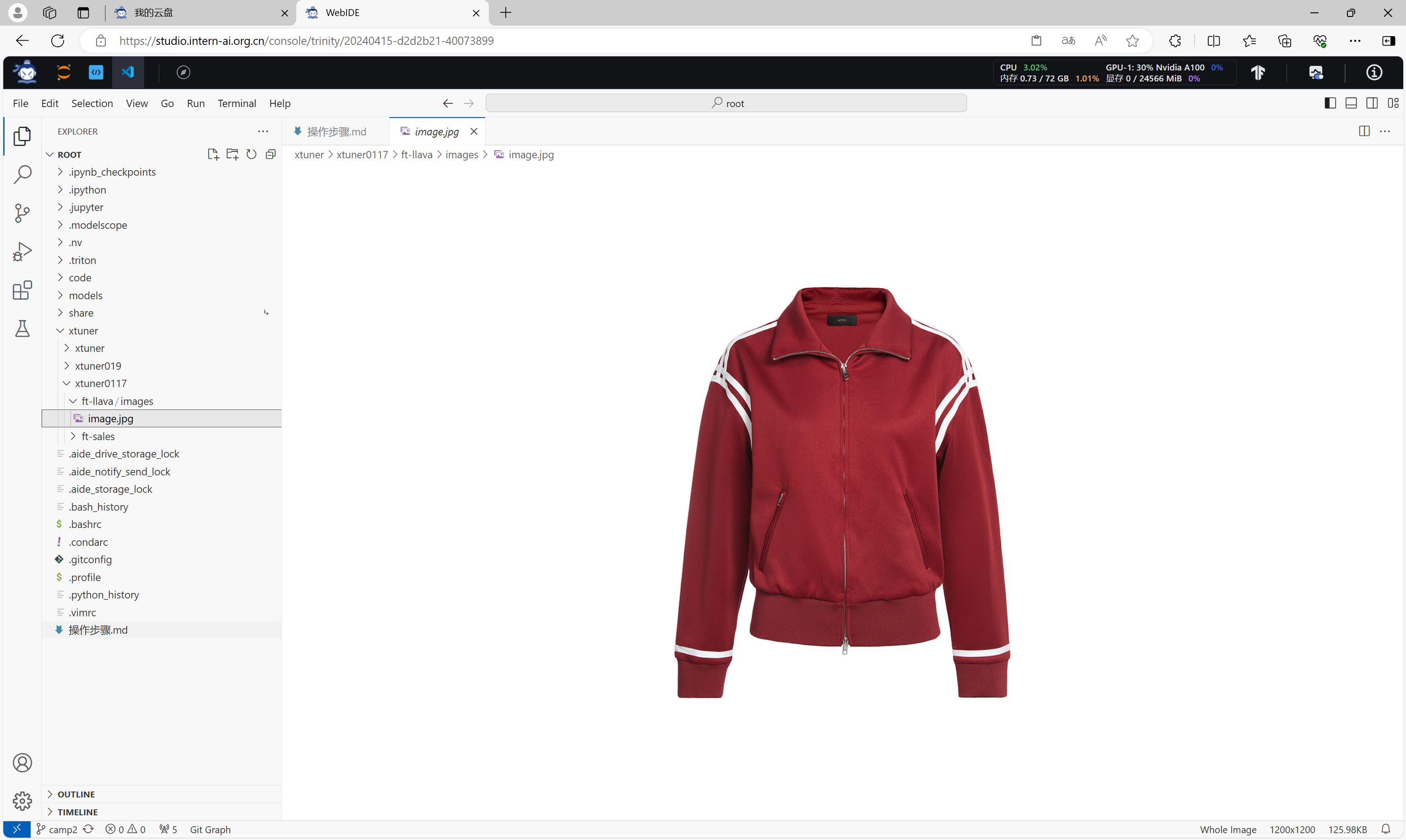
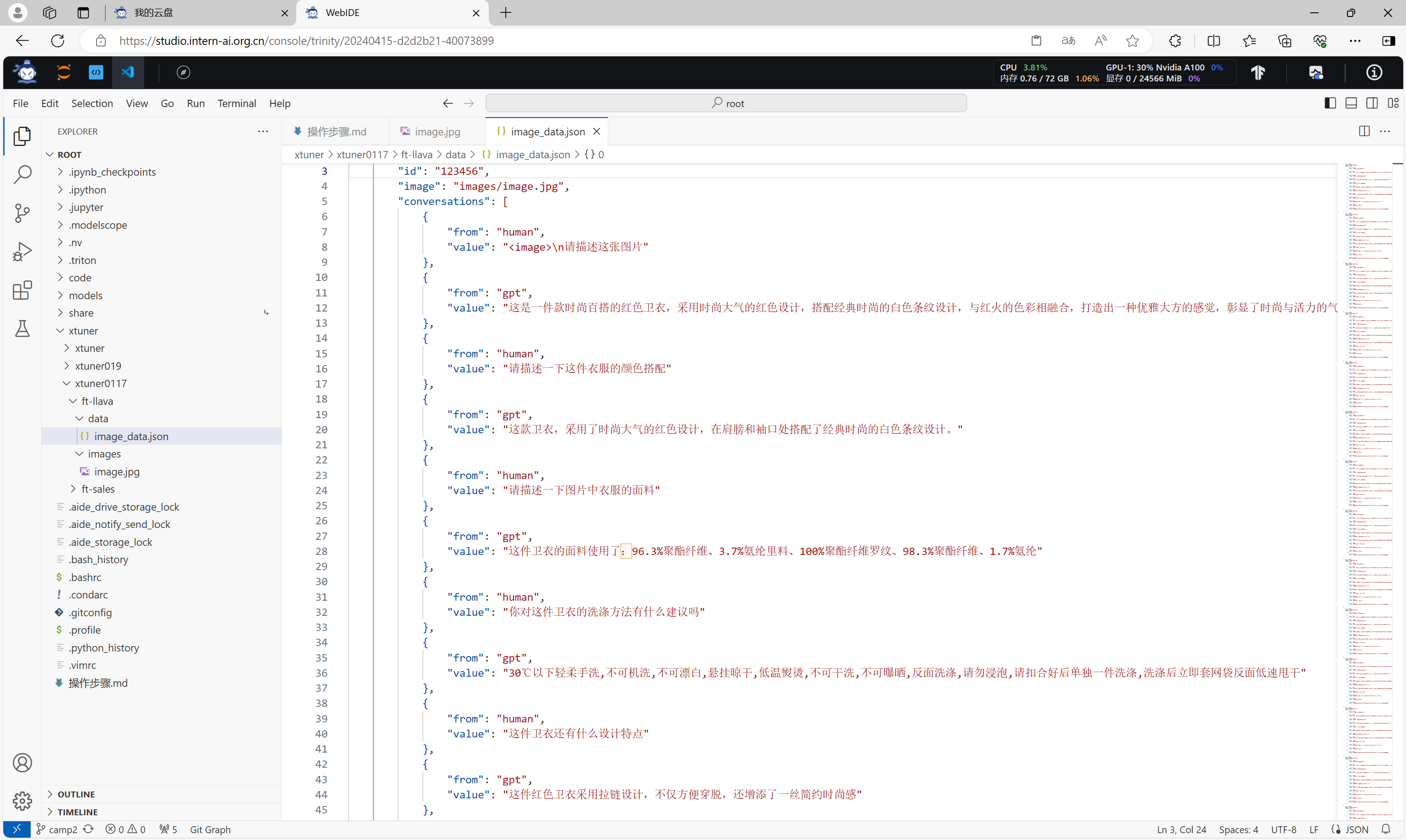
准备对于该图片的微调数据集。
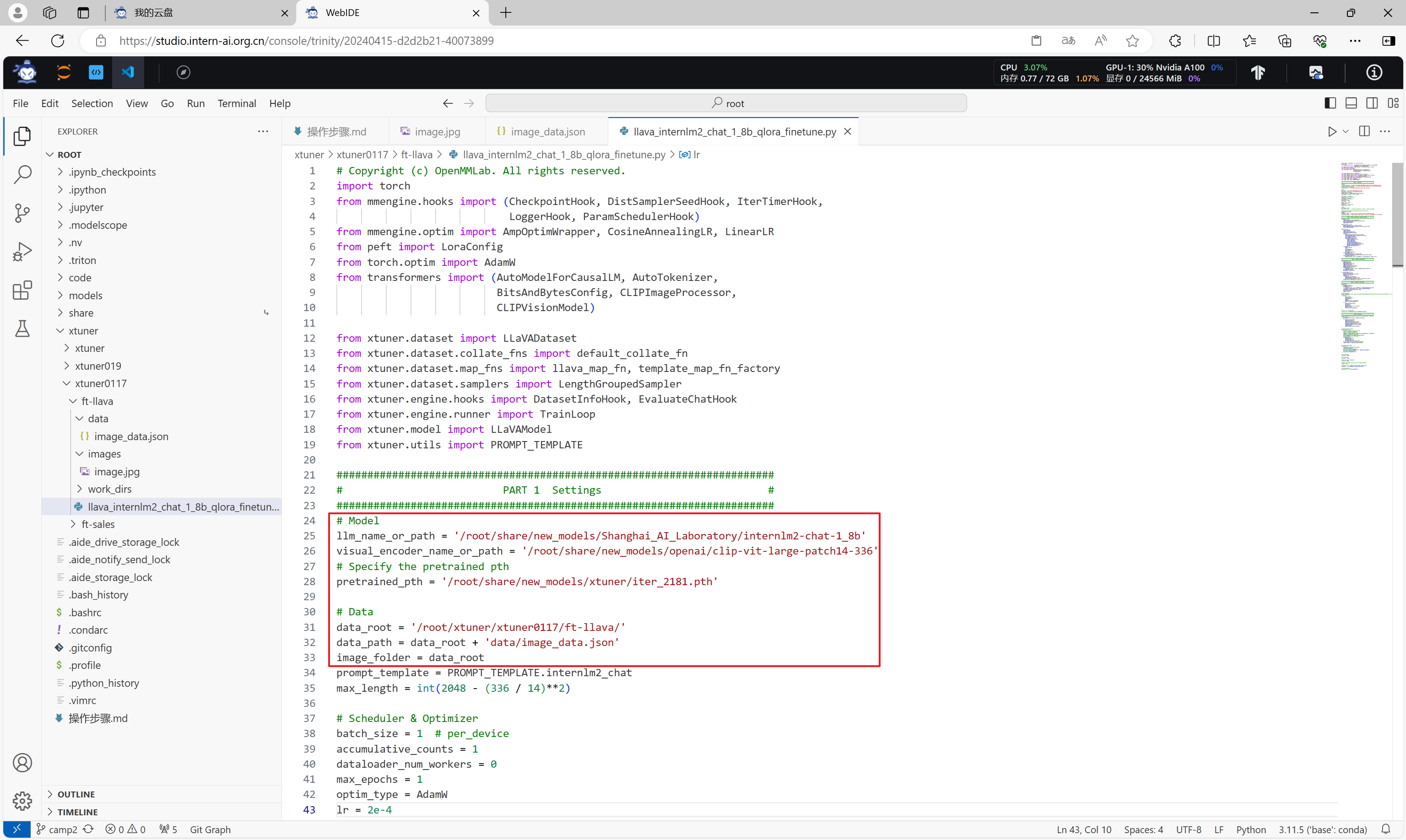
对微调配置脚本进行修改,主要修改其中的模型路径、数据集路径、图片路径等信息。
启动微调
执行命令启动微调。
xtuner train llava_internlm2_chat_1_8b_qlora_finetune.py
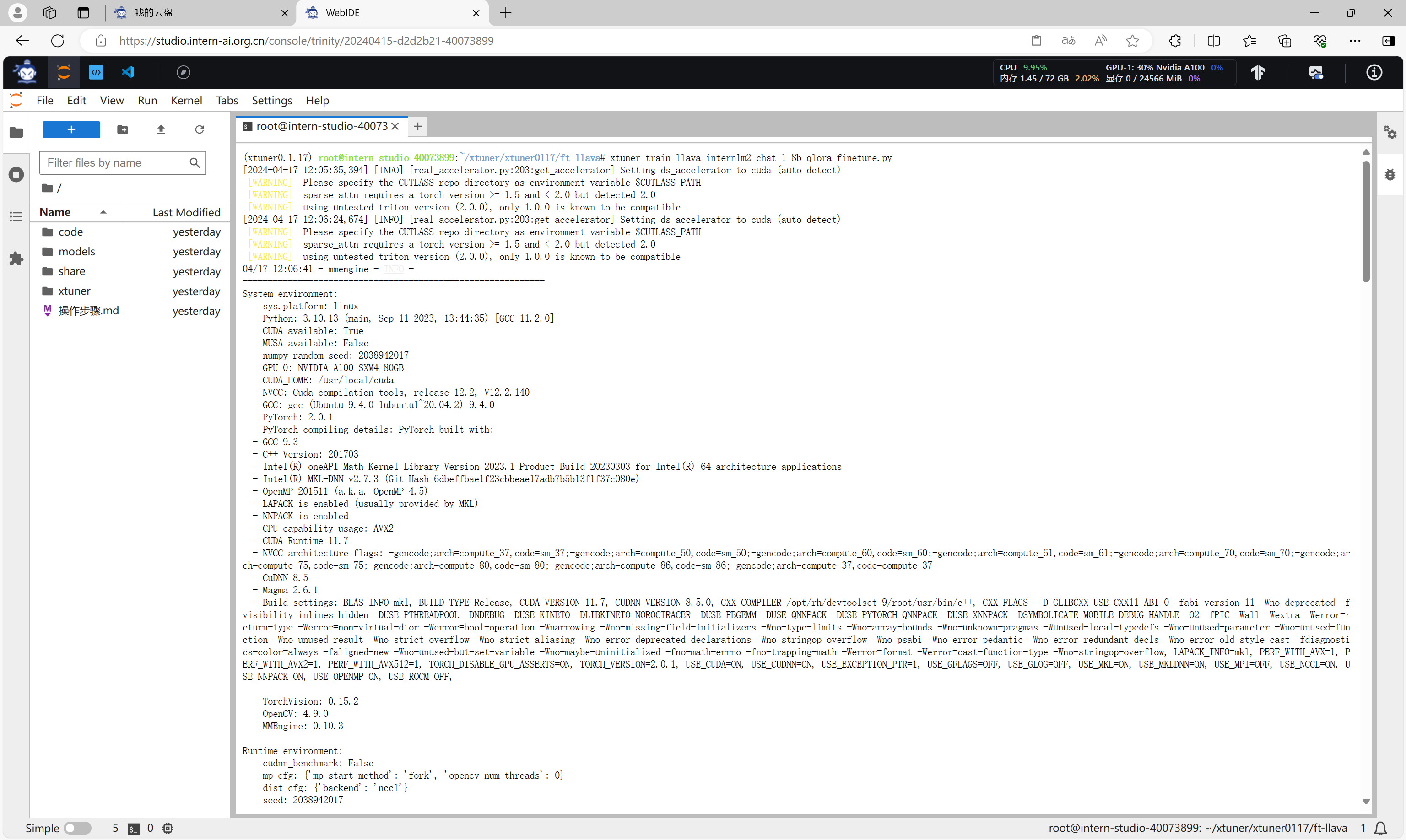
加载模型。
加载数据集。
执行微调并进行评估。
微调完成后,在work_dirs目录下会生成一个*.pth文件,这个就是微调的结果文件。
结果验证
微调前的模型验证
执行命令,将微调前的*.pth文件转换成HuggingFace格式的文件。
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNUxtuner convert pth_to_hf llava_internlm2_chat_1_8b_clip_vit_large_p14_336_e1_gpu8_pretrain /root/share/new_models/xtuner/iter_2181.pth iter_2181_hf
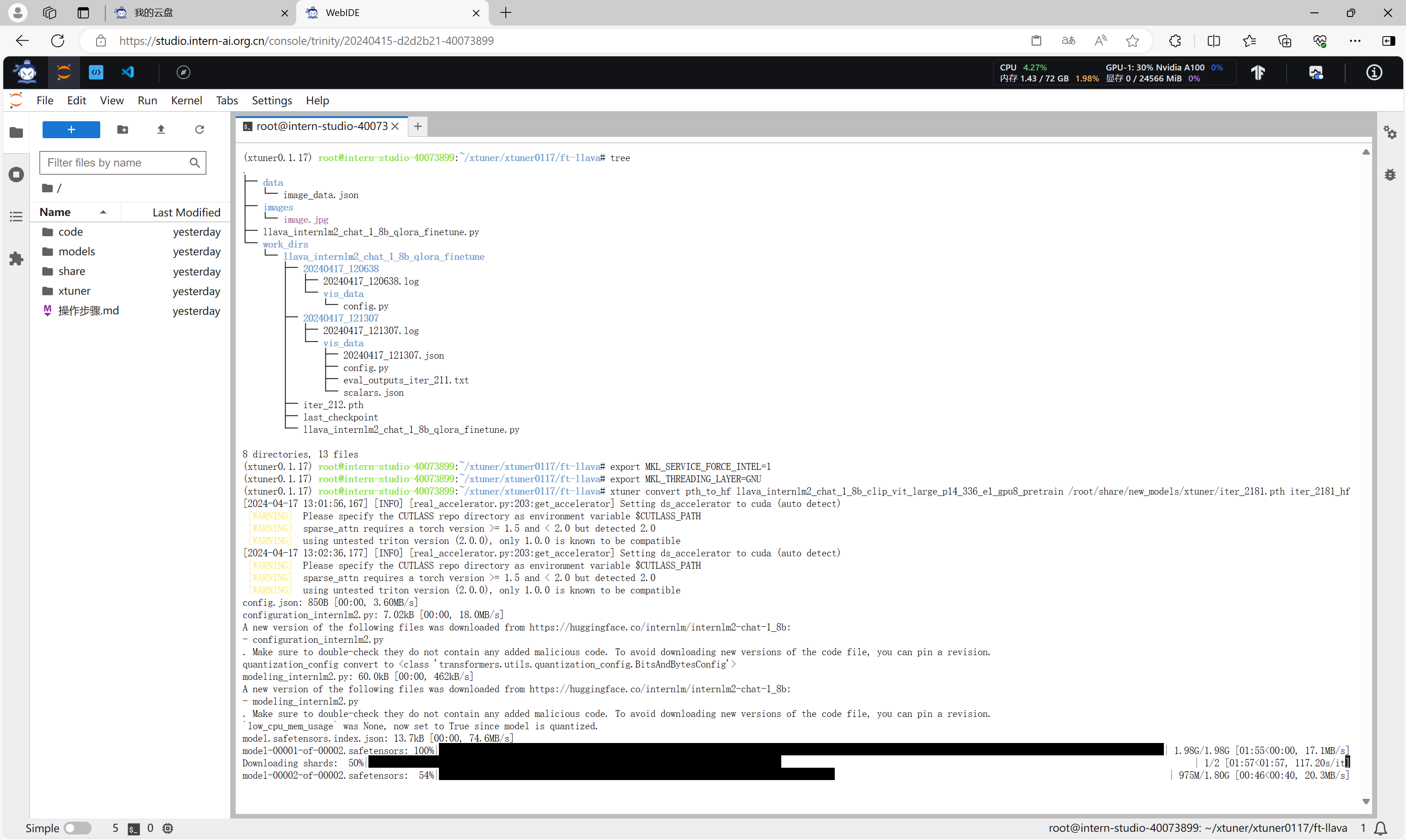
转换完成。
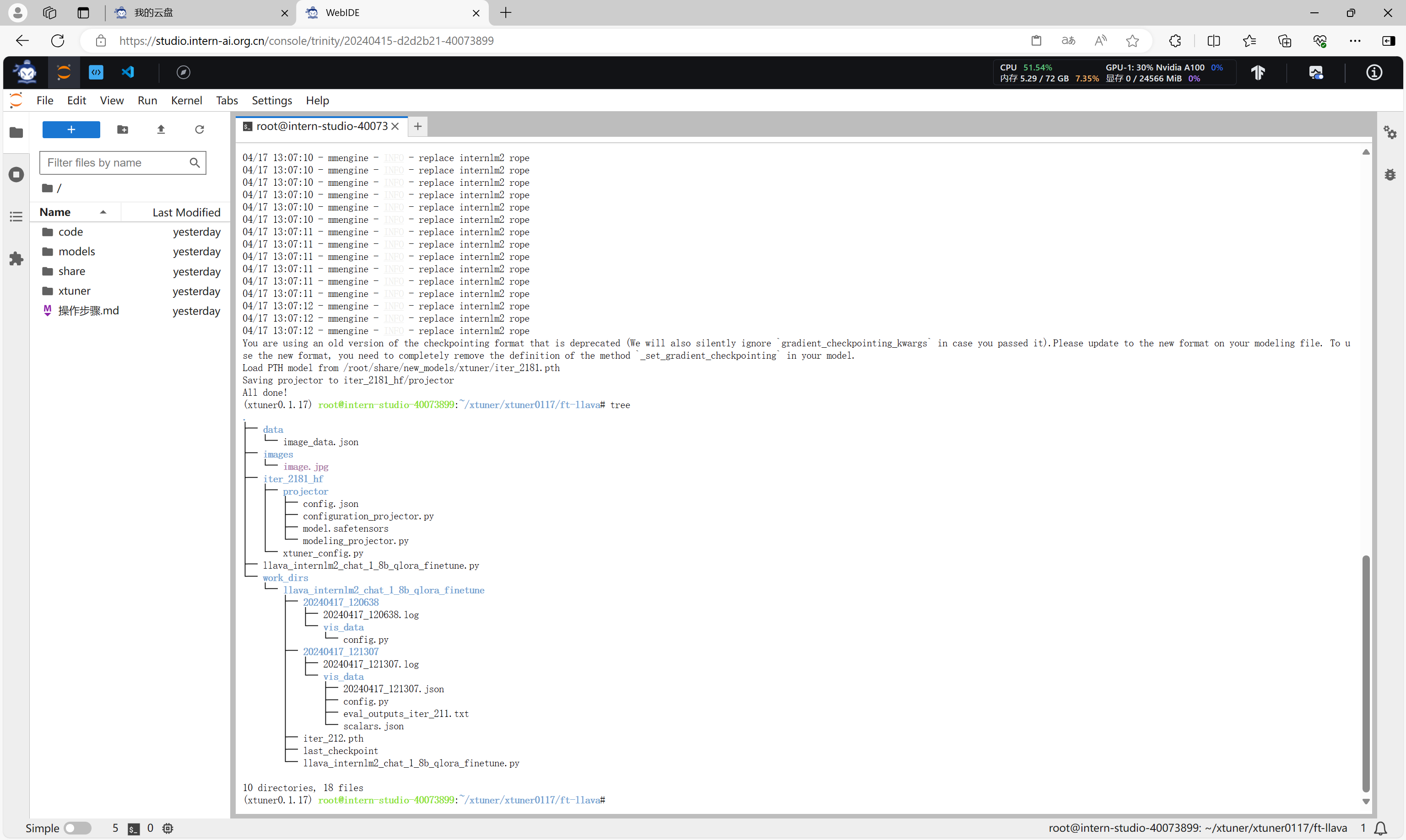
通过xtuner chat命令可以与微调前的模型进行对话。
xtuner chat /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --visual-encoder /root/share/new_models/openai/clip-vit-large-patch14-336 --llava iter_2181_hf --prompt-template internlm2_chat --image images/image.jpg
可以看到,微调前的模型只会标注图片。
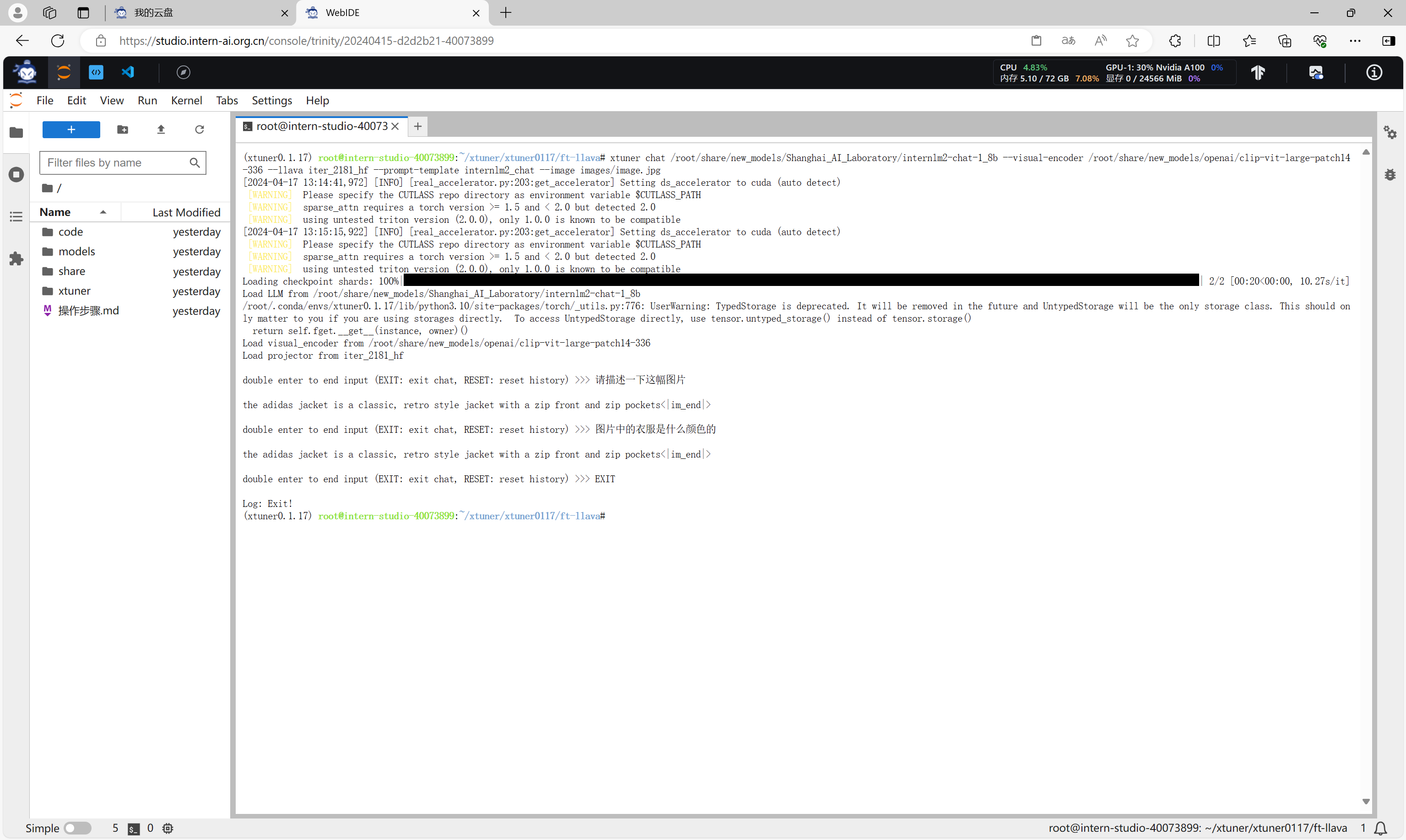
微调后的模型验证
执行命令,将微调后的*.pth文件转换成HuggingFace格式的文件。
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNUxtuner convert pth_to_hf llava_internlm2_chat_1_8b_qlora_finetune.py work_dirs/llava_internlm2_chat_1_8b_qlora_finetune/iter_212.pth iter_212_hf
转换完成。
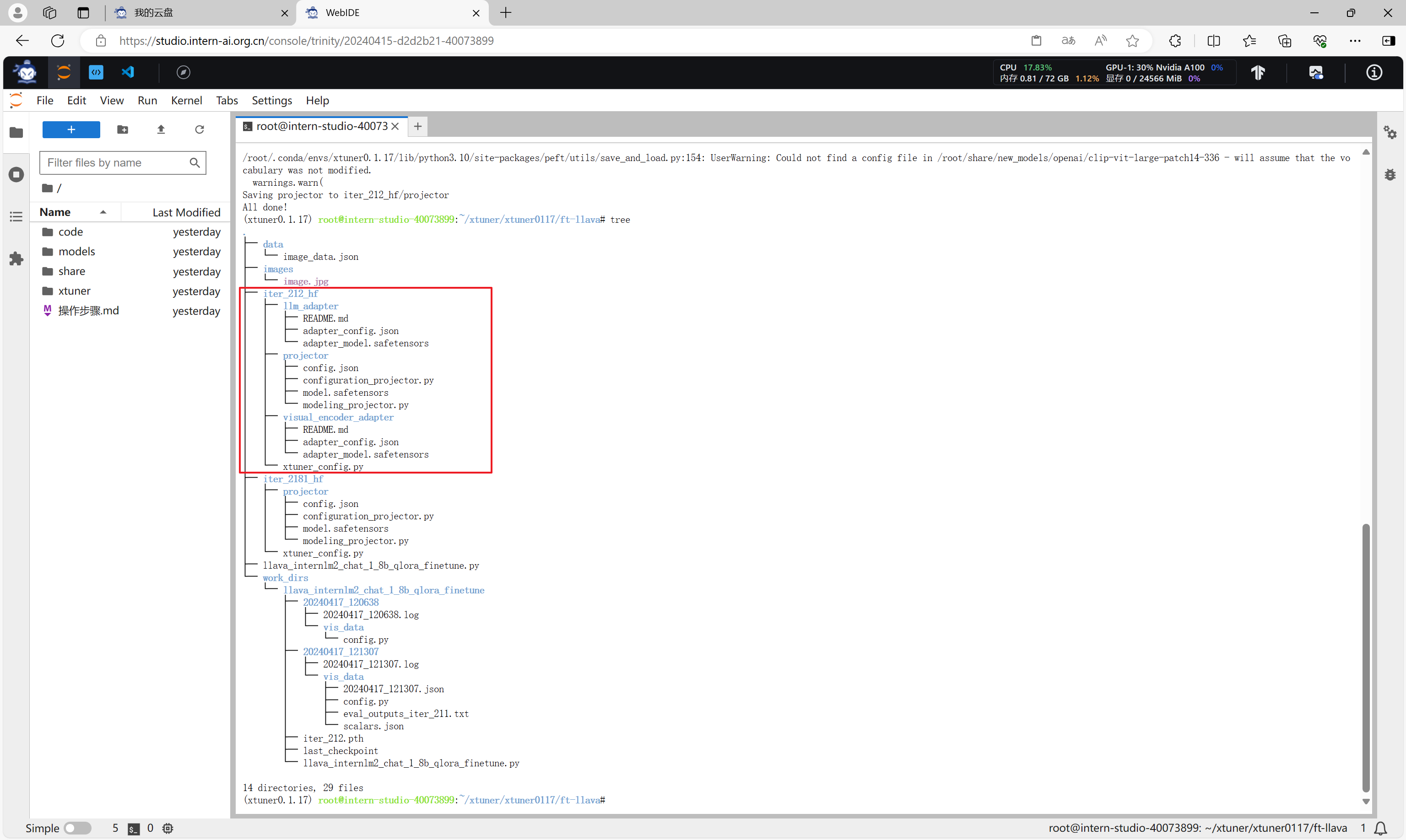
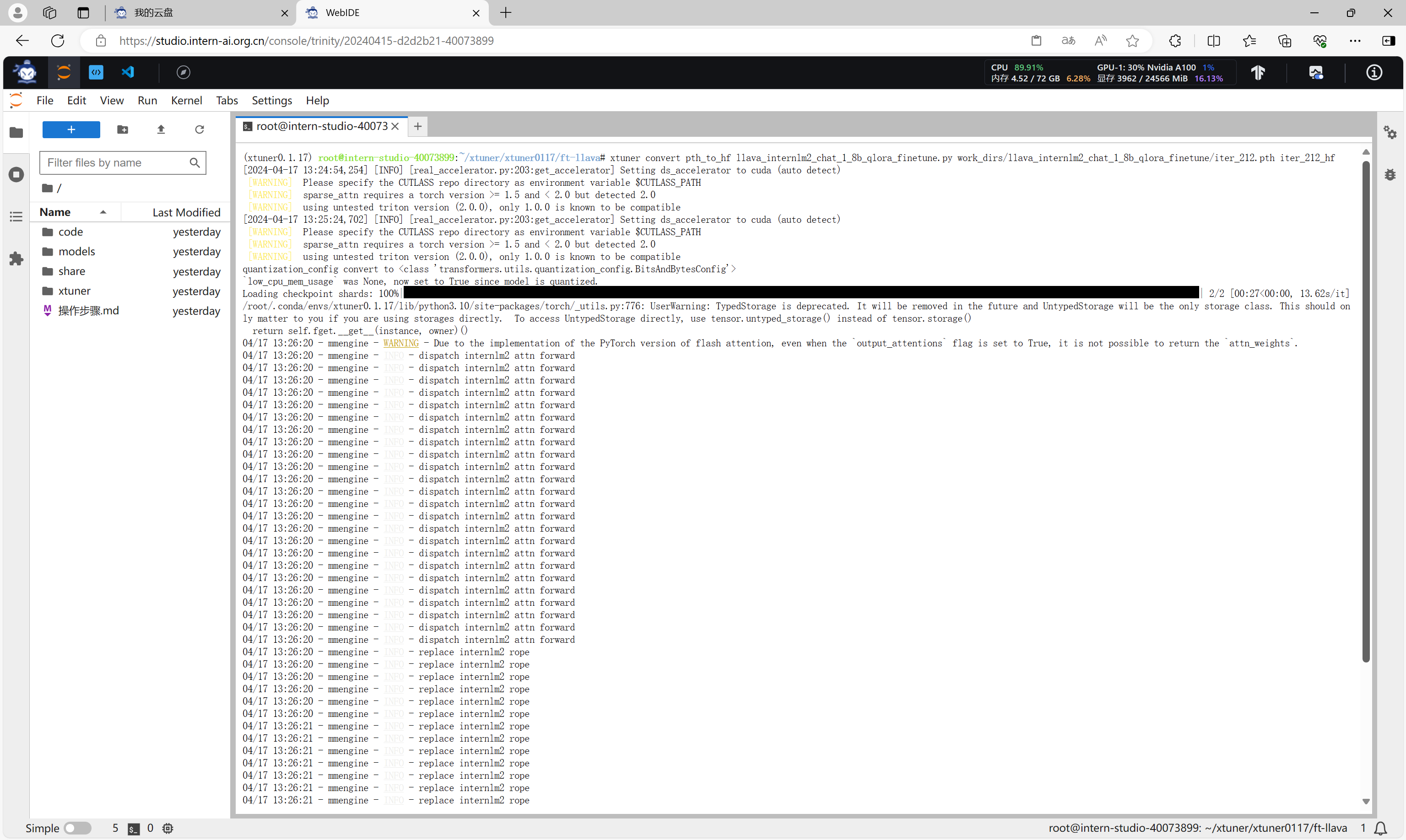
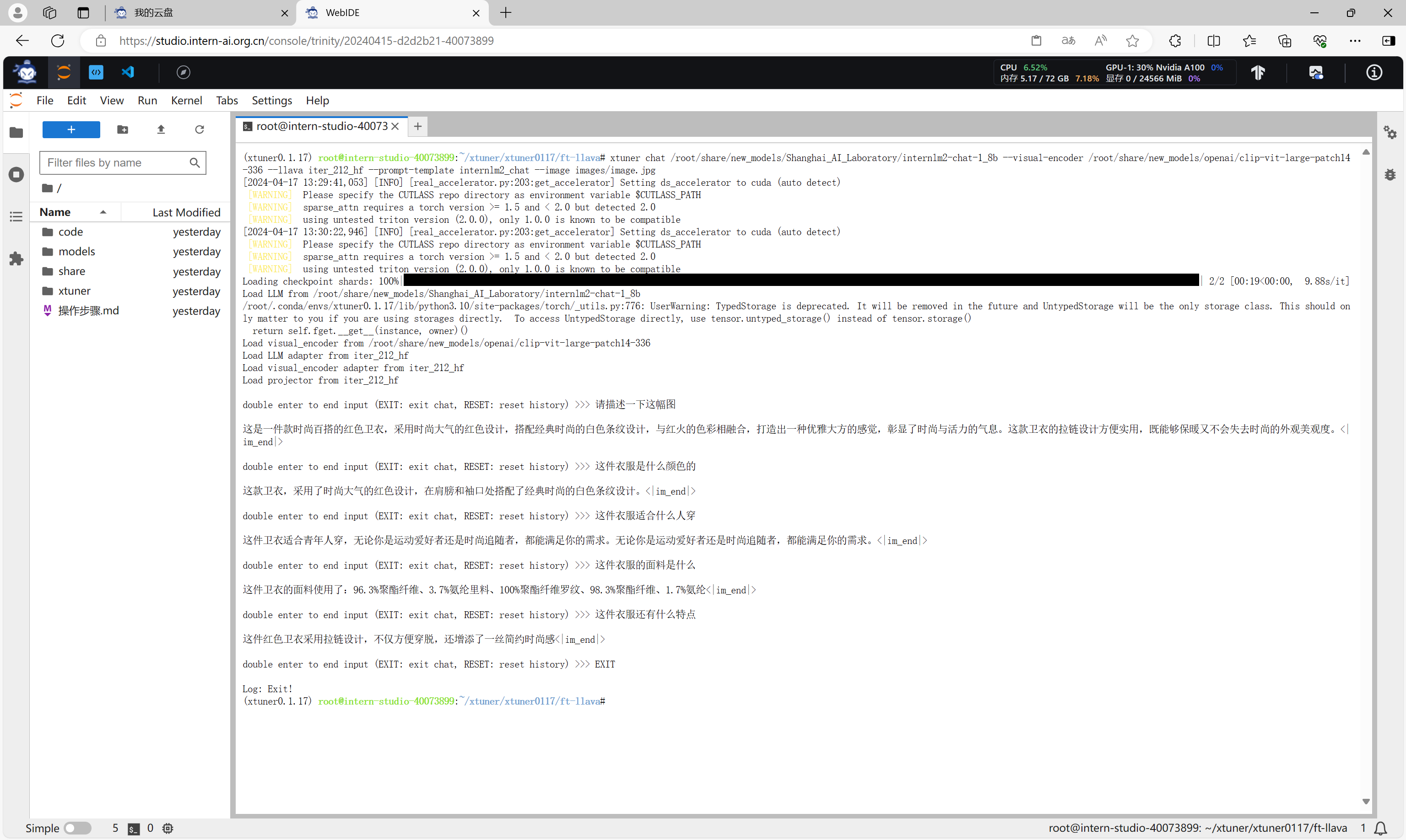
通过xtuner chat命令可以与微调前的模型进行对话。
xtuner chat /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --visual-encoder /root/share/new_models/openai/clip-vit-large-patch14-336 --llava iter_2181_hf --prompt-template internlm2_chat --image images/image.jpg
可以看到,,微调后的模型认识了该图片,并且能够描述、回答关于该图片的信息。
至此,使用XTuner微调大模型、多模态的内容完成。