- 主时钟约束命令/生成时钟约束命令
- IO输入输出延迟约束命令及效果
- 最大最小延迟命令及作用
- 多周期路径怎么约束
- 什么情况设置伪路径
- 时钟组设置的三个选项
如果不了解时序分析可以先看下下面这篇文章:
数字IC/FPGA——时序分析
目录
- 1.时钟约束
- (1)主时钟约束
- (2)生成时钟约束(Generated Clock)
- 2.IO延迟约束
- (1)输入延迟约束
- (2)输出延迟约束
- 3.最大/最小延迟
- (1)set_max_delay/set_min_delay
- (2)以格雷码多bit之间存在偏斜举例:
- (3)拿异步FIFO举例
- 4.多周期路径约束
- (1)多周期路径约束命令
- (2)为什么会有多周期路径约束
- (3)四种情况下的多周期路径约束
- 5.set_false_path
- (1)命令
- (2)设置伪路径的范围和原因
- (3)实例
- 6.set_clock_groups
- (1)命令
- (2)`set_clock_groups`和`set_false_path`的区别
- (3)实例
时序约束
时序引擎能够正确分析4种时序路径的前提是,用户已经进行了正确的时序约束。时序约束本质上就是告知时序引擎一些进行时序分析所必要的信息,这些信息只能由用户主动告知,时序引擎对有些信息可以自动推断,但是推断得到的信息不一定正确。
●第一种路径需要约束Input_delay;
●第二种路径需要约束时钟;
●第三种路径需要约束output_delay;
●第四种路径需要约束Max_delay/Min_delay;

主要有如下几种约束命令:
- create_clock
- create_generate_clock
- set_input_delay
- set_output_delay
- set_multicycle_path
- set_false_path
- set_clock_groups
1.时钟约束
首先用户必须要正确的约束时钟,时序引擎才能根据时钟信息进行各种时序检查。
用户约束时钟时,一般有两种类型的时钟需要约束,分别通过create_clock 和create_generate_clock进行约束。
(1)主时钟约束
主时钟(Primary Clock)有两种类型:第一种是从FPGA的全局时钟输入引脚输入的时钟;第二种是从高速收发器输出给用户的恢复时钟,使用Create_clock进行时序约束。主时钟周期时钟约束主要包括三个要素:时钟周期,占空比和时钟源。使用create_clock命令进行约束,-name规定了时钟名,-period规定时钟周期(单位ns),-waveform规定了占空比,get_ports规定了时钟源。
下面举两个例子:
①从FPGA的全局时钟输入引脚输入的时钟
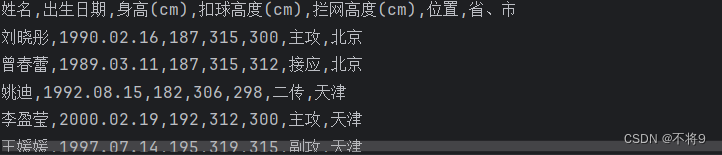
全局时钟输入引脚是sysclk,时钟周期10ns,占空比50%,相移0度
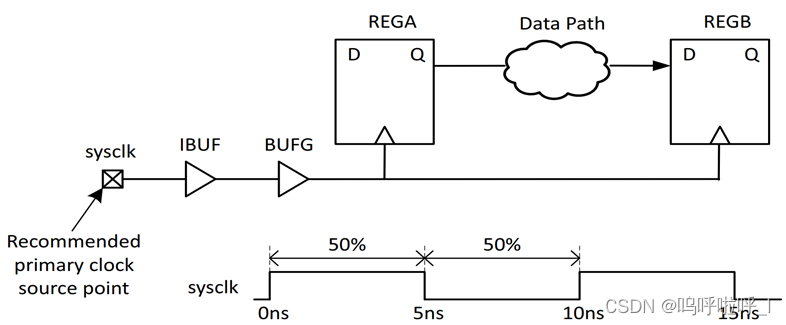
create_clock -period 10 [get_ports sysclk]
(get_ports sysclk命令为指定时钟源节点)
●全局时钟输入引脚是ClkIn,时钟周期10ns,占空比25%,相移90度
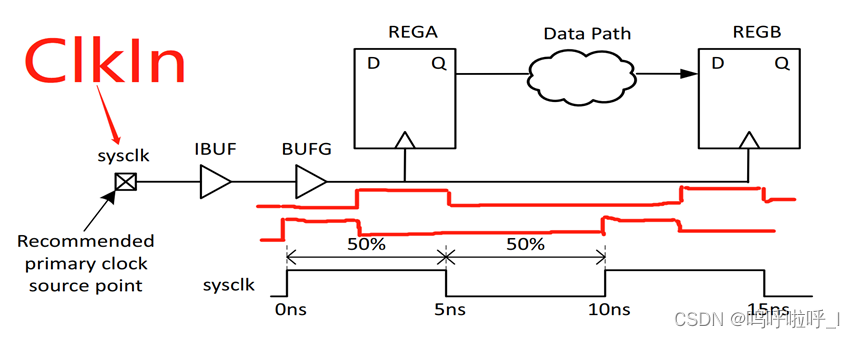
create_clock -name devclk -period 10 -waveform{2.5 5} [get_ports ClkIn]
-name devclk为该时序约束指定名字-waveform{2.5 5}为时钟指定第一个上升沿和第一个下降沿时间点。
②从高速收发器输出给用户的恢复时钟
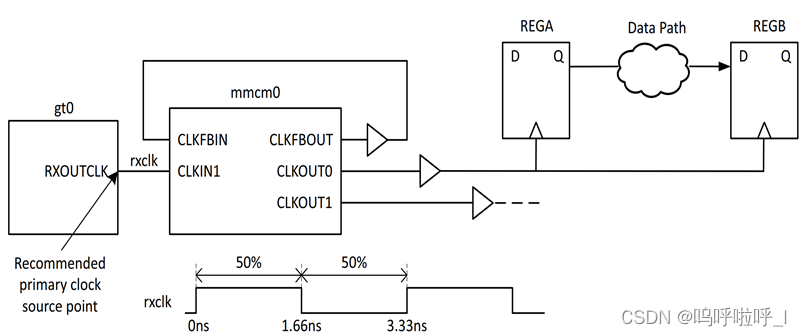
create_clock -name rxclk -period 3.33 [get_pins gt0/RXOUTCLK]
(2)生成时钟约束(Generated Clock)
生成时钟(Generated Clock)有两种类型:第一种是由FPGA的专用时钟管理模块(PLL/MMCM)产生的时钟(这种时钟可以由时序引擎自动推断出来,不需要用户手动约束);第二种是由用户通过LUT或寄存器产生的时钟(这种时钟必须由用户手动约束)。
生成时钟通常都是由某个主时钟源衍生而来的时钟,所以生成时钟周期约束包括三个要素:分频比,主时钟源,生成时钟源。使用create_generate_clock命令进行约束,-name规定时钟名,-source规定主时钟源,-divide_by规定分频比,get_pins(注意不是get_ports)规定生成时钟源。
下面举几个例子:
①由触发器实现的二分频电路
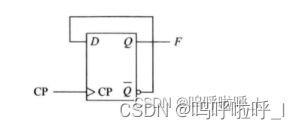
create_generate_clock -name F -source [get_pins REGA/CP] -divide_by 2 [get_pins REGA/Q]
②二选一时钟选择器的输出时钟
create_generate_clock -name clk0mux -source [get_pins mux/I0] -divide_by 1 [get_pins mux/O]
create_generate_clock -name clk1mux -source [get_pins mux/I1] -divide_by 1 -add [get_pins mux/O]
set_clock_groups -physically_exclusive -group clk0mux -group clk1mux
选择器的生成时钟的主时钟源可能是clk0mux也可能是clk1mux,因此需要两行约束来指定不同的主时钟源,需要注意的是在第二行指定主时钟源时在-divide_by 后加上了-add,否则会覆盖掉第一行的约束。
此外,还需要使用set_clock_groups -physically_exclusive将两个生成时钟分组,表示两个生成时钟在某一时刻下只有一个有效。
2.IO延迟约束
IO延迟约束主要包括输入延迟约束和输出延迟约束。
为什么需要有IO延迟约束呢?
IOP延迟约束针对的是第一种时序路径(从FPGA的输入端口到目的寄存器的数据输入端口)、第三种(从源寄存器的时钟端口到FPGA的输出端口)、第四种时序路径(从FPGA的输入端口到FPGA的输出端口)。
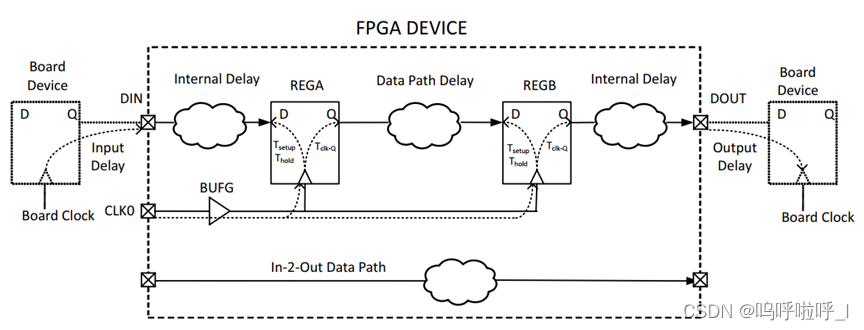
对于第一种时序路径来说,没有源时钟路径,需要约束Input Delay和时钟来告知时序引擎必要信息,这些信息包括PCB板的走线时延和外部设备的Tco(对应数据路径的延迟)、外部时钟和第一级寄存器的时钟偏差。
对第三种时序路径来说,没有目的时钟路径,需要约束Output Delay和时钟来告知时序引擎必要信息,这些信息包括PCB板的走线时延、外部器件与最后一级寄存器的时钟偏差、外部器件的建立时间。
第四种时序路径,数据横穿FPGA,没有经过任何触发器,这种路径也叫in-to-out path,约束输入和输出延时的参考时钟可以使用虚拟时钟。这种路径中只有数据路径,用户需要约束Input Delay和Output Delay,告知时序引擎必要的信息,时序引擎才能正确的分析这种时序路径。
接下来结合图示,具体分析:
(1)输入延迟约束
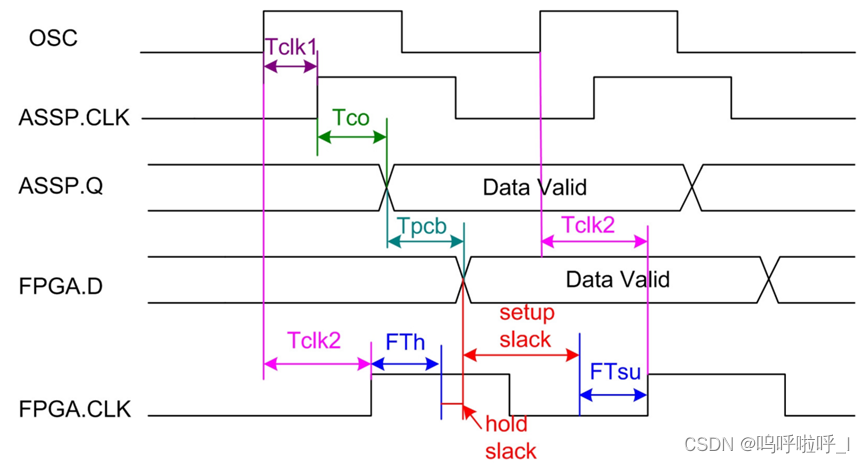
输入延时指的是从外部器件发送数据到FPGA的输入端口之间的延时。其中包括时钟源(CLK)到FPGA和到外部器件的延时差(Tskew),外部器件的数据传输时间(Tco),PCB板的走线延时(Tpcb)。Tskew等于时钟源到FPGA的延时减去时钟源到外部器件的延时。
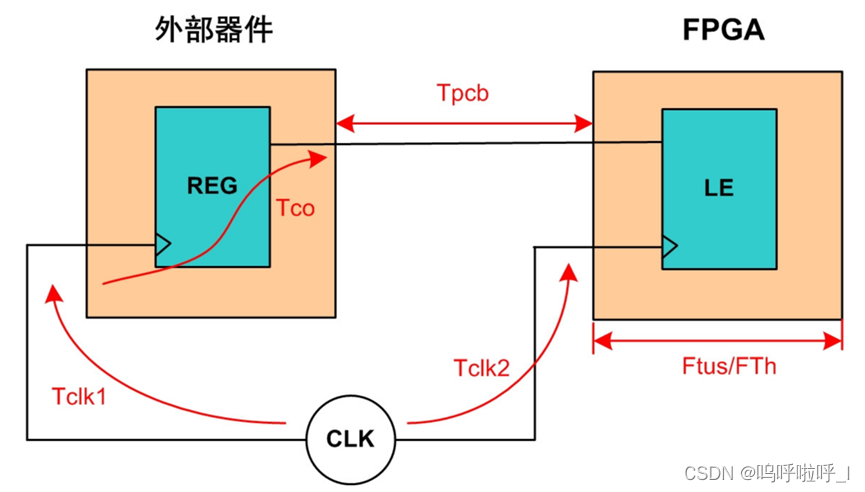
①最大输入延迟
最大输入延迟保证的是在输入延迟最大的情况下,数据要在FPGA内部第一级寄存器的建立时间要求之前达到。
利用建立时间裕量>0我们可知:
S e t u p s l a c k = ( R e q u i r e d t i m e − A r r i v e t i m e ) ≥ 0 = T c l k 2 + T ( 周期 ) − T s u − ( T c l k 1 + T c o (外部器件) + T p c b ) ≥ 0 Setupslack=(Requiredtime-Arrivetime)\geq0\\ = Tclk2+T(周期)-Tsu-(Tclk1+Tco(外部器件)+Tpcb)\geq0 Setupslack=(Requiredtime−Arrivetime)≥0=Tclk2+T(周期)−Tsu−(Tclk1+Tco(外部器件)+Tpcb)≥0
我们将未知信息放在一边,经过移项:
T c l k 2 + T ( 周期 ) − T s u − ( T c l k 1 + T c o + T p c b ) ≥ 0 T − T s u ≥ T c o (外部器件) + T p c b + ( T c l k 1 − T c l k 2 ) Tclk2+T(周期)-Tsu-(Tclk1+Tco+Tpcb)\geq0\\ T-Tsu\geq Tco(外部器件)+Tpcb+(Tclk1-Tclk2) Tclk2+T(周期)−Tsu−(Tclk1+Tco+Tpcb)≥0T−Tsu≥Tco(外部器件)+Tpcb+(Tclk1−Tclk2)
我们可以发现,不等式左边是时序引擎已知的,而右边的Tco、Tpcb、以及时钟偏差Tclk1-Tclk2(外部时钟路径延迟-FPGA寄存器时钟路径延)是未知的,将他们共同包含在Input_delay内。因此最终如下:
I n p u t d e l a y = T c o (外部器件) + T p c b + ( T c l k 1 − T c l k 2 ) I n p u t d e l a y ( m a x ) = T c o (外部器件) + T p c b m a x + ( T c l k 1 m a x − T c l k 2 m i n ) ≤ T − T s u Inputdelay= Tco(外部器件)+Tpcb+(Tclk1-Tclk2) \\ Inputdelay(max)= Tco(外部器件)+Tpcb_{max}+(Tclk1_{max}-Tclk2_{min}) \leq T-Tsu Inputdelay=Tco(外部器件)+Tpcb+(Tclk1−Tclk2)Inputdelay(max)=Tco(外部器件)+Tpcbmax+(Tclk1max−Tclk2min)≤T−Tsu
当对最大输入延时进行约束后,工具会尽可能的对输入端口到第一级寄存器之间的路径延迟进行优化(尽量减小Tsu,使其小于其最大值,这样使得不等式更容易成立),来确保在最大输入延时的情况下,输入端口的数据也能够满足FPGA的建立时间要求。
②最小输入延迟
最小输入延迟保证的是在输入延迟最小的情况下依然能够满足保持时间要求。
利用保持时间裕量>0我们可知:
H o l d u p s l a c k = ( A r r i v e t i m e − R e q u i r e d t i m e ) ≥ 0 = ( T c l k 1 + T c o (外部器件) + T p c b ) − ( T c l k 2 + T h ) ≥ 0 = T c l k 1 − T c l k 2 + T c o (外部器件) + T p c b ≥ T h Holdupslack=(Arrivetime-Requiredtime)\geq0\\ = (Tclk1+Tco(外部器件)+Tpcb)-(Tclk2+Th)\geq0\\ =Tclk1-Tclk2+Tco(外部器件)+Tpcb\geq Th Holdupslack=(Arrivetime−Requiredtime)≥0=(Tclk1+Tco(外部器件)+Tpcb)−(Tclk2+Th)≥0=Tclk1−Tclk2+Tco(外部器件)+Tpcb≥Th
我们可以发现,不等式右边是时序引擎已知的,而左边的Tco、Tpcb、以及时钟偏差Tclk1-Tclk2是未知的,将他们共同包含在Input_delay内。因此最终如下:
I n p u t d e l a y = T c o (外部器件) + T p c b + ( T c l k 1 − T c l k 2 ) I n p u t d e l a y ( m i n ) = T c o (外部器件) + T p c b m i n + ( T c l k 1 m i n − T c l k 2 m a x ) ≥ T h Inputdelay= Tco(外部器件)+Tpcb+(Tclk1-Tclk2) \\ Inputdelay(min)= Tco(外部器件)+Tpcb_{min}+(Tclk1_{min}-Tclk2_{max}) \geq Th Inputdelay=Tco(外部器件)+Tpcb+(Tclk1−Tclk2)Inputdelay(min)=Tco(外部器件)+Tpcbmin+(Tclk1min−Tclk2max)≥Th
当对最小输入延时进行约束后,工具会尽可能的对输入端口到第一级寄存器之间的路径延迟进行优化(尽量减小Th,使得不等式更容易成立),来确保在最小输入延时的情况下,输入端口的数据也能够满足FPGA的保持时间要求。
(2)输出延迟约束
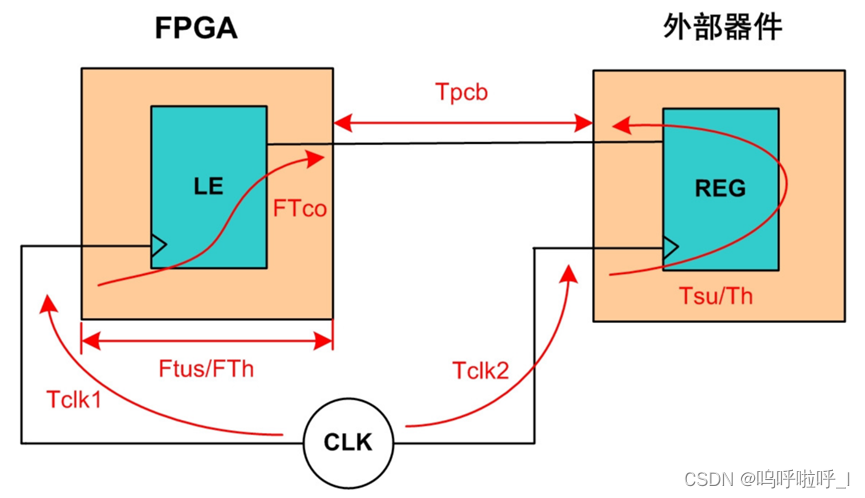
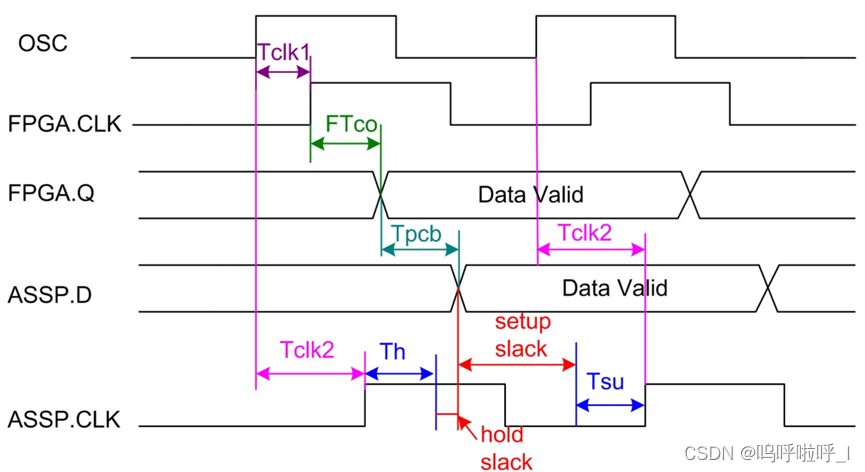
输出延时指的是从FPGA输出数据到外部器件的延时时间。其中包括时钟源(CLK)到外部器件和到FPGA的延时差(Tskew),PCB板的走线延时(Tpcb)和外部器件的建立时间和保持时间(Tsu/Th)。Tskew等于时钟源到外部器件的延时减去时钟源到FPGA的延时。
①最大输出延迟
最大输出延迟保证的是在输出延迟最大的情况下,数据要在外部器件建立时间要求之前达到。
利用建立时间裕量>0我们可知:
S e t u p s l a c k = ( R e q u i r e d t i m e − A r r i v e t i m e ) ≥ 0 = T c l k 2 + T ( 周期 ) − T s u (外部器件) − ( T c l k 1 + T c o + T p c b ) ≥ 0 Setupslack=(Requiredtime-Arrivetime)\geq0\\ = Tclk2+T(周期)-Tsu(外部器件)-(Tclk1+Tco+Tpcb)\geq0 Setupslack=(Requiredtime−Arrivetime)≥0=Tclk2+T(周期)−Tsu(外部器件)−(Tclk1+Tco+Tpcb)≥0
我们将未知信息放在一边,经过移项:
T c l k 2 + T ( 周期 ) − T s u (外部器件) − ( T c l k 1 + T c o + T p c b ) ≥ 0 T − T c o ≥ T p c b + T s u (外部器件) + ( T c l k 1 − T c l k 2 ) Tclk2+T(周期)-Tsu(外部器件)-(Tclk1+Tco+Tpcb)\geq0\\ T-Tco\geq Tpcb+Tsu(外部器件)+(Tclk1-Tclk2) Tclk2+T(周期)−Tsu(外部器件)−(Tclk1+Tco+Tpcb)≥0T−Tco≥Tpcb+Tsu(外部器件)+(Tclk1−Tclk2)
我们可以发现,不等式左边是时序引擎已知的,而右边的Tco、Tpcb、以及时钟偏差Tclk1-Tclk2(FPGA寄存器时钟路径延迟-外部时钟路径延迟,需要注意这里和最大输入延迟处相反)是未知的,将他们共同包含在Output_delay内。因此最终如下:
O u t p u t d e l a y = T s u (外部器件) + T p c b + ( T c l k 1 − T c l k 2 ) O u t p u t d e l a y ( m a x ) = T s u (外部器件) + T p c b m a x + ( T c l k 1 m a x − T c l k 2 m i n ) ≤ T − T c o Outputdelay= Tsu(外部器件)+Tpcb+(Tclk1-Tclk2) \\ Outputdelay(max)= Tsu(外部器件)+Tpcb_{max}+(Tclk1_{max}-Tclk2_{min}) \leq T-Tco Outputdelay=Tsu(外部器件)+Tpcb+(Tclk1−Tclk2)Outputdelay(max)=Tsu(外部器件)+Tpcbmax+(Tclk1max−Tclk2min)≤T−Tco
当对最大输出延时进行约束后,工具会尽可能的对最后一级寄存器到输出端口之间进行优化(尽量减小Tco,使得不等式更容易成立),来确保在最大输出延时的情况下,输入端口的数据也能够满足外部器件的建立时间要求。
②最小输出延迟
利用保持时间裕量>0我们可知:
H o l d u p s l a c k = ( A r r i v e t i m e − R e q u i r e d t i m e ) ≥ 0 = T c l k 1 + T c o + T p c b − ( T c l k 2 + T h (外部器件)) ≥ 0 Holdupslack=(Arrivetime-Requiredtime)\geq0\\ =Tclk1+Tco+Tpcb-(Tclk2+Th(外部器件))\geq0 Holdupslack=(Arrivetime−Requiredtime)≥0=Tclk1+Tco+Tpcb−(Tclk2+Th(外部器件))≥0
我们将未知信息放在一边,经过移项:
T c l k 1 + T c o + T p c b − ( T c l k 2 + T h (外部器件)) ≥ 0 T c l k 1 − T c l k 2 + T p c b − T h (外部器件) ≥ − T c o Tclk1+Tco+Tpcb-(Tclk2+Th(外部器件))\geq0\\ Tclk1-Tclk2+Tpcb-Th(外部器件)\geq-Tco Tclk1+Tco+Tpcb−(Tclk2+Th(外部器件))≥0Tclk1−Tclk2+Tpcb−Th(外部器件)≥−Tco
我们可以发现,不等式左边是时序引擎已知的,而右边的Tco、Tpcb、以及时钟偏差Tclk1-Tclk2是未知的,将他们共同包含在Input_delay内。因此最终如下:
O u t p u t d e l a y = T p c b − T h (外部器件) + ( T c l k 1 − T c l k 2 ) O u t p u t d e l a y ( m i n ) = T p c b m i n − T h (外部器件) + ( T c l k 1 m i n − T c l k 2 m a x ) ≥ − T c o Outputdelay= Tpcb-Th(外部器件)+(Tclk1-Tclk2) \\Outputdelay(min)= Tpcbmin-Th(外部器件)+(Tclk1_{min}-Tclk2_{max}) \geq -Tco Outputdelay=Tpcb−Th(外部器件)+(Tclk1−Tclk2)Outputdelay(min)=Tpcbmin−Th(外部器件)+(Tclk1min−Tclk2max)≥−Tco
当对最小输出延时进行约束后,工具会尽可能的对最后一级寄存器到输出端口之间进行优化(尽量增大Tco,使得不等式更容易成立),来确保在最小输出延时的情况下,输入端口的数据也能够满足外部器件的保持时间要求。
3.最大/最小延迟
(1)set_max_delay/set_min_delay
set_max_delay [-datapath_only] -from [ node_list] -to [node_list] delay_value
set_min_delay -from [ node_list] -to [node_list] delay_value
关于最大最小延迟看了很多文章,最后找到如下这篇文,可以说解释的很明白:
FPGA设计时序约束六、设置最大/最小时延 - 知乎 (zhihu.com)
异步信号之间从某种意义上来说,它们之间是没有确切的时序关系与时序要求的,但为了对从源端到目的端的数据传输延迟有一个基本限制,不至于让其延时不受控,因此采用set_max_delay可以对系统的时序性能做到一个基本的控制。

set_max_delay另一个常用的场景是没有时钟关系的异步信号,但需要设置最大时延。**两个异步时钟路径可以使用set_clock_group或set_false_path,从而不会进行时序分析。当异步时钟间的设计合理,如FIFO中的两级同步寄存器,要放宽约束,保证两个时钟间的路径延时符合实际情况,就需要使用set_max_delay。
CDC路径的时序分析可以通过使用set_false或set_clock_groups约束完全忽略,也可以通过使用set_max_delay datapath_only进行部分分析。虽然多bit之间的偏斜可以通过set_bus_skew来约束,但必须确保两个时钟域间的时延不能太大。此时可以通过约束set_max_delay -datapath_only代替set_false_path/set_clock_groups。

(2)以格雷码多bit之间存在偏斜举例:
格雷码在正常情况下跨时钟域如下:
若格雷码各bit之间偏斜过大,则会变成下图的情况,导致采样错误:
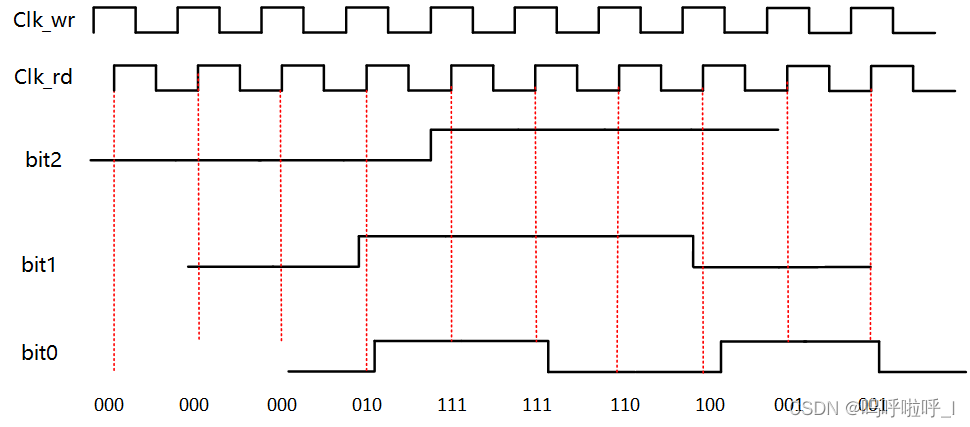
因此需要对格雷码的最大延时进行约束,延时可设置为读写时钟中最快时钟周期的一半,也可以设置成源端时钟的一半,或者设置成源端时钟的倍数且bit间的skew明显小于一个源端时钟周期,这样的话就能保证采样值和预想值一致。
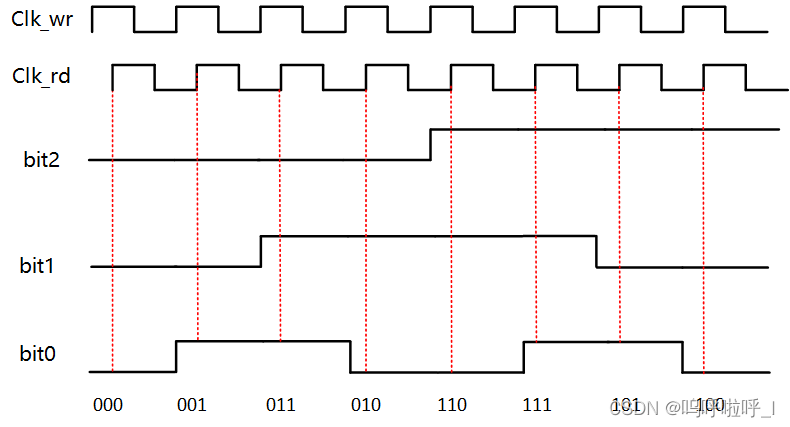
(3)拿异步FIFO举例
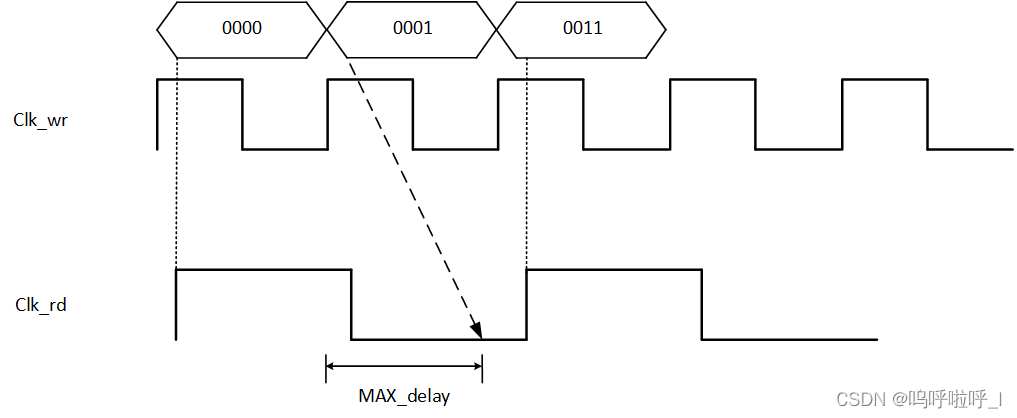
当读时钟域较慢时,写时钟域的写地址从0000>0001>0011,但是读时钟域之采样到了0000和0011,在相邻两次采样之间发生了两bit变换,这时候不符合异步FIFO采用格雷码的特性,但是可以通过设置set_max_delay约束,值为两个时钟间较块的一个时钟周期内。这样的话就可以保证在第二个时钟沿采样的时候中间的那个数据0001的bit0已经 稳定了。可以看下面的示意图:
4.多周期路径约束
(1)多周期路径约束命令
set_multicycle_path <path_multiplier> [-setup|-hold] [-start|-end] [-from ] [-to ] [-through <pins|cells|nets>]
| 参数名称 | 含义 |
|---|---|
| -setup | 表示建立时间所需要的时钟周期个数 |
| -hold | 表示分析保持时间时,相较于默认的捕获沿,实际捕获沿偏差的时钟周期个数 |
| -start | 表示以源端时钟作为时钟周期计数基准 |
| -end | 表示以目的时钟作为时钟周期的计数基准 |
(2)为什么会有多周期路径约束
在默认情况下,时序引擎进行时序分析是,建立时间要求默认是一个周期而保持时间要求默认是0各周期,但是会出现几种情况使得最终采样并不是以此为依据,以之前文章提到的多bit跨时钟域中的DMUX为例,数据在源时钟域保持多拍,接收方在对单bit有效信号进行同步后才会去采样数据(已经过了几个时钟周期),这时候数据已经稳定。因此需要通过设置多周期路径约束来改变建立时间要求。
数字IC/FPGA——亚稳态及跨时钟域-CSDN博客
以下图为例:
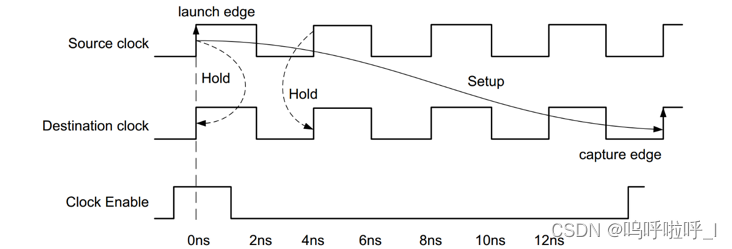
在0ns发送数据,接收方在16ns处(时钟使能时)接收数据。如果不进行多周期路径约束,那么当前发起沿在0ns,捕获沿在4ns,前一个捕获沿在0ns,即建立时间需求1个时钟周期,保持时间需求0个时钟周期,但是这并不符设计意图。因此需要修正,发起沿在0ns,使捕获沿在16ns处,前一个捕获沿为12ns,因此建立时间需求为4个时钟周期,对应的保持时间要求为3个时钟周期,但是保持时间要求为3个时间周期和起初数据保持多个时钟周期的要求不符,因此需要将保持时间依然变为0ns处。
要实现上述操作,需要对建立时间和保持时间通过set_multicycle_path命令实现:
set_multicycle_path -from [get clocks source_clk] -to [get clocks des_clock] -setup -end 4
setup的约束使捕获沿向后移动,同时holdcheck也跟着setup约束向后移动了,此时的保持时间要求在当前捕获沿的前一个捕获沿,也就是12ns处。因此再次使用set_multicycle_path将保持时间要求向前三个目的时钟周期。
set_multicycle_path -from [get clocks source_clk] -to [get clocks des_clock] -hold -end 3
(3)四种情况下的多周期路径约束
①同频同相
上述介绍的情况变为同频同相:
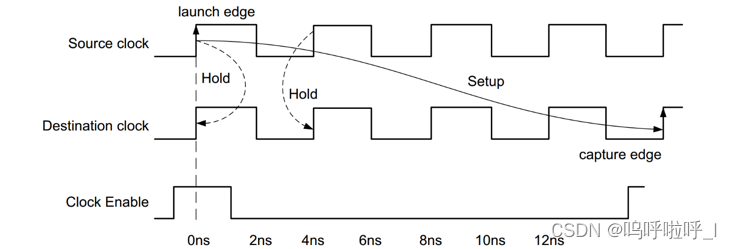
set_multicycle_path -from [get clocks source_clk] -to [get clocks des_clock] -setup -end 4
set_multicycle_path -from [get clocks source_clk] -to [get clocks des_clock] -hold -end 3
②同频异相
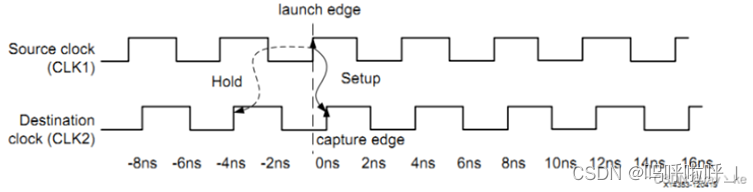
set_multicycle_path -from [get clocks source_clk] -to [get clocks des_clock] -setup -end 2
这里保持时间变为了0.3s,因此无需再进行移动。
③慢时钟到快时钟
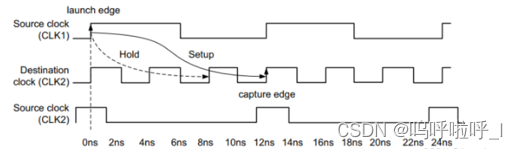
set_multicycle_path -from [get clocks source_clk] -to [get clocks des_clock] -setup -end 3
set_multicycle_path -from [get clocks source_clk] -to [get clocks des_clock] -hold -end 2
④快时钟到慢时钟
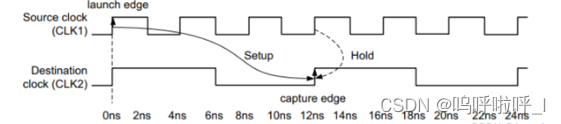
set_multicycle_path -from [get clocks source_clk] -to [get clocks des_clock] -setup -start 3
set_multicycle_path -from [get clocks source_clk] -to [get clocks des_clock] -hold -start 2
需要注意这里采用的是-start,相对于源时钟需要三个时钟周期的建立时间要求,而保持时间要求依然为0个时钟周期。
5.set_false_path
(1)命令
set_false_path [-setup] [-hold] [-from <node_list>] [-to <node_list>] \ [- through <node_list>]
-from选项的节点列表应该是一个有效的起始点列表。有效的起点是时钟对象、顺序元素的时钟引脚或输入(或输出)主端口。
可以提供多个元素。
-to选项的节点列表应该是有效端点的列表。有效的端点是时钟对象、输出(或输入)主端口或顺序元素输入数据引脚。可以提供多个元素。
-through选项的节点列表应该是有效引脚,端口或网络的列表
| 参数名称 | 含义 |
|---|---|
| -from | 节点列表应该是一个有效的起始点列表,有效的起点是时钟对象、时序元件的时钟引脚或输入(或输出)主端口。 |
| -to | 节点列表应该是有效端点的列表 |
| -through | 节点列表应该是有效引脚,端口或网络的列表 |
注意:在使用-through选项而不使用-from和-to时要小心,因为它从时序分析中删除了通过该引脚或端口列表的任何路径。当时序约束是为IP或子块设计的,但随后用于不同的上下文中或更大的项目时,要特别小心。
当单独使用-through时,可能会删除比预期更多的路径。
(2)设置伪路径的范围和原因
伪路径约束指的是某条路径的电路功能不会发生或者该路径不需要进行时序分析。
根据Xinlinx官方手册UG903提供的内容,可以不进行时序分析的路径有:
①两级同步器的异步跨时钟域;
②只需在上电时写一次的寄存器;
③异步复位;
④忽略异步分布式RAM的写时钟和读时钟之间的路径
设置伪路径可以减少综合、实现、时序分析的时间,极大的提高工具对设计的综合、实现、优化的结果。
(3)实例
①非功能路径
下图显示了一个非功能路径的示例,图中两个选择器由相同的信号驱动,因此Q到D的路径不存在,应该定义为伪路径,采样以下命令:
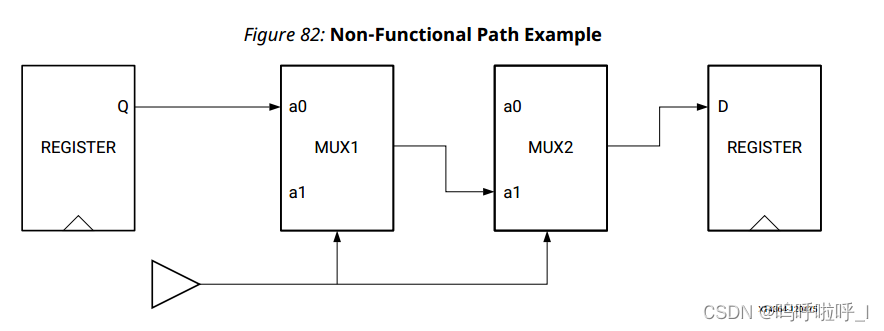
set_false_path -through [get_pins MUX1/a0] -through [get_pins MUX2/a1]
②异步复位
设置异步复位信号驱动的路径为伪路径:
set_false_path -from [get_ports rst_n]
③跨时钟域
设置两个异步时钟之间的路径为伪路径(从clka到clkb的时钟域):
set_false_path -from [get_clocks CLKA] -to [get_clocks CLKB]
若两个方向都需要设置:
set_false_path -from [get_clocks CLKA] -to [get_clocks CLKB]
set_false_path -from [get_clocks CLKB] -to [get_clocks CLKA]
尽管前面两个set_false_path示例执行了预期的操作,但当两个或更多的时钟域是异步的,应该禁用这些时钟域之间的路径无论哪个方向,AMD都建议使用set_clock_groups命令:
set_clock_groups -group CLKA -group CLKB
④异步分布式RAM
另一个常见的例子是异步双端口分布式RAM。写操作与时钟RAM是同步的,但在设计允许的情况下,读操作可以是异步的。在这种情况下,设置写时钟和读时钟之间的定时路径是安全的。
有两种实现方法:
-
定义一条从RAM前的写寄存器到RAM接收到读时钟后的寄存器的假路径:
set_false_path -from [get_cells <write_registers>] -to [get_cells <read_registers>] -
定义从RAM写使能引脚WE开始的假路径
set_false_path -from [get_cells -hier -filter {REF_NAME =~ RAM* && IS_SEQUENTIAL && NAME =~ <PATTERN_FOR_DISTRIBUTED_RAMS>}]
下图所示为WAVE (HDL)示例项目中驱动分布式RAM的方式:
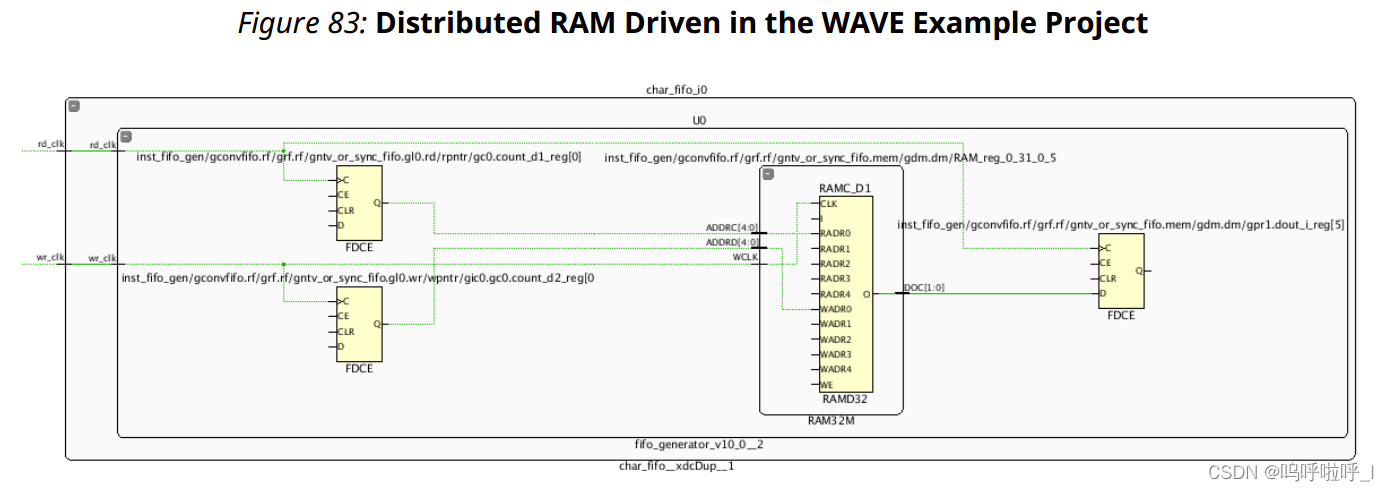
对应上述两种方式的约束命令为:
set_false_path -from [get_cells -hier -filter {NAME =~ gntv_or_sync_fifo.gl0.wrreg[*]}] -to [get_cells -hier -filter {NAME=~ gntv_or_sync_fifo.memgpr1.dout_i_reg[*]}]
set_false_path -from [get_cells -hier -filter {REF_NAME =~ RAM* && IS_SEQUENTIAL && NAME =~ char_fifo}]
6.set_clock_groups
(1)命令
set_clock_groups
| 参数名称 |
|---|
| -asynchronous |
| -logically_exclusive |
| -physically_exclusive |
(2)set_clock_groups和set_false_path的区别
默认情况下,Vivado IDE对设计中所有时钟之间的路径进行时序分析,除非通过使用时钟组或伪路径约束指定。set_clock_groups命令禁用规定的时钟组之间的时序分析,而同一组内的时钟之间的时序分析不禁用。与set_false_path约束不同,set_clock_groups在两个时钟之间的两个方向上都忽略时序分析。
忽略两个时钟之间的时序分析并不意味着它们之间的路径将在硬件中正常工作。为了防止亚稳态,必须验证这些路径是否具有适当的同步电路或异步数据传输协议。
(3)实例
①异步时钟组示例
- 主时钟clk0在输入端口上定义,并到达MMCM, MMCM生成时钟usrclk和itfclk
- 第二个主时钟clk1是在GTP实例的输出上定义的恢复时钟,并到达第二个MMCM,该MMCM生成时钟gtclkrx和gtclktx。
set_clock_groups -name async_clk0_clk1 -asynchronous -group {clk0 usrclk itfclk} -group {clk1 gtclkrx gtclktx}
如果不能提前预测生成的时钟的名称,可以使用get_clocks include_generated_clocks动态检索:
set_clock_groups -name async_clk0_clk1 -asynchronous -group [get_clocks -include_generated_clocks clk0] -group [get_clocks -include_generated_clocks clk1]
②Exclusive Clock Group
有些设计有多种操作模式,需要使用不同的时钟。时钟之间的选择通常使用时钟多路复用器(如BUFGMUX和BUFGCTRL)或LUT来完成。
使用set_clock_groups的选项来约束
-
-logically_exclusive
如果一个电路中有两个 时钟接入一个多路复用器,这两个clk就可以设置为logically_exclusive(logically_exclusive一定要满足这两个clk在传播路径上没有相互的path)
-
-physically_exclusive
如果两个 clock 定义在同一个端口上,那么这两个 clock 在物理层面就是不可能同时存在的,此时就需要声明成 physical exclusive
具体可以参考下面的文章:
set_clock_groups/Logically Exclusive/Physically Exclusive Clocks/create_clock
针对时序约束,推荐参考Xinlinx官方文档UG903,链接如下:
PDF • 查看器 • AMD 技术信息门户