目录
- Hazel 引擎学习笔记
- 学习方法思考
- 引擎结构
- 创建工程
- 程序入口点
- 日志系统
- Premake
- \MD
- 没有 cpp 文件的项目会出错
- include 到某个库就要包含这个库的路径,注意头文件展开
- 事件系统 获取和利用派生类信息
- 预编译头文件
- 抽象窗口类和 GLFW
- git submodule add
- premake 脚本
- 禁止一个类被实例化的方法
- 纯虚析构函数
- protected constructor
- 它目前实现创建派生窗口类对象的方式
- make_unique 相比于 unique_ptr<T>(new T)
- 窗口事件
- 层级 Layer
- Layer 的绘制顺序与接受事件的顺序相反
- LayerStack
- vector 的 emplace 和 insert 的区别
- 使用for循环时需要提前设置迭代器
- 添加 Glad 图形库
- 初始化 glad 的顺序
- 添加 ImGUI 库
- InGui 添加事件
- 强制 premake 将路径视为 Windows 路径
- 输入轮询 Input Polling
- 键位 Key Code
- GLM 数学库
- ImGui 拖拽和视窗 mGui Docking and Viewports
- 为 ImGui 添加 dllexport 相关的宏定义
- 在 Engine, ImGui, Sandbox 添加一些预编译头的 hack
- 在 Engine 项目的宏定义的头文件中为 ImGui 添加 dllexport dllimport 相关的宏定义
- 在 Engine 项目的宏定义的头文件中为 ImGui 添加 dllimport,在 ImGui 项目中添加 dllexport 的宏定义
- 使用 Module Definition File
- 将 Engine 项目改为静态库
- 为 submodule 添加文件
- lib 和 dll 之间的选择
- dll 导出的类中包含 stl 成员时出现的问题
- 修复其他一些 warning
- runtime library
- c++17
- 重复的编译内容
- CRT warning
- 渲染 Rendering 介绍
- Design Architecture
- 如何设计 Graphics API Abstraction
- 如何起步
- Rendering: Render Context
- 绘制三角形
- 着色器 OpenGL Shaders
- 渲染 API 抽象 Renderer API Abstraction
- Compile Time Or Runtime
- Vertex Buffer Layouts
- OpenGL 和 DirectX 中的 Buffer Layout
- 关于 initializer_list
- 顶点数组对象 Vertex Arrays Object
- make_shared 和抽象类连用,无法构造对象
- const 限定符被丢弃
- 渲染流和提交 Render Flow And Submission
- Renderer Architecture
- 摄像机 CAMERAS
- 顶点坐标计算时的归属分配问题
- Camera作为参数传给Renderer的BeginScene函数
- 正交相机 Orthographic Camera
- 时间戳 TIMESTEPS and DELTA TIME
- 三种 Timestamp
- Fixed Timestamp
- Variable Timestamp
- Semi-fixed Timestep
- spiral of death
- 物理确定性
- 物理模拟插值
- 变换 Transform
- 材质 Material
- 着色器抽象类 Shader Abstraction and Uniforms
- 引用,作用域和智能指针 Refs, Scopes and Smart Pointers
- 为什么 Shader 不设置为 unique_ptr 而是设置为 shared_ptr
- 材质素材 TEXTURES
- 混合 Blend
- 着色器资源文件 Shader Asset Files
- 着色器库 ShaderLibrary
- 创建 2D 渲染器 How to Build a 2D Renderer
- 渲染架构
- 2D Renderer需要支持的内容
- 关于BatchRenderer和Texture Atlas
- 关于Scripting
- 相机控制器 Camera Controllers
- Resizing
- 可维护性 Maintenance
- Preparing for 2D Rendering
- 2D Renderer Transforms and Textures
- Single Shader 2D Renderer
- Intro to Profiling
- Visual Profiling
- Instrumentation
- Improving our 2D Rendering API
- How I Made a Game in an Hour Using Hazel
- Hazel 2020
- 批渲染 BATCH RENDERING
- Batch Rendering Textures
- 使用 flat v_TexIndex 解决 z-fighting
- Drawing Rotated Quads
- Index Buffer 可以先绑定到 GL_ARRAY_BUFFER 设置缓冲,再绑定到 GL_ELEMENT_ARRAY_BUFFER
- Renderer Stats and Batch Improvements
- Testing Hazel's Performance
- Let's Make Something in Hazel
- 只能使用 int uniform 作为 array uniform 的 index
- C++类的成员变量初始化顺序
- How Sprite Sheets/Texture Atlases Work
- SubTextures - Creating a Sprite Sheet API
- Creating a Map of Tiles
- 如何表示Tiles组成的地图
- Next Steps + Dockspace
- Framebuffers
- Render Pass
- Making a New C++ Project in Hazel
- Scene Viewport
- ImGui 无边框
- 使用 `glTexImage2D` 创建纹理附件,方便更新
- Code Review + ImGui Layer Events
- 虚析构函数
- 在 Compile Time 决定 Input 的实现
- ImGui 的 IsWindowFocused
- Where to go next + Code Review
- ImGui::GetContentRegionAvail() 可能返回负值
- 单独 resize ImGui 窗口时出现的闪烁
- 不要把重要的最通用的宏定义放到头文件里
- VertexArray在跨平台的图形API里并不存在
- Entity Component System
- Intro to EnTT (ECS)
- 在引擎中包含整个 entt 路径的原因
- Entities and Components
- 空结构体
- The ENTITY Class
- AddComponent
- Camera Systems
- Scene Camera
- Native Script
- Native Script with virtual function
- Scene Hierarchy Panel
- Properties Panel
- Camera Component UI
- Drawing Component UI
- Transform Component UI
- Adding/Removing Entities and Components UI
- Making the Hazelnut Editor Look Good
- Saving and Loading Scenes
- Open/Save File Dialogs
- Transformation Gizmos
- Editor Camera
- Multiple Render Targets
- 为鼠标点选准备 FBO
- 清理 FBO 的颜色附件
- 鼠标点选 Mouse Picking
- Clicking to Select Entities
- SPIR-V and the New Shader System
- UniformBuffer
- SPIR-V and the New Shader System
- SPIR-V
- SPIR-V对各个平台的shader转换的流程图
- Vulkan SDK
- Uniform 的写法
- 在 Shader 中使用预编译头
- XXX 已在 XXX.obj 中重新定义
- 代码中调用 shaderc 编译 glsl 到 spirv
- spirv 编译到 glsl
- 从编译得到的 spirv 数据中获取 shader 信息
- 在 OpenGL 加载 spirv 二进制数据
- 其他问题
- 内容浏览器 Content Browser/Asset Panel
- Content Browser Panel - ImGui Drag Drop
- 显示图标
- 鼠标拖拽
- Texture for Entities
- Everything You Need in a 2D Game Engine
- PLAY BUTTON
- 顶点数组会被插值的 bug
- 绘制顺序问题导致的 bug
- 游戏模式
- 窗口的 dock space 消失
- 2D PHYSICS
- 显示文件 include 了哪个头文件
- Box2D
- Universally Unique Identifiers (UUID/GUID)
- Playing and Stopping Scenes (and Resetting)
- Rendering Circles in a Game Engine
- Rendering Lines in a Game Engine
- Circle Physics Colliders
- Visualizing Physics Colliders
- Return of the Game Engine Series
- Physics Simulation Mode
- Community Issues/PRs and Merging Branches
- 使用可变参数模板来完成重复性的工作
- Vulkan1.3
- GLFW 只调用 GLFW_PRESS RELEASE
- 将从属性面板添加组件的函数替换成函数模板
- 调整 include 的顺序
- 摄像机接受事件的需要播放模式的条件
- 类型的 size 为 0 时 asset
- 在程序主循环中少使用一些函数
- 鼠标选择穿过透明物体
- 定义某一个类的 hash 模板的特化
- 添加 C#
- 获取 Mono 文件
- 链接到 Mono
- 初始化 Mono
- 创建一个 C# 类库
- 测试程序集加载
- 在 C++ 端获取 C# 的类,实例化 C# 的类,调用 C# 类的方法
- Calling C++ from C#
- P Invoke
- Internal Call
- C#调用C++的自定义struct为参数的静态函数
- C#调用C++的重名重载函数
- Internal Call的特殊情况
- Calling C++ from C#
- C# 到 C++ 的调用的抽象
- 初始化时,获取并存储 C# 中的继承于某一已知命名空间名类名的类的所有派生类的信息
- ScriptComponent 初始化时根据已知的 命名空间名类名 创建 MonoObject
- ScriptComponent 实例化 C# 的 Entity 的派生类获得 MonoObject 时,创建的是派生类的 MoboObject,还要调用 C# 的 Entity 基类的构造函数
- ScriptComponent 想要有多个 C# 类的实例怎么办
- Scene OnUpdate 时获取所有包含 ScriptComponent 的 Entity,调用 ScriptEngine::OnUpdateEntity,ScriptEngine::OnUpdateEntity 又调用 ScriptInstance 里存储的从 C# 获得的 OnUpdate
- Component
- 将游戏 Assembly 和 核心 Assembly 分离
- C++ 获取 C# 类的属性
- 将 C# 字段的值复制到运行时 Storing/copying C# field values to runtime
- 序列化 ScriptComponent 的 fieldMap
- Added FindEntityByName and Entity.As to retrieve script class instance
- C# 程序集 Assembly 重新加载
- 文件监视 fileWatch
- 暂停和步进 Pausing and Stepping
- 添加 C# debugging
- 自定义 Buffer 和 ScopeBuffer
- 游戏工程的抽象类 Project
- 复制时的 bug
- Clone submodule 时的错误
- error MSB8013: This project doesn't contain the Configuration and Platform combination of Debug|Win32
- 字体
- AssetManager
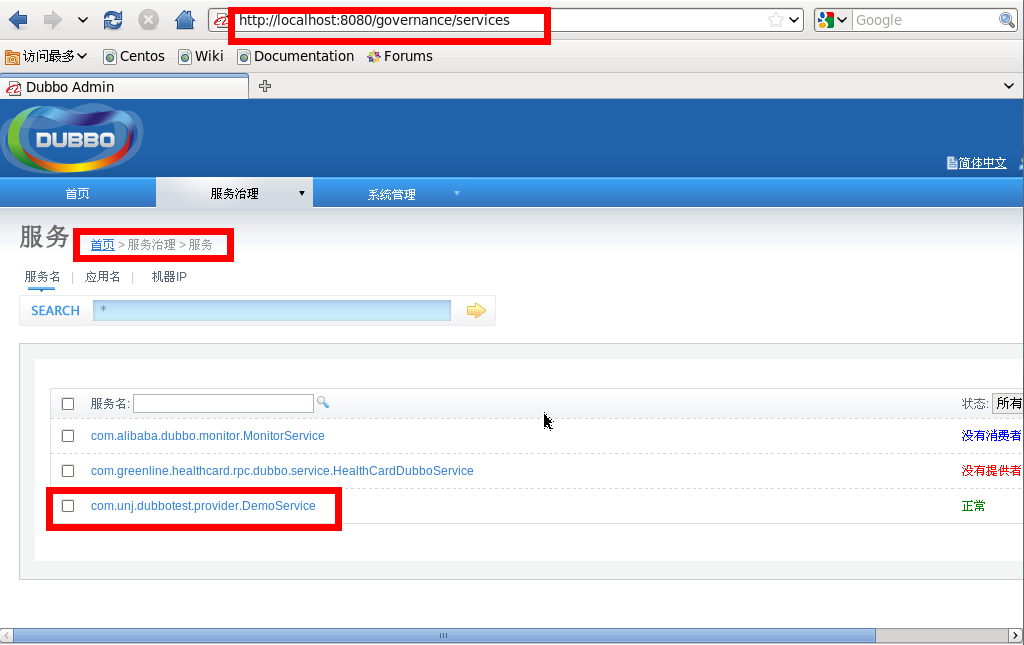
https://youtu.be/etdSXlVjXss
Hazel 引擎学习笔记
学习方法思考
我感觉自己照抄视频中的脚本还是有点慢了
因为你不知道他什么时候加了什么东西,或者自己照抄就很容易抄错
我觉得最好的方法就是自己快速过一遍他的视频,知道他大概的思路是怎么样的,然后自己再拉取那个 commit 的代码,用 diff 方便看他具体修改了什么代码,然后自己看看,自己总结一下,就差不多了
然后我还大部分参考了别的大佬的笔记:https://blog.csdn.net/alexhu2010q/category_10165311.html
引擎结构
-
Entry point
启动点
-
Application layer
-
Windows layer
Input
Event
-
Renderer
-
Render API abstract
-
Debugging support
-
Scripting language
-
Memory system
-
ECS
-
Physics
-
File IO, virtual file system(VFS)
-
Build system
build custom format of data offline
创建工程
创建 github 仓库
创建 Visual Studio 空项目
在 sln 文件的目录下 git clone 仓库
现在我们的解决方案中只有 Engine 一个项目
我们要做的是把引擎编译成一个库,静态或者动态的,然后应用程序链接这个库
在项目的属性页-配置管理器-活动解决方案平台-编辑 中删去 x86,不去支持 32 位平台
配置管理器-项目上下文-平台-编辑 中删去 Win32
在 Engine 项目的属性页 配置 改为所有配置
在 Engine 项目的属性页-配置属性-常规-常规属性-配置类型 改为 dll
现在这个项目会构建成 dll 而不是 exe
在 Engine 项目的属性页-配置属性-常规-常规属性-输出目录 改为 $(SolutionDir)bin\$(Configuration)-$(Platform)\$(ProjectName)\
中间目录改为 $(SolutionDir)bin-int\$(Configuration)-$(Platform)\$(ProjectName)\
这就表示 bin-int 是一个可以随时删除的文件夹
在解决方案资源管理器中,右键解决方案,新建空项目,命名为 Sandbox
对这个项目也是像之前一样,删掉 32 位,设置输出目录和中间目录,但是编译成 exe 就不用改了
在解决方案资源管理器中,对 Sandbox 项目右键,设置为启动项目
退出这个项目,用 vs code 打开 sln 文件,将 sandbox 项目这行移动到 engine 项目的上面
这是为了方便第一次看这个项目的人,他们习惯认为第一个项目是启动项目
在解决方案资源管理器中,对 Sandbox 项目右键,添加引用,勾选 Engine 项目,确认
这就链接到了 Engine 项目产生的 dll
我打开 Sandbox 项目的属性页 linker - command line 的时候没有看到 Hazel.lib,这是为什么?我确定我已经设置 Hazel 项目编译为 dll,设置了 Sandbox 引用 Hazel 项目。
不管了,继续往下看吧
生成 dll 的时候为什么会同时生成 lib 和 dll?
https://stackoverflow.com/questions/38602618/why-some-programs-require-both-lib-and-dll-to-work
这个回答说 lib 分为两种,一种是静态库,一种是导入库,导入库是在 dll 编译时生成的,只是包含 dll 所需要的符号
在两个项目下创建 src 文件夹
在 Engine 项目下面新建一个测试用的
Test.h
#pragma oncenamespace MeowEngine {__declspec(dllexport) void Print();}
Test.cpp
#include "Test.h"#include <stdio.h>namespace MeowEngine {void Print() {printf("Welcome to Meow Engine!");}
}
__declspec(dllexport) 的作用就是让编译器按照某种预定的方式(前面大致解释了这种方式的规则)来输出导出函数及变量的符号
然后在 Sandbox 里面创建
Application.cpp
namespace MeowEngine {__declspec(dllimport) void Print();}void main() {MeowEngine::Print();
}
这个时候构建 Sandbox 会运行报错,因为找不到 dll
把 Engine 构建生成的 dll 复制粘贴到 Sandbox 的 exe 目录中,就可以正常运行了
程序入口点
在 Engine 的 src 文件夹中新建一个 Engine 文件夹
创建 Application 类
#pragma oncenamespace MeowEngine {class __declspec(dllexport) Application{public:Application();virtual ~Application();void Run();};
}
#include "Application.h"namespace MeowEngine {Application::Application() {}Application::~Application() {}void Application::Run() {while (true) {}}
}
创建 Core.h
#pragma once#ifdef ME_PLATFORM_WINDOWS#ifdef ME_BUILD_DLL#define ME_API __declspec(dllexport)#else#define ME_API __declspec(dllimport)#endif // ME_BUILD_DLL
#else#error Meow Engine only support Windows!
#endif
ME_PLATFORM_WINDOWS 表示对 Windows 构建
通过 ME_BUILD_DLL 我们实现了使用一个 ME_API 就能处理 dll 的导入导出
之前定义的 Application 类中 declspec 也可以替换成 ME_API 了
打开 Engine 属性页-配置属性-C/C+±预处理器-预处理器定义,添加 ME_PLATFORM_WINDOWS 用分号分隔
对 Sandbox 同样如此
对 Engine 再添加一个预处理器 ME_BUILD_DLL 表示这是用来构建 dll 的项目
把 Sandbox 的 Application.cpp 改名为 SandboxApp.cpp 与 Engine 中的 Application.cpp 区分开
然后如果要在 SandboxApp.cpp 中引用 Engine 中的文件的话,就会需要比较复杂的引用
例如:
#include "../../MeowEngine/src/MeowEngine/Core.h"
如果 Sandbox 中的某一个文件需要去引用很多 Engine 中的头文件,就需要写很多这样的 include 代码,比较难看
所以我们可以用新建一个头文件,作为中介,包括掉 Engine 中的一些头文件,然后在 Sandbox 中只去包括那单独一个中介头文件
在 Engine 项目的 src 文件夹中创建一个头文件作为中介
MeowEngine.h
#pragma once#include "MeowEngine\Application.h"
在 Sandbox 的属性页-C/C+±常规-附加包含目录 中添加 $(SolutionDir)MeowEngine\src;
也就是添加了 Engine 中的一个路径
这样我们在 Sandbox 项目中,某一个文件要引用那个中介头文件的时候,就可以不用写一长串路径了
例如:
SandboxApp.cpp
#include "MeowEngine.h"
前面我们 Engine 项目中定义了 Application 类,现在我们在 Sandbox 中继承它
#include "MeowEngine.h"class Sandbox : public MeowEngine::Application {
public:Sandbox() {}~Sandbox() {}};void main() {Sandbox* sandbox = new Sandbox();sandbox->Run();delete sandbox;
}
我在想,为什么要这么搞,我觉得是因为 Application 是入口点,所以不管是提供工具的 Engine 还是 Sandbox 都需要通过这个联系
还是得看之后写了什么吧
之后它把 main 函数的位置改了
他在 Engine 项目的 src/Engine 下面创建了一个 EntryPoint.h 把 main 放到了这里
#pragma once#ifdef ME_PLATFORM_WINDOWSextern MeowEngine::Application* MeowEngine::CreateApplication();void main(int args, char** argv) {auto app = MeowEngine::CreateApplication();app->Run();delete app;
}#endif // ME_PLATFORM_WINDOWS
在 Application.h 中,添加声明 CreateApplication
#pragma once#include "Core.h"namespace MeowEngine {class ME_API Application{public:Application();virtual ~Application();void Run();};// To be define in CLIENTApplication* CreateApplication();
}
在 MeowEngine.h 中,添加包含头文件
#pragma once// For use by CheapMeow applications#include "MeowEngine\Application.h"// ---Entry Point-------------------------
#include "MeowEngine\EntryPoint.h"
// ---------------------------------------这样,SandboxApp.cpp 就包含了 EntryPoint.h
原来在 SandboxApp.cpp 中的 main 就不需要了,改成了对 CreateApplication 的实现
#include "MeowEngine.h"class Sandbox : public MeowEngine::Application {
public:Sandbox() {}~Sandbox() {}};MeowEngine::Application* MeowEngine::CreateApplication() {return new Sandbox();
}
这样,就是实现了,在 Engine 里面声明 Application,在 Engine 里面创建、调用 Application,在 Sandbox 里面具体实现
我看别人说,这样的好处是,客户端只负责 new,对象释放交给引擎处理
emmm,毕竟我经验少,一时半会也说不出这里怎么好了
日志系统
需要打印不同警告等级,还需要格式化打印不同对象,比如数,数组,对象
这里就是新建了一个 Log 类,Log 类创建了两个 spdlog 静态对象
一般的使用方法例如,获取静态对象->warn()
再创建一些宏,把这些变成缩写
Log.h
#include <memory>
#include "spdlog\spdlog.h"namespace MeowEngine {class Log{public:static void Init();static std::shared_ptr<spdlog::logger>& GetCoreLogger() { return s_CoreLogger; }static std::shared_ptr<spdlog::logger>& GetClientLogger() { return s_ClientLogger; }private:static std::shared_ptr<spdlog::logger> s_CoreLogger;static std::shared_ptr<spdlog::logger> s_ClientLogger;};}// Core log macros
#define ME_CORE_TRACE(...) ::MeowEngine::Log::GetCoreLogger()->trace(__VA_ARGS__)
#define ME_CORE_INFO(...) ::MeowEngine::Log::GetCoreLogger()->info(__VA_ARGS__)
#define ME_CORE_WARN(...) ::MeowEngine::Log::GetCoreLogger()->warn(__VA_ARGS__)
#define ME_CORE_ERROR(...) ::MeowEngine::Log::GetCoreLogger()->error(__VA_ARGS__)
#define ME_CORE_CRITICAL(...) ::MeowEngine::Log::GetCoreLogger()->critical(__VA_ARGS__)// Client log macros
#define ME_TRACE(...) ::MeowEngine::Log::GetClientLogger()->trace(__VA_ARGS__)
#define ME_INFO(...) ::MeowEngine::Log::GetClientLogger()->info(__VA_ARGS__)
#define ME_WARN(...) ::MeowEngine::Log::GetClientLogger()->warn(__VA_ARGS__)
#define ME_ERROR(...) ::MeowEngine::Log::GetClientLogger()->error(__VA_ARGS__)
#define ME_CRITICAL(...) ::MeowEngine::Log::GetClientLogger()->critical(__VA_ARGS__)
Log.cpp
#include "Log.h"#include <spdlog/sinks/stdout_color_sinks.h>namespace MeowEngine {std::shared_ptr<spdlog::logger> Log::s_CoreLogger;std::shared_ptr<spdlog::logger> Log::s_ClientLogger;void Log::Init() {spdlog::set_pattern("%^[%T] %n: %v%$");s_CoreLogger = spdlog::stdout_color_mt("MEOW ENGINE");s_CoreLogger->set_level(spdlog::level::trace);s_ClientLogger = spdlog::stdout_color_mt("APP");s_ClientLogger->set_level(spdlog::level::trace);}
}
#pragma once#ifdef ME_PLATFORM_WINDOWSextern MeowEngine::Application* MeowEngine::CreateApplication();void main(int args, char** argv) {MeowEngine::Log::Init();MeowEngine::Log::GetCoreLogger()->warn("Welcome!");auto app = MeowEngine::CreateApplication();app->Run();delete app;
}#endif // ME_PLATFORM_WINDOWS这里是,声明写在头文件,定义写在源文件
声明(declare)做的事情是,告诉编译器有这么个 符号(函数/变量) 存在,让编译器允许后面的代码使用这个符号。
定义(define) 做的事情是,为这个符号(函数/变量) 分配内存空间/获取其地址,让编译器知道去哪里找这个符号。
如果这里 cpp 不写 s_CoreLogger s_ClientLogger 的定义,那么编译不会报错,在 Visual Studio 点击变量名跳转也能跳转,但是链接的时候会报错,找不到符号
严重性 代码 说明 项目 文件 行 禁止显示状态
错误 LNK1120 1 个无法解析的外部命令 MeowEngine E:\MeowEngine\bin\Debug-x64\MeowEngine\MeowEngine.dll 1
严重性 代码 说明 项目 文件 行 禁止显示状态
错误 LNK2001 无法解析的外部符号 "private: static class std::shared_ptr<class spdlog::logger> MeowEngine::Log::s_CoreLogger" (?s_CoreLogger@Log@MeowEngine@@0V?$shared_ptr@Vlogger@spdlog@@@std@@A) MeowEngine E:\MeowEngine\MeowEngine\Log.obj 1
Premake
workspace 相当于一个解决方案
configurations 相当于解决方案的构建方式,就是 Debug,Release 那种,跟 VS 一样,只是自己定义的一个任意名字的 enum,用来区别自己选择的不同构建设定而已
platforms 的作用相当于另一种 configurations 只是方便之后区别不同情况
project 相当于定义了一个项目,也就是解决方案中的一个项目,比如 Engine 和 Sandbox
define 是定义一个 preprocessor 预编译头
就是之前 ME_PLATFORM_WINDOWS 之类
kind 表示构建类型
language 表示构建语言
targetdir 表示构建位置
objdir 设置构建项目时应放置对象和其他中间文件的目录。
files 表示源文件,包括 .h 和 .cpp
include 表示附加的头文件目录
filter 对 configurations platforms 进行筛选,在筛选之后的构建方式之下进行配置
还可以对 system 筛选,这个 system 可以在工作区中定义,不定义的话就自动识别
tokens 包括值令牌和命令令牌,值令牌是 premake 提供的一些内建变量,可以访问我们之前定义的比如 configurations platforms 之类的信息,这样我们就可以方便使用这些信息来输出
具体有哪些内建变量可以看 wiki
staticruntime On 的效果是 Sets to “MultiThreaded”,这个我不知道是什么意思
之后的
https://blog.csdn.net/alexhu2010q/article/details/106942099
讲的还挺清楚的
之后还有一点是,要在 Sandbox 中也包含 spdlog 的 include 路径
就很奇怪,为什么呢,因为 Sandbox 中包含了 MeowEngine.h 这个 MeowEngine,h 是我们之前用来连接到引擎的各个头文件的中介,其中包含了引擎中的一些头文件,其中包含了引擎的 Log 类的头文件,Log 类包含了 spdlog,那就相当于 Sandbox 中还是用到了 spdlog,所以还要配置
然后这里如果代码没有报错,但是链接始终不成功,除了静态类成员需要定义这个坑,还有一个可能性是,有些需要导出导入的 dll 中的类没有附加 import export
workspace "MeowEngine"architecture "x64"startproject "Sandbox"configurations{"Debug","Release","Dist"}outputdir = "%{cfg.buildcfg}-%{cfg.system}-%{cfg.architecture}"project "MeowEngine"location "MeowEngine"kind "SharedLib"language "C++"targetdir ("bin/" .. outputdir .. "/%{prj.name}")objdir ("bin-int/" .. outputdir .. "/%{prj.name}")files{"%{prj.name}/src/**.h","%{prj.name}/src/**.cpp"}includedirs{"%{prj.name}/vendor/spdlog/include"}filter "system:windows"cppdialect "C++17"staticruntime "On"systemversion "latest"defines{"ME_PLATFORM_WINDOWS","ME_BUILD_DLL"}postbuildcommands{("{COPY} %{cfg.buildtarget.relpath} ../bin/" .. outputdir .. "/Sandbox")}filter "configurations:Debug"defines "ME_DEBUG"symbols "On"filter "configurations:Release"defines "ME_RELEASE"symbols "On"filter "configurations:Dist"defines "ME_DIST"symbols "On"project "Sandbox"location "Sandbox"kind "ConsoleApp"language "C++"targetdir ("bin/" .. outputdir .. "/%{prj.name}")objdir ("bin-int/" .. outputdir .. "/%{prj.name}")files{"%{prj.name}/src/**.h","%{prj.name}/src/**.cpp"}includedirs{"MeowEngine/vendor/spdlog/include","MeowEngine/src"}links{"MeowEngine"}filter "system:windows"cppdialect "C++17"staticruntime "On"systemversion "latest"defines{"ME_PLATFORM_WINDOWS"}filter "configurations:Debug"defines "ME_DEBUG"symbols "On"filter "configurations:Release"defines "ME_RELEASE"symbols "On"filter "configurations:Dist"defines "ME_DIST"symbols "On"
可以创建一个 bat 自动完成构建
call .\vendor\bin\premake\premake5.exe vs2019
pause
\MD
https://blog.csdn.net/alexhu2010q/article/details/107688039
如果dll和exe分别拥有自己的Heap,可能导致同一块内存在堆A上创建,又在堆B上释放
As this is a DLL, the problem might lie in different heaps used for allocation and deallocation (try to build the library statically and check if that will work).The problem is, that DLLs and templates do not agree together very well. In general, depending on the linkage of the MSVC runtime, it might be problem if the memory is allocated in the executable and deallocated in the DLL and vice versa (because they might have different heaps). And that can happen with templates very easily, for example: you push_back() to the vector inside the removeWhiteSpaces() in the DLL, so the vector memory is allocated inside the DLL. Then you use the output vector in the executable and once it gets out of scope, it is deallocated, but inside the executable whose heap doesn’t know anything about the heap it has been allocated from. Bang, you’re dead.
为了解决这个问题,需要保证dll和exe享用同一块Heap。
那么需要设置 VS 中的 Runtime Library 选项
/MT Multi-threaded
/MTd Multi-threaded Debug
/MD Multi-threaded DLL
/MDd Multi-threaded Debug DLL
用带 DLL 的选项就可以了
没有 cpp 文件的项目会出错
如果一个 vs 项目没有 cpp 文件,只有 h 文件,那么它的属性页会缺失 C/C++ 这一项,premake 中设置的 includedirs 也不会出现在这个项目中,就会导致一些错误
我做这样一个项目一开始是为了测试某个头文件,没想到有这样的错误
https://stackoverflow.com/questions/2309091/can-not-find-c-c-in-project-properties
我猜这是因为没有 cpp 文件的话就没有真正编译一个模块出来,所以 vs 项目中才没有 C/C++ 这一项——因为这不算是 C/C++ 要编译的
include 到某个库就要包含这个库的路径,注意头文件展开
最终我遇到了类似这样的问题
https://stackoverflow.com/questions/17715725/visual-studio-unable-to-find-header-file-during-compile-despite-include-director
我的问题跟他的差不多,但是具体有所不同
我是在 A 项目中的附加包含目录中添加了某个库(假设称为 foo.h)的路径,然后我在 A 项目的 a.h 中写了
// a.h#include "foo.h" // for example
然后我在 B 项目中也添加了 a.h 的路径,然后 include 了 a.h
然后 a.h 中就出现了报错,说找不到 foo.h
这个时候我一直在想,我在 A 项目中确实定义了 foo.h 的路径了啊,怎么还会找不到呢,然后就一直找解决方法,没找到
之后我在 B 项目中把对 a.h 的 include 删掉,问题就消失了,这个时候我才反应过来是怎么回事
实际上我没有在 B 项目中定义 foo.h 的路径,但是我又在 B 项目中变相地 include “foo.h”,那么在 B 中去找 “foo.h” 就找不到了
所以解决方法就是,用到这个库的项目都要加上这个库的路径
事件系统 获取和利用派生类信息
之后的
https://blog.csdn.net/alexhu2010q/article/details/106942099
讲的还挺清楚的
首先 premake 中 Engine 的 include 路径中添加一个 src,方便引用
比如 Engine 这个文件夹放 Engine 的 vcxproj 然后底下有一个 src 文件,那么我们的 src 文件夹中的文件包含东西的时候不希望在路径中还要写到 src
project "MeowEngine"location "MeowEngine"kind "SharedLib"language "C++"targetdir ("bin/" .. outputdir .. "/%{prj.name}")objdir ("bin-int/" .. outputdir .. "/%{prj.name}")files{"%{prj.name}/src/**.h","%{prj.name}/src/**.cpp"}includedirs{"%{prj.name}/vendor/spdlog/include","%{prj.name}/src"}
这个事件系统就是多态的一个很好的例子,事件是多态的,但是我却需要有一个东西能够处理所有类型的事件,他就演示了怎么获得派生类的信息,怎么利用获得的派生类的信息,这些是一个简单的多态继承 virtual 函数所不会展示的
class EventDispatcher{template<typename T>using EventFn = std::function<bool(T&)>;public:// 传入事件的基类// 外部传入一个 EventFn 的同时,还需要指定事件的派生类类型// 传入的派生类类型是传到模板的 T 中的// 也就是我们实现多态的方式是,用基类指针存储那些会派生的数据// 然后要求外部调用的时候通过类模板传入类型 T// 拿到类型 T,我们就可以获得派生类的相关信息,Dispatcher 就是需要处理这个派生类的信息才能完成自己的工作// 例如验证自己存储的事件的派生类事件类型与传入的派生类事件类型是否相同(用 enum 来判断)// 自己存储的事件虽然是用基类指针来指向的,但是它用虚函数来实现获得派生类事件类型,所以即使是基类指针也能获取到派生类信息// 拿到类型 T,还可以用这个 T 来将自己存储的基类指针指向的事件转换到派生类// 这样我们就可以调用传入的回调函数 EventFnEventDispatcher(Event& event): m_Event(event){}template<typename T>bool Dispatch(EventFn<T> func){if (m_Event.GetEventType() == T::GetStaticType()){m_Event.m_Handled = func(*(T*)&m_Event);return true;}return false;}private:Event& m_Event;};
这里完成的是,Event 自己有一个虚函数,提供给子类继承,用来返回函数的类型
这里返回的类型实际上是一个 enum 变量
而每一个函数对这个虚函数的继承都需要根据自己的情况来重写一遍
例如,我新写了一个事件 A,那么我先到 enum 定义中添加 A,然后我再写继承函数会返回 A 这个 enum
那么我们用一个宏定义来实现继承虚函数返回自己的类型 enum 的这一步
dispatcher 是接受一个事件,存下来,然后应用阶段,别人传入一个函数,dispatcher 用这个传入的函数来处理自己保存好的事件
dispatcher 就根据泛型 T 来得到 enum,通过和已经保存的事件的 enum 来比对,enum 相同才能允许调用传入的函数
什么情况下只知道类型不知道实例,就能调用这个类的函数?静态函数,所以 GetType GetName 这种都是静态函数
这样我们也就看到了静态函数的价值,除了不需要对象的普通成员之外,我们还可以用它来传递某个类型的信息
预编译头文件
我也遇到了一个问题就是,在将是否使用预编译头从 否 改为 使用 的时候,第一次生成 Engine 项目的时候,会产生警告,说有些 cpp 是不是没有包括预编译头文件,哪怕是那些不需要使用到预编译头文件中的库的源文件
https://blog.csdn.net/alexhu2010q/article/details/107132670
但是我什么都不动,再重新生成 Engine 项目,就不会有这个警告了
真的是,只有在切换之后的第一次生成才会出现的问题,我猜与旧构建有关,所以我在不使用预编译头的时候生成了 Engine 项目之后,清理了项目,然后切换到使用预编译头,然后再生成,这次就不管怎么样都生成不了了,一直存在这个是否是少了 pch 的错误
所以确实是,所有源文件都要加 pch
抽象窗口类和 GLFW
git submodule add
git submodule add 出错时怎么清理这个命令的痕迹
https://stackoverflow.com/questions/11887203/you-are-on-a-branch-yet-to-be-born-when-adding-git-submodule
如果是连接断开,可能要设置代理,看自己的 clash 的端口号
然后这个命令可以设置 git 的全局代理,其中 7890 是我的 clash 的端口号
git config --global http.proxy http://127.0.0.1:7890
premake 脚本
我一开始用的 油管主的 GLFW,用它自带的 premake 脚本,结果得到了链接错误
严重性 代码 说明 项目 文件 行 禁止显示状态
错误 LNK2019 无法解析的外部符号 __imp_realloc,函数 defaultReallocate 中引用了该符号 MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(init.obj) 1
错误 LNK2019 无法解析的外部符号 __imp_strncpy,函数 glfwWindowHintString 中引用了该符号 MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(window.obj) 1
错误 LNK2001 无法解析的外部符号 __imp_strncpy MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(input.obj) 1
错误 LNK2001 无法解析的外部符号 __imp_strncpy MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(monitor.obj) 1
错误 LNK2001 无法解析的外部符号 __imp_strncpy MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(win32_joystick.obj) 1
错误 LNK2001 无法解析的外部符号 __imp__wassert MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(osmesa_context.obj) 1
错误 LNK2001 无法解析的外部符号 __imp__wassert MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(monitor.obj) 1
错误 LNK2001 无法解析的外部符号 __imp__wassert MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(vulkan.obj) 1
错误 LNK2001 无法解析的外部符号 __imp__wassert MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(wgl_context.obj) 1
错误 LNK2001 无法解析的外部符号 __imp__wassert MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(egl_context.obj) 1
错误 LNK2001 无法解析的外部符号 __imp__wassert MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(window.obj) 1
错误 LNK2001 无法解析的外部符号 __imp__wassert MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(context.obj) 1
错误 LNK2001 无法解析的外部符号 __imp__wassert MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(input.obj) 1
错误 LNK2001 无法解析的外部符号 __imp__wassert MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(win32_thread.obj) 1
错误 LNK2019 无法解析的外部符号 __imp___stdio_common_vsscanf,函数 _vsscanf_l 中引用了该符号 MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(context.obj) 1
错误 LNK2019 无法解析的外部符号 __imp_strspn,函数 glfwUpdateGamepadMappings 中引用了该符号 MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(input.obj) 1
错误 LNK2019 无法解析的外部符号 __imp_wcscpy,函数 createMonitor 中引用了该符号 MeowEngine E:\MeowEngine\MeowEngine\GLFW.lib(win32_monitor.obj) 1
错误 LNK1120 6 个无法解析的外部命令 MeowEngine E:\MeowEngine\bin\Debug-windows-x86_64\MeowEngine\MeowEngine.dll 1 在保证我代码没抄错之后,我去比对了源代码,发现它的 GLFW 的 premake 脚本不一样,它使用了 /MT 构建
但是如果我全抄它的脚本,确实,/MT 了,但是有新的链接错误
于是我就在我的 GLFW 自带的 premake 的脚本中稍微改了一下,改成了 /MT,然后就好了
project "GLFW"kind "StaticLib"language "C"targetdir ("bin/" .. outputdir .. "/%{prj.name}")objdir ("bin-int/" .. outputdir .. "/%{prj.name}")files{"include/GLFW/glfw3.h","include/GLFW/glfw3native.h","src/glfw_config.h","src/context.c","src/init.c","src/input.c","src/monitor.c","src/null_init.c","src/null_joystick.c","src/null_monitor.c","src/null_window.c","src/platform.c","src/vulkan.c","src/window.c",}filter "system:linux"pic "On"systemversion "latest"files{"src/x11_init.c","src/x11_monitor.c","src/x11_window.c","src/xkb_unicode.c","src/posix_module.c","src/posix_time.c","src/posix_thread.c","src/posix_module.c","src/glx_context.c","src/egl_context.c","src/osmesa_context.c","src/linux_joystick.c"}defines{"_GLFW_X11"}filter "system:macosx"pic "On"files{"src/cocoa_init.m","src/cocoa_monitor.m","src/cocoa_window.m","src/cocoa_joystick.m","src/cocoa_time.c","src/nsgl_context.m","src/posix_thread.c","src/posix_module.c","src/osmesa_context.c","src/egl_context.c"}defines{"_GLFW_COCOA"}filter "system:windows"systemversion "latest"buildoptions "/MT"files{"src/win32_init.c","src/win32_joystick.c","src/win32_module.c","src/win32_monitor.c","src/win32_time.c","src/win32_thread.c","src/win32_window.c","src/wgl_context.c","src/egl_context.c","src/osmesa_context.c"}defines { "_GLFW_WIN32","_CRT_SECURE_NO_WARNINGS"}filter "configurations:Debug"runtime "Debug"symbols "on"filter "configurations:Release"runtime "Release"optimize "speed"filter "configurations:Dist"runtime "Release"optimize "speed"symbols "off"如果还有问题,那就可能是代码抄错了
例如我就抄错了,导致 glfw 的初始化函数没运行,结果之后 glfw 报错没有 tls,我还在想是怎么回事hhhh
禁止一个类被实例化的方法
纯虚析构函数
https://blog.csdn.net/alexhu2010q/article/details/107132670
多态使用的时候,如果子类中有属性开辟到堆区,如果使用父类类型的指针来指向子类对象,那么使用这个父类类型的指针来释放对象时,只会调用父类的析构函数(进行了函数地址早绑定)
解决方法:将父类中的析构函数改为虚析构或者纯虚析构(进行了函数地址晚绑定)
虚析构和纯虚析构共性:
-
可以解决父类指针释放子类对象,
-
都需要有具体的含函数实现
虚析构和纯虚析构的区别:
- 如果是纯虚析构,该类属于抽象类,无法实例化对象(纯虚析构的作用)
一般纯虚函数和纯虚析构的区别:
-
一般函数的纯虚函数不需要实现,但是纯虚析构函数一定要在类外提供函数的实现。
因为某一个类一定要有能够被调用的析构函数……?
protected constructor
对于抽象基类,如果把其 constructor 设置为 protected,那么,该基类虽然不能被用户直接进行实例化,但声明为 protected 能让该基类的子类被实例化
class Base1
{
public:virtual ~Base1() {}
protected:Base1() {}
};class Base2
{
public:virtual ~Base2() {}Base2() {}
};int main() {Base1 *base1 = new Base1(); //编译错误,Base1的构造函数是protected,不可以访问Base2 *base2 = new Base2(); //编译成功
}所以声明 protected constructor for base class,就是保证基类的构造函数,只能在其派生类中调用,这种基类一般是 abstract 类,但又不是接口类
它目前实现创建派生窗口类对象的方式
它目前实现创建派生窗口类对象的方式还是比较神奇的
因为 Window 现在包含纯虚函数,是一个抽象类,所以不能直接 new 同理也不能直接 make_unique
所以需要一个函数来创建一个 Window 类的派生类的对象
然后他又希望跨平台嘛,所以才把窗口类做成多态的
但是他现在返回 Window 类的派生类的对象的方法是在 WIndow 类里面声明一个 static 函数
static Window* Create(const WindowProps& props = WindowProps());
然后在类外定义死了,这个类就是返回某个特定平台的 Window 派生类
Window* Window::Create(const WindowProps& props){return new WindowsWindow(props);}
这样的话,就相当于这个 Create 只能派生一次了
make_unique 相比于 unique_ptr(new T)
虽然原来的
在 C++ 11 的时候,作为函数参数的各个函数调用之间的调用顺序是不确定的
foo(unique_ptr<T>(new T), otherFunction()); // first case
foo(make_unique<T>(), otherFunction()); // second case
对于第一种写法,各个函数调用的顺序可能是
// case 1
new T
unique_ptr<T>(...)
otherFunction()// case 2
new T
otherFunction()
unique_ptr<T>(...)// case 3
otherFunction()
new T
unique_ptr<T>(...)
之中的一种
乍一看看不出什么,但是当这个 otherFunction() 是一个可能会抛出异常的函数时。对于 case 2,当 otherFunction() 抛出异常时,foo(...) 函数会提前终止,那么这里 new T 的地址无法返回,后面的程序也就无法拿到这个地址来释放这个内存,那么这样就会有一块内存无法释放
https://stackoverflow.com/questions/19472550/exception-safety-and-make-unique/19472607#19472607
C++17 解决了这个顺序的问题,现在,每一个作为参数的函数调用都一定会完整的执行完,才轮到下一个作为参数的函数调用
此外还有解决了一些其他情况下的调用问题,例如 << 情况下
https://www.cppstories.com/2021/evaluation-order-cpp17/#does-it-mean-all-errors-are-fixed
但是这并不是说 foo(unique_ptr<T>(new T), otherFunction()); 这种形式一定不会产生内存泄漏,对于这个情况,C++17 只是使得,不会因为函数调用顺序不确定,某函数抛出异常使得其他地方的 new 没有返回地址,但这不是说这个形式本身没有其他内存泄露的可能性
例如:
foo(unique_ptr<T>(new T), new int {10});
这时,如果 foo 函数内部,或者 new T 会抛出异常,导致 foo 函数提前终止,原本应该在 foo 中释放的 new int 现在释放不了了,那么还是会导致内存泄漏
但是这种问题的根本是在于,直接就把一个 new 出来的匿名对象传到了函数中
而 cpp 的一个习惯是,尽可能少地在程序级别上进行new和delete调用——最好是没有。任何需要动态内存的东西都应该隐藏在一个 RAII 对象中,当它超出范围时释放内存。RAII 在构造函数中分配内存并在析构函数中释放内存,这样当变量离开当前范围时,内存就可以被释放。
(注:RAII 资源获取即初始化,也就是说在构造函数中申请分配资源,在析构函数中释放资源)
窗口事件
他这个触发事件的流程分为若干个步骤
-
每一个引擎窗口有自定义的窗口数据结构体
每一个窗口派生类的对象有一个 glfw 窗口对象
GLFWwindow成员m_Window与自定义的窗口数据结构体WindowData成员m_Data这使得整个应用可以有多个窗口,每一个窗口有自己的状态
-
窗口绑定事件
m_Data具有一个std::function<void(Event&)>成员窗口派生类的对象在初始化时可以创建一个自定义的事件处理函数
OnEvent,将这个自定义的事件处理函数用std::bind处理,得到我们规定好的事件回调函数的格式std::function<void(Event&)>,绑定到m_Data中也就是在初始化的时候给
m_Data中的事件回调函数赋值而事件回调函数具体的内容是,接受一个事件,根据这个事件初始化构造一个 EventDispatcher,然后对 EventDispatcher 调用各种事件处理函数
我感觉这里 EventDispatcher 起到的就是一个 if 的作用,因为其实 EventDispatcher 内部就是通过比对事件类型来判断是否执行传入的函数的
void Application::OnEvent(Event& e) // 这里用 Event 的基类来接受各种事件的派生类的对象 {EventDispatcher dispatcher(e);// 以下列出各种事件的处理函数// 如果 e 是 WindowCloseEvent,那么这里传入的函数会被调用dispatcher.Dispatch<WindowCloseEvent>(BIND_EVENT_FN(OnWindowClose)); // 再列出其他情况的,例: // 如果 e 是 WindowXXXEvent,那么这里传入的函数会被调用// dispatcher.Dispatch<WindowXXXEvent>(BIND_EVENT_FN(OnWindowXXX));HZ_CORE_TRACE("{0}", e); // 对任意类型的事件打印事件信息 } -
GLFW 事件传递的起点
在每一个窗口派生类的对象的初始化函数中,使用
glfwSetWindowUserPointer将本对象包含的 glfw 窗口对象GLFWwindow成员m_glfw_Window(虽然源代码不是叫这个名字,源代码写的也是 m_Window,在这里写出来的话我感觉会混淆) 与m_Data绑定起来然后就是事件传递的起点,glfw 提供了各种 glfw 事件的回调函数。在每一个窗口派生类的对象的初始化函数中,都将 glfw 事件的回调函数绑定为一个匿名函数。在游戏运行时,glfw 事件发生时,调用这个绑定的匿名函数,匿名函数的内容是:通过
glfwGetWindowUserPointer获取m_Data,然后创建引擎事件,将这个引擎事件传入m_Data,调用m_Data的事件回调函数这样,就完成了通过
glfwSetWindowUserPointer和glfwGetWindowUserPointer,将 glfw 窗口与自定义的窗口数据结构体一一绑定。而这样也就支持了多个 glfw 窗口能够有自己的事件绑定函数glfwSetWindowUserPointer(m_Window, &m_Data);// Set GLFW callbacks glfwSetWindowSizeCallback(m_Window, [](GLFWwindow* window, int width, int height) {WindowData& data = *(WindowData*)glfwGetWindowUserPointer(window);// custom logicWindowResizeEvent event(width, height);data.EventCallback(event); });
层级 Layer
设计完Window和Event之后,需要创建Layer类。Layer这个概念比较抽象,具体在游戏里,比如游戏画面可能是离摄像机最远的Layer,然后依次可能会有UI Layer和Debug Layer。
游戏里的Layer应该具备最基本的两个功能:可以在该Layer上渲染一些东西和接受外部的Event,所以Layer类需要有以下内容:
OnUpdate:用于处理渲染的loop
OnEvent:用于处理事件
Init函数:负责Layer的初始化
Exit函数: 负责Layer的结束操作
Layer 的绘制顺序与接受事件的顺序相反
在游戏里经常会有多个Layer,当多个Layer存在时,往往需要对上面一层的Layer(离摄像机最近的)进行处理,比如我们在点击UI时并不想让角色随之进行动作,所以这里设计了一个LayerStack,用于按照到摄像机距离从远到近的存放Layer,值得注意的是,处理渲染时,应该先画最远的Layer,再画最近的Layer,而处理事件时正好相反,因为最上面一层的Layer才应该是接受event的对象,二者的顺序正好是相反的。
LayerStack
实际实现 Layer 的功能,是在 Application 中设置一个 LayerStack
它是在 Application 的 OnEvent 中调用各个层级的 OnEvent,在 Application 的 OnUpdate 中调用各个层级的 OnUpdate。而 Application 的 OnEvent 是绑定到 Application 的 m_Winodw 中的 m_Data
这样其实就说明,这个层级是对于某一个窗口而言的,是一个窗口的内部有各种层级
这样也让我有点在意,他通过 glfw 将 glfw 窗口和自定义的窗口数据结构体一一对应地绑定,就是为了实现多窗口,现在它在一个 Application 里把 Application 窗口的各个层级绑定到 Application 的窗口,那就意味着 Application 只能有一个窗口了?毕竟因为如果有多个窗口的话……好像也不是不行
但是我总觉得这个层级的事情,应该是写在窗口里面的,而不应该写在 Application 里……
vector 的 emplace 和 insert 的区别
insert函数和emplace函数的区别在于, emplace() 在插入元素时,是在容器的指定位置直接构造元素,而insert函数是先单独生成,再将其复制(或移动)到容器中。因此,在实际使用中,推荐大家优先使用 emplace()。
使用for循环时需要提前设置迭代器
对于自定义类型的 vector,使用for循环时需要提前设置迭代器
LayerStack::~LayerStack(){for (Layer* layer : m_Layers)delete layer;}
所以在头文件时还需要声明头尾迭代器
std::vector<Layer*>::iterator begin() { return m_Layers.begin(); }std::vector<Layer*>::iterator end() { return m_Layers.end(); }private:std::vector<Layer*> m_Layers;unsigned int m_LayerInsertIndex = 0;
添加 Glad 图形库
可以使用glew,也可以使用glad库,二者的在效率上好像没啥区别,不过glad的库要更新一些,所以这里用glad库,具体步骤有:
-
上网站https://glad.dav1d.de/上下载对应版本的header和src文件,放在vendor文件夹下
-
网站上下载的glad库没有premake5文件,所以按照glfw库的方式为其写一个,与glfw库相同,这里的glad库也是作为lib文件使用
-
把glad库的premake5文件相关内容整合到整个工程的premake5文件里
初始化 glad 的顺序
glfwMakeContextCurrent 之后再 gladLoadGLLoader
添加 ImGUI 库
由于我们用的是 glfw 库加上 OpenGL3 的版本,所以要参考的两个 cpp 文件为:imgui_impl_opengl3.cpp 和 imgui_impl_glfw.cpp
在Platform文件夹下,创建OpenGL文件夹:
把 imgui_impl_opengl3 的头文件和源文件放进去,更名为 ImGuiOpenGLRenderer,用来存放 ImGui调用 OpenGL 的代码。
而原本用到的 imgui_impl_glfw 相关内容,就直接 Copy 和 Paste 到 ImGuiLayer 里。
可能需要修改一些头文件的包含
还有就是,mgui\examples\example_glfw_opengl3\main.cpp 是用来创建一个示例 glfw 窗口的,我们需要参考一些它对 imgui 的初始化和 Update 方法
初始化包含 ImGui::CreateContext(); ImGui_ImplOpenGL3_Init() 这两个函数
而渲染循环要看 main.cpp 中的渲染循环,主要就是这些
...// Start the Dear ImGui frame
ImGui_ImplOpenGL3_NewFrame();
ImGui_ImplGlfw_NewFrame();
ImGui::NewFrame();...// Rendering
ImGui::Render();...ImGui_ImplOpenGL3_RenderDrawData(ImGui::GetDrawData());
然后就把这些写到自己的 ImguiLayer 的 Update 中
计算 deltaTime 可以参考 ImGui_ImplGlfw_NewFrame(); 中写的,它在 imgui\examples\imgui_impl_glfw.cpp 中定义
InGui 添加事件
参考已有的事件的写法,我们需要在 ImGuiLayer 定义各个自定义的事件处理函数,然后在 OnEvent 中用传入的事件来创建一个 EventDispatcher 实例,然后将自己所有的事件处理函数都送到 EventDispatcher 中,EventDispatcher 中,只有事件类型和传入的事件处理函数的类型相同时才允许调用传入的函数……总之就是之前那一套
只是怎么自定义各个派生类事件的处理函数,就需要知道一些怎么传递信息到 ImGui,这还是需要看视频的
强制 premake 将路径视为 Windows 路径
之前 premake 中我们设置将构建结果复制到指定目录下
但是当工程中没有这个指定目录的时候,premake 将不会把构建出来的 dll 复制过去,导致第一次构建失败
而第一次构建失败的过程中,在构建 Sandbox 的时候创建了这个目录
所以第二次构建 premake 可以找到这个目录,可以构建成功
根据:https://github.com/TheCherno/Hazel/pull/22
第一次构建,premake 找不到这个目录(或者说没有创建这个目录)的原因是把第二个参数最后一个斜杠删掉了,这就导致这个路径表示一个文件而不是表示一个路径
emmm,我有点没懂,主要是,这样解释的话,就无法解释为什么第二次构建会成功
但是总之他给出的解决方法是,将第二个参数整体用双引号包起来,表示这是一个 windows 路径
例如原先是 %{cfg.buildtarget.relpath}/XXX,现在是 %{cfg.buildtarget.relpath}/“XXX”
postbuildcommands
{--("{COPY} %{cfg.buildtarget.relpath} ../bin/" .. outputdir .. "/Sandbox/")("{COPY} %{cfg.buildtarget.relpath} \"../bin/" .. outputdir .. "/Sandbox/\"")
}
输入轮询 Input Polling
需要知道当前的输入状态,例如某一键是否被按下
如果对所有可能的输入状态设置 bool,或者比特图……?这样就太繁琐了
于是 glfw 提供了根据键的序号查询键的状态的函数
我们要做的就是封装 glfw 的查询函数,封到自己的一个 Input 类中
这个类应该在任何地方都可以访问
又因为不同平台的输入设备不一样,所以这个 Input 类需要是跨平台的,也就是多态的
既要多态,又要全局访问,所以这个博客作者一开始希望的是 virtual 和 static 连用
https://blog.csdn.net/alexhu2010q/article/details/107688039
但是这样是没有意义的,因为 virtual 的底层是依赖于对象里面存储的虚函数指针,现在用 static 的话,就是直接通过类名来调用函数,没有对象了,就没有虚函数指针了,那就不能知道这个 virtual 函数实际上到底是指向哪个 static 函数了,是基类的 static virtual 函数还是派生类的 static override 函数?不知道了
所以正确的实现方法是在基类中创建一个静态单例。之前也做过,在 Application 那里
单例对象设置成 private,static get 函数设置成 public,这样可以防止外部更改这个单例对象
单例还要把类的拷贝构造函数和赋值运算符重载函数设置成 delete
键位 Key Code
我们是从 glfw 查询输入的,但是 glfw 中的键位的 enum 值和各个平台自己设置的 key code 的 enum 值可能是不一样的
例如 glfw 中 #define HZ_KEY_TAB 258 但是 Windows 中 TAB 是 9
https://learn.microsoft.com/en-us/windows/win32/inputdev/virtual-key-codes
我们在引擎中肯定是要定义一套 Key Code 的,这样纠结的地方就来了,如果要跨平台,例如我们现在不用 glfw 来轮询输入,而是用 Win32 的 API 来轮询输入,而如果这个时候我们还是用的 glfw 风格的 Key Code 传递给 Win32 的 API,那么就会发生错误
最有效的解决方法就是,我们知道我们要把引擎编译到什么平台上,所以我们用预处理指令 #ifdef,根据平台相关的预编译头,来决定编译哪种 Key Code
这种在运行时的效率是最高的,唯一一点不好是,存储的游戏数据(包含了键位映射数据)可能无法跨平台共享(或者这就需要你还开发一个跨平台共享数据的工具?)(或者这也可以通过更详细的序列化措施来实现,例如原来无法跨平台共享的是 enum 值,那么现在我键位映射数据不存 enum 值,而是存 string 值,这样就可以跨平台了,但是这总归是你需要 hard code 各个平台之间的转换的)(当然也不是说这样子不好……?)
然后第二种方案就是,在引擎中需要考虑跨平台 KeyCode 的时候,从引擎输入到特定平台,做一个转换函数,例如 EngineKeyToGlfwKey(key),从特定平台输入引擎,做一个转换函数,例如 GlfwKeyToEngineKey(key)
第一种方案就太复杂了,总归来说,而且性能瓶颈也不在这里,所以可以不用这样优化
然后如果我们将引擎的 Key Code 从某个平台 copy 过来,那么在这个平台相关的代码中,我们还可以方便一点,就不用这两个转换了
这里的跨平台更多的说的是,嗯,跨平台的库的 API
例如其实我们引擎也是运行在 Windows,但是其实我们没有用到 Windows 的库,所以我们不会在 Windows 的应用上做键位交互,我们一直是在和 glfw 窗口交互,所以我们一直用 glfw 的 Key Code 作为引擎的 Key Code,所以我们不用转换函数,更不用转换到 Window 的 Key Code
GLM 数学库
一个好的数学库,除了跨平台,还可以通过 simd 指令来提高效率
当然评论区也说 simd 不一定更好,例如他需要内存对齐,如果你忘了内存对齐,他可能更慢,之类的
如果要自己写 simd 指令,就需要写汇编代码,或者是 intrinsic 代码,这些都是与编译器相关的
所以与其费心思学这些,不如直接用现有的数学库,例如 GLM
ImGui 拖拽和视窗 mGui Docking and Viewports
游戏引擎,比如Unity、UE4里的窗口都是可以拖拽(Docking)的,这是编辑器最基本的功能,为了不采用WPF、QT这些技术来完成拖拽功能,可以直接用ImGui来完成,而ImGui在其Dock分支正在开发这一功能,还没合并到master上,这意味着这个相关功能可能会随时更新
之前是链接到 ImGui,然后直接把 ImGui 的示例代码 copy 一份,然后放在自己的工程中
那是一个暂时性的操作,现在我们对 ImGui 是 git submodule 的,所以需要时刻与 ImGui 的更新保持同步,所以我们应该以某种方式 include ImGui 的代码
而这里,我们知道我们需要什么代码,所以我们直接在工程中新建一个源文件,然后包含我们需要的源文件
这些 ImGui 中的源文件就会被编译到工程中
其中有一个预编译头,表示我们的 OpenGL 用 Glad 来加载
#include "hzpch.h"#define IMGUI_IMPL_OPENGL_LOADER_GLAD
#include "examples/imgui_impl_opengl3.cpp"
#include "examples/imgui_impl_glfw.cpp"
然后我们就可以删掉我们之前写的暂时性的代码,例如在 ImGuiLayer::OnAttach() 中的一些初始化的代码就可以去掉了,因为这些在我们包含的 ImGui 代码中都有,我们之前就是从这些抄过来的
还有一个变动是,他把原先的 OnUpdate() 拆成了三个,Begin(), OnImGuiRender(), End()
Begin() 和 End() 就是原来的 OnUpdate() 中的头尾,而 OnImGuiRender() 会调用一些 ImGui 的 API
为 ImGui 添加 dllexport 相关的宏定义
参考:https://blog.csdn.net/alexhu2010q/article/details/107688039
拉取了 7c02b7863f1d70af88b7c447b223c9da4dc9e04a 这个 commit 的时候,构建会报错
原因是我们在 E:\Hazel-master\Hazel\Sandbox\src\SandboxApp.cpp 中调用了 ImGui 的 API
virtual void OnImGuiRender() override{ImGui::Begin("Test");ImGui::Text("Hello World");ImGui::End();}
但是 ImGui 是链接到 Engine 项目的,而 Engine 项目是编译成 dll 的,所以 ImGui 是 Engine 项目编出的 dll 的一部分,也就是说 ImGui 的类被 Engine 项目外部调用的时候也需要 dllexport dllimport 等操作
ImGui 中对他自己的类也有进行 IMGUI_API 的定义,但是默认情况下这个 IMGUI_API 是没有值的,所以我们可以利用它
在 Engine, ImGui, Sandbox 添加一些预编译头的 hack
直接在 Engine 和 ImGui 的项目属性中添加预编译头 IMGUI_API = _declspec (dllexport),在 Sandbox 的项目属性中添加预编译头 IMGUI_API = _declspec (dllimport)
这样可以 work,证明我们之前的想法是对的,但是我们需要一个非手动 hack 的解决方法
在 Engine 项目的宏定义的头文件中为 ImGui 添加 dllexport dllimport 相关的宏定义
例如在 Engine 项目的 Core.h 中添加这些定义
#ifdef HZ_PLATFORM_WINDOWS#ifdef HZ_BUILD_DLL#define HAZEL_API _declspec (dllexport)#define IMGUI_API _declspec (dllexport) // 添加对IMGUI_API的定义,导出api#else #define HAZEL_API _declspec (dllimport)#define IMGUI_API _declspec (dllimport) // 添加对IMGUI_API的定义,导入api#endif // HZ_BUILD_DLL
#endif但是这是头文件,所以要对 ImGui 起作用的话,就需要在 ImGui 中,对包含 IMGUI_API 的文件的开头加上包含 Core.h
这样我们就修改了 submodule 的文件,不可持续
在 Engine 项目的宏定义的头文件中为 ImGui 添加 dllimport,在 ImGui 项目中添加 dllexport 的宏定义
在 Engine 项目的 Core.h 中添加这些定义
#ifdef HZ_PLATFORM_WINDOWS#ifdef HZ_BUILD_DLL#define HAZEL_API _declspec (dllexport)//#define IMGUI_API _declspec (dllexport) // 添加导出这一行不要了#else #define HAZEL_API _declspec (dllimport)#define IMGUI_API _declspec (dllimport) // 添加导入#endif // HZ_BUILD_DLL
#endif而在 ImGui 的 premake5.lua 中设置
defines {"IMGUI_API=__declspec(dllexport)"}这样就方便实现了目标
使用 Module Definition File
除了上面说的去定义宏的方法,还可以使用第三种方法:Module Definition File,这种方法比较麻烦,但是可以不改变submodule的内容,其文件格式后缀为.def,可以在该文件里,列出所有需要exportdll的函数的签名,如下图所示:

Cherno给出的文件代码如下所示,这里把ShowDemoWindow、End等四个函数进行了dllexport的操作,不过这玩意儿很难写:

将 Engine 项目改为静态库
当然还有一种方法是把 Engine 项目改为静态库,这样就不会有那个问题了
为 submodule 添加文件
我们不能直接再 submodule 里面添加文件
但是我们又确实希望多加一些,例如 premake5.lua
这个时候我们可以 fork 我们需要的 submodule,然后我们对自己的 fork 时是有权限的,我们就可以在自己的 fork 中添加文件,然后再将自己的 fork 作为 submodule
这样,我们可以在 fork 中更新原仓库,也可以添加自己的文件了
lib 和 dll 之间的选择
引擎作为dll的优点:
-
hotswapping code
-
Easy to Link
引擎作为dll的缺点:
-
没有static linking快,因为Linker可以对static link的东西做优化,比如inline操作
-
lib只会产生一个exe,比dll方便
-
不用担心dll的版本与使用引擎的代码不匹配的问题
-
使用dll,有一些因为使用template或者其他内容的警告很难处理,比如说下面这个警告:
// 因为使用了智能指针,而没有把unique_ptr作为dll接口导出(dll boundary issues)
warning C4251: 'Hazel::Application::m_Window': class 'std::unique_ptr<Hazel::Window,std::default_delete<_Ty>>' needs to have dll-interface to be used by clients of class 'Hazel::Application
也可以维护两个版本,一个dll版本一个lib版本,但是工作量太大,就算了。
其实,一个Game Engine没有太大必要去做成hot swappable的,Game Engine做出来的游戏很有必要支持热更,但是游戏引擎本身就没必要了,比如说Doom这个游戏,他们就是把游戏的内容做成dll,然后用Engine去启动这个dll作为游戏,这样用户可以直接热更dll更新游戏,但是引擎本身是不会更新的,所以说具体使用Engine的时候,Engine改动的频率不会很高,所以最终还是决定把Hazel从dynamic library改为static library,热更可以交给编写游戏程序的脚本语言来做,而不一定非得用C++支持热更
dll 导出的类中包含 stl 成员时出现的问题
https://stackoverflow.com/questions/4145605/stdvector-needs-to-have-dll-interface-to-be-used-by-clients-of-class-xt-war/6869033
https://stackoverflow.com/questions/32098001/stdunique-ptr-pimpl-in-dll-generates-c4251-with-visual-studio
https://jeffpar.github.io/kbarchive/kb/168/Q168958/
解决方法:
-
如果 dll 没有必要把某个包含 stl 成员的类暴露出来,那就不暴露出来(不用 dllexport dllimport)
-
如果确实这个包含 stl 成员的类的这个 stl 成员不会被客户端(相对于编译成 dll 的项目而言的,链接 dll 编译 exe 的那个项目)所访问,那么就可以禁用这个警告
-
如果确实客户端要用到这个包含 stl 成员的类,那么可以考虑做一层包装之后再对这个包装类 dllexport dllimport、
-
如果包含 stl 成员的类中,客户端只是用到某个成员,那么可以不对整个类 dllexport dllimport 而是单独 dllexport dllimport 这个类中的某个成员
-
或者也可以使用 PImpl 技术,但是如果 PImpl 是用 unique_ptr 来隐藏细节的话,那么 dllexport 这个包含 unique_ptr 的类仍然会有问题
如果Application用不到这个数据,那么没有必要把它暴露出来,如果心里有数,确实用不到的话,可以禁用掉警告
修复其他一些 warning
https://blog.csdn.net/alexhu2010q/article/details/111030313
改成了静态库之后会修复一部分
runtime library
改成静态库之后,runtime library 还需要设置成 /MT
c++17
还有 -std=c11 这种错误
https://stackoverflow.com/questions/29473786/command-line-warning-d9002-ignoring-unknown-option-std-c11
在 premake 中指定 C++17 就好了
cppdialect "C++17"
重复的编译内容
warning LNK4221: This object file does not define any previously undefined public symbols, so it will not be used by any link operation that consumes this library
这个警告发生在,当一个.obj文件要被Linker链接到一起的时候,如果这个.obj里的东西,其他的.obj都有,那么这个.obj就会被忽略。
// a.cpp
#include <iostream>// b.cpp
#include <iostream>
int func1()
{return 0;
}a 中的 b 中都有,那么 a 会被忽略
解决方法就是删掉多余的 a 文件
CRT warning
对于某个单个文件想要忽略掉旧函数的安全提示,可以用
#define _CRT_SECURE_NO_WARNINGS
对于整个项目都想要忽略掉的话,可以为项目定义这个预编译头
渲染 Rendering 介绍
Design Architecture
如何 Draw API Line,举个例子,不同的平台上渲染的方式都不同,那么如何设计出那些通用的API方法,也就是找到一个普适的由Hazel的Drawing API Line组成的程序,根据平台的不同,去使用对应的override的方法。举个例子,Vulkan和OpenGL完全不一样,在OpenGL里,绘制一个三角形需要创建对应的Contex,而Vulkan里面需要调用Command Queue、rendering devices等等,但是二者肯定是有通用的地方的,比如都需要上传对应的vertices数据、上传对应的顶点数据、上传一个shader、调用drawcall等等,那么设计游戏引擎的时候,能不能设计出来通用的API框架呢?
如何设计 Graphics API Abstraction
下面给出了一个架构图,右边的都是具体与各个platform绑定的API,所以右边的API,需要对每一个平台,完成该平台对应的具体API的实现,简单的说,就是右边的东西都是与Platform相关的,这些东西属于Render API Primitives,而左边的渲染概念是所有平台通用的,举个例子,如果现在多了一个平台,叫Toby平台,那么右边所有的内容,都需要加一个分支,也就是增加对应的Toby平台的API的相关内容,而左边的内容是完全不会改变的:

关于渲染,如何画出上面这条线,也就是如何决定哪些类的平台无关的,哪些类是平台通用的,其实挺难的。即使做出了上面的这个划分,实际执行起来也没有那么简单,因为不同的平台使用的primitive(图右边的内容)可能也不是一样的,比如在OpenGL和Vulkan实现Deffered Renderer,在OpenGL上只需要创建一些frame buffers就可以了,而Vulkan需要额外的内容,比如pipelines、descriptive sets等,两个平台上相同内容的执行逻辑本身就是不一样的
关于左边的内容,这里再进一步解释一下
-
Scene Graph:场景里物体的Hierarchy,相当于Unity的Scene Hierarchy,UE4的World Outliner
-
Sorting:用于决定物体的渲染顺序,可以用于透明颜色的Blending,还可以把相同Material的物体sort到一起,然后一起渲染
-
Culling:决定哪些在Frustum里面,比如Occlusion Culling
-
Material:Material其实就是Shader和Uniform Data的集合(或者再加一个Texture)
-
LOD
-
Animation
-
Camera:Camera can be tied to a framebuffer or a camera may be redering to a render target
-
VFX:Visual Effects,比如粒子系统
-
postVFX:后处理效果,比如说颜色矫正,实现眩晕、酒醉效果或Screen Space Occlusion等
还有些内容,比如Render Command Queue,这个Queue用来存储所有渲染的指令,这样就可以开一个单独的线程用于执行这个Queue,Command Queue在Vulkan里是本身就有的,而OpenGL就没有这个功能,所以需要单独为OpenGL添加这一块的功能
如何起步
首先,选择使用OpenGL来开始工作,因为它是最简单和容易的图形库
然后,需要build Render API,这里就是使用OpenGL渲染出一个三角形即可,这一步我以前做过,没啥难度,注意这里并不是一次性build所有的Render API
接着,需要build Renderer,这个Renderer可以绘制一个三角形
最后,基于这个三角形的绘制,我们可以绘制任何东西
Rendering: Render Context
开始搭建渲染引擎的第一件事,就是创建对应的Render Context,这个Context是与平台相关的,不同的平台对应的Render Context也是不同的,现阶段不会像之前设计EventSystem那样先搭建好大多数的代码框架,而是会先从Render Context开始搭建
GLFW 的 context 支持 OpenGL 和 Vulkan,但是当我们想要做 DirectX 和 Metal 的时候,GLFW 就不够了
我们目前是在 Hazel\src\Platform\Windows\WindowsWindow.cpp 的 WindowsWindow::Init 中使用 glfw 提供的设置 context 的函数 glfwMakeContextCurrent 来完成 context 的设置,为了支持包含 DirectX 和 Metal 的多平台,这个就不能用了
同理,gladLoadGLLoader glfwSwapBuffers 也是不能支持 DirectX 和 Metal
最后我们可能要把 glfwSwapBuffers 抽象成一个函数,这个函数会完成
m_Context.SwapBuffers();
m_Context.GetSwapChain().Flush();
之类的
现在要做的就是创建一个Context类,经过反复考虑谁应该拥有Context后,决定,Context需要作为一个Static对象放到Window类里,这样就是一个Window里绘制一个平台的渲染图像,有的引擎可以在一个Window里实现左半边用DirectX绘制,右半边用OpenGL绘制,Hazel引擎暂时不打算支持这种功能。
其实具体的做法,就是创建一个Context类,然后把OpenGL的相关操作再封装一层
这里虽然是改成了 m_Context = new OpenGLContext(m_Window); 然后把一些 glfw 的操作移动到了 OpenGLContext 中,看上去好像没有什么方便,但是总之,这一结构意味着我们以后可以再创建一个 DirectXContext 然后使用统一的接口。多态嘛,基类定义接口,派生类实现,OpenGLContext 和 DirectXContext 都继承 GraphicsContext,这样的话我们在 GraphicsContext 定义一套统一的接口,就可以方便实现跨平台的操作
绘制三角形
之前学过 OpenGL,这里跳过
着色器 OpenGL Shaders
之前学过 OpenGL,这里跳过
官方 Shader 示例
https://www.khronos.org/opengl/wiki/Shader_Compilation
里面还讲了分离式的着色程序,例如第一个分离式的着色程序只有顶点着色器,第二个分离式的着色程序只有几何和片元着色器,然后我们创建一个着色管道将它们链接在一起,然后可以使用这个着色管道
我觉得,这样的方便之处在于,以前我们要更换着色器的话,是以着色器为单位进行更换的,现在是以可分离的着色程序为单位进行更换的,可能会更省力,比如在上面的例子中如果我想更换顶点着色器的话,我就不用管第二个可分离的着色程序了
渲染 API 抽象 Renderer API Abstraction
Compile Time Or Runtime
关于游戏引擎Hazel,它需要可以根据不同的平台使用不同的渲染接口,比如DirectX、OpenGL、Metal或者Vulkan等。目前有两种做法。
第一种是在Compile Time决定Hazel引擎使用哪种渲染API,具体是通过不同的宏来实现的,比如USE_OPENGL_RENDERER这些宏,然后根据这些宏的设定,对引擎代码进行编译,就只会编译OpenGL相关的渲染代码,如果我想要OpenGL来实现绘制,就使用对应的宏build OpenGL的代码,如果想用Vulkan就用Vulkan对应的宏来build Vulkan的代码,总之最后的build出来的引擎就只是支持一个平台的渲染API。
这样做的坏处时,一次build只能用一个平台的渲染API,而且每次切换渲染的API时,都需要rebuild相关代码,这对开发者来说是很不友好的,比如说同样的技术实现的画面效果,用DX或OpenGL应该是一样的,如果不一样就说明出了什么问题,如果开发者要对比两个平台的画面效果,那么要反复切换宏,然后rebuild,这很麻烦。虽然可以把各个渲染平台对应的组件,设置为各自的dll,但仍然需要在Compile Time重新编译代码,生成新的引擎build(应该最终是exe文件)。而好处就是,引擎在runtime不必花时间去判断到底用哪个平台的渲染API,所以runtime下效率会更快
第二种是在Runtime决定使用哪种渲染API,既然是Runtime那么肯定是不能用宏了,有人之前用if条件去为每一个渲染的API做一个条件判断,这样做工程量很大,也有点傻,这里建议的做法是利用多态(虚函数)来做,比如说有Shader类,那么就有OpenGLShader和DirectXShader这样各平台的派生类,这样在build时会编译所有可用平台的相关渲染api,比如ios平台就会编译OpenGL和metal的渲染API。
Vertex Buffer Layouts
OpenGL 和 DirectX 中的 Buffer Layout
在OpenGL里,描述顶点缓存的布局,与顶点着色器的关系不大,而DX里,只有绑定了顶点着色器后,才可以描述Buffer Layout。
在DX里,只有Vertex Buffer和Buffer Layout这种东西,没有像OpenGL这样专门搞一个VAO来描述最终使用的顶点数据,所以这里就按照DX的来,每一个Vertex Buffer,都有他自己对应的BufferLayout(所以要定义一个BufferLayout的类)
关于 initializer_list
方案 1
// Buffer.hclass BufferLayout
{
public:BufferLayout(const std::vector<BufferElement>& elements): m_Elements(elements){...}
private:std::vector<BufferElement> m_Elements;
}// OpenGLBuffer.hclass OpenGLVertexBuffer : public VertexBuffer
{
public:virtual void SetLayout(const BufferLayout& layout) override { m_Layout = layout; }...
}// Application.cpp// BufferLayout layout = { // wrong
std::vector<BufferElement> layout = { // list -> vector constructor -> vector{ ShaderDataType::Float3, "a_Position" },{ ShaderDataType::Float4, "a_Color" }
};m_VertexBuffer->SetLayout(layout); // vector -> vector copy constructor -> vector member
方案 2
// Buffer.hclass BufferLayout
{
public:BufferLayout(const std::initializer_list<BufferElement>& elements): m_Elements(elements){...}
private:std::vector<BufferElement> m_Elements;
}// OpenGLBuffer.hclass OpenGLVertexBuffer : public VertexBuffer
{
public:virtual void SetLayout(const BufferLayout& layout) override { m_Layout = layout; }...
}// Application.cppBufferLayout layout = { // list -> vector constructor -> vector member{ ShaderDataType::Float3, "a_Position" },{ ShaderDataType::Float4, "a_Color" }
};m_VertexBuffer->SetLayout(layout);
所以第一种方法多了一个 vector 的拷贝构造,要想消去的话,就要用 std::move
// BufferLayout layout = { // wrong
std::vector<BufferElement> vec = { // list -> vector constructor -> vector{ ShaderDataType::Float3, "a_Position" },{ ShaderDataType::Float4, "a_Color" }
};// m_VertexBuffer->SetLayout(layout); // vector -> vector copy constructor -> vector member
BufferLayout layout(std::move(vec)); // no vector copy constructor
关于 std::move 如何使用:
https://stackoverflow.com/questions/3413470/what-is-stdmove-and-when-should-it-be-used-and-does-it-actually-move-anythi
顶点数组对象 Vertex Arrays Object
OpenGL里的VAO,其实本身不包含任何Buffer的数据,它只是记录了Vertex Buffer和IndexBuffer的引用,并且使用glVertexAttribPointer函数来决定VAO通过哪种方式来挖取 VBO中的数据。
这一节课的目的是创建Vertex Array类,由于OpenGL有VAO这个东西,而DX里完全没有这个概念,但是前期的Hazel引擎是极大程度依赖OpenGL的,所以目前是先创建VertexArray类,至于Dx这种的,里面可能会有对应VertexArray的API,但里面的执行代码弄成空的就行了。
make_shared 和抽象类连用,无法构造对象
来自这个人的问题 https://blog.csdn.net/alexhu2010q/article/details/111030313
make_shared make_unique 这些是在内部调用了传入的模板类的构造函数的,所以不能用于抽象类,因为抽象类包含纯虚函数,无法构造对象
// Buffer.cppVertexBuffer* VertexBuffer::Create(float* vertices, uint32_t size)// Application.cppstd::shared_ptr<VertexBuffer> vertexBuffer;
// vertexBuffer.reset(VertexBuffer::Create(vertices, sizeof(vertices))); // right
// vertexBuffer = std::make_shared<VertexBuffer>(VertexBuffer::Create(vertices, sizeof(vertices))); // error: can not instantiate abstract class
vertexBuffer = std::shared_ptr<VertexBuffer>(VertexBuffer::Create(vertices, sizeof(vertices))); // right
const 限定符被丢弃
报错的第一种情况:
两个变量类型不匹配的时候,编译器实际上生成了一个临时变量进行类型转换
对于底层 const,不能通过引用来修改引用指向的变量,而现在底层 const 引用一个 tmp 变量,这是可以接受的,因为虽然这个 tmp 与原来的 a 没有关系,但是这个 tmp 不能被通过这个引用来更改,那么其实指向这个 tmp 的引用和 a 的引用的效果是一样的,所以编译器可以容忍
double a = 3;
const int& b = a; // right, because ref to const tmp var is meaningful// euqal todouble a = 3;
const int temp = a;
const int& b = temp;
但是如果没有 const,那么这里就相当于引用了一个临时变量,而这个临时变量与 a 没有任何关系,所以通过这个引用来修改值的时候不会影响到 a,就失去了期望的效果,所以编译器报错
double a = 3;
int& b = a; // wrong, because ref to non const tmp var is meaningless// euqal to double a = 3;
int temp = a;
int& b = temp;
报错的第二种情况
class OpenGLVertexArray : public VertexArray{public:...// virtual const std::shared_ptr<IndexBuffer>& GetIndexBuffer() const { return m_IndexBuffer; } // rightvirtual std::shared_ptr<IndexBuffer>& GetIndexBuffer() const { return m_IndexBuffer; } // wrongprivate:...std::shared_ptr<IndexBuffer> m_IndexBuffer;};
函数后加 const,那么返回的对象的前面会加上一个 const,但是函数返回值没有加 const,那么就相当于忽略了 const 限定符,导致报错
渲染流和提交 Render Flow And Submission
之前对 VerterBuffer、VertexArray、IndexBuffer进行了抽象化,也就是说目前Application里不会有具体的OpenGL这种平台相关的代码,还剩下一个DrawCall没有进行抽象化,也就是里面的glDrawElements函数,还有相关的glClear和glClearColor没有抽象化。
Renderer Architecture
前面做的抽象化,比如VertexBuffer、VertexArray,这些都是渲染要用到的相关概念的类抽象,真正的跨平台 用于渲染的Renderer类还没有创建起来。
思考一下,一个Renderer需要干什么 它需要Render一个Geometry。Render一个Geometry需要以下内容:
-
一个Vertex Array,包含了VertexBuffers和一个IndexBuffer
-
一个Shader
-
人物的视角,即Camera系统,本质上就是一个Projection和View矩阵
-
绘制物体的所在的世界坐标,前面的VertexBuffer里记录的是局部坐标,也就是Model(World)矩阵
-
Cube表面的材质属性,wooden或者plastic,金属度等相关属性,这个也可以属于Shader的范畴
-
环境信息:比如环境光照、比如Environment Map、Radiance Map
这些信息可以分为两类:
-
环境相关的信息:渲染不同的物体时,环境信息也一般是相同的,比如环境光照、人物的视角等
-
被渲染的物体相关的信息:不同物体的相关信息很多是不同的,比如VertexArray,也可能部分属性相同(比如材质),这些相同的内容可以在批处理里进行处理,从而优化性能
总结得到,一个Renderer应该具有以下功能:
-
设置环境相关的信息
-
接受被渲染的物体,传入它对应的数据,比如Vertex Array、引用的Material和Shader
-
渲染物体,调用DrawCall
-
批处理,为了优化性能,把相同材质的物体一起渲染等
可以把Renderer每帧执行的任务分为四个步骤:
-
BeginScene: 负责每帧渲染前的环境设置
-
Submit:收集场景数据,同时收集渲染命令,提交渲染命令到队列里
-
EndScene:对收集到的场景数据进行优化
-
Render:按照渲染队列,进行渲染
具体步骤如下:
-
BeginScene
由于环境相关的信息是相同的,所以在Renderer开始渲染的阶段,需要先搭建相关环境,为此设计了一个Begin Scene函数。Begin Scene阶段,基本就是告诉Renderer,我要开始渲染一个场景,然后会设置其周围的环境(比如环境光照)、Camera。
-
Submit
这个阶段,就可以渲染每一个Mesh了,他们的Transform矩阵一般是不同的,依次传给Renderer就可以了,这里会把所有的渲染命令都commit到RenderCommandQueue里。
-
End Scene
应该是在这个阶段,在收集完场景数据后,做一些优化的操作,比如
-
把使用相同的材质的物体合并到一起(Batch)
-
把在Frustum外部的物体Cull掉
-
根据位置进行排序
-
-
Render
在把所有的东西都commit到RenderCommandQueue里后,所有的Scene相关的东西,现在Renderer都处理好了,也都拥有了该数据,就可以开始渲染了。
整个过程的代码示例:
// 在Render Loop里
while (m_Running)
{// 这个ClearColor是游戏最底层的颜色,一般不会出现在用户界面里,可能用得比较少RenderCommand::SetClearColor();// 参数省略RenderCommand::Clear();RenderCommand::DrawIndexed();Renderer::BeginScene();// 用于设置Camera、Environment和lighting等Renderer::Submit();// 提交Mesh给RendererRenderer::EndScene();// 在多线程渲染里,可能会在这个阶段用一个另外的线程执行Render::Flush操作,需要结合Render Command QueueRenderer::Flush();...
}Renderer 是对渲染部分的拆分,就像上面所展示的那样 BeginScene() Submit() EndScene()
然后 Renderer 拆分的步骤里面调用的是 RenderCommand,RenderCommand 里面有很多静态函数,作为接口,RenderCommand 还有一个指向 RendererAPI 的指针,这是 impl 的思想,把实现封装到第二个类用指针指向它,就相当于用指针封装了实现
然后 RendererAPI 是抽象类,具体实现看派生类,依次实现跨平台的操作
摄像机 CAMERAS
Camera除了与渲染相关,还与玩家有着交互, 比如User Input、比如玩家移动的时候,Camera往往也需要移动,所以说,Camera既受GamePlay影响,也会被Submit到Renderer做渲染工作,这节课的主要目的是Planning。
Camera本身是一个虚拟的概念,它的本质其实就是View和Projection矩阵的设置,其属性有:
-
相机的位置
-
相机的相关属性,比如FOV,比如Aspect Ratio
-
MVP三个矩阵里,M是与模型密切相关的,但是不同模型在同一个相机下,V和P矩阵是相同的,所以说,VP矩阵属于相机的属性
实际渲染时,默认相机都是在世界坐标系原点,朝向-z方向看的,当调整相机属性时,比如说Zoom In的时候,相机的位置并没有变,实际上是整个世界的物体在靠近相机,即往Camera这边平移;当我们向左移动相机的时候,其实没有Camera这个概念,实际上我们是把所有世界的物体向右移,所以,相机的transform变化矩阵与物体的transform变化矩阵正好是互逆的。也就是说,我们可以通过记录相机的transformation矩阵,然后取逆矩阵,就可以得到对应的View矩阵了,这里只需要Position和Rotation,因为相机是没有缩放的。
顶点坐标计算时的归属分配问题
如下图所示,是一个顶点进行计算到屏幕坐标系的过程:
gl_Position = project * view * model * vertPos
project * view 是属于相机的,相机看到的所有物体的投影变换和视角变换都是一样的
model 是属于物体的,每个物体在自己的局部坐标系下的变换是不一样的
Camera作为参数传给Renderer的BeginScene函数
具体在代码里的思路是,在游戏的Game Loop里有一个BeginScene函数,这个函数是Renderer的静态函数,会去更新相机、灯光等设置,所以这里的BeginScene函数里需要接受Camera类的对象作为参数,不过这里的作为参数,会有两种做法:
-
Camera对象作为引用传入BeginScene函数,传入的是引用
-
Camera对象作值传入BeginScene函数,传入的是值
正常情况下,我思考的肯定是第一种传Camera的方法,但是这里却需要选择第二种,原因就在于,这里是多线程渲染,因为在多线程渲染里,会把函数都放在RenderCommandQueue里执行,这个BeginScene也会放进去,而在RenderCommandQueue里的函数,如果存了相机的引用,是一件比较危险的事情,因为多线程代码里有了camera的引用,camera在多线程渲染的时候就不保证是不变的,如果渲染时主线程更改了Camera的相关信息,比如Camera的Pos, 就会乱套(注意,传入const& 也不行,因为这只能保证不在RenderCommandQueue里去改Camera的信息,并不代表主线程里不可以改变Camera的信息)
太强了……我自己看视频的时候感觉油管主好像没有提到?这个博客的作者就已经思考了这么多了
正交相机 Orthographic Camera
没什么好说的
时间戳 TIMESTEPS and DELTA TIME
原视频没什么好说的
三种 Timestamp
参考 https://gafferongames.com/post/fix_your_timestep/
Fixed Timestamp
固定 dt 等于某一值
double t = 0.0;double dt = 1.0 / 60.0;while ( !quit ){integrate( state, t, dt );render( state );t += dt;}
但是物理解算和渲染耗时不一定是 dt,这样可能导致物理和渲染不同步
Variable Timestamp
dt 可变,根据上一帧实际所用时间而定
double t = 0.0;double currentTime = hires_time_in_seconds();while ( !quit ){double newTime = hires_time_in_seconds();double frameTime = newTime - currentTime;currentTime = newTime;integrate( state, t, frameTime );t += frameTime;render( state );}
这样虽然确实会得到正确的 dt,不会有不同步的问题,但是实际游戏中每帧用时如果相差比较大的话,dt 可能不稳定,dt 不稳定,可能超过某个值,带来游戏设计者不期望的效果,例如,步长过大导致的物理解算不稳定
Semi-fixed Timestep
这里 dt 被限制在不大于给定的值,例如不大于 1/60
如果大于了,那么就多次模拟 dt = 给定值 的物理解算
double t = 0.0;double dt = 1 / 60.0;double currentTime = hires_time_in_seconds();while ( !quit ){double newTime = hires_time_in_seconds();double frameTime = newTime - currentTime;currentTime = newTime;while ( frameTime > 0.0 ){float deltaTime = min( frameTime, dt );integrate( state, t, deltaTime );frameTime -= deltaTime;t += deltaTime;}render( state );}
这样有一个问题,可能陷入模拟的死亡螺旋
spiral of death
在 Semi-fixed Timestep 中,如果你的单帧物理模拟时间大于 dt 阈值,那么实际上下一次你的两帧之间的时间间隔会变长,因为实际用时大于模拟 dt 的这个 dt 的时间。如果一直单帧物理模拟时间大于 dt,那么两帧之间的时间间隔会单调增加,无限增加最后达到不可忽视的地步
解决方法也很容易想到,要么就确保你的单帧的物理解算时间确实小于模拟的 dt,要么就是钳制模拟的次数(模拟的次数减少了,表现上就是物理效果变慢了)
物理确定性
在需要网络同步的游戏中,如果游戏逻辑是同步输入的,那么我们希望客户端的物理是确定性的,才能在各个客户端之间得到相同的物理表现
但是各个客户端之间的电脑配置是不一样的,所以每一帧的渲染时间也是不一样的,而之前的 Semi-fixed Timestep 的物理模拟的 dt 其实是和渲染速率相关的,例如,假设 dt 阈值是 1/60,现在渲染 FPS = 100,那么物理模拟速率显然也是被动的成为 100 FPS
现在我们希望各个客户端之间的渲染速率可以不一样,但是物理模拟速率一样,所以我们需要一个新的方法:
double t = 0.0;const double dt = 0.01;double currentTime = hires_time_in_seconds();double accumulator = 0.0;while ( !quit ){double newTime = hires_time_in_seconds();double frameTime = newTime - currentTime;currentTime = newTime;accumulator += frameTime;while ( accumulator >= dt ){integrate( state, t, dt );accumulator -= dt;t += dt;}render( state );}
这里我们实现了物理模拟的 dt 为给定的值,同时渲染速率是由硬件决定
这里也会有死亡螺旋问题
物理模拟插值
因为我们使用了固定 dt 的物理模拟,所以当累加器中的值小于 dt 时,不会执行一次完整的物理模拟
所以我们希望最后一次执行完物理模拟之后,这个时候的物理状态为 curr,累加器还剩下一个小于 dt 的值,我们将他除以 dt,转化为一个 0 到 1 的比率,然后把 prev = curr,再模拟一步物理,更新 curr,然后在 curr 之间插值
double t = 0.0;double dt = 0.01;double currentTime = hires_time_in_seconds();double accumulator = 0.0;State previous;State current;while ( !quit ){double newTime = time();double frameTime = newTime - currentTime;if ( frameTime > 0.25 )frameTime = 0.25;currentTime = newTime;accumulator += frameTime;while ( accumulator >= dt ){previousState = currentState;integrate( currentState, t, dt );t += dt;accumulator -= dt;}const double alpha = accumulator / dt;State state = currentState * alpha + previousState * ( 1.0 - alpha );render( state );}
这里两个渲染帧之间的物理模拟的次数做了限制
if ( frameTime > 0.25 )frameTime = 0.25;
然后这个代码似乎是向后插值的,这让我很迷惑,我觉得应该向前插值啊
比如写成
double t = 0.0;double dt = 0.01;double currentTime = hires_time_in_seconds();double accumulator = 0.0;State previous;State current;while ( !quit ){double newTime = time();double frameTime = newTime - currentTime;if ( frameTime > 0.25 )frameTime = 0.25;currentTime = newTime;accumulator += frameTime;double alpha = 0.0;while ( accumulator > 0.0 ){previousState = currentState;integrate( currentState, t, dt );t += dt;accumulator -= dt;if ( accumulator < dt ){alpha = accumulator / dt;accumulator = 0.0;}}State state = currentState * alpha + previousState * ( 1.0 - alpha );render( state );}
变换 Transform
添加一个 Transform 表示模型在世界中的位置
材质 Material
Material 是包装了 shader 的绑定,uniform 变量的提交等操作
着色器抽象类 Shader Abstraction and Uniforms
为了跨平台,Shader 做成抽象类,glfw 相关的放到 OpenGLShader 派生类中
引用,作用域和智能指针 Refs, Scopes and Smart Pointers
做了一个缩写
// Core.h
namespace Hazel
{template<typename T>using Scope = std::unique_ptr<T>;template<typename T>using Ref = std::shared_ptr<T>;}为什么 Shader 不设置为 unique_ptr 而是设置为 shared_ptr
我们现在是要对整个场景进行渲染
而现在我们是每一个层级之内有一些 Shader,VAO 要提交到渲染器
Shader VAO 那些都可能是体积挺大的,都是资源文件,所以我们需要用指针来指向
那好,真实的场景中可能是有多个层级,如果某一个层级被 pop 了,失去了引用,销毁了,然后如果其中的 shader 和 VAO 等等是 unique_ptr,就会被销毁
但是实际的渲染是延迟的,就是说,先要把场景中所有的资源先提交,然后统一处理,所以并不是提交了某个 shader 之后就立即渲染的,是有一个延迟的,如果在这个延迟的过程中销毁了 shader,实际渲染的时候就找不到了
还有多线程的问题
shared_ptr是线程安全的,它的引用计数的加和减操作都是原子级别的,为了保证多线程,会造成额外的消耗,所以如果不是在多线程下使用的,为了更高效,未来还可能需要实现自己引擎的shared_ptr类,无非不是线程安全的
根据编程经验,绝大多数情况下,可以使用shared_ptr,而不是unique_ptr,二者性能开销其实不大,如果二者性能开销较大,可能还不如用raw pointers
这里的Hazel::Ref,也就是shared_ptr引用计数的部分,可以视作一个非常粗略的AssetManager,一旦资源的引用计数为0,则自动销毁该资源
shared_ptr 的引用计数存放在一个 new 出来的 int 内存中(shared_ptr 中有一个指针指向存放引用计数的内存),多个指向相同对象的 shared_ptr 共享这个引用计数的内存(shared_ptr 的指向引用计数的指针都指向这个内存)因为是 new 出来的,所以在堆上
传递智能指针的本质是在传递“所有权”(ownership),传递 shared_ptr 对象实例是传递一个可以共享的所有权,传递 unique_ptr 对象是传递一个唯一的所有权
一般来说,如果是传递 shared_ptr 对象,如果是值传递,那么会改变它的引用计数,那么这种情况一般是想要延长这个对象的生命周期,例如这里提到的渲染器的例子。如果是传递 shared_ptr 的引用,这么做的原因可能是因为值传递 shared_ptr 涉及到线程安全,所以可能花费较大,但是传递引用那么不会增加它的引用计数,那么就要小心确保拿到这个引用之后,函数不会意外释放它,导致引用计数错误,所以我们一般用 const & 避免意外释放
void doSomething(std::shared_ptr<int>& o) {o = nullptr; // usage wrong but pass compilation}void doSomething2(const std::shared_ptr<int>& o) {o = nullptr; // don't pass compilation}
其他的可见:
shared_ptr 的用法及事故:
https://heleifz.github.io/14696398760857.html
-
用 shared_ptr,不用 new
-
使用 weak_ptr 来打破循环引用
-
用 make_shared 来生成 shared_ptr
虽然他举的例子是
f(shared_ptr<A>(new A), shared_ptr<B>(new B));但是在 C++17 中,某一个函数参数完全计算之后才会轮到下一个参数计算,所以new A之后一定是shared_ptr<A>,new B之后一定是shared_ptr<B>,虽然 new A 和 new B 不知道谁先谁后,但是不会出现内存泄露了 -
用 enable_shared_from_this 来使一个类能获取自身的 shared_ptr
防止返回 this 野指针(的写法)(就是说
return std::shared_ptr<A>(this);这种写法算是构造了一个新的 shared_ptr 而不是从现有的 shared_ptr 中复制的) -
传递 shared_ptr 时,要么值传递,要么用
const &
材质素材 TEXTURES
Textures 并不只是单纯的颜色组合出来的一张图而已,它还可以存储一些离线计算的结果,还有法线贴图等,比如动画里,甚至可以用其存储skin矩阵
代码实现是 Texture 抽象类,派生类跨平台,用 stb_image.h 加载纹理,没什么好说的
一般我们把资源文件的路径存放在一个 AssetManager 里面,这样当硬盘上的资源文件更新的时候,我们就可以根据这个路径将最新的资源文件更新到我们的游戏工程里面
但是目前我们还没有这个 AssetManager,所以我们暂时把路径存放在资源类里面
混合 Blend
材质混合这些设置属于初始化的范围,所以我们再在 renderer command 中添加一个初始化的内容,他也是 impl 的,最后调用 openglrenderAPI 中的 init,其中放着比如设置混合模式的函数
着色器资源文件 Shader Asset Files
利用ifstream来读取文件
一般来说,游戏引擎里的Shader,都是在Editor下预先编译好的二进制文件,然后再在Runtime对其进行组合和应用
着色器库 ShaderLibrary
这章也很简单,其实就是把Shader的读取和存储位置都分配到ShaderLibrary类里,ShaderLibrary本质就是个哈希map,key是shader的名字,value是shader的内容
创建 2D 渲染器 How to Build a 2D Renderer
不管是3D还是2D的游戏引擎,都需要渲染2D的东西,因为一个游戏里是必须有UI的。
渲染架构
目前引擎里Render的代码是这样的:
// 把Camera里的VP矩阵信息传到Renderer的SceneData里
Hazel::Renderer::BeginScene(m_Camera);
{glm::mat4 scale = glm::scale(glm::mat4(1.0f), glm::vec3(0.1f));...flatColorShader->UploadUniformVec4("u_Color", m_FlatColor);// Submit里面会bind shader, 上传Vertex Array, 然后调用DrawCallHazel::Renderer::Submit(flatColorShader, m_QuadVertexArray, transform);...Hazel::Renderer::Submit(textureShader, m_QuadVertexArray, transform);...
}
Hazel::Renderer::EndScene();
这里面的操作基本就是,设置统一的SceneData后,针对各个VertexArray,也就是Mesh,提交其Mesh数据,然后添加对应的Draw的命令。
但这套操作,对于绘制2D的内容而言,不太符合,有这么几个原因:
-
2D的渲染过程中,基本没有Mesh这个概念,它不需要Vertex Array,因为万物皆可用Quad来表示
-
2D的渲染,也没啥Shader和Material的概念,因为它就是一张图贴上去而已,还要啥渲染(感觉加点类似光照的后处理是不是就行了)?
那么如何设计相关的2D渲染呢,由于3D渲染和2D渲染的相机不同,这里直接可以分为两个Scene,然后设置不同的Renderer即可设计两种Renderer,分别负责2D和3D的内容,大概是这样:
Hazel::Renderer::BeginScene(m_Camera);
{Hazel::Renderer::DrawCube(...);// 3D...
}
Hazel::Renderer::EndScene();Hazel::Renderer2D::BeginScene(m_OrthographicCamera);
{Hazel::Renderer2D::DrawQuad(...);// 2D...
}
Hazel::Renderer2D::EndScene();
2D Renderer需要支持的内容
2D的Renderer主要需要实现以下内容:
-
2D Batch Render: 支持批处理的2D Renderer,主要是合并多个Quad的Geometry
-
Texture Atlas的支持
-
Sprite Animation系统
-
贴图Data压缩技术:大概是只保留第一帧的全数据,后面都只记录产生变化的像素的Delta值,主要是为了支持高精度的贴图,后面会细聊
-
UI系统:主要是Layout系统,还挺复杂的,比如怎么布置UI、UI元素怎么随窗口变化而自动匹配、怎么对其Text、怎么支持不同分辨率的屏幕、Font文件的读取和使用(文字的SpriteSheet)
-
后处理系统:为了做好2D游戏,这个系统是必须的,比如做2D的爆炸特效、实现HDR、粒子系统、blur、bloom的后处理效果、Color Grading用于矫正颜色
-
Scripting:暂时不需要考虑
不需要考虑的:
- Dynamic Lighting
在性能上,目标是实现每帧绘制10W个quad,而且fps在60以上。
关于BatchRenderer和Texture Atlas
目前是做2D的部分,那么先实现2D的quad的批处理即可,至于每帧的贴图个数,实际上游戏引擎里的需求,一般每帧用到一两百张贴图就已经很多了。假设GPU上有32个贴图槽位,假设其中的8个是用于其他需求的,不是用于直接渲染的,那么还剩24个槽位。那么120张贴图,就要Flush Renderer五次,也就是五次Draw Call。所以2D的渲染来说,Texture Atlas或者说Sprite Sheet,至关重要。就是在一张贴图上,尽可能多的存储贴图内容。当然,这种适合小的低像素的贴图,才能进行组合,如果是一个4K的贴图,那么一般是不会把它合并到Texture Atlas里面的。
关于Scripting
当谈到Game Engine与User的Interaction部分时,人们很容易想到ECS架构或者CGO(Composable GameObjects)。也就是说GameObject可以通过Component来组合,而不是代码里面的通过继承来组合(比如多重继承)。比如一个Player,是个Entity,然后里面添加各种Component,比如:
-
Transform组件
-
Renderer组件
-
Script组件,用于负责Interaction和自定义行为
但这里提到的是Scriting。有的是用lua作为脚本语言,UE4里用蓝图作为可视化的脚本,还提供了U++;Frosbite里也提供了类似蓝图的schematics,Unity是C#,基本的游戏引擎都有这块部分。
相机控制器 Camera Controllers
把相机初始化,相机移动和缩放,相机的 view 和 proj 矩阵的更新放到了一个 Camera Controllers 里面
Resizing
glfw 窗口 resize 的时候,需要做:
-
从 glfw 的 resize 事件唤起引擎自己设置的 resize 事件
或许在 glfw 的 resize 事件中还需要做的:
-
重新设置 opengl 的 framebuffer
也不是所有 framebuffer 都需要调整,例如阴影贴图,可能就是一直就是 1024 * 1024
-
设置一个 framembuffer pool,避免重复创建内存。
-
-
在引擎自己设置的 resize 事件中,自定义逻辑
-
通知摄像机跟随变化
这里还涉及到一个东西,就是相机如何根据窗口大小变化而变化,比如,当窗口变大时,画面是变大,还是会展示更多的内容?
如果窗口改变的时候,只调整Viewport,那么窗口里绘制的东西,会随着窗口变大而变大;如果不想改变尺寸,那么需要调整正交相机的投影矩阵,动态调整 zoom 和 aspectRadio
正交相机中可能需要考虑一下用哪种方法,而投影相机中一般都是调整 zoom 和 aspectRadio
-
-
给Application类添加一个bool,标识窗口是否被缩小化了
缩小的时候,窗口的width和height都会接收WindowResizedEvent变成0,所以当缩小化时,需要停止各个Layer的更新。
现在是这么写
bool OrthographicCameraController::OnWindowResized(WindowResizeEvent& e){m_AspectRatio = (float)e.GetWidth() / (float)e.GetHeight();m_Camera.SetProjection(-m_AspectRatio * m_ZoomLevel, m_AspectRatio * m_ZoomLevel, -m_ZoomLevel, m_ZoomLevel);return false;}
这样写的效果就是,在 X 上拉伸,物体不会缩放,只是能看到的画面变多,而在 Y 上拉伸,物体会缩放
因为 m_AspectRatio 的定义是依赖于某一个轴的
同时这个 proj 矩阵也影响了世界中的一个单位是否是对应屏幕上的一个像素单位……
可维护性 Maintenance
整理了一下文件
Preparing for 2D Rendering
将 2d 部分的 VAO 摄像机 渲染提交放到了一个 Sandbox2D 层中
Starting our 2D Renderer
为了避免跟原本的3D的Renderer混淆,这里创建了个Renderer2D,内容也比较简单,里面全部都是静态函数,之所以不做成成员函数是因为没有必要,毕竟成员函数本质上也是静态函数,无非静态函数的第一个参数变成了this指针而已。
这里可以开始设计Renderer2D类了,这里设计的Renderer2D,与原本的Renderer类的区别在于:
-
2D渲染里没有什么Vertex Array和Mesh的概念,万物皆可用带贴图的quad绘制,所以这里只会有唯一的Mesh数据,所以这里直接把quad的顶点数据作为静态数组存在了Renderer2D类里,在其Init函数里被创建出来。
-
2D渲染里,基本不需要用户在绘制的时候传入自定义的Shader,所以Shader可以作为Renderer2D的静态数据
emmm我感觉 2d 不需要 shader 有点不对劲吧
2D Renderer Transforms and Textures
Renderer2D 现在有两种 DrawQuad 函数,一种是传入颜色一种是传入纹理的,它们内部使用的 Shader 都是写死了的
在 Shader 基类中设置了统一的虚函数:Uniform 的设置函数,在 OpenGLShader 实现
现在就可以用 Ref<Shader> 的指针直接调用 Set Uniform 的函数,而不用像之前那样笨笨的 dynamic_cast 到派生类再调用派生类的特定实现函数
在 OpenGLRendererAPI::Init() 中设置了深度测试
Single Shader 2D Renderer
之前说的那个Renderer2D 现在有两种 DrawQuad 函数,一种是传入颜色一种是传入纹理的,它们内部使用的 Shader 都是写死了的
这里是两个 Shader,现在我们希望写成一个 Shader
其实就是一直写成采样 * main_color 的形式
对于传入颜色的 DrawQuad,那么就把 shader 的纹理参数设置成 runtime 创建的一个贴图 WhiteTexture,它的width和height均为1,图片通道格式为RGBA或者RGB,每个pixel的值都是(1,1,1,1)或(1,1,1)。
那么 Texture 中新增一个函数,用于传入长和宽来创建一个 Texture
之前我们是传入纹理的地址,在内部使用 stb_image.h 来读取纹理,现在这个是没有现有的纹理,直接创建空纹理
所以我们需要指定纹理的长宽和格式,长宽是构造函数输入的,格式是构造函数内部写死的,比如纹理格式设置为 GL_RGBA8,指定一个内部格式,这样我们就知道一个通道有多少位,方便我们在传入原始数据指针之前先计算好我们要准备什么样的数据
glTextureSubImage2D 用于从现有的数据指针,也就是原始数据中创建纹理
对于传入纹理的 DrawQuad,那么就把 shader 的颜色参数设置成白色
Intro to Profiling
他这个计时类的写法就很骚
它把开始计时写在构造函数里面,结束计时写在析构函数里面,构造函数中传入了回调函数,计时结束时也就是析构时调用回调函数
创建一个宏定义,包装创建类的语句,其中回调函数是把计时结果压入自己的一个堆栈变量
这样,当我们在一个作用域内调用这个宏定义的时候,我们就是在创建计时器,然后程序退出这个作用域的时候,局部变量析构,也就是计时器析构,那么退出作用域的同时就停止计时了
因此我们就用一个宏定义就完成了计时的功能,其他什么都不用操作了,太妙了
你还可以自己用花括号做一个作用域出来
Visual Profiling
按照一定的格式把计时器记录的信息写成 json
然后谷歌浏览器有一个内置的功能读取这个 json 输出时序图 chrome://tracing
这样的意义应该就是,我们也可以自己写 json 自己写读取 json 输出时序图的功能
或许 imgui 中就有这样的示例……或者有人写过……?
然后还有一些可以提到的就是,如果两次计时比较相近的话,返回的值可能会相同,这样导致两个计时项分不开,可能需要一些 dirty 的操作,例如确保计时器不会返回与上一次相同的数……
好吧……之后别人的更改也很简单,把 high_resolution_clock 改成了 steady_clock
Instrumentation
指定时间开始录制指定时间结束录制
Improving our 2D Rendering API
为 DrawQuad 函数添加了缩放比例和旋转角度这两个参数
shader 也对应地更改
emmmm在我看来这都是没有必要的(也不是这么说,只是我感觉现在缺少那种通用的 Draw 才导致居然连 uniform 参数的传递都要写到函数参数里面,一般来说这应该是脚本来完成的把
How I Made a Game in an Hour Using Hazel
Hazel 2020
Hazel决定使用lua作为脚本语言,lua非常简单,其实就是相当于几个C++文件、5000多行代码而已,这里没有选择C#作为脚本语言,然后用Mono来跨平台,是因为这样做工作量太大了。尽管C#是很好用的语言,但基于跨平台的原因,还是不选择它。不过如果只想在Win平台上发布游戏,那么游戏引擎是可以考虑用C#的,此时可以用C++/CLI来负责C++与C#的交互。
批渲染 BATCH RENDERING
一开始创建一个数据区,大小为一次批处理最多绘制的长方形数量 * 单个长方形的 uniform 数据大小,我们得到了这个数据区开头的指针,设为 base
之后我们要画长方形的时候,就往这个 base 指向的数据区里面填充一个长方形的数据,例如 Position Color TexCoord 等
填充数据的时候,我们有维护一个指向数据区末尾的指针 ptr,还有维护要绘制的长方形的数量
然后等到 Render2D 在一个循环里面结束了,我们让 ptr-base 就得到了数据区的大小,我们把这个 base 和数据区的大小传入 opengl,opengl 就知道了 VBO 的大小
具体到 ptr - base 是怎么算的,可以提一下,我之前还没见过这种写法
uint32_t dataSize = (uint8_t*)s_Data.QuadVertexBufferPtr - (uint8_t*)s_Data.QuadVertexBufferBase;
这种写法就是把指针指向的对象的大小设置为了 8 个比特,也就是一个字节,也就是说,现在指针与指针之间的间隔用一个比特来衡量,那么 ptr - base 得到的数字的单位就是比特,这样就能够满足 opengl 的要求
而我们在初始化的时候已经设置了 VAO 解释了各个属性,我们还在初始化设置了一整个 EBO,EBO 的大小是 一次批处理最多绘制的长方形数量 * 单个长方形的顶点数
这样,我们之前已经设置好了 VAO,也一次设置了好整个 EBO,所以我们直接传入数据区的大小,base 指针,要绘制的长方形的数量,就可以完成一次批渲染了
但是这样有一个问题就是……如果有些长方形不想渲染了,怎么删掉……因为现在对数据区的处理是单调增的,还没有删除相关的
具体思路:
-
在Renderer2D的Init函数里,创建动态可更新的VertexBuffer
-
在Renderer2D的Init函数里,创建静态的IndexBuffer
-
修改Renderer2D的static SceneData数据,把里面的VertexArray里的Vertex Buffer调整为1W个Quad大小的动态Buffer,Index Buffer调整为1W个Quad大小的静态Buffer,创建时,俩Buffer里的数据都是uninitialized data
-
修改DrawQuad函数,让其绘制时动态往Vertex Buffer里填充要绘制的顶点属性数据,同时记录绘制Quad的个数,目前只支持绘制FlatColor,DrawQuad对应的FlatColor颜色会作为颜色的顶点属性存在Vertex Buffer里
-
在EndScene里,根据记录绘制Quad的个数,填充IndexBuffer里的数据,然后调用DrawCall绘制这些Quads
Batch Rendering Textures
基本思路是在提供的GPU槽位上绑定尽可能多的贴图,然后让Vertex Attribute里包含使用的Texture的id。这个贴图槽位数,即Texture slot limit,取决于GPU。A desktop GPU至少会有32个贴图槽位,而手机则至少有8个,技术层面上,向GPU驱动去查询GPU的最多贴图槽位,这样是比较合理的。但是目前还是就写成最多32个槽位,因为查询GPU相关参数这个功能还比较麻烦。
另外,为了让使用相同的贴图的DrawQuad函数能合并使用同一张贴图,需要设置一个数据结构,用于记录已经用于绘制的贴图,类似于map,key为贴图资源的引用,value为贴图绑定的槽位,这样,当绘制一个带Texture的Quad时,它会去检查map,如果有key,就取得对应的贴图槽位,存到顶点属性里,合并到一个DrawCall内。当然,这个map可能还不止32个key,所以最多一次DrawCall是绘制32种贴图的Quad,但对于2D的Renderer来说,由于Texture Atlas存在,这种超过32个贴图的情况很少见,就先不考虑了。感觉用array代替map也行,无非是把数组的id作为槽位就可以了。
注意:这里的Texture的Key需要是一个unique identifier,这里可以临时使用OpenGL的TextureID,但是对于游戏引擎而言,贴图是一种资源,游戏引擎应该有自己的资源系统,对于任何一种资源,引擎都应该为其生成一个资源的Unique ID,作为Asset Handle,比如Unity把资源的ID存到了其.meta文件里。因为资源生成的Asset Handle不应该存在资源文件里,第一点,正常情况下,即使资源文件被美术家修改了,其Asset Handle也不应该变,如果变了,那原本引用这个素材的,记录了这个素材的旧 id 的文件就会失去对这个素材的引用。同理,Asset Handle 更不应该是运行时的东西,比如 opengl 生成材质的 texture id。
具体思路如下:
-
创建Texture数组,数组大小为32,数组id对应的是贴图槽位,数组元素是Texture的ID,会在BeginScene里被重置,即数组元素全部为0,然后记录一个s_Data.CurrentTextureSlotID,在BeginScene被初始化为1(因为0号槽位预定给了WhiteTexture使用,用于绘制FlatColor)
-
修改Shader文件,用来同时适配32个Texture Uniform槽位
-
Shader 中会接受一个 float uniform 作为 TexIndex(用 int 也可以就是要加 flat,表明从顶点着色器到片元着色器不插值),外部设置 VertexBuffer 的时候,要多设置一个 TexIndex
同样这里也没有做从存储了这 32 个 Texture 的 map 中删除元素的逻辑
使用 flat v_TexIndex 解决 z-fighting
https://github.com/TheCherno/Hazel/pull/362
可以使用 flat v_TexIndex 解决 z-fighting
emmm说实话,我从来没有想过要这么批处理纹理,所以这个问题我没有想过……明明 v_TexIndex 只是用来 switch 的
Drawing Rotated Quads
现在 DrawQuad 的 API 变成,我们已经有了静态的四边形的四个点的坐标,现在我们输入了 pos, size, rotation,就可以组成一个transform,对我们的静态的坐标 transform,就是得到了要求的点的坐标,组成 VBO
Index Buffer 可以先绑定到 GL_ARRAY_BUFFER 设置缓冲,再绑定到 GL_ELEMENT_ARRAY_BUFFER
根据 commit 5e94d7da514829d69c22e93202319ade63f29d67
我们一般学的是,Index Buffer 要绑定到 GL_ELEMENT_ARRAY_BUFFER
但是这个 commit 说,绑定到 GL_ELEMENT_ARRAY_BUFFER 需要已经有 VAO 绑定,这样的话就不能实现顺序无关了,所以我们可以先绑定到 GL_ARRAY_BUFFER,他是与 VAO 无关的
等到我们真正要用到这个 Index Buffer 的时候,我们再绑定到 GL_ELEMENT_ARRAY_BUFFER
Renderer Stats and Batch Improvements
-
添加Renderer的相关Statistics信息,比如当前帧调用了几个DrawCall?绘制了多少个Quad
-
改进Batch系统,添加了一个 FlushAndReset,在存储的顶点数据达到给定上限的时候,可以将顶点数据 Flush 掉(提交一次渲染),然后重置顶点数据指针,复用这一块内存
但是仍然没有删除某一个长方形的功能
-
用ImGui把Stats绘制出来
我感觉他这里 FlushAndReset() 中少了对 ResetStats() 的调用……?
Debug 模式和 Release 模式差距还挺大的
Testing Hazel’s Performance
Let’s Make Something in Hazel
只能使用 int uniform 作为 array uniform 的 index
根据
https://github.com/TheCherno/Hazel/pulls?q=18abce3c28db4e8384ad21cf64b6d36bee003215
OpenGL 只能使用 int uniform 作为 array uniform 的 index
C++类的成员变量初始化顺序
构造函数的列表初始化中,成员变量的初始化顺序,不是列表中的顺序,而是按照对应变量出现在C++类头文件定义的顺序先后来初始化的
How Sprite Sheets/Texture Atlases Work
采样精灵表
SubTextures - Creating a Sprite Sheet API
-
为了方便处理SpriteSheet或者说Texture Atlas,可以添加一个额外的SubTexture类,它本质上就是一个Texture的Wrapper,然后添加了额外的四个TexCoord坐标,用于表示Texture对应部分区域的Texture,从而起到SubTexture的作用。
-
SubTexture是一个笼统的概念,虽然Texture是跨平台的(需要有OpenGLTexture等类),但它作为一个Wrapper,不需要跨平台(不需要有OpenGLSubTexture等类)
-
在Renderer2D类里添加额外的DrawCall函数,用于支持SubTexture
还需要注意一点,目前的游戏引擎是没有合并Geometry的功能,就目前的2D Renderer来说,暂时是不需要的。因为2D Renderer里一般只会绘制看得见的东西,不会像3D游戏里,需要绘制到很多屏幕看不到的东西(Occlusion)。3D渲染才需要Geometry合并的功能,比如说它会把只看得见的部分合并成一个Mesh,然后把它绘制出来,从而优化性能。
Creating a Map of Tiles
-
如何表示Tiles组成的地图,每个Tile用哪个SubTexture?
-
二维数组优先行遍历还是优先列遍历,哪一种更Cache Friendly一些
C 中的数组按照行优先存储,所以行优先遍历比较好
如何表示Tiles组成的地图
方法其实很多,总之目的是为了表示出地图上用了哪些类型的Tile,以及每个Tile的位置,就目前所用的2D贴图而言,它最小的图形应该是128128像素的,所以19201080(16:9)的屏幕最多也就是15*8.4375个Tile而已。
这里介绍了两种:
-
用字符串表示,字符串里的不同字符用于代表不同类型的Tile
-
用很小的像素图表示场景,一个Tile用一个像素表示,这样地图看起来比较直观,而且是用图片资源存储的,比较方便迭代
Next Steps + Dockspace
参照 imgui_demo.cpp 里的代码,调用对应绘制 Dockspace 的代码。
找到的示例函数是 ShowExampleAppDockSpace,它是在 ShowDemoWindow 里被直接调用的
ImGui::Image 用来在 ImGui 窗口中画图。为了支持跨平台,他接受的纹理 id 是用一个指向纹理 id 的 void* 来实现
Framebuffers
framebuffer 有一个变量 SwapChainTarget,在 Vulkan 中 = false 表示离屏渲染,那么 = false 要在 OpenGL 中表示离屏渲染,就是 glBindFramebuffer(frameBufferIndex); SwapChainTarget = true 表示渲染到屏幕就是 glBindFramebuffer(0);
Render Pass
后续的引擎还会添加Render Pass的概念,Render Pass在OpenGL里更像是一个抽象的概念,但在Vulkan里却是一个实实在在存在的类,它会有一个Framebuffer,和一个target。像上面的RenderToScreen为false的Framebuffer,其实就是一个渲染到屏幕上的Render Pass而已,渲染时的代码大概是:
renderer.BeginRenderPass();
Making a New C++ Project in Hazel
之前在 ImGui 中用一个 framebuffer 的颜色附件作为纹理展示了出来
这就是一个 viewport 的原型,那么这个 ImGui 层就是一个 editor 的原型
创建一个 Editor 工程,把这个 ImGui 层的代码放进来,方便归纳 Editor,和 Engine 与 Sandbox 分开
Scene Viewport
在 ImGui 的 Render 函数中,前面部分是抄的 ImGui 的例子,后面我们用 ImGui::GetContentRegionAvail() 获得 ImGui 窗口的大小,与存储的窗口大小相比,如果不相同,说明 ImGui 窗口的大小发生了变化,那么我们通知 framebuffer 和 camera,触发它们的 OnResize 函数
framebuffer 的 OnResize 函数需要把旧的framebuffer和纹理附件删掉,重新创建framebuffer和纹理附件,绑定
摄像机的 OnResize 函数是重新设置 AspectRatio 和 Proj 矩阵
ImGui 无边框
ImGui::PushStyleVar(ImGuiStyleVar_WindowPadding, ImVec2{ 0, 0 });
使用 glTexImage2D 创建纹理附件,方便更新
当然你也可以不重新创建 FBO 只是重新创建颜色附件和深度附件,使用 glTexImage2D 创建颜色附件和深度附件就好了,如果是 glTexStorage2D 创建的纹理,这种纹理是不可变的
void OpenGLFramebuffer::Invalidate(){glCreateFramebuffers(1, &m_RendererID);glBindFramebuffer(GL_FRAMEBUFFER, m_RendererID);glCreateTextures(GL_TEXTURE_2D, 1, &m_ColorAttachment);glBindTexture(GL_TEXTURE_2D, m_ColorAttachment);glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA8, m_Specification.Width, m_Specification.Height, 0, GL_RGBA, GL_UNSIGNED_BYTE, nullptr);glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, m_ColorAttachment, 0);glCreateTextures(GL_TEXTURE_2D, 1, &m_DepthAttachment);glBindTexture(GL_TEXTURE_2D, m_DepthAttachment);glTexImage2D(GL_TEXTURE_2D, 0, GL_DEPTH_COMPONENT, m_Specification.Width, m_Specification.Height, 0, GL_DEPTH_COMPONENT, GL_FLOAT, nullptr);glFramebufferTexture2D(GL_FRAMEBUFFER, GL_DEPTH_ATTACHMENT, GL_TEXTURE_2D, m_DepthAttachment, 0);//glTexStorage2D(GL_TEXTURE_2D, 1, GL_DEPTH24_STENCIL8, m_Specification.Width, m_Specification.Height);//glFramebufferTexture2D(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_TEXTURE_2D, m_DepthAttachment, 0);HZ_CORE_ASSERT(glCheckFramebufferStatus(GL_FRAMEBUFFER) == GL_FRAMEBUFFER_COMPLETE, "Framebuffer is incomplete!");glBindFramebuffer(GL_FRAMEBUFFER, 0);}void OpenGLFramebuffer::Resize(uint32_t width, uint32_t height){m_Specification.Width = width;m_Specification.Height = height;if (m_RendererID != -1){glBindTexture(GL_TEXTURE_2D, m_ColorAttachment);glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA8, m_Specification.Width, m_Specification.Height, 0, GL_RGBA, GL_UNSIGNED_BYTE, nullptr);glBindTexture(GL_TEXTURE_2D, m_DepthAttachment);glTexImage2D(GL_TEXTURE_2D, 0, GL_DEPTH_COMPONENT, m_Specification.Width, m_Specification.Height, 0, GL_DEPTH_COMPONENT, GL_UNSIGNED_BYTE, nullptr);//glTexStorage2D(GL_TEXTURE_2D, 1, GL_DEPTH24_STENCIL8, m_Specification.Width, m_Specification.Height);}}
写的时候我创建纹理用的是 GL_DEPTH_COMPONENT 的格式,但是绑定的时候我还是用的 GL_DEPTH_STENCIL_ATTACHMENT 所以导致出现了 FBO 不完整的错误……我还一直都不知道为什么,给我心态整的有点小崩hhh
Code Review + ImGui Layer Events
虚析构函数
使用基类指针指向派生类成员,析构的时候,需要基类定义了虚析构函数,才能调用派生类的析构函数
在 Compile Time 决定 Input 的实现
因为我们已经知道了编译平台,所以我们可以决定 Input 只在哪个平台上运行
所以我们的 Input 只需要对每一个平台一个 cpp 实现,然后在编译的时候设置,某个平台编译哪个 cpp 就好了
这就是多态的一种实现方法,这就是这种方法的使用场合,就是多态对于某一个平台是确定的,那么直接在编译的时候确定就好了
另一种多态的实现方法是虚基类继承的方法,这种适用于运行时切换多态中的某一种状态,例如运行时需要切换 OpenGL 或者 DirectX 或者 Vulkan
ImGui 的 IsWindowFocused
它用窗口是否为焦点来判断是否要接受事件,m_ViewportFocused 或 m_ViewportHovered 为假的时候不接受事件,m_ViewportFocused 都 m_ViewportHovered 为真的时候才接受事件
但是这个 m_ViewportFocused m_ViewportHovered 都是要 glfw 窗口被 focuse 的时候才开始判断的(很合理)
void EditorLayer::OnImGuiRender(){m_ViewportFocused = ImGui::IsWindowFocused();m_ViewportHovered = ImGui::IsWindowHovered();//Application::Get().GetImGuiLayer()->BlockEvents(!m_ViewportFocused || !m_ViewportHovered);Application::Get().GetImGuiLayer()->BlockEvents(!m_ViewportFocused);...
然后这个,emmm,其实只是控制 ImGui 的输入事件,然后其实这里写的摄像机的控制是用 glfw 的输入来控制的
所以要达成相同的目的还要这么写……
void EditorLayer::OnUpdate(Hazel::Timestep ts){HZ_PROFILE_FUNCTION();// Updateif (m_ViewportFocused && m_ViewportHovered)m_CameraController.OnUpdate(ts);...
Where to go next + Code Review
ImGui::GetContentRegionAvail() 可能返回负值
这是在最小化 glfw 窗口的时候出现的问题
不知道为啥我没出现这个问题
单独 resize ImGui 窗口时出现的闪烁
原来是这么写的
void EditorLayer::OnImGuiRender(){...ImVec2 viewportPanelSize = ImGui::GetContentRegionAvail();if (m_ViewportSize != *((glm::vec2*)&viewportPanelSize)){m_Framebuffer->Resize((uint32_t)viewportPanelSize.x, (uint32_t)viewportPanelSize.y);m_ViewportSize = { viewportPanelSize.x, viewportPanelSize.y };m_CameraController.OnResize(viewportPanelSize.x, viewportPanelSize.y);}...}
把这个 imgui 窗口从 dockspace 中提取出来,然后单独缩放的话,就会有闪烁黑屏的现象
现在是这么写的,可以修复黑屏
void EditorLayer::OnUpdate(Hazel::Timestep ts){// Resizeif (Hazel::FramebufferSpecification spec = m_Framebuffer->GetSpecification();m_ViewportSize.x > 0.0f && m_ViewportSize.y > 0.0f && // zero sized framebuffer is invalid(spec.Width != m_ViewportSize.x || spec.Height != m_ViewportSize.y)){m_Framebuffer->Resize((uint32_t)m_ViewportSize.x, (uint32_t)m_ViewportSize.y);m_CameraController.OnResize(m_ViewportSize.x, m_ViewportSize.y);}...}void EditorLayer::OnImGuiRender(){ImVec2 viewportPanelSize = ImGui::GetContentRegionAvail();m_ViewportSize = { viewportPanelSize.x, viewportPanelSize.y };...}
就很神奇,他相当于是,在 OnImGuiRender() 中获取到新的 size,保存下来,但是仍然使用旧的 size 的设置(framebuffer,相机参数)来渲染,然后在 OnUpdate() 中完成 resize 的处理(framebuffer,相机参数),然后在下一次的 OnImGuiRender() 渲染上一次的 size
程序主循环是这样的
for (Layer* layer : m_LayerStack)layer->OnUpdate(timestep);m_ImGuiLayer->Begin();
for (Layer* layer : m_LayerStack)layer->OnImGuiRender();
m_ImGuiLayer->End();
神奇的是,如果把 resize 放到 OnImGuiRender() 中,不管是放到获取 size 的前面还是后面,效果都是一样的
所以我们可以知道,起码这个问题,resize 和获取 size 之间的顺序是无关的
但是我们又把 resize 放到 OnUpdate() 中就没有这个问题了,所以是 resize 和 ImGui 的渲染之间有关系
马后炮只能分析到这里了
之后看别人的评论才知道是什么原因
https://github.com/TheCherno/Hazel/pull/268
我们相当于是
-
绑定了一个 framebuffer
-
渲染到这个 framebuffer,然后解绑
-
resize 这个 framebuffer,然后绑定,这个时候 framebuffer 里面是空的
-
绘制
这个时候我们绘制的是一个空的 framebuffer,所以会导致黑屏
这就很合理……即使我的 resize 是直接用 glTexImage2D 重新分配纹理附件完成的,那重新分配也是分配了空的数据指针,效果是一样的
所以说这或许给我长了记性,黑屏闪烁可能是什么原因导致的
不要把重要的最通用的宏定义放到头文件里
它很难被所有cpp引用,即使把它放到pch里,它也只能保证被Hazel引擎内的代码使用,对于引擎使用的第三方库文件,不大可能会include这个Core.h文件。
头文件确实可以理论上可以被所有人引用,但是还可能存在顺序问题,不了解的头文件具体作用的人很容易就出错
更好的方法,是通过premake5.lua把宏定义放到项目的Preprocessing对应的属性栏里,如下图所示:
VertexArray在跨平台的图形API里并不存在
除了OpenGL 其他的渲染API是根本没有VertexArray这个概念 所以VertexArray这个类要大改 因为它不是一个Render跨平台通用的概念
VertezArray其实是用来描述vertex buffer的,其实DX和Vulkan的设计理念更好,就是让vertex layout绑定到shader,而OpenGL里,vertex layout是存在vertex array里,vertex arrray会绑定到context上,跟shader没有绑定关系
Entity Component System
老生常谈,为什么用 ECS
Intro to EnTT (ECS)
介绍了一下 entt 的用法
在引擎中包含整个 entt 路径的原因
如果在引擎中不包含整个 entt 路径,那么引擎使用到了 entt 中的某个函数的模板功能,编译器就只会编译那些模板,而在引擎是编译成 lib 提供给 Editor 和 Game 使用的,Editor 和 Game 就没有办法使用到 entt 那些没有编译的模板
虽然油管主是这么讲的……但是我觉得,把一个库的路径添加到附加包含目录的原因,只是为了能够找到库吧……
虽然我也知道模板是在编译的时候实例化的,但是,嗯,所谓的”添加头文件路径是为了能够获得模板特性“这种说法就很怪
因为首先,你要用 entt 的话,那你就必须要 include entt 的文件,那其实这里,要不报错的话,你要不就是用完整的相对路径,要不就是用附加包含目录,总之这和直接一直添加附加包含目录的作用是一样的……
总之我很混乱
Entities and Components
空结构体
空的结构体在使用的时候会出现问题
比如这里是在 MeshComponent 没有成员的时候出现的问题
我一路看那个输出,他最后我感觉是,从一个 group 中 get,是从一个 storage 中调用 get,然后空结构体没有被编译,所以 get 这个模板在实例化的时候就出错了
但是实际上我们不会使用一个空的结构体,所以这个错误只是一个有趣的……小点?
The ENTITY Class
AddComponent
entt 中的 entity 需要获取到它所在的 registry 才能调用 registry 的 get component
现在我们就创建一个 Entity 类,每一个 Entity 存放一个 Scene 的指针,在构造函数中初始化,Scene 里面有唯一的一个 registry,在 Entity 类创建函数,里面通过指向 scene 的指针获取到 registry 再 get component
这样,我们封装了 entt 的 component 相关的逻辑到 Entity 中,对 Entity 直接调用 get component 就好了,这样我们不需要知道 reg
然后这个 entity 需要知道 scene 用原始指针当然可以,用智能指针也行,智能指针的话不能用 shared ptr 因为我们不希望 entity 的存在会延续 scene 的生命周期,所以我们应该用 weak ptr
Camera Systems
之前他已经写过了一个 OrthographicCamera
现在不知道为什么又写了一个 Camera 类
他应该是为了 ECS 里面的 CameraComponent
我觉得这有点麻烦了说实话
Scene Camera
为 Camera 创建了一个派生类 SceneCamera
然后把 OrthographicCamera 中的一些东西搬到 SceneCamera 中
仍然觉得挺冗余
只是为了配合 CameraComponent 吧
Native Script
创建了一个 NativeScriptComponent,其中有一些 std::function,在主循环中会调用这些 function
还提供了一个 bind 函数,对 function 成员赋值
把 bind 制作成模板类,那么编译器在编译的时候根据输入的 T 的类型去找到 T 的对应的函数
NativeScriptComponent 在初始化的时候会调用 bind,会指定模板类的类型
所以就相当于,我只知道我有一个 NativeScriptComponent,假设我不知道这个组件是怎么初始化的,我就单单调用这个组件里面存好的 function 就好了
估计这就是他调用 Script 的想法……?就是 Script 在初始化的时候从 Script 中取出函数放到 function 成员中
只是这里的例子有点怪,就是 function 里面存的都是 C++ 里面写好的类的成员函数而不是脚本中的函数
应该只是为了演示这个思路才这么做的把
Native Script with virtual function
这个代码变得更奇怪了
NativeScriptComponent 中有一个函数模板 Bind,组件存了两个函数指针,一个是初始化一个是销毁,Bind 中会接收到一个模板类型 T,初始化函数中,他会创建一个 T 类型的对象,然后转换到 ScriptableEntity 类,存为 instance,销毁函数中删除 instance
instance 是 ScriptableEntity 类,这个类里面有虚函数 OnCreate OnUpdate 等提供给外部
所以相当于,在场景初始化的时候,为某个 entity 加上 NativeScriptComponent,然后调用 NativeScriptComponent 的 Bind 函数,其中要制定 ScriptableEntity 类的某个派生类
然后在主循环中,假设我不知道是怎么初始化的,我就去找有 NativeScriptComponent 的 Entity,找到 NativeScriptComponent,然后从 NativeScriptComponent 中获取 ScriptableEntity 类的 instance,然后调用 ScriptableEntity 类的虚函数接口
emmmm感觉有点怪
感觉不像 Script
Scene Hierarchy Panel
获取到所有 entity,对每一个 entity 用 ImGui::TreeNodeEx 画一遍
因为我们在绘制 ImGui 的 TreeNode 的时候知道我们是对哪个 Entity 画的,所以我们在画的时候就可以查询一下这个节点是不是被点击了,如果被点击了,那么就可以告知其他系统,当前 UI 上选中的是哪个 Entity
他是用 ImGui::IsItemClicked() 来判断的,就很神奇,因为他这里查的时候没有指定查的是哪个节点嘛,所以我觉得这种写法似乎跟 OpenGL 有点像,都是相当于对状态机查?比如说我在画这个节点的时候,之后我的操作都默认是对这个节点进行的?我不太懂,没有学过 ImGui
Properties Panel
类似,略
Camera Component UI
类似,略
Drawing Component UI
类似,略
Transform Component UI
用矩阵存储Rotation数据是不准确的,因为比如我有个绕Z轴旋转7000°的Rotation,用矩阵去存储和运算就会存成0到360°范围的值,所以这里用Yaml这种文本文件来存储GameObject的Transform(跟Unity一样)
修改Transform组件,数据从mat4改成三个向量:translation、rotation和scale,它这里的旋转还是用欧拉角表示的,还没用到四元数(因为目前的2DRenderer只会有绕Z轴的旋转,不会有Gimbal Lock)。然后修改相应的使用代码和Inspector代码
这里画 Transform 的方式让我学到了一点 ImGui 画东西的方式……总之就是默认直接往下画,如果要加新格式就声明,然后就按照这个格式来,这个格式结束之后就是按照默认的来堆……哎呀我也说不好,但是总之是很简单的堆堆堆,只是堆 UI 之前声明 UI 的堆的格式
Adding/Removing Entities and Components UI
类似
Making the Hazelnut Editor Look Good
设置了字体,颜色样式
在 ImGui 各个按钮绘制之间设置了间隔
把 DrawComponent 中的 ImGui 的一些通用的绘制样式做成模板,传入 lambda 来绘制每一个 Component 独特的部分
Saving and Loading Scenes
可以用JSON来存储场景,但是这种格式在merge的时候,没有Yaml格式好,而且JSON文件很容易写漏掉{}。
yaml-cpp 的用法看一下代码里面是怎么写的就理解了
Open/Save File Dialogs
通过 Windows API,出现出搜寻文件的创建,可以加载指定路径的 .scene 文件,将其反序列化得到 Scene 对象
保存文件同理
Transformation Gizmos
ImGuizmo 的使用方法
传入 Manipulate 的是 view 和 proj 矩阵,还有物体的 transform
通过 gizmos 操作之后的值会存到传入的 transform 对象中,从这个对象中 decompose 出位移,旋转,缩放赋回物体
Editor Camera
把原本用作EditorCamera的OrthographicCamera和OrthographicCameraController重命名为EditorCamera和EditorCameraController类
并完善EditorCamera类,专门负责Viewport的绘制,EditorCamera不再是原本的Orthographic Camera,而是支持两种模式,而且默认为透视投影
添加快捷键,让EditorCamera在Viewport里移动、旋转
神秘二次函数,在图像论坛上获取的,用于根据Viewport窗口大小,调整合适的Pan Speed,就是用中键来调整Viewport缩放
Multiple Render Targets
现在我们要实现一个鼠标点击场景,能够获取到点击到的物体的功能
其实我觉得可以用射线来做,但是应该是因为在复杂物体的情况下射线是不准确的吧
比如如果一个物体比较小很难用射线判断到相交,或者被一个透明材质的物体挡住,或者……
然后第二个方法就是把 Entity ID 渲染到场景中,跟渲染颜色是一样的,只是没有 alpha test 和 alpha 混合这样……
然后我们再输入鼠标在视口中的位置,然后用这个视口位置来从贴图中查询值,读取像素信息用 glReadPixel
既然我们 Entity ID 渲染到场景中跟渲染颜色是一样的利用深度的,所以我们可以在一个 shader 里面同时完成这两件事
但是一般的 shader 的输出只有一个 frag color
这个时候就需要用到 MRT 技术,其实就是,一个 framebuffer 可以绑定多个颜色附件,但只有一个深度附件。创建颜色附件的时候,创建到 GL_COLOR_ATTACHMENT0 + index,然后 frag shader 中写 layout(location = 0) out vec4 fragColor0; layout(location = 1) out vec4 fragColor1; … 然后使用 glDrawBuffers 传入一个以 GL_COLOR_ATTACHMENT0 为基的数据,告诉 opengl 哪一个 layout location = index out 对应哪一个 GL_COLOR_ATTACHMENT0 + index
然后他这里就是,在创建 framebuffer 创建颜色附件和深度附件的时候,额外多写了 MRT 的逻辑
然后他还添加了一个,多重采样的设置
为鼠标点选准备 FBO
在创建纹理的时候提供一个 RED_INTEGER 的选项
在 frag shader 中设置 layout location = 2 out
他这个计算鼠标在视口中的 0 到 1 的坐标的做法可能需要看一下
主要是,某一个 imgui 的窗口的边界的确定就很神奇
调用的是 getcursorpos 得到的却是 viewposoffset,调用的是 getwindowspos 得到的是 minbound
左上角是 0,0 右下角是 bound
对 y 取 bound.y-y 使得 y 轴反过来,左下角是 0,0 右上角是 bound,与 opengl 的视口坐标系的方向相符
之后在 commit 7d0ccc4077adaeea53b5ad23a78ffa0849319062 中把获取视口左下角坐标的函数改了,改成了 GetWindowContentRegionMin(); 获取左下角,GetWindowContentRegionMax(); 获取右上角
清理 FBO 的颜色附件
添加了一个清理 FBO 的颜色附件的函数
鼠标点选 Mouse Picking
如何在绘制物体的时候,在Fragment Shader里知道物体的ID,有两种直观思路:
-
通过Vertex Shader传入
-
通过Uniform传入
对于现在的情况,第二种方法是不行的,因为我们现在是批处理了,在一个 drawcall 里面绘制属于不同物体的面,所以我们如果传 uniform 的话,就会对于不同物体得到相同的一个 uniform
所以还是要通过顶点属性传入
而这个顶点属性的传入需要我们在代码中定义一个包含 entity id 的结构体,但是实际上在游戏中我们不需要顶点属性包含 entity id,我们只在编辑器中需要,所以这个结构体中的 entity id 只在编辑器环境下存在
ok,现在实现了绘制的时候要传入 entity id 到顶点属性,配合之前做好的 MRT,readpixel,鼠标点选就完成了
Clicking to Select Entities
我们在每帧可以获取到鼠标位置,用 readpixel 获得 id 纹理上的 id,保存到 hovered_entity 中
添加一个事件,在鼠标点击时将 selected_entity 设置为 hovered_entity
SPIR-V and the New Shader System
在引擎里只写一份Shader,但是该Shader能跑在不同的平台上,其实也就是引擎的Shader跨平台编译系统,更具体来说,目前是想让写的OpenGL的shader,能够跑在vulkan上
实现Shader的缓存,相当于编译出Shader在各个平台上的Binary文件,然后利用类似glGetProgramBinary去直接上传Shader,从而省去Runtime编译Shader的过程
具体分为以下步骤:
-
介绍SPIR-V (可以把shader翻译为跨平台中间语言的编译器)
-
介绍github上的shaderc项目(可以理解为封装了SPIR-V的github项目)
-
介绍Vulkan SDK,以及脚本一键安装Vulkan SDK环境
-
接入shaderc项目到Hazel里
-
修改现有的Shader文件,以支持vulkan
-
Tip: Vulkan里的depth范围是[-1, 1],而OpenGL是[0, 1]
-
给调用的exe添加命令行参数
UniformBuffer
uniform 本质上是告诉 GPU 在这次着色程序渲染的时候创建一个缓冲区
所以 uniform 可以视为 Shader 之外的一个,但是配合 Shader 的东西
所以可以把 uniform 的设置抽象出来
这里就是创建了一个 UniformBuffer 基类
OpenGL 的派生类里面是 UBO 的内容
这么一看我才记起来 OpenGL 确实有 UBO,怪不得他要提这个抽象
SPIR-V and the New Shader System
SPIR-V
SPIR-V是一个Shader的编译器,它会把Shader编译为intermediate byte code。全称叫Standard Portable Intermediate Representation,是一种跨平台的中间语言。
实际使用的时候,比如我有一个vulkan用的shader,语法是glsl,那么怎么在OpenGL上用呢,具体步骤如下:
可以通过SPIR-V,把它编译为Binary文件。基于这个文件,通过SPIR-V的跨平台编译器,返回一个string,此时就是对应的OpenGL版本的shader(也是个文本文件),然后这个 string 当然可以直接通过OpenGL来编译,但也可以基于这个文件,通过SPIR-V的跨平台编译器,获取OpenGL版本的shader编译得到的binary文件,可以把它存到磁盘上,用的时候通过glGetProgramBinary类似的代码读取Shader。
SPIR-V对各个平台的shader转换的流程图
https://www.khronos.org/spir/

GLSL->glslang->SPIR-V Tools
Vulkan SDK
需要的 lib 可见仓库的 premake 的 lua 文件
可以直接下载 Vulkan SDK,打开 installer.exe 下载的时候勾选 Debug 工具,然后把 premake 的 lua 文件中的 Vulkan SDK Debug 路径改为环境变量的 Vulkan SDK 的路径,因为油管主想要的是,sdk 去环境变量找,debug 相关的 lib 下载到自己的库,但是现在我们直接下载都一起了,所以一起到环境变量找就行了
Uniform 的写法
OpenGL 中 Uniform Struct 的写法:
struct Transform{mat4 Transform;
}uniform Transform u_RendererUniforms;
但是 Vulkan 不会识别到
他说是不会识别到反射,emmm,这算反射吗,不懂
Vulkan 的写法是
layout(push_constant) uniform Transform{mat4 Transform;
}u_RendererUniforms;
在 Shader 中使用预编译头
可能我们需要在 Shader 中使用预编译头,来处理不同平台上的不同行为
例如 OpenGL 和 Vulkan 的深度范围是不一样的,前者是 -1 到 1后者是 0 到 1
float value = 0;
#if OpenGLvalue = value * 0.5 + 0.5
#endif
XXX 已在 XXX.obj 中重新定义
一开始我拉取了 commit 之后,构建出现了一堆“XXX 已在 XXX.obj 中重新定义”的错误
我看了一下输出,应该是运行时库的错误
yaml-cpp.lib(stream.obj) : error LNK2038: 检测到“RuntimeLibrary”的不匹配项: 值“MTd_StaticDebug”不匹配值“MDd_DynamicDebug”(EditorLayer.obj 中)
于是我把 Editor 和 Engine 的运行时库都改成 Mtd
结果还是有错
2>Hazel.lib(spirv_cross.obj) : error LNK2038: 检测到“RuntimeLibrary”的不匹配项: 值“MDd_DynamicDebug”不匹配值“MTd_StaticDebug”(EditorLayer.obj 中)
2>Hazel.lib(spirv_cross.obj) : warning LNK4099: 未找到 PDB“”(使用“Hazel.lib(spirv_cross.obj)”或在“”中寻找);正在链接对象,如同没有调试信息一样
2>Hazel.lib(spirv_glsl.obj) : error LNK2038: 检测到“RuntimeLibrary”的不匹配项: 值“MDd_DynamicDebug”不匹配值“MTd_StaticDebug”(EditorLayer.obj 中)
2>Hazel.lib(spirv_glsl.obj) : warning LNK4099: 未找到 PDB“”(使用“Hazel.lib(spirv_glsl.obj)”或在“”中寻找);正在链接对象,如同没有调试信息一样
2>Hazel.lib(spirv_cfg.obj) : error LNK2038: 检测到“RuntimeLibrary”的不匹配项: 值“MDd_DynamicDebug”不匹配值“MTd_StaticDebug”(EditorLayer.obj 中)
2>Hazel.lib(spirv_cfg.obj) : warning LNK4099: 未找到 PDB“”(使用“Hazel.lib(spirv_cfg.obj)”或在“”中寻找);正在链接对象,如同没有调试信息一样
2>Hazel.lib(spirv_cross_parsed_ir.obj) : error LNK2038: 检测到“RuntimeLibrary”的不匹配项: 值“MDd_DynamicDebug”不匹配值“MTd_StaticDebug”(EditorLayer.obj 中)
2>Hazel.lib(spirv_cross_parsed_ir.obj) : warning LNK4099: 未找到 PDB“”(使用“Hazel.lib(spirv_cross_parsed_ir.obj)”或在“”中寻找);正在链接对象,如同没有调试信息一样
2>Hazel.lib(spirv_parser.obj) : error LNK2038: 检测到“RuntimeLibrary”的不匹配项: 值“MDd_DynamicDebug”不匹配值“MTd_StaticDebug”(EditorLayer.obj 中)
2>Hazel.lib(spirv_parser.obj) : warning LNK4099: 未找到 PDB“”(使用“Hazel.lib(spirv_parser.obj)”或在“”中寻找);正在链接对象,如同没有调试信息一样
所以似乎是 vulkan 的 lib 要求我用 /MDd,但是 yaml-cpp 要求我用 /MTd
之后我觉得,嗯,这个运行时库的设置,不是用来链接别人的吗,那么 yaml-cpp 没有链接到别人啊,所以它的运行时库的设置应该跟着别人来吧
所以我就把 Editor Engine yaml-cpp 的运行时库的设置都改成了 /MDd 就好了
代码中调用 shaderc 编译 glsl 到 spirv
需要创建 shaderc 的 Compiler 和 CompileOptions 对象
shaderc::Compiler compiler;
shaderc::CompileOptions options;
options 中设置了要编译到 Vulkan
如果shader代码中用了宏定义,那么这里还可以写 options.AddMacroDefinition("OpenGL");
编译的话就用到 compiler.CompileGlslToSpv
shaderc::SpvCompilationResult module = compiler.CompileGlslToSpv(source, Utils::GLShaderStageToShaderC(stage), m_FilePath.c_str(), options);
存储也是根据 enum 值来存
shaderData[stage] = std::vector<uint32_t>(module.cbegin(), module.cend());
同时用 ofstream 输出到文件
spirv 编译到 glsl
需要创建 shaderc 的 Compiler 和 CompileOptions 对象
shaderc::Compiler compiler;
shaderc::CompileOptions options;
options 中设置了要编译到 OpenGL
现在我们经过之间的步骤,得到的是 vulkan 的 shader 的二进制文件,现在我们要利用它,得到 opengl 的 shader 的二进制文件
(确实我们是用 glsl 文件得到的 vulkan 的 shader 的二进制文件,那为什么不直接用 glsl 一步到位到 opengl 的 shader 的二进制文件……?可能是因为油管主想演示这整个流程吧)
这里一开始我还有点懵,因为我因为 spirv 只是 vulkan 需要的着色器的二进制形式
现在我才明白,原来 spirv 在 options 里面设置哪个平台,得到的就是哪个平台的着色器的二进制数据
那么现在我们有 vulkan 的 shader 的二进制数据 m_VulkanSPIRV 我们想要 opengl 的 shader 的二进制数据 m_OpenGLSPIRV
但是 spirv 没有直接在两个平台的二进制数据之间转换的功能
所以我们需要用 spirv_cross 将 m_VulkanSPIRV 转换到 glsl 源码,然后将得到的源码输入 spirv 生成 m_OpenGLSPIRV
spirv_cross 的使用也很简单
spirv_cross::CompilerGLSL glslCompiler(spirv);
m_OpenGLSourceCode[stage] = glslCompiler.compile();
之后将得到的源码输入 spirv 生成 m_OpenGLSPIRV 就是前面我们已经做过类似的了
从编译得到的 spirv 数据中获取 shader 信息
spirv_cross 除了把 spirv 文件转化成源码之外,还有一个功能是可以获得源码的数据
将 spirv 的二进制文件输入 spirv_cross 之后,编译成源码,spirv_cross 就可以根据这个源码获得到 shader 的一些信息
这应该算反射把……
比如 uniform buffers 有多少啊之类的
在 OpenGL 加载 spirv 二进制数据
直接用 glShaderBinary 和 glSpecializeShader 替换 glShaderSource 和 glCompileShader
其他问题
现在的逻辑是,一旦有了二进制 shader 文件,就直接读取了,但是你不知道这个二进制文件是不是从当前源 shader 编译来的
就是说可能出现版本不一致的问题
果然还是需要 meta
内容浏览器 Content Browser/Asset Panel
层级显示
点击按钮,修改路径 string
Content Browser Panel - ImGui Drag Drop
显示图标
在这之前实现了图标显示
要考虑到图标的大小,图标之间的间隔
因此需要获取到窗口的宽度,除以单元格的宽度,得到每一行能够显示的图标数量
单元格的宽度等于图标大小 + 图标之间的间隔
从之前的判断按钮是否点击 if (ImGui::Button("<-"))
变为判断图片是否被点击 if (ImGui::IsItemHovered() && ImGui::IsMouseDoubleClicked(ImGuiMouseButton_Left))
其他的没啥了
显示图片按钮之前要先清理颜色,不然虽然用的是透明图片,但还是有默认底色
ImGui::PushStyleColor(ImGuiCol_Button, ImVec4(0, 0, 0, 0));
ImGui::ImageButton((ImTextureID)icon->GetRendererID(), { thumbnailSize, thumbnailSize }, { 0, 1 }, { 1, 0 });
ImGui::PopStyleColor();
鼠标拖拽
在显示 ImageButton 的时候,调用 if (ImGui::BeginDragDropSource())
这个时候我理解的是,如果鼠标点击了就会触发
那么这个时候要设置 payload 给 imgui,就是鼠标点击时的信息,比如点击到的项目所代表的相对路径
然后在别的地方应该调用 if (ImGui::BeginDragDropTarget())
这个时候是,如果鼠标松开了就会触发
其中添加一个获得 payload 的逻辑
这个时候就获得了 content 的相对路径,进而获得资源的完整路径,可以打开了
这里想要鼠标拖拽到 viewport,所以我们在显示 viewport 的 begin 和 end 之间加入这个接受 payload 的代码
Texture for Entities
经过之间鼠标拖拽到 viewport 的操作
现在我们希望鼠标拖拽到组件属性中的一个地方就能设置纹理
同样的写法,只是在属性栏显示属性的时候加入接受 payload 的代码
Everything You Need in a 2D Game Engine
2D游戏里经常用到Sprite Sheets,因为GPU往往只能一次性绑定32个通道的Texture,不过这种把多个贴图合为一个大贴图的方法,不只是用于Sprite Sheets,比如一个点光源、甚至多个点光源、周围六个方向的Shadow Map,都可以合并存到一个贴图上。甚至2D游戏里的动画都是Sprite Sheets实现的
目前的Hazel引擎,作为2D的游戏引擎,还缺少的功能有:
Animation系统:用Sprite Sheets即可实现,毕竟2D游戏的动画不会需要分辨率特别高的贴图
Shader和材质系统:2D游戏里,由于万物都是贴图,其实Material和Shader在2D游戏里并不是特别重要,但少数情况还是会用到,比如给角色周边添加彩色光照的buff效果
后处理系统:比如添加bloom、color grading等效果,实现HDR Rendering
Scrpting: C#与C++交互的脚本系统
可视化编程系统
Reflection系统:这个系统可以帮助在Inspector上直接调整Property的值,也可以实现Serialization(暂时不太懂为什么可以这么做),当在编辑器里更改数据的值时(比如从5变为6),C#相关的Assembly不需要重新编译即可改变内存里对应的值。通过反射也可以实现Assembly的加载、卸载和reload,毕竟点击Play按钮进入PlayMode时,是需要Reload C#的Assembly的
2D的物理引擎
Callbacks系统
2D Particle System:会使用到类似VFX graph(a node based editor used to define the flow of particles and how they react to things)的东西,碰撞,纹理,CPU compute
Editor相关的工具:比如UNDO/REDO系统
UI相关:比如Text Rendering,可能需要使用signed distance field;还有algnment、类似css之类的东西。UI Animation等
Memory Mapping:可以用于帮助上传很大的贴图(比如500mb的贴图)到GPU
本地化
stripping 代码剥离 删除未使用或无法访问的代码 例如将 Editor 代码从发布的游戏中剥离
联网
音频
运行时:在 Editor 中运行游戏
优化:多线程,GPU,性能检测,内存管理
PLAY BUTTON
顶点数组会被插值的 bug
Shader里的TextureId应该用uniform以flat形式传输,用顶点数组数据的形式会被interpolate
绘制顺序问题导致的 bug
在绘制透明物体的时候,如果先绘制前面的透明物体,那么前面的透明物体就会先写入 depth,后面的透明物体的 depth 没有通过,所以不会被绘制,那么自然不会进入 alpha blend,那么就会出现前面的透明物体完全挡住了后面的透明物体的 bug
游戏模式
Viewport窗口上面绘制了Toolbar一栏,里面绘制了Play Button
代码的EditorLayer里,存两种Scene对应的PlayMode的状态,Editor和Play状态
Scene里的Update函数分为EditorUpdate和RuntimeUpdate函数
窗口的 dock space 消失
我不知道源码为什么会让 docking space 消失……我觉得是有什么函数调用的时候隐藏了,然后写到了布局文件中
因为我删了他的一些代码之后,就能显示那个小三角形了
然后我再恢复成源码,小三角形也没有消失
这个 ImGui 的 docking space 分支果然还是有点问题
2D PHYSICS
显示文件 include 了哪个头文件
可以显示 cpp include 了哪些头文件
需要在Visual Studio里,选中cpp文件,然后右键点击属性,在里面的C+±>Advanced->Show Includes改为Yes,然后直接编译该cpp即可(Visual Studio里使用Ctrl + F7可以单独编译一个cpp)
Box2D
使用 Box2D 进行物理模拟
在游戏开始的时候,遍历 RigidBodyComponent,在物理世界中创建 body
如果该 entity 还有 Collider2DComponent,就配置 b2FixtureDef
在程序主循环的时候调用物理世界的 update,然后遍历包含 TransformComponent 和 RigidBodyComponent 的 entity,从 RigidBodyComponent 中获取变换赋给 TransformComponent
Universally Unique Identifiers (UUID/GUID)
创建了全局唯一 ID 组件
组件……也行把,这或许不是需要展示出来的东西?
或者说,我觉得这更像是管理资源文件要用到的东西,而不是游戏物体中需要的东西……
Playing and Stopping Scenes (and Resetting)
他是在切换到播放模式 OnScenePlay 的时候从 m_EditorScene 复制一份场景到 m_ActiveScene
结束播放模式的时候,m_ActiveScene 重新赋为 m_EditorScene,那么旧的 m_ActiveScene 指向的运行时内容就释放掉了
评论中有人说,可以不用这么复制,而是正常结束播放模式,然后在结束播放模式的时候将场景文件重新反序列化回场景
emmmm,我觉得这也可以,但是万一在播放模式的时候用户又把场景文件删除了,那岂不是永远得不到开始时的场景了
所以还是在内存中一直存着 m_EditorScene 比较合理
Rendering Circles in a Game Engine
添加了一个画圆的功能
配套的有shader,批处理提交部分,要存储批处理的 VAO VBO,组件定义,序列化与反序列化中的新增部分,主循环中处理画圆组件的逻辑……
我其实就觉得这些函数定义,有点冗余……
Rendering Lines in a Game Engine
同上
Circle Physics Colliders
添加一个 Component 的流程……感觉很多都是重复的
感觉可以用反射生成代码来实现……?
Visualizing Physics Colliders
在 OnUpdate 中加一个逻辑,找所有的长方形的 collider,绘制长方形,找所有的圆形的 collider,绘制圆形
emmm我在这里,突然发现这个 EditorLayer 没有调用 Renderer2D 的 BeginScene
然后之后才发现,在 Scene 里面是完整地调用了 BeginScene 和 EndScene 但是在 EditorLayer 的 OnUpdate 里面只有 EndScene
其实 EndScene 就是一次提交
所以就,嗯,我感觉这个设计有点反直觉
Return of the Game Engine Series
Physics Simulation Mode
多做了一个物理模拟的模式
runtime 模式中,会 update script,模拟物理;物理模拟模式中,只会模拟物理
两个模式的不同就在于渲染2D时用的摄像机可能不同,runtime 用的是 scene 中的相机,物理模拟用的是 editor 中的相机
Community Issues/PRs and Merging Branches
使用可变参数模板来完成重复性的工作
他这个写法还挺有意思的
template<typename... Component>
static void CopyComponent(entt::registry& dst, entt::registry& src, const std::unordered_map<UUID, entt::entity>& enttMap)
{([&](){auto view = src.view<Component>();for (auto srcEntity : view){entt::entity dstEntity = enttMap.at(src.get<IDComponent>(srcEntity).ID);auto& srcComponent = src.get<Component>(srcEntity);dst.emplace_or_replace<Component>(dstEntity, srcComponent);}}(), ...);
}
这里用了一个逗号表达式来展开可变参数
那么逗号表达式的第一个表达式是一个生命周期仅存在于逗号表达式的 lambda
还有这种利用可变参数列表把所有类型包起来的写法,我也是第一次见,很优雅:
template<typename... Component>
struct ComponentGroup
{
};using AllComponents = ComponentGroup<TransformComponent, SpriteRendererComponent,CircleRendererComponent, CameraComponent, NativeScriptComponent,Rigidbody2DComponent, BoxCollider2DComponent, CircleCollider2DComponent>;
Vulkan1.3
Vulkan1.3 的下载,Debug 库是和 SDK 一起下载的,所以不用引擎自己下载的
终于不用我每次拉取的时候都手动把 Dependencies 里面的 VulkanSDK Debug 等等修改了
GLFW 只调用 GLFW_PRESS RELEASE
GLFW 只调用 GLFW_PRESS RELEASE
GL_REPEAT 是在回调函数中的……
有点没懂
将从属性面板添加组件的函数替换成函数模板
调整 include 的顺序
将引擎内的头文件放在最前面
摄像机接受事件的需要播放模式的条件
Editor 在运行的时候有多个摄像机,每个摄像机用于不同的模式,摄像机接受事件需要处于特定模式
类型的 size 为 0 时 asset
我很好奇什么类型的 size 会为 0
我记得空结构的 size 至少为 1 才对
在程序主循环中少使用一些函数
https://github.com/TheCherno/Hazel/pull/539
他把 std::filesystem::relative 放到了点击事件中
这样就不用每一个循环中都使用一次这个函数
噢……涉及到 OnImGuiRender 的这种 Update 函数确实要小心
鼠标选择穿过透明物体
在 editor 渲染的 shader 中 discard 透明物体的像素,就不会写入,这样,id framebuffer 也不会写入透明物体的 id
定义某一个类的 hash 模板的特化
stl 里面的 unordered_map 底层是用哈希实现的,所以如果要用自定义类型作为 key,需要对这个自定义类型实现哈希定义
首先在这个自定义类型的 cpp 文件里面声明一下 hash,然后写一个特化,hash 结构体里面有一个括号运算符重载,这样,hash 这个结构体就可以在 stl 中直接被使用
namespace std {template <typename T> struct hash;template<>struct hash<Hazel::UUID>{std::size_t operator()(const Hazel::UUID& uuid) const{return (uint64_t)uuid;}};}
添加 C#
获取 Mono 文件
添加 C# 到游戏引擎中的教程:
https://nilssondev.com/mono-guide/book/introduction.html
JetBrain DotPeek 可以查看 .NET 的 DLL 中包含的代码
https://www.jetbrains.com/decompiler/
下载 Mono
https://www.mono-project.com/download/stable/#download-win
这里获得的是 Mono 要用到的 .NET的库文件
Mono 仓库:
https://www.mono-project.com/download/stable/#download-win
在 Windows 上从源码构建 Mono:
-
克隆 mono
-
git checkout 到最近一次 Release 的 commit
-
打开克隆下来的 mono 源码中的 msvc 文件夹中的 sln
可以看到这个解决方案中有很多项目
https://nilssondev.com/mono-guide/book/introduction/building-mono.html 中并没有说我们要构建哪个项目
于是我们可以自己打开项目的属性页,看常规属性-目标文件名,打开编辑,其中有完整构建名的预览
可以看到 libmono-static 的构建的目标文件是 libmono-static-sgen,同理我们也可以这么看 libmono-dynamic
虽然 https://nilssondev.com/mono-guide/book/introduction/necessary-files.html 中说我们最需要的可能只是 mono-2.0-sgen.lib,但是我们现在知道,libmono-static 是构建成 lib,libmono-dynamic 是构建成 dll,这两个的区别仅此而已
所以如果我们要静态链接到 C#,就用 libmono-static-sgen.lib 就好了
-
编译 libmono-static 项目
要选中 libmono-static 项目,然后按 Ctrl + Shift + B 编译,这样编译出来,会在 msvc 中产生 build 文件夹,里面放目标文件,还会一起产生一个 include 文件夹,里面放构建相关的头文件
单纯右键点击项目然后点编译不会产生这个 include 文件夹,我也很奇怪为什么网上搜不到相关的描述……
Debug 和 Release 都构建一遍,方便我们自己的 Debug 和 Release 项目构建
之后提到了,编译 static 项目可能需要定义某些预编译头,当然这和在 vs 中编译是一样的
于是我们可以去看看 libmono-static 项目中的预编译头……但是 libmono-static 项目是没有源文件的,所以它不会被识别为一个 cpp 项目,所以在项目属性中不会显示 cpp 相关的属性……emmm
所以这就很神奇,我还挺想知道,一个库没有源文件,那么编译它的时候到底是在编译什么
-
在游戏引擎的项目的放第三方库的目录中新建一个文件夹 mono,拷贝进去编译产生的 include 文件夹,在里面创建一个 lib 文件夹,拷贝进去编译产生的 build/sgen/x64/lib 中的内容(应该包含 Debug 和 Release)
链接到 Mono
更改 premake 文件,添加 includeDir libraryDir
在需要使用到 Mono 的项目的 premake lua 文件中添加 link
初始化 Mono
点开 Mono 下载的库文件,一般是下载到 C 盘,我们在要用到 C# 的项目的 vxproj 根目录下创建 mono/lib,把 C:\Program Files\Mono\lib\mono\4.5 这个文件夹拷贝进去
那么我们在初始化 Mono 的代码中可以写
mono_set_assemblies_path("mono/lib");
相关的教程可见 https://nilssondev.com/mono-guide/book/first-steps/runtime-setup.html
然后是初始化 JIT,这个指针是要存储的
MonoDomain* rootDomain = mono_jit_init("MyScriptRuntime");if (rootDomain == nullptr)
{// Maybe log some error herereturn;
}// Store the root domain pointer
s_RootDomain = rootDomain;
C# 会先通过编译器转换为 MSIL
JIT 在运行时按需将 MSIL 转换为机器语言。第一次用到某个方法的时候转换为机器语言,存在内存的某个地方 stub(存根)(是指针吗……?),之后再次调用这个方法的时候就直接取存根
托管执行的过程:
https://learn.microsoft.com/en-us/dotnet/standard/managed-execution-process
然后是创建应用域……就不再死复制教程了
应用域:
https://learn.microsoft.com/en-us/dotnet/framework/app-domains/application-domains
感觉像一个独立的沙盒
创建一个 C# 类库
我们的目标是创建一个 C# 的程序集,它里面包含着游戏引擎相关的代码,提供给 C# 的应用域使用
那么这个游戏引擎的 C# 程序集就是需要我们创建一个 C# 类库的项目,编译出来 dll,然后调用 LoadCSharpAssembly
这个函数的内容可以看教程
实际拉取的 Hazel 代码中,我觉得可能要先编译这个类库,然后再编译整个解决方案
也就是说 Hazel 依赖于 Hazel-ScriptCore
所以我觉得这位博主说的依赖关系可能是错的……?
https://blog.csdn.net/alexhu2010q/article/details/126960468
反正我要是不这么做的话,编译整个解决方案的时候,编译 Engine 项目的时候还没有编辑 C# 类库,所以还没有输出程序集 dll,就会报错
感觉 premake 应该存在那种控制编译顺序的功能吧……一下子没找到,之后再说吧
之后编译的时候会出现一些找不到 Windows 的库的问题,我们需要链接到一些 Windows 的库
在 Dependencies.lua 中定义一些 Windows 的 lib 然后在引擎中 link
具体可以看仓库
ScriptEngine.cpp 定义的静态变量 static ScriptEngineData* s_Data 在 Visual Studio 的监视面板中会被识别为 Renderer2D.cpp静态变量 static Renderer2DData s_Data
这就很神奇,应该是 Visual Studio 中的一个错误吧
我自己写的时候避免这个全局变量重名的情况就好了
实际上静态变量的作用域是编译模块,这两个 cpp 不相关所以它们不是一个东西
测试程序集加载
https://nilssondev.com/mono-guide/book/first-steps/testing-assembly-loading.html
从程序集获取 MonoImage,从 MonoImage 获取类型定义表 MonoTableInfo
整个表每一行代表一个类型,列方向上存了类型有关的信息
嗯……就很神奇
我原本以为这个 col 是存数据的,结果我一看 MONO_TYPEDEF_SIZE 居然是 enum,那实际上 col 这个数组的大小只有六个……?用一个 uint32_t 来存数据……?很强
然后之后的 MONO_TYPEDEF_NAMESPACE 也是同一套 enum,就很强
在 C++ 端获取 C# 的类,实例化 C# 的类,调用 C# 类的方法
教程已经很清楚了
https://nilssondev.com/mono-guide/book/first-steps/classes.html
https://nilssondev.com/mono-guide/book/first-steps/methods.html
Calling C++ from C#
前面的部分实现了在C++调用C#里的任何内容,包括调用Method和获取Property和Field等,现在需要反过来,实现在C#里调用C++提供的API。其实有很多可选的做法:
-
使用Platform Invoke (P/Invoke),
这种做法更适合C#工程去使用C++的dll时使用,我之前工作时就是用Unity去通过这种方式,调用寻路导航插件的dll的
-
借助Mono的Internal Call
-
C++和C#的中间语言:C++/CLI,EA的寒霜引擎就是用的C#作为编辑器,C++作为Runtime,它们使用C++/CLI进行交互,不过这玩意儿是只支持Windows的
P Invoke
https://mark-borg.github.io/blog/2017/interop/
cpp 中对函数声明 __declspec(dllexport)
//----- ImageHandler.h -------
#pragma once#ifdef IMAGEHANDLER_EXPORTS
# define IMAGEHANDLER_API __declspec(dllexport)
#else
# define IMAGEHANDLER_API __declspec(dllimport)
#endifextern "C" IMAGEHANDLER_API float ValidateImageColourInterop(char**& inputParams, int* numInputParams, char**& outputParams, int* numOutputParams);
extern "C" IMAGEHANDLER_API float ValidateImageResolutionInterop(char**& inputParams, int* numInputParams, char**& outputParams, int* numOutputParams);
在 C# 中声明函数,使用 DllImport 标签
using System;
using System.Runtime.InteropServices;public class ColourValidator
{[DllImport("ImageHandler", CallingConvention = CallingConvention.Cdecl, CharSet = CharSet.Ansi)]static extern int ValidateImageColourInterop(ref IntPtr inParams, ref int inParamsSize, ref IntPtr outParams, ref int outParamsSize);public bool Validate(){// ...int rc = ValidateImageColourInterop(ref inputParamsRoot, ref inputParamsSize, ref outParamsRoot, ref outParamsSize);// ...}
}
Internal Call
目前的Scripting系统,对应的.NET和Assembly的代码,其实是Hazel的一部分,所以并不适合用P/Invoke(而且Hazel引擎目前是用的static linking)。这里的Internal Call,相当于告诉.NET Runtime,我有一些Native Functions你可以调用。
cpp 里面的函数中的参数要设置成 C# 的类型,定义了函数之后要使用 mono_add_internal_call 在 C# 注册
#define HZ_ADD_INTERNAL_CALL(Name) mono_add_internal_call("Hazel.InternalCalls::" #Name, Name)static void NativeLog(MonoString* string, int parameter){char* cStr = mono_string_to_utf8(string);std::string str(cStr);mono_free(cStr);std::cout << str << ", " << parameter << std::endl;}static void NativeLog_Vector(glm::vec3* parameter, glm::vec3* outResult){HZ_CORE_WARN("Value: {0}", *parameter);*outResult = glm::normalize(*parameter);}static float NativeLog_VectorDot(glm::vec3* parameter){HZ_CORE_WARN("Value: {0}", *parameter);return glm::dot(*parameter, *parameter);}void ScriptGlue::RegisterFunctions(){HZ_ADD_INTERNAL_CALL(NativeLog);HZ_ADD_INTERNAL_CALL(NativeLog_Vector);HZ_ADD_INTERNAL_CALL(NativeLog_VectorDot);}
C# 中声明函数,使用 MethodImplAttribute 标签
[MethodImplAttribute(MethodImplOptions.InternalCall)]
internal extern static void NativeLog(string text, int parameter);
这么看,两种在 C# 中调用 Cpp 的方法都挺简单
虽然Mono对string这个特殊变量做了个处理,但对于函数的参数和返回值是其他struct和class的情况,就比较复杂了,在C++里class和struct基本是一样的,而C#里却完全不一样,这里涉及到的点有:
-
如何在C#进行值传入,在C++里也创建一份数据对象,此时的传入值在C#里为struct,在C++里可以是struct或class,各自的栈上各有一份数据
-
如何在C#进行引用传入,即指针传入,在C++里输入的也是指针,托管堆和非托管堆共享同一份数据
-
相同类在managed和unmanaged代码上存在时,如何保证内存分布一致(涉及Marshalling 编组)
-
怎么传struct或class的数组、怎么传普通primitive的数组
-
返回类型也可以是值类型或指针类型,这里应该和传参是一样的,就不重复提了,后面注意下语法就行了
总的来说,C#与C++交互处理传参和返回值时,分两种情况:
-
通过指针进行,不存在值拷贝的过程,C#的struct对应的是ref和out关键字,C#的class直接传对象即可
-
通过Copy值类型进行
两种情况下,只要接触到了struct和class,都需要保证C++和C#定义相同内存结构,对于class会复杂一些,后面再深入研究
C#调用C++的自定义struct为参数的静态函数
由于C#里struct和class的区别,这里具体分为两种,如果是struct,那么需要先定义两端的Struct,写法为:
// 对于POD类型, 只要它俩内存Layout相同即可
// C#
struct Vector3
{float x;float y;float z;
}// cpp
struct float3
{float x,y,z;
}static void LogFloat3(const float3* input)
{LOG(input);
}// method需要用ClassName::的形式
mono_add_internal_call("MyNamespace.Program::PrintVector3", &LogFloat3);
假设我要从C#这边传入一个Vector3,再让C++打印出来,那么传入Vector3的引用就行了,此时csharp这边传入的参数为ref A ,c++这边传入的参数为A*,代码如下所示:
namespace MyNamespace
{public class Program{public void PrintVector3(ref Vector3f input){PrintVector3(input);}[MethodImplAttribute(MethodImplOptions.InternalCall)]extern static void PrintString(ref Vector3f input);}
}
C#调用C++的重名重载函数
鉴于mono_add_internal_call(“MyNamespace.Program::Print”, &PrintFuncForCSharp);这种写法,C++这边应该是不支持函数重载的,但是C#这边是可以通过Wrapper来模拟函数重载的,所以C++这边只能用老的C语言的方式处理函数重载了,比如:
// C++ 端
static void Func(){};
static void FuncString(std::string){};// C#端
[MethodImplAttribute(MethodImplOptions.InternalCall)]
extern static void Func();[MethodImplAttribute(MethodImplOptions.InternalCall)]
extern static void FuncString(string);// 加个wrapper
public static void Function()
{Func();
}public static void Function(string s)
{FuncString(s);
}
Internal Call的特殊情况
如果想要在C++设计一个函数,这个函数返回一个指针或引用,此时再把这个函数暴露给C#,是不太好的,更好的方法是让这个函数返回值为void,原本返回的参数作为函数参数传入和传出(应该C#这边也能接受C++返回的指针,无非是要用unsafe的代码),写法大概是这样:
// C++
static void Func(glm::vec3* para, glm::vec3* outResult)// 原本想返回的*变成了参数
{...
}// C#
[MethodImplAttribute(MethodImplOptions.InternalCall)]
extern static void FuncString(ref Vector3 para, out Vector3 result);
Calling C++ from C#
C# 到 C++ 的调用的抽象
这里把 C# 到 C++ 的调用抽象成了 ScriptEngine ScriptClass ScriptInstance 三个部分
一开始看有点复杂,之后还好
ScriptEngine 分为两个部分,第一个部分是与 Mono 的配置有关的,例如 InitMono, LoadAssembly, ShutdownMono,把应用域啊,assembly 啊存储到全局静态变量 s_Data,第二部分是管理 C++ 内部的,带有 C++ 的 ScriptComponent 类的 Entity 的
ScriptClass 类里面存了 nameSpace 和 name,这样,构造函数里面就调用 mono_class_from_name,存储 MonoClass
所以可以说 ScriptClass 是用来存储 MonoClass 的,还封装了 MonoClass 的接口,例如 mono_class_get_method_from_name,以及与存储了应用域的 ScriptEngine 配合,实例化的接口
ScriptInstance 里面存了 MonoObject,初始化参数包括 ScriptClass,初始化时从 ScriptClass 获取并存储一些我们已知要从 C# 中获取的方法,比如 .ctor, OnCreate, OnUpdate 等,也存了调用 Method 的接口
这些安排都是和 Mono 接口相匹配的,比如 mono_runtime_invoke 就需要 MonoObject MonoMethod,那么 ScriptInstance 就刚好,他存储了 MonoObject,还在初始化的时候存储了 MonoMethod
emmm 当然这个安排获取我也有点别的想法,比如我觉得 MonoMethod 可以存在 ScriptClass 而不用每个 ScriptInstance 都存一套 Method……
初始化时,获取并存储 C# 中的继承于某一已知命名空间名类名的类的所有派生类的信息
ScriptEngine 与 Mono 的配置有关的部分中的 LoadAssembly 就是教程中的获取 Assembly dll 的路径然后加载。它还有一个初始化的步骤 LoadAssemblyClasses 是,他需要知道 C# 中的类型,于是跟教程中的 Test Assembly 一样,我们可以从 assembly 获取 MonoImage,再从 MonoImage 获取 MonoTableInfo,再从 MonoTableInfo 的每一行获取 nameSpace 和 name,有了这两个,我们再用 mono_class_from_name 就能获取 MonoClass,而我们已知我们的 C# 中的基类是 Hazel 命名空间,基类名为 Entity,所以我们同样也能获得基类的 MonoClass,两个 MonoClass 可以进行比较,可以判断是否是子类,所以我们可以得到 C# 中定义的 Entity 的所有派生类,所以我们可以存一个表 EntityClasses,key 是 C# 中 Entity 的派生类型的全称,value 是我们用 nameSpace 和 name 构造的自定义的 ScriptClass 类
这样,我们就完成了初始化时,获取并存储 C# 中的继承于某一已知命名空间名类名的类的所有派生类的信息
ScriptComponent 初始化时根据已知的 命名空间名类名 创建 MonoObject
这个信息有什么用呢?我们 C++ 的 Entity 的 ScriptComponent 在逻辑上需要创建 C# 的实例,并且拥有它,所以从 ScriptComponent 的角度来说,它应该获取到一个 MonoClass 然后实例化它
ScriptComponent 是用户在编辑器里配置的,用户这个时候应该只知道 C# 里面的类的类名,所以我们约定,用户往 ScriptComponent 里面写 命名空间名.类名,因此我们就需要一个 string 命名空间名.类名 -> MonoClass 的映射,EntityClasses 就是做这件事
实际 Hazel 代码中,ScriptComponent 获取到 EntityClasses 之后,竟然是把他存到了一个 map EntityInstances 里面,key 为 Entity 的 ID,value 为 ScriptInstance
ScriptComponent 实例化 C# 的 Entity 的派生类获得 MonoObject 时,创建的是派生类的 MoboObject,还要调用 C# 的 Entity 基类的构造函数
ScriptComponent 实例化 C# 的 Entity 的派生类获得 MonoObject 时,创建的是派生类的 MoboObject,还要调用 C# 的 Entity 基类的构造函数
之前我也一直没上代码,但这个没上代码确实不太好说……
C# 中的游戏逻辑所在的类都是需要继承 Entity 的,这样才能在初始化的时候被放入 EntityClasses,这样 ScriptComponent 初始化的时候根据自己被写入的 string 才能从 EntityClasses 中找到对应的 ScriptClass ,才能用 ScriptClass 实例化一个 MonoObject
public class Player : Entity{...
ScriptComponent 去 Mono 的反射信息中找的时候,是用 ScriptComponent 里存的 Entity 的派生类的名字去找的的,ScriptComponent 创建 MoboObject 的时候创建的 Entity 的派生类的 MonoObject
void ScriptEngine::Init(){...// Retrieve and instantiate classs_Data->EntityClass = ScriptClass("Hazel", "Entity", true);...}ScriptInstance::ScriptInstance(Ref<ScriptClass> scriptClass, Entity entity): m_ScriptClass(scriptClass){m_Instance = scriptClass->Instantiate(); // 创建的是派生类的 MonoObjectm_Constructor = s_Data->EntityClass.GetMethod(".ctor", 1); // 但是还要调用一个基类的有参构造函数m_OnCreateMethod = scriptClass->GetMethod("OnCreate", 0);m_OnUpdateMethod = scriptClass->GetMethod("OnUpdate", 1);// Call Entity constructor{UUID entityID = entity.GetUUID();void* param = &entityID;m_ScriptClass->InvokeMethod(m_Instance, m_Constructor, ¶m);}}
但是还要调用一个基类的有参构造函数,就是,我们在实例化一个 MonoClass 的时候,我们用的是 mono_object_new,这个时候我们是没有传入参数的,所以这个函数是调用的这个派生类的无参构造函数
MonoObject* ScriptEngine::InstantiateClass(MonoClass* monoClass){MonoObject* instance = mono_object_new(s_Data->AppDomain, monoClass);mono_runtime_object_init(instance);return instance;}
调用的这个派生类的无参构造函数的之前,根据继承原理,调用的基类的,是基类的无参构造函数
但是我们又需要保证调用 C# 的 Entity 基类里面的那个构造 ID 的函数,C# 的类才能知道自己的 ID
public class Entity{internal Entity(ulong id){ID = id;}
所以我们还需要调用一次 C# 的基类 Entity 的有参构造函数
这里也看出来,我们在 C# 里面不能自己去 new 继承了 Entity 的派生类,如果自己去 new,自己就找不到 C++ 中对应的 Entity
ScriptComponent 想要有多个 C# 类的实例怎么办
我还在想,ScriptComponent 想要有多个 C# 类的实例怎么办……因为现在是不允许一个 Entity 有多个 ScriptComponent 嘛,所以只能是 ScriptComponent 想要有多个 C# 类的实例
或许用 unordered_multimap 来做 id 到 ScriptInstance 的映射?
Scene OnUpdate 时获取所有包含 ScriptComponent 的 Entity,调用 ScriptEngine::OnUpdateEntity,ScriptEngine::OnUpdateEntity 又调用 ScriptInstance 里存储的从 C# 获得的 OnUpdate
这就没什么好说了
Component
C# 中的 Entity 类的实例对应到 C++ 中 ScriptComponent 创建出的 MonoObject,C++ 里面有一个 <UUID, ScriptInstance> 的 map
注意这里不是直接存 <UUID, MonoObject> 而是存 <UUID, ScriptInstance>,因为 ScriptInstance 是对 MonoObject 和他相关的接口的封装
但是现在,如果我只是在 C++ 里面知道这个 map,我在 C++ 端可以根据 UUID 取 ScriptInstance,但是我在 C# 端却不能根据 MonoObject 取 UUID,不能取 UUID 也就意味着不能取到 C++ 的 ScriptInstance
所以我们还需要在 C++ 调用 C# 的类的构造函数的时候传入 C++ 端的 Entity 的 UUID
具体就是,C++ 端的 Entity 有 ScriptComponent,这个 ScriptComponent 要实例化 C# 的类,这个 ScriptComponent 自己知道自己属于哪个 Entity ,也就知道自己的 UUID,可以传参数给 C#
那现在 C# 中的 Entity 就知道自己的,在 C++ 端分配的 UUID 了
那现在我们就可以用 internal call 在 C# 端调用 C++ 的函数,C# 中的 Entity 传入 UUID,获得自己对应到 C++ 的 Entity
这样我们就可以做很多事情了,比如 HasComponent GetComponent
在 C++ 初始化的时候,要 RegisterComponent,其中输入了 C++ 中定义了一些 Component 的类型,在函数中转化成 C# 中的命名空间.类名的 string 输入到 mono_reflection_type_from_name 获取 MonoType
在 C# 端我们会定义与 C++ 里面定义的 Component 的名字同名的,C# 的 Component,这样,我们在 C++ 初始化 RegisterComponent 中用 mono_reflection_type_from_name 应该能获取到对应名字的 MonoType
其实这些 C# 的 Component 里面只是一些属性,get set 都是 internal call,调用 C++ 的提供的 get set
感觉这个 C# 的组件定义,里面这些属性,还有 C++ 中提供给 C# 的 internal call 都是可以代码生成的hhh
如果能获取到 MonoType,说明 C# 端是成功定义了与 C++ 里面定义的 Component 的名字同名的 C# 的 Component,那么我们可以再初始化一个 map <MonoType, std::function<bool(Entity)>>,因为我们在 C++ 里面是 类型 -> 类型名 -> C# 中的命名空间.类名 -> mono_reflection_type_from_name -> MonoType,所以我们同时知道 MonoType 和 C++ 类名,如果我们使用模板编程,这里的 C++ 类型就是模板 T,我们可以放入 [](Entity entity) { return entity.HasComponent<T>();
HasComponent 向 C++ 端传入 UUID 和 C# 的 Type 类型,C# 的 Type 类型对应到 C++ 就是 MonoReflectionType
C++ 中提供给 C# 的 internal call 的 HasComponent 可以通过 mono_reflection_type_get_type 获得 MonoType,就是从这个 map 获得判断某个 Entity 是否具有某个组件的函数
C# 的 GetComponent 不是单纯的初始化,因为我们现在 C# 的 Component 与 C++ 的 Component 是有对应关系的,所以我们在 C# 中创建 C# 的 Component 类的时候,我们需要首先从 C# 这里出发,去问 C++,我自己对应到 C++ 的 Entity 中有没有这个 C++ 的对应的 Component,有的话我才创建 C# 中的 Component 类
如果不做这个检查,C# 直接就 new 的话,那么 C# 中的组件其实也只是 get set 用 internal call 调用 C++ 而已,调用了 C++,C++ 函数里面本来需要 C++ 的 Entity 具有特定的 C++ 的 Component,现在没有的话就会出错
当然这里还有一个问题是,嗯,现在这个写法,假设 C++ 的 Entity 中有这个 C++ 的对应的 Component,那么我 C# 每次调用 GetComponent 都在 new 啊,我感觉是不是应该,第一次 new,之后就返回之前 new 出来的对象……
public T GetComponent<T>() where T : Component, new()
{if (!HasComponent<T>())return null;T component = new T() { Entity = this };return component;
}
将游戏 Assembly 和 核心 Assembly 分离
它刻意要把游戏的 Assembly 和 核心的 Assembly 分离,做成两个类库,就很强
这样的话,就相当于,游戏的 Assembly 是玩家写的,核心的 Assembly 是引擎写好的不用动的
这样的话,每次玩家更新脚本,只用重新编译玩家写的 Assembly 就好了
C++ 获取 C# 类的属性
看代码就行了,很简单
现在的获取属性还是需要游戏开始运行,游戏开始运行时,才会开始创建 ScriptInstance,Panel 这里才能获取到 ScriptInstance,才能 GetFieldValue
这是很显然的,运行时,C++ 这边才开始遍历 ScriptComponet 才开始创建继承了 Entity 的 C# 类的实例,这个时候才有 C# 的对象,才有对象里的字段
但是 Unity 那里是可以在编辑器模式下更改字段的默认值的,所以我觉得那应该是从类得到的字段表,然后存一个字段的默认值的 map,在游戏开始时从这个 map 赋值
将 C# 字段的值复制到运行时 Storing/copying C# field values to runtime
很好,就是我之前的想法
他设置了一个标志表示当前场景是否在运行,如果是游戏在运行(不是运行物理模拟),那么就显示 ScriptInstance 的 get field,如果拖动了,那么就对 ScriptInstance SetValue,如果游戏没有在运行,那么如果拖动了 imgui 的 float,那么就获取到这个 entity 对应的 field map 然后把值存到 field map
中
序列化 ScriptComponent 的 fieldMap
现在我们已经对每一个有 ScriptComponent 的 Entity 创建了一个 fieldMap,用于在运行时把 fieldMap 中的值赋给 C# 类的实例
现在我们要序列化这个 fileMap
还是很简单的,序列化某一个 ScriptComponent 的时候,我们知道它存储的 C# 类的类名,根据这个类名我们可以获得 MonoClass 根据 MonoClass 我们可以获得 Fields,遍历 Fields 我们可以获得 name 和 fieldType
我们手写 fieldType 和 C++ type 的对应关系,就可以从 field 中获取到 C++ 类型的值,写入到 ymal 流
反序列化也是一样的
Added FindEntityByName and Entity.As to retrieve script class instance
现在我们要在一个 C# 的 Entity 的派生类的实例中获取另一个 Entity 的派生类的实例
我们暂时没有 CreateEntity 的方法,我们现在可以做的是,C# 根据一个 string name 到 C++ 中去找 Entity ID,C++ 返回一个 Entity ID,然后 C# 中根据这个 ID 创建一个 Entity 类的对象
public Entity FindEntityByName(string name)
{ulong entityID = InternalCalls.Entity_FindEntityByName(name);if (entityID == 0)return null;return new Entity(entityID);
}
我们知道了 ID,C++ 中有 <UUID, ScriptInstance> 的 map,ScriptInstance 里存了 MonoObject 我们就可以从 C# 传 UUID 到 C++,C++ 去 map 里面找到 ScriptInstance,获取 MonoObject 然后传到 C#,C# 里面获取到 Object 之后拆箱成 Entity 的派生类
所以这里,嗯,新建一个 Entity 的话……感觉有点怪
就是说,本来我们都知道 C# 世界中一个 Entity 的派生类对应 C++ 世界中的一个 ScriptInstance 中的一个 MonoObject 的
现在你要是允许这样创建一个 Entity 的话,虽然你已经检查了, 确保这个 Entity 可以对应到 C++ 中的某个 ScriptInstance ,但这会不会造成多个 Entity 对应到 ScriptInstance
public T As<T>() where T : Entity, new()
{object instance = InternalCalls.GetScriptInstance(ID);return instance as T;
}
这也说明了,在 C# 和 C++ 之间传对象的时候,如果是要传 C# 的 class 的话,那就不得不传 Object 了,就不得不拆箱了
如果是要传原始类型的话,不用编组,如果是传自定义结构体的话就要编组了
C# 程序集 Assembly 重新加载
在 Unload 某个 AppDomain 之间先 mono_domain_set 当前的 RootDomain 为 false
此外没有了,这个 commit 就是知道了这一点。他存下了 Core Assembly 和 Game Assembly 的位置,然后提供了 imgui 的 menu 按钮和 imgui 检测按键,去重新加载 Assembly
Unload Assembly 的话就是 Unload 当前 AppDomain,因为加载 Assembly 就是加载到当前 AppDomain 的
重新加载,就是先 Unload 然后再 Load Core Assembly 和 Game Assembly
这个 commit 还没有添加文件检测
然后它也没有在 Reload 的时候更新 C++ 到 C# 的映射时要利用的反射信息,例如
std::unordered_map<std::string, Ref<ScriptClass>> EntityClasses;
std::unordered_map<UUID, Ref<ScriptInstance>> EntityInstances;
std::unordered_map<UUID, ScriptFieldMap> EntityScriptFields;
因为你完全可能 Reload 一个与旧的 Assembly 完全不同的 Assembly,导致之前加载的所有的类都失效,或者类不变,但是类里面的字段全变了,也有可能……
这些都是可以做的……
文件监视 fileWatch
使用了一个 filewatch 库来检测文件是否发生更改
https://github.com/ThomasMonkman/filewatch
因为这个 filewatch 是单独开一个线程的,所以这就涉及到了文件监视线程和主线程的互斥问题
通过约定文件监视线程发送请求到 queue,主线程从 queue 中拿请求的方式,可以完成文件监视线程到主线程的通信
而主线程从 queue 中拿请求的时候,文件监视线程不能发送请求,所以这是两个互斥的操作
互斥可以用一个 std::scoped_lock 方便地实现对当前作用域上锁,并且还是 RAII 的
// Application.h
std::mutex m_MainThreadQueueMutex;// Application.cpp
void Application::SubmitToMainThread(const std::function<void()>& function)
{std::scoped_lock<std::mutex> lock(m_MainThreadQueueMutex);m_MainThreadQueue.emplace_back(function);
}void Application::ExecuteMainThreadQueue()
{std::scoped_lock<std::mutex> lock(m_MainThreadQueueMutex);for (auto& func : m_MainThreadQueue)func();m_MainThreadQueue.clear();
}void Application::Run()
{while (m_Running){...ExecuteMainThreadQueue();...}
}
暂停和步进 Pausing and Stepping
在内置的 OnUpdate 中设置条件判断 if (!m_IsPaused || m_StepFrames-- > 0) 通过后才能 Update
这样,如果是暂停时,那么需要 m_StepFrames 为正才能 Update
如果点一次步进按钮会给 m_StepFrames 加 1,就能达成点一次步进按钮,世界步进一次的效果
添加 C# debugging
使用 mono_debug_open_image_from_memory 加载符号表
自定义 Buffer 和 ScopeBuffer
在加载文件的时候经常需要创建一个数据指针,接收数据,然后我们要记得销毁掉这个指针
所以我们可以自定义一个 RAII 风格的 ScopeBuffer 类,它的生命周期是当前作用域,离开了作用域就会被销毁
游戏工程的抽象类 Project
把游戏工程抽象出来
每一个游戏工程有自己的:名称、启动场景、资源目录、C# 脚本目录
引擎的内容浏览器要依赖于当前工程创建,因为只有知道了工程才能知道资源目录
复制时的 bug
复制 Entity 的时候会复制名字
如果复制的时候一直传引用的话,那么最后得到的是
Clone submodule 时的错误
我在拉取到 MSDF 那个 commit 的时候 clone 不了 submodule
E:\Hazel-master\Hazel>git submodule update --init --recursive
fatal: No url found for submodule path 'Hazel/vendor/msdf-atlas-gen' in .gitmodules
查了一下:
https://stackoverflow.com/questions/4185365/no-submodule-mapping-found-in-gitmodule-for-a-path-thats-not-a-submodule
我把 .gitmodule 中的路径中的 \\ 改成了 / 就好了
Windows,真是神奇
error MSB8013: This project doesn’t contain the Configuration and Platform combination of Debug|Win32
看了这个,我的 vcxproj 里面确实都是 x64,这一点时可以信任 premake 的
https://stackoverflow.com/questions/33156131/x64-build-error-msb8013-this-project-doesnt-contain-the-configuration-and-pla
看了这个,我的项目文件夹里面没有 Directory.Build.props 这个文件……
https://github.com/flutter/flutter/issues/129997
之后我重启电脑就好了……神奇的 Visual Studio
字体
用了 https://github.com/Chlumsky/msdf-atlas-gen
我根本看不懂……
AssetManager
说实话没太看懂……