注:案例测试数据及其索引构建详见:ElasticSearch中使用bge-large-zh-v1.5进行向量检索(一)-CSDN博客 中的第三部分。
假设任务场景为:用“新疆”向量检索相关的数据,同时需要匹配关键词“巴州”。
首先获取“新疆”的bge-large-zh-v1.5向量:
POST _ml/trained_models/bge-large-zh-v1.5/_infer
{"docs": [{"text_field": "新疆"}]
}结果如下:

直接根据“新疆”向量查询
GET article_embeddings/_search
{"query": {"knn": {"field": "text_embedding.predicted_value","num_candidates": 10,"query_vector": [-0.03627504035830498,-0.007771393284201622,0.036312565207481384,此处省略若干值]}}
}
默认返回所有的数据,且编号002的文档排在003前面。

如果我们想让包含关键词“巴州”的003文档排在002的前面,可以采用加filter的方式:
编写相应语句:
GET article_embeddings/_search
{"knn": {"field": "text_embedding.predicted_value","num_candidates": 10,"filter": {"match": {"title": "巴州"}},"query_vector": [-0.03627504035830498,-0.007771393284201622,0.036312565207481384,此处省略若干值]}
}
结果如下:
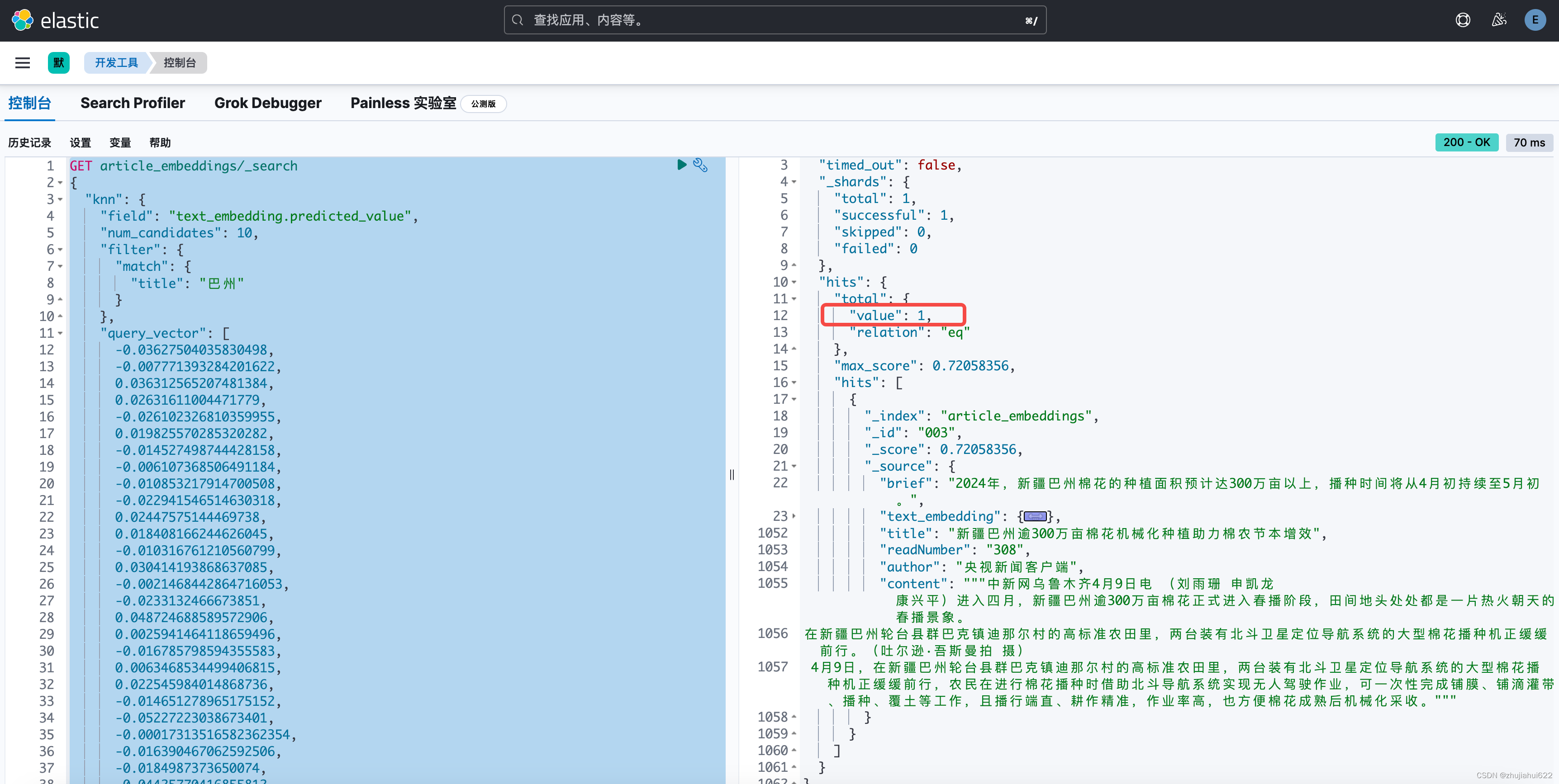
此时发现最终只剩一条满足title中有“巴州”的文档了。
如果只是想把含有“巴州”的文档提前,不过滤,则可以采用如下的方式:
GET article_embeddings/_search
{"query": {"match": {"title": "巴州"}},"knn": {"field": "text_embedding.predicted_value","num_candidates": 10,"query_vector": [-0.03627504035830498,-0.007771393284201622,0.036312565207481384,此处省略若干值]}
}
效果如下:



![[Kubernetes] etcd的集群基石作用](https://img-blog.csdnimg.cn/direct/7b4e2099576e408a81cfffbf8384be77.webp)