一、本文介绍
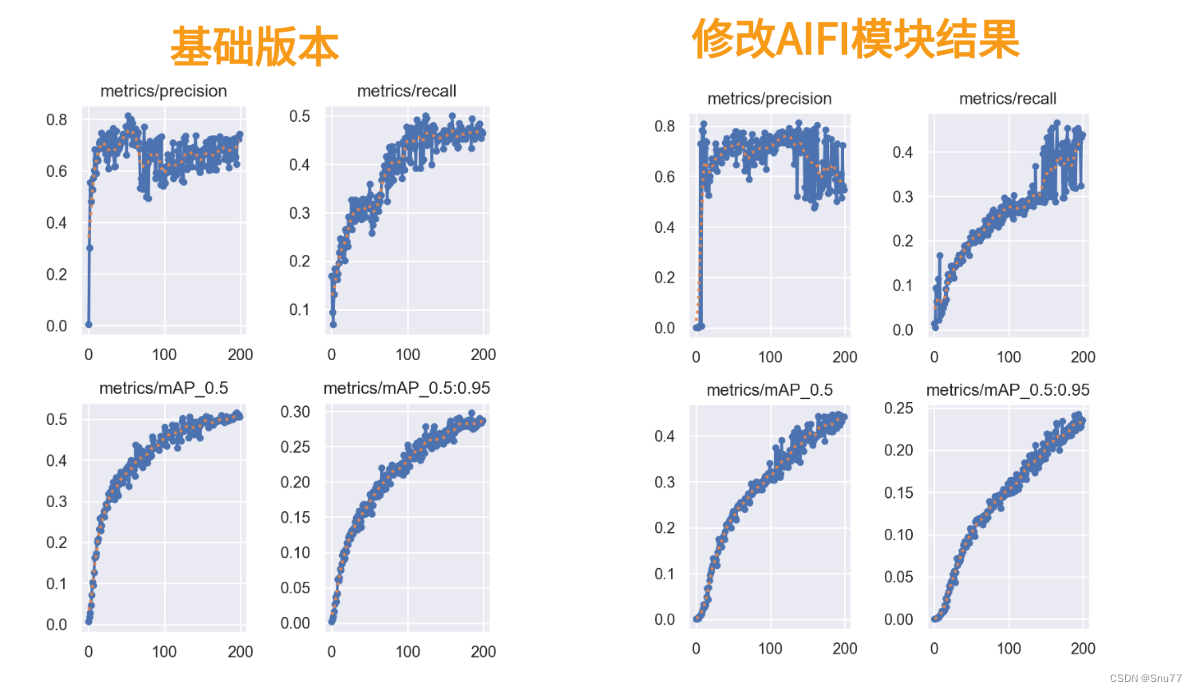
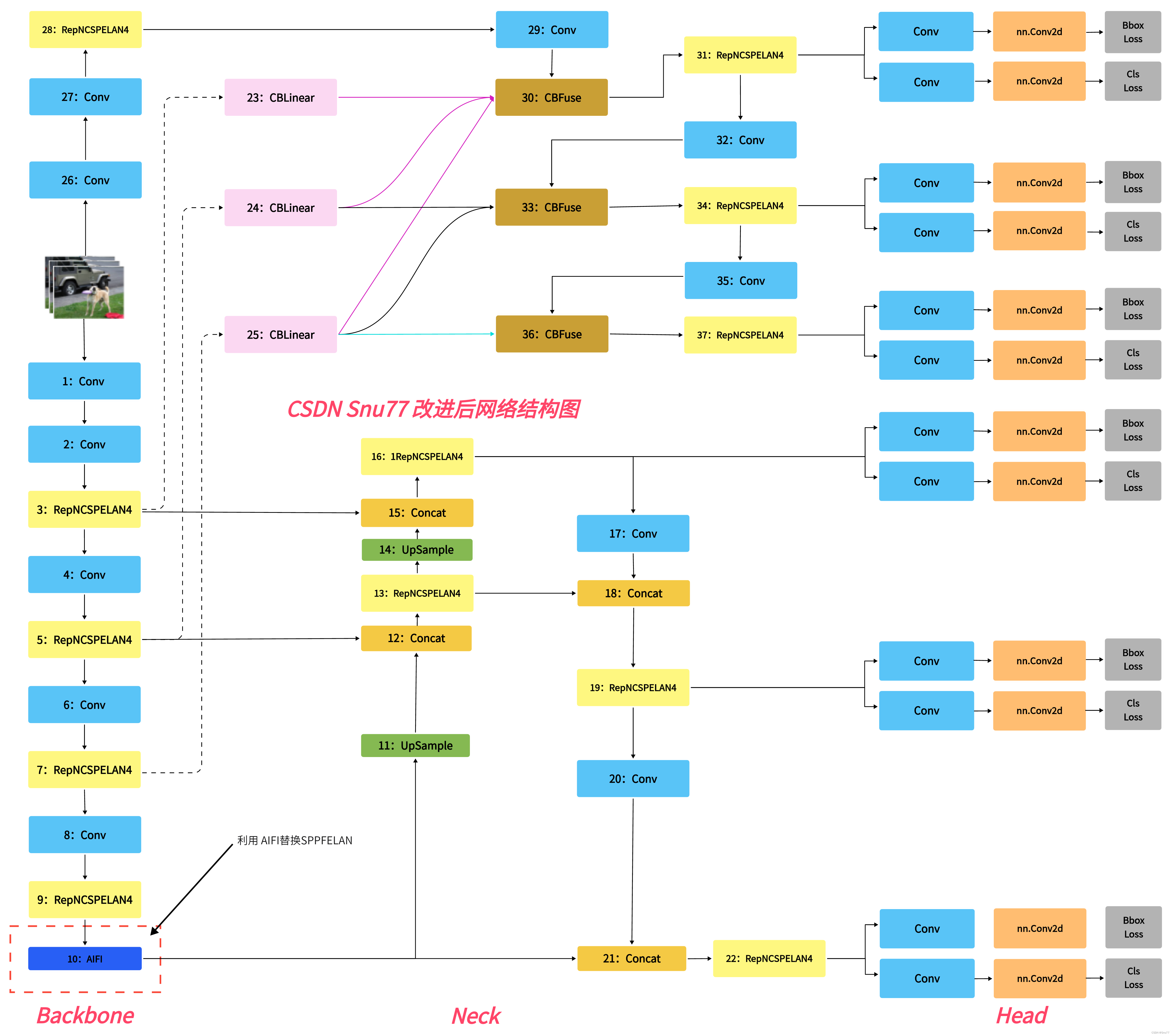
本文给大家带来是用最新的RT-DETR模型中的AIFI模块来替换YOLOv9中的SPPFELAN。RT-DETR号称是打败YOLO的检测模型,其作为一种基于Transformer的检测方法,相较于传统的基于卷积的检测方法,提供了更为全面和深入的特征理解,将RT-DETR中的一些先进模块融入到YOLOv9往往能够达到一些特殊的效果。同时欢迎大家订阅本专栏,本专栏每周更新3-5篇最新机制,更有包含我所有改进的文件和交流群提供给大家。同时本专栏目前改进基于yolov9.yaml文件,后期如果官方放出轻量化版本,专栏内所有改进也会同步更新,请大家放心,本文提供三种使用方式,下面图片为yaml1对应的结构图。
专栏地址:YOLOv9有效涨点专栏-持续复现各种顶会内容-有效涨点-全网改进最全的专栏
目录
一、本文介绍
二、RT-DETR的AIFI框架原理
2.1 AIFI的基本原理
三、AIFI的完整代码
四、手把手教你添加AIFI模块
4.1 细节修改教程
4.1.1 修改一
4.1.2 修改二
4.1.3 修改三
4.1.4 修改四
4.2 AIFI的yaml文件
4.3 AIFI运行成功截图
五、本文总结
二、RT-DETR的AIFI框架原理

论文地址:RT-DETR论文地址
代码地址:RT-DETR官方下载地址

2.1 AIFI的基本原理
RT-DETR模型中的AIFI(基于注意力的内部尺度特征交互)模块是一个关键组件,它与CNN基于的跨尺度特征融合模块(CCFM)一起构成了模型的编码器部分。AIFI的主要思想如下->
-
基于注意力的特征处理:AIFI模块利用自我注意力机制来处理图像中的高级特征。自我注意力是一种机制,它允许模型在处理特定部分的数据时,同时考虑到数据的其他相关部分。这种方法特别适用于处理具有丰富语义信息的高级图像特征。
-
选择性特征交互:AIFI模块专注于在S5级别(即高级特征层)上进行内部尺度交互。这是基于认识到高级特征层包含更丰富的语义概念,能够更有效地捕捉图像中的概念实体间的联系。与此同时,避免在低级特征层进行相同的交互,因为低级特征缺乏必要的语义深度,且可能导致数据处理上的重复和混淆。
总结:AIFI模块的主要思想其实就是通过自我注意力机制专注于处理高级图像特征,从而提高模型在对象检测和识别方面的性能,同时减少不必要的计算消耗。
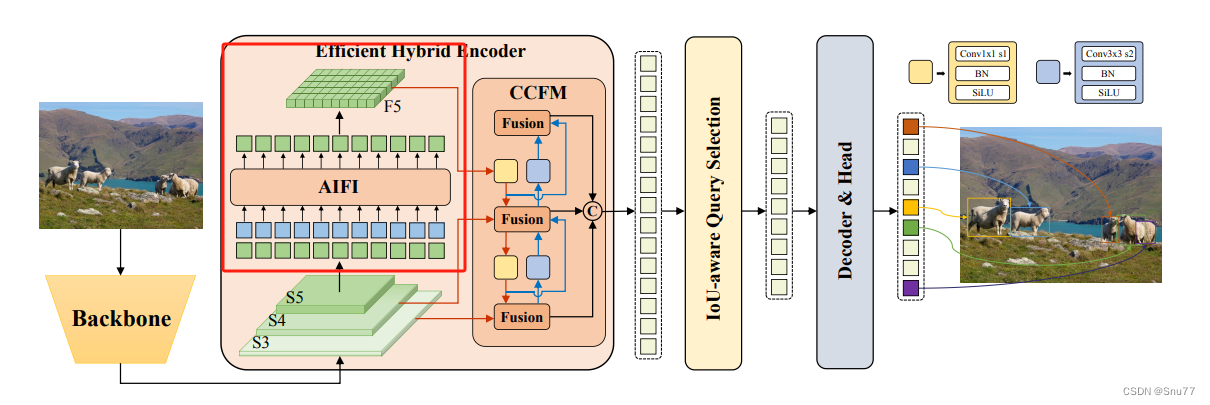
AIFI模块的主要作用和特点如下:
1. 减少计算冗余:AIFI模块进一步减少了基于变体D的计算冗余,这个变体仅在S5级别上执行内部尺度交互。
2. 高级特征的自我注意力操作:AIFI模块通过对具有丰富语义概念的高级特征应用自我注意力操作,捕捉图像中概念实体之间的联系。这种处理有助于随后的模块更有效地检测和识别图像中的对象。
3. 避免低级特征的内部尺度交互:由于低级特征缺乏语义概念,以及存在与高级特征交互时的重复和混淆风险,AIFI模块不对低级特征进行内部尺度交互。
4. 专注于S5级别:为了验证上述观点,AIFI模块仅在S5级别上进行内部尺度交互,这表明模块主要关注于处理高级特征。
没啥好讲的这个AIFI具体的内容大家可以看我的另一篇博客->
RT-DETR回顾:RT-DETR论文阅读笔记(包括YOLO版本训练和官方版本训练)
三、AIFI的完整代码
我们将在“ultralytics/nn/modules”目录下面创建一个文件将其复制进去,使用方法在后面第四章会讲。
import torch
import torch.nn as nn__all__ = ['AIFI']class TransformerEncoderLayer(nn.Module):"""Defines a single layer of the transformer encoder."""def __init__(self, c1, cm=2048, num_heads=8, dropout=0.0, act=nn.GELU(), normalize_before=False):"""Initialize the TransformerEncoderLayer with specified parameters."""super().__init__()self.ma = nn.MultiheadAttention(c1, num_heads, dropout=dropout, batch_first=True)# Implementation of Feedforward modelself.fc1 = nn.Linear(c1, cm)self.fc2 = nn.Linear(cm, c1)self.norm1 = nn.LayerNorm(c1)self.norm2 = nn.LayerNorm(c1)self.dropout = nn.Dropout(dropout)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.act = actself.normalize_before = normalize_before@staticmethoddef with_pos_embed(tensor, pos=None):"""Add position embeddings to the tensor if provided."""return tensor if pos is None else tensor + posdef forward_post(self, src, src_mask=None, src_key_padding_mask=None, pos=None):"""Performs forward pass with post-normalization."""q = k = self.with_pos_embed(src, pos)src2 = self.ma(q, k, value=src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]src = src + self.dropout1(src2)src = self.norm1(src)src2 = self.fc2(self.dropout(self.act(self.fc1(src))))src = src + self.dropout2(src2)return self.norm2(src)def forward_pre(self, src, src_mask=None, src_key_padding_mask=None, pos=None):"""Performs forward pass with pre-normalization."""src2 = self.norm1(src)q = k = self.with_pos_embed(src2, pos)src2 = self.ma(q, k, value=src2, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]src = src + self.dropout1(src2)src2 = self.norm2(src)src2 = self.fc2(self.dropout(self.act(self.fc1(src2))))return src + self.dropout2(src2)def forward(self, src, src_mask=None, src_key_padding_mask=None, pos=None):"""Forward propagates the input through the encoder module."""if self.normalize_before:return self.forward_pre(src, src_mask, src_key_padding_mask, pos)return self.forward_post(src, src_mask, src_key_padding_mask, pos)class AIFI(TransformerEncoderLayer):"""Defines the AIFI transformer layer."""def __init__(self, c1, cm=2048, num_heads=8, dropout=0, act=nn.GELU(), normalize_before=False):"""Initialize the AIFI instance with specified parameters."""super().__init__(c1, cm, num_heads, dropout, act, normalize_before)def forward(self, x):"""Forward pass for the AIFI transformer layer."""c, h, w = x.shape[1:]pos_embed = self.build_2d_sincos_position_embedding(w, h, c)# Flatten [B, C, H, W] to [B, HxW, C]x = super().forward(x.flatten(2).permute(0, 2, 1), pos=pos_embed.to(device=x.device, dtype=x.dtype))return x.permute(0, 2, 1).view([-1, c, h, w]).contiguous()@staticmethoddef build_2d_sincos_position_embedding(w, h, embed_dim=256, temperature=10000.0):"""Builds 2D sine-cosine position embedding."""grid_w = torch.arange(int(w), dtype=torch.float32)grid_h = torch.arange(int(h), dtype=torch.float32)grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing="ij")assert embed_dim % 4 == 0, "Embed dimension must be divisible by 4 for 2D sin-cos position embedding"pos_dim = embed_dim // 4omega = torch.arange(pos_dim, dtype=torch.float32) / pos_dimomega = 1.0 / (temperature ** omega)out_w = grid_w.flatten()[..., None] @ omega[None]out_h = grid_h.flatten()[..., None] @ omega[None]return torch.cat([torch.sin(out_w), torch.cos(out_w), torch.sin(out_h), torch.cos(out_h)], 1)[None]四、手把手教你添加AIFI模块
4.1 细节修改教程
4.1.1 修改一
我们找到如下的目录'yolov9-main/models'在这个目录下创建一整个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个文件,将我们的代码复制粘贴进去。

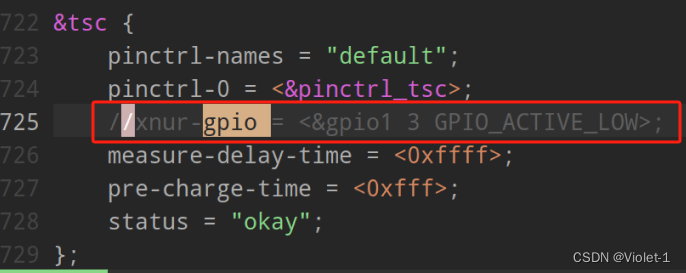
4.1.2 修改二
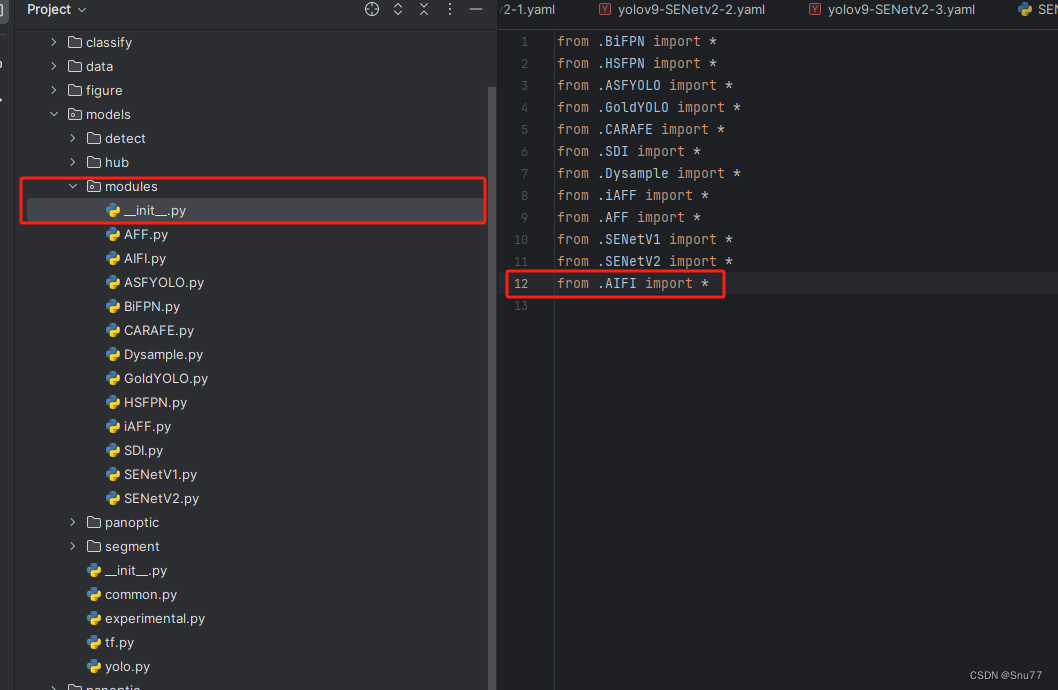
然后新建一个__init__.py文件,然后我们在里面添加一行代码(均用红框标记出来了)。注意标记一个'.'其作用是标记当前目录。
4.1.3 修改三
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加。)

4.1.4 修改四
然后我们找到parse_model方法,按照如下修改->

elif m in {AIFI}:c2 = ch[f]args = [c2, *args]到此就修改完成了,复制下面的ymal文件即可运行。
4.2 AIFI的yaml文件
# YOLOv9# parameters
nc: 80 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()# anchors
anchors: 3# YOLOv9 backbone
backbone:[[-1, 1, Silence, []],# conv down[-1, 1, Conv, [64, 3, 2]], # 1-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 2-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3# conv down[-1, 1, Conv, [256, 3, 2]], # 4-P3/8# elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5# conv down[-1, 1, Conv, [512, 3, 2]], # 6-P4/16# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7# conv down[-1, 1, Conv, [512, 3, 2]], # 8-P5/32# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9]# YOLOv9 head
head:[# elan-spp block[-1, 1, AIFI, []], # 10# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 16 (P3/8-small)# conv-down merge[-1, 1, Conv, [256, 3, 2]],[[-1, 13], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 19 (P4/16-medium)# conv-down merge[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 22 (P5/32-large)# routing[5, 1, CBLinear, [[256]]], # 23[7, 1, CBLinear, [[256, 512]]], # 24[9, 1, CBLinear, [[256, 512, 512]]], # 25# conv down[0, 1, Conv, [64, 3, 2]], # 26-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 27-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 28# conv down fuse[-1, 1, Conv, [256, 3, 2]], # 29-P3/8[[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 31# conv down fuse[-1, 1, Conv, [512, 3, 2]], # 32-P4/16[[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 34# conv down fuse[-1, 1, Conv, [512, 3, 2]], # 35-P5/32[[25, -1], 1, CBFuse, [[2]]], # 36# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 37# detect[[31, 34, 37, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)]
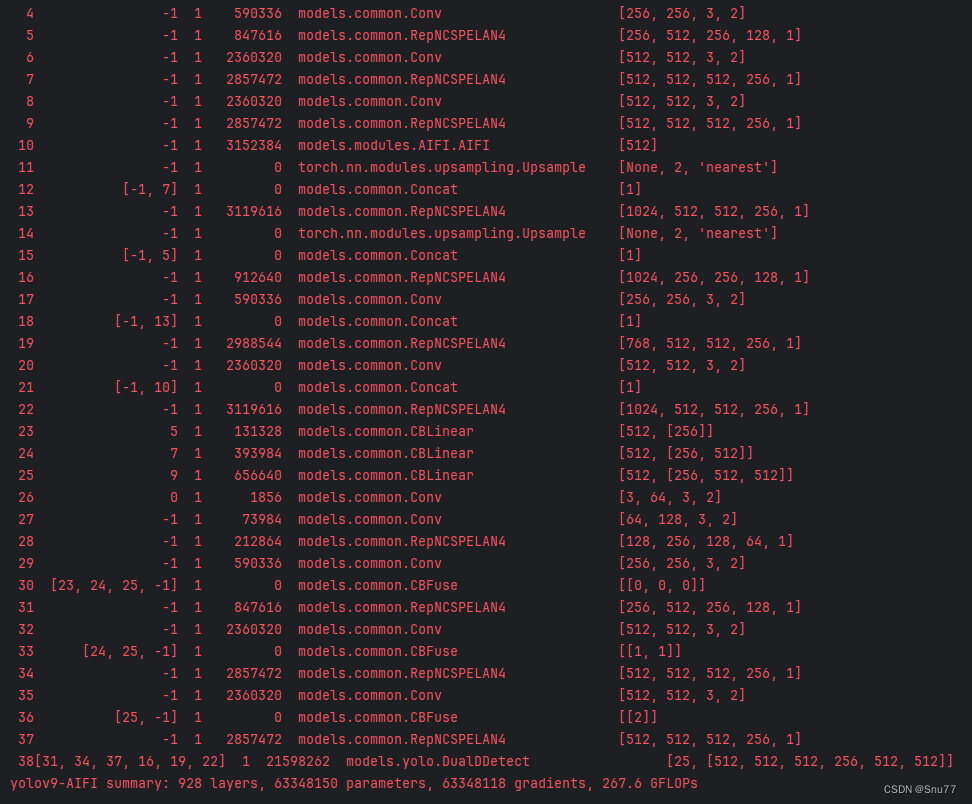
4.3 AIFI运行成功截图
附上我的运行记录确保我的教程是可用的。
五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv9改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏地址:YOLOv9有效涨点专栏-持续复现各种顶会内容-有效涨点-全网改进最全的专栏