1.大语言模型相关基本概念综述
语言模型指对语言进行建模,其起源于语音识别(speech recognition),输入一段音频数据,语音识别系统通常会生成多个句子作为候选,究竟哪个句子更合理?
学术上表达为:描述一段自然语言的概率或给定上文时下一个词出现的概率

根据之前的介绍,语言模型经过四个阶段的发展,详情请参考上一节学习分享博客
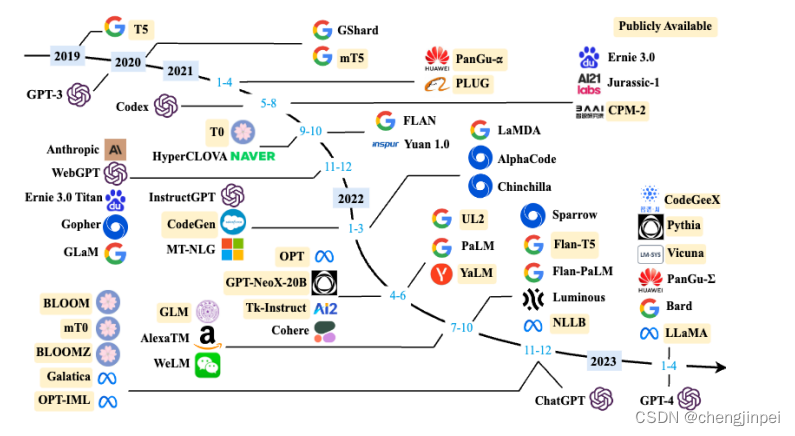
毫无疑问,大语言模型是一种由包含数百亿以上参数的深度神经网络构建的语言模型,通常使用自监督学习方法通过大量无标注文
本进行训练。大模型发展的时间线可以参考下图
1.1 大语言模型的涌现能力
大语言模型的涌现能力(Emergent Capability)指的是随着模型规模的增加,模型展现出超出预期的能力和表现,这种能力使得大语言模型成为能够解决负责任务和推动人工智能进步的重要工具。涌现一般体现在如下几个方面:
- 学习能力提升:大语言模型具备更大的空间参数和表征能力,能够学习到更复杂、抽象的模式和特征,自然语言理解能力更强,能够捕捉数据的细微差异
- 语言理解和生成能力:在自然语言任务重,大模型能够理解更丰富的语义和语法知识,并具备更好的语言理解和生成能力
- 创新和探索:大语言模型能力不仅体现在已知任务重,而且在一些创新探索领域仍然可以发挥自己的创造性
1.2 大模型的推理能力
大模型的推理能力指的是逻辑推理、推断和推理问题解决方面的能力,一般体现在如下5个方面:
- 逻辑推理:具备一定的逻辑推理能力,掌握逻辑推理的规则和方法
- 推断和推理问题解决:可以通过已有知识的推理和推断,填补不完整的信息,解决模糊和宽泛的问题。
- 关联和关系理解:大模型具备强大的关联和关系理解能力,能够识别多个要素直接的关系
- 多步推理:大模型能够完成多步推理,在推理过程汇总进行多个步骤的演绎和推断;
- 常识推理:因大模型学习过海量知识,具备一定的常识推理能力
2.大语言模型构建流程
大模型的训练阶段主要包含四个阶段:预训练阶段、有监督微调阶段、奖励模型阶段和强化学习阶段,这四个学习阶段都需要不同规模的数据集合以及不同的算法,而且需要不同的机器资源和相关策略。

接下来介绍不同阶段的细节及特点
2.1预训练阶段
预训练阶段:需要利用海量的训练数据,包括互联网网页、维基百科、书籍、GitHub、论文、问答网站等,构建包含数千亿甚至数万亿单词的具有多样性的内容。该阶段可以理解为使模型能够理解和生成各种不同类型的文本,相当于广泛学习,具备通识知识。
2.2 有监督微调(指令微调)阶段
有监督学习阶段:为指令微调,利用少量高质量数据集合,包含用户输入的提示词(Prompt)和对应的理想输出结果。用户输入包括问题、闲聊对话、任务指令等多种形式和任务。该阶段可以理解为使用人工标注的数据集来训练模型,使得大模型具备特定问题生成回复是更加准确和有针对性。
2.3 奖励建模阶段
奖励建模阶段:目标是构建一个文本质量对比模型,对于同一个提示词,SFT模型给出的多个不同输出结果的质量进行排序。奖励模型(RM 模型)可以通过二分类模型,对输入的两个结果之间的优劣进行判断。该阶段可以理解为用户区分模型生成内容质量的高低,引导模型向好的方向靠齐。
2.4 强化学习阶段
强化学习阶段:根据数十万用户给出的提示词,利用在前一阶段训练的 RM 模型,给出 SFT 模型对用户提示词补全结果的质量评估,并与语言模型建模目标综合得到更好的效果。该阶段和奖励模型一起,不断的优化大模型自己的生成策略,是的大模型能够生成更加流畅、准确的回复内容。
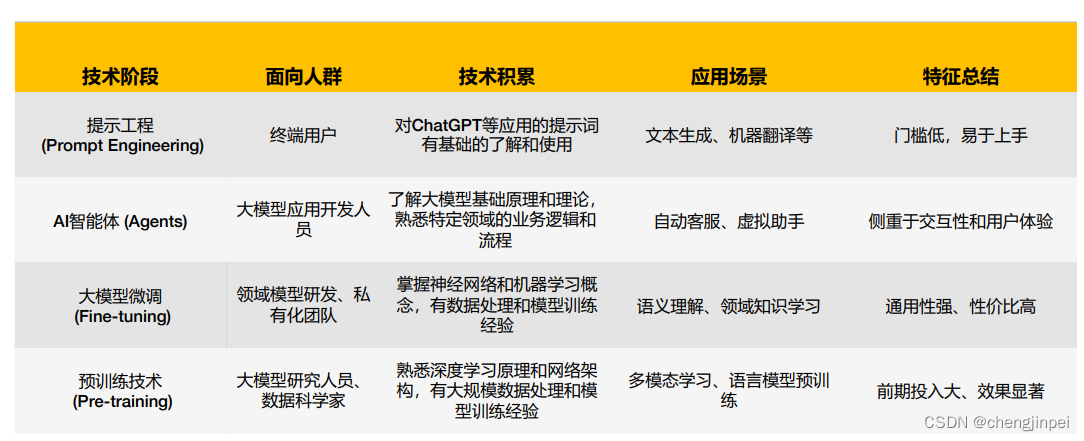
由上述的四个阶段,也衍生出不同的使用者的四个阶段。一般情况下对于纯粹的使用者来说,可以使用prompt快速使用入门;对于应用开发人员,可以使用langchain等工具快速开发出一个智能体,从而完成特定流程的实现;对于算法人员来说,额外关注大模型的落地应用,这块往往需要掌握大模型微调技术;对于深度算法使用人员来说,一般更关注于底座大模型的训练,从而提成底座能力。对于大模型感兴趣的人员,可以从prompt指令入手,开始用起来,可以参考prompt指令入门。本次主要分享微调技术,其他的技术阶段待后续更新。
3.大语言模型参数微调方法
在了解微调方法之前,我们先了解下为什么需要微调大模型,而不是直接预训练模型?首先是预训练模型的成本比较高,其次提示工程存在一定的限制,不能够完全解决下游问题,此外对于下游任务,特别是特定领域数据,大模型在预训练时,并没有见到过,所以这部分场景往往需要微调从而实现下游任务。
大模型的微调一般包含 全量微调方式 和 微调其他
全量微调方式:全量微调(Full Fine-Tune,FFT)
其他微调方式
- 高效微调方式(Parameter-Efficient Fine-Tune,PEFT)
- 有监督微调(Supervice Fine-tune,SFT)
- 基于人类反馈的强化学习(RLHF)
- 基于AI反馈的强化学习(RLAIF)
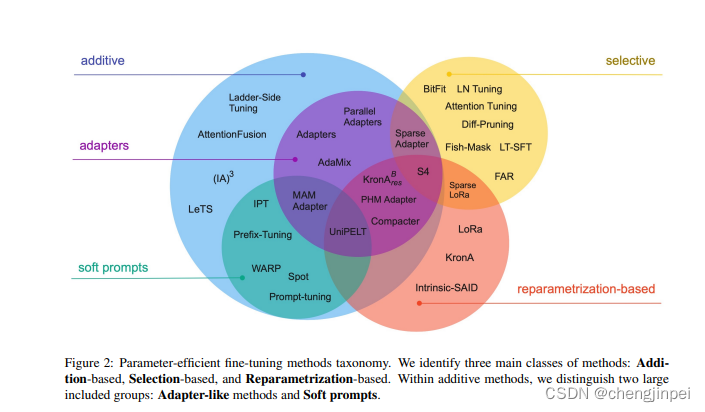
一般情况下,对于个人来说,PEFT为当下主流的应用方式,如上图所示,PEFT高效微调方法可以按照如下结果方面划分:
(1)围绕Token做文章:语言模型不变,额外添加token - Prompt tuning
- Prefix tuning
- P-tuning
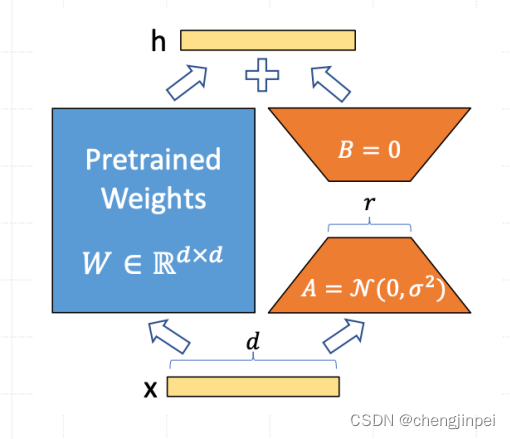
(2)特定场景任务:训练“本质”的低秩模型 - Lora
- QLora
- AdaLora
(3)少量数据类等 - IA3
- UniPELT
为了方便进一步理解上述微调方法,接下来使用图例进行解释。对于输入x 和输入y,模型需要做的就是建立输出y与x之间的映射关系,即y = f(x) = Wx
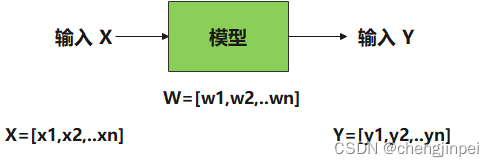
对于上述的图示中,W表示模型参数,X表示输入,Y表示输出,上述的高效微调方法可以分为改变输入X(如prompt-tuning),额外替代W参数(如lora)以及对于W进行参数存储量化。
3.1 BitFit
3.2 Prefix Tuning
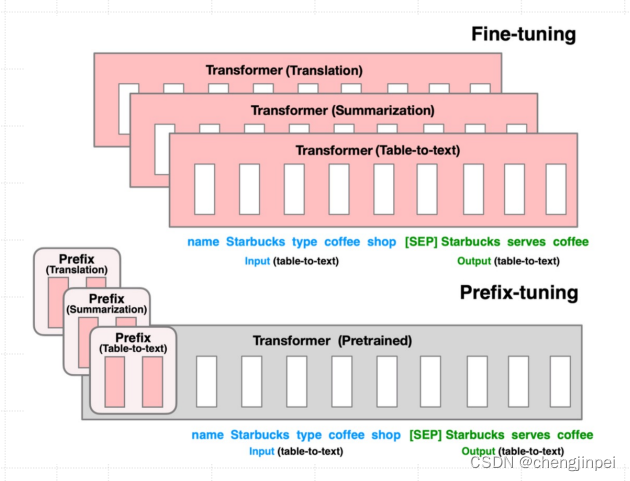
3.3 Prompt Tuning
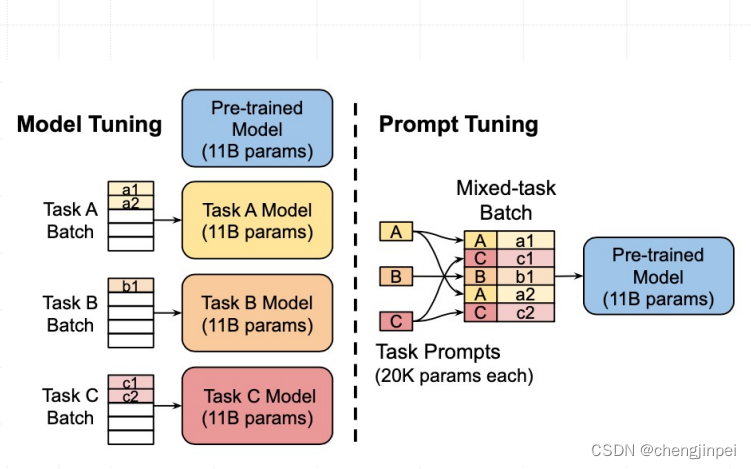
3.4 P-Tuning & P-Tuning V2

3.6 Adapter Tuning
3.7 Lora