系列文章目录
文章目录
- 系列文章目录
- 前言
前言
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用,看懂了就去分享给你的码吧。

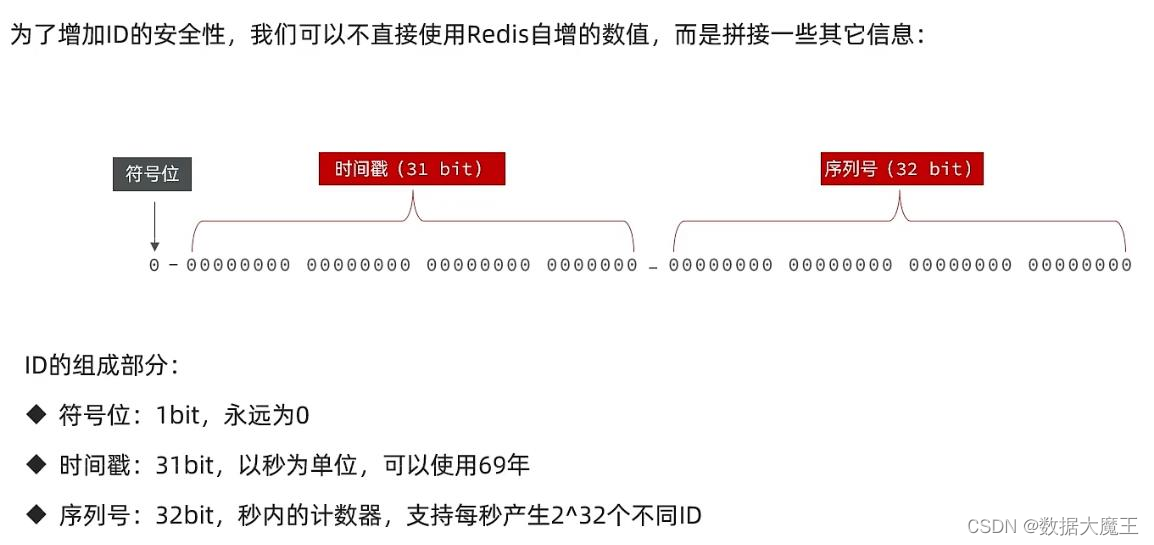
在分布式系统中,做事务跟踪,数据分片,都需要使用全局唯一ID。全局唯一ID的生成方式需要满足的需求一般包括:

1.全局唯一:最基本的要求
2.趋势递增:在MySQL的innoDB引擎中使用的是聚集索引,由于使用Btree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
3.单调递增 :保证下一个ID大于上一个ID,例如事务版本号、IM增量信息、排序等特殊需求
4.信息安全: 如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可 所以在一些应用场景下,需要ID无规则 不规则,让竞争对手不好猜
5.含时间戳:这样就能在开发中快速了解分布式id的生成时间
6.高可用,低延迟,高QPS(对QPS不了解的,可以简单的理解为每秒的生产id的个数)
实现方案
UUID,绝对唯一但占用存储
数据库自增主键,可用性不高
Redis实现,集群宕机ID不连续
雪花算法Snowflake,依赖时钟
无意中看到黑马老师代码中利用Redis自增实现ID生产的代码,感觉比较实用,撸下来备用,方案
代码
package com.example.springboot;import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.StringRedisTemplate;import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.time.format.DateTimeFormatter;/*** 利用Redis自增,生成唯一ID*/
@SpringBootTest
public class RedisIDBuilder {@Autowiredprivate StringRedisTemplate stringRedisTemplate;/*** 开始时间戳,参考方法getTimesMap()*/private static final long BEGIN_TIMESTAMP = 1645568542L;/*** 序列号的位数*/private static final int COUNT_BITS = 32;/*** 自增前缀*/private String keyPrefix = "Order";@Testpublic void nextId() {// 1.生成时间戳LocalDateTime now = LocalDateTime.now();long nowSecond = now.toEpochSecond(ZoneOffset.UTC);long timestamp = nowSecond - BEGIN_TIMESTAMP;// 2.生成序列号// 2.1.获取当前日期,精确到天String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));// 2.2.自增长long count = stringRedisTemplate.opsForValue().increment("ID:" + keyPrefix + ":" + date);// 3.拼接long id = timestamp << COUNT_BITS | count;System.out.println(id);}/*** 得到某时间的时间戳*/@Testpublic void getTimesMap(){LocalDateTime localDateTime = LocalDateTime.of(2022, 2, 22, 22, 22, 22);System.out.println(localDateTime.toEpochSecond(ZoneOffset.UTC));}}
配置
spring:redis:host: 127.0.0.1port: 6379client-name: portalpassword: l52u27lv1Jurlettuce:pool:max-idle: 10max-active: 20min-idle: 2max-wait: 5000msdatabase: 0
分析,这段代码以时间戳作为基础,即已经把ID划分到了秒,后面又根据Redis自增进行填补,根据不同业务生成不同的自增ID,由于生成的是数字,对于数据库存储和查询比较友好,而且能满足高并发时安全生成ID的要求。