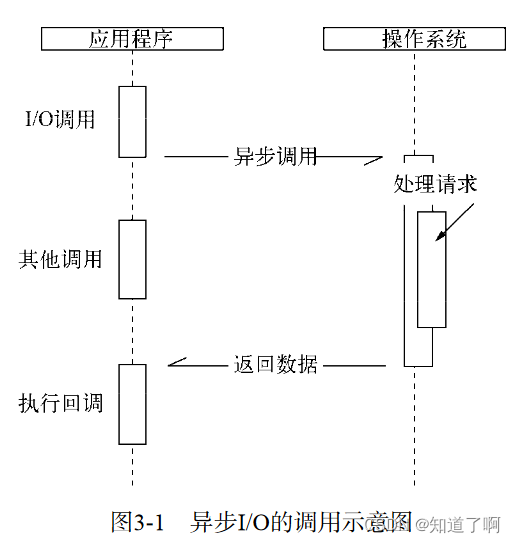
异步I/O
利用单线程,远离多线程死锁,状态同步等问题,利用异步I/O, 让单线程原理阻塞,更好的使用cpu
异步I/O实现现状
-
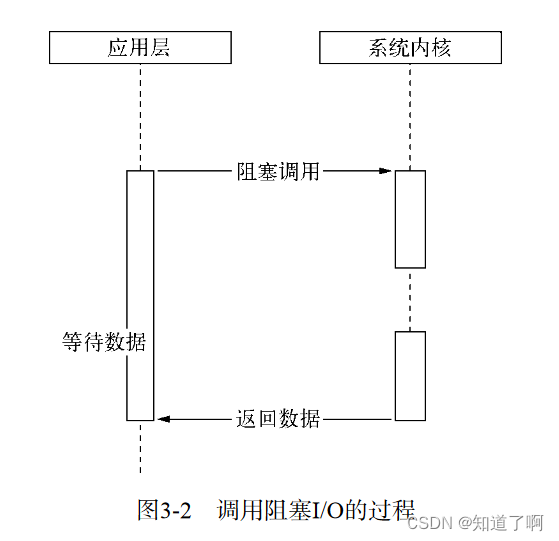
阻塞IO
操作系统内对于I/O只有两种方式: 阻塞和非阻塞。在调用阻塞I/O的时候,应用程序需要等待I/O完成之后才返回结构。
阻塞I/O的特点是调用之后等到系统内核层面完成所有操作之后,调用才结束。阻塞i/o造成CPU等待I/O,浪费等待事件,CPU的处理能力不能被充分利用
-
非阻塞I/O
操作系统对计算机进行了抽象,将所有的输入输出设备抽象为文件,内核在进行文件I/O的操作的时候,通过文件操作符进行管理,而文件描述符类似于引用程序和系统内核之间的凭证,应用程序如果需要对I/O进行调用,需要调用文件描述符。非阻塞I/O获取数据,不带数据进行返回,如果需要获取数据,需要调用文件操作符进行读取。为了获取完整的数据,引用程序需要重复调用I/O操作来确认是否完成。
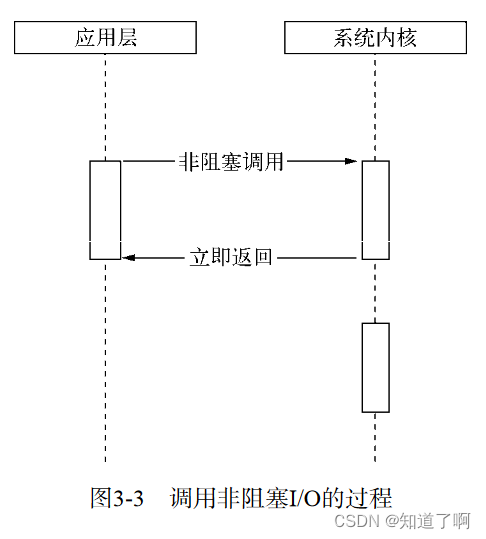
非阻塞I/O返回的后,CPU的时间片可以用来处理其他事务,
- 轮询
减少I/O状态判断的CPU损耗-
read 重复调用检查I/O的状态来完成数据的读取,在获得到最终的数据之前,cpu会一直耗用在等待上。
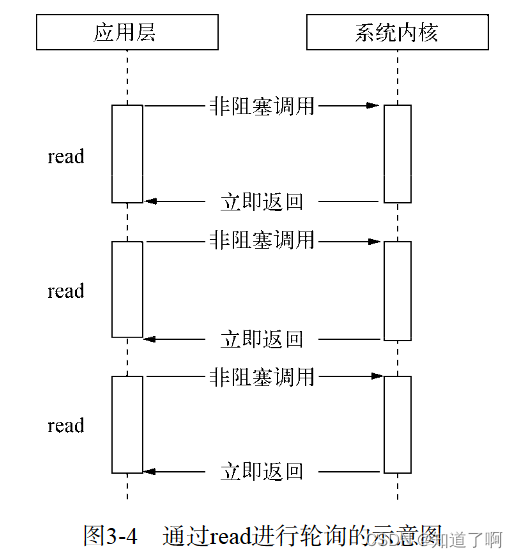
-
select 在read的基础上进行改进的一种方案,通过对文件描述符上的事件状态来判断。select轮询必须使用1024数组来存储状态。
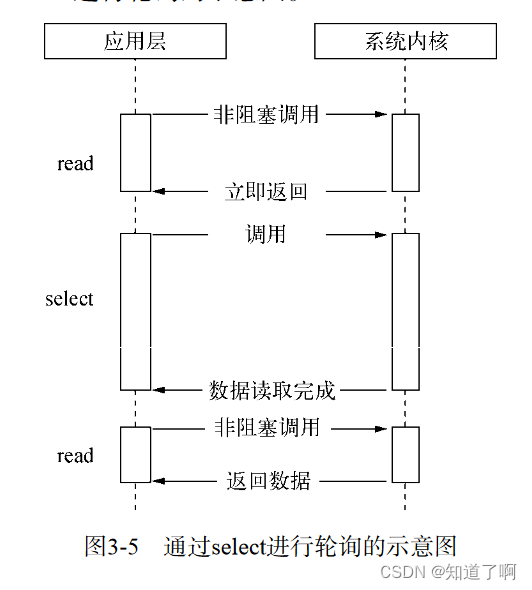
-
poll 使用链表的方式避免数组长度限制,其次避免不需要的检查。当文件操作符较多的时候,性能还是十分低下的。
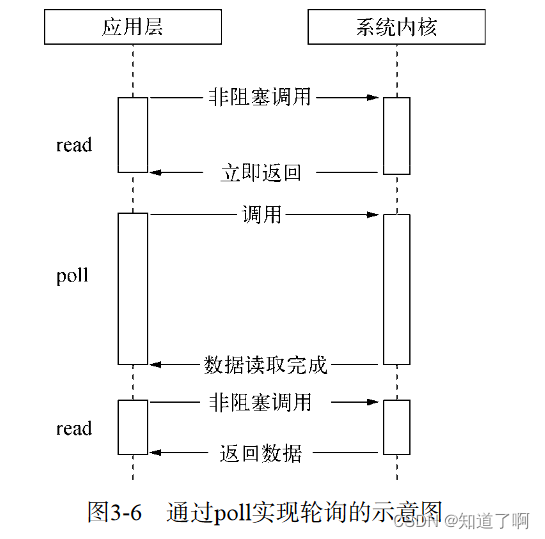
-
epoll linux下最高效率的I/O事件通知机制。进入轮询的时候,如果没有检查到的I/O事件。就会进行休眠,知道事件将它唤醒,利用事件通知,执行回调的方式,而不是遍历查询
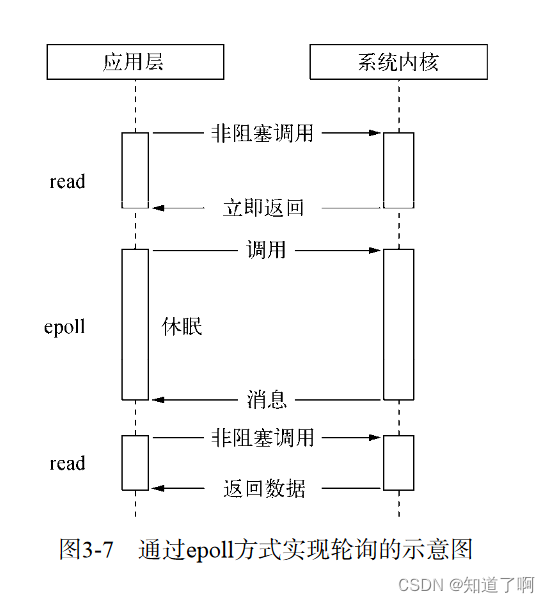
-
kqueue 仅仅在FreeBSD系统下运行,类似于epoll
-
- 轮询
-
异步I/O
Node在*nix平台下实现了libeio配合libev实现io部分。采用了线程池和阻塞I/O模拟异步。
在window利用IOCP
区别: node提供了libuv作为抽象封装层。是的所有的平台兼容性判断都有这一层来完成,保证上层的node和下层的自定义线程池之间独立。
在node是单线程,这里的单线程仅仅是JavaScript执行在单线程
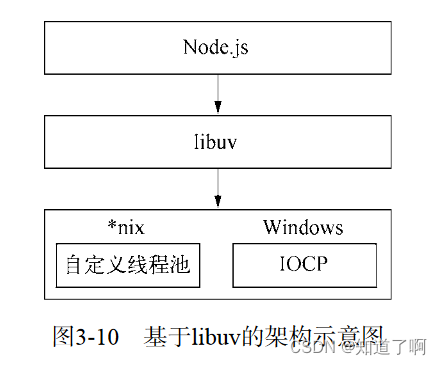
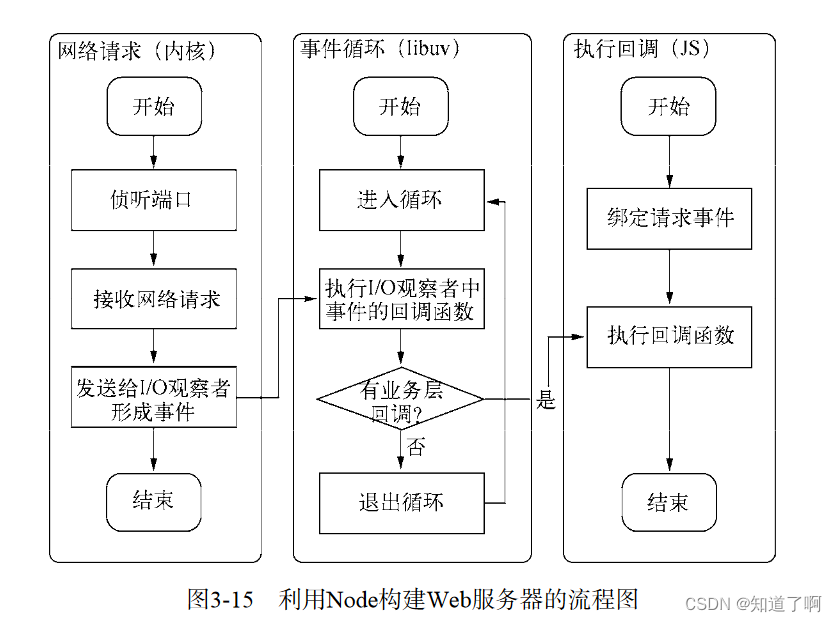
Node的异步I/O
- 事件循环
node自身的执行模型- 事件循环。在进程启动的时候,会创建一个while的循环,每执行一个循环体的过程称为tick,每个tick的过程就是查看是否有是事件待处理,如果有,就取出事件以及相关的回调函数。如果存在关联的回调函数。就执行。无的话,退出流程。
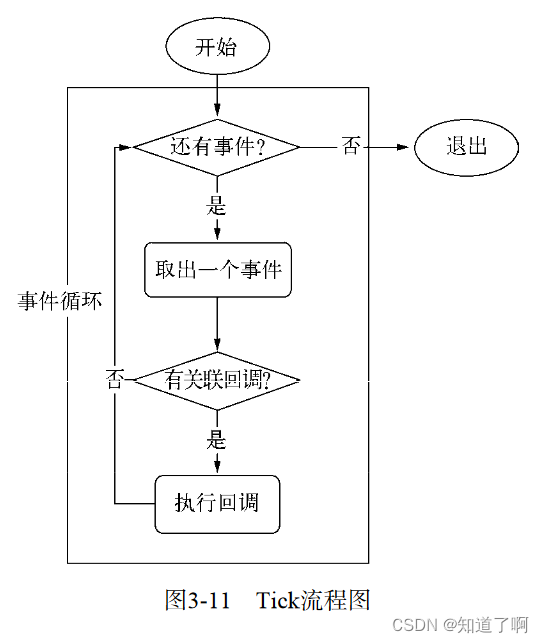
-
观察者
每个事件循环中有一个或者多个观察者,判断是否有事件要处理就是向观察者询问是否有要处理的事件。
node中,事件主要来源于网路请求,文件I/O, 这些事件对应的观察者都有文件I/O观察者,网络I/O观察者。
事件循环是一个生产者/消费者模型。生产者: 异步io,网络请求。事件传递到观察者,事件循环从观察者那边取出事件循环。 -
请求对象
fs.open = function(path, flags, mode, callback) { binding.open(pathModule._makeLong(path), stringToFlags(flags), mode, callback) }fs.open() 根据执行路径和参数打开一个文件,从而得到一个文件操作符,这是后续io操作的初始操作。
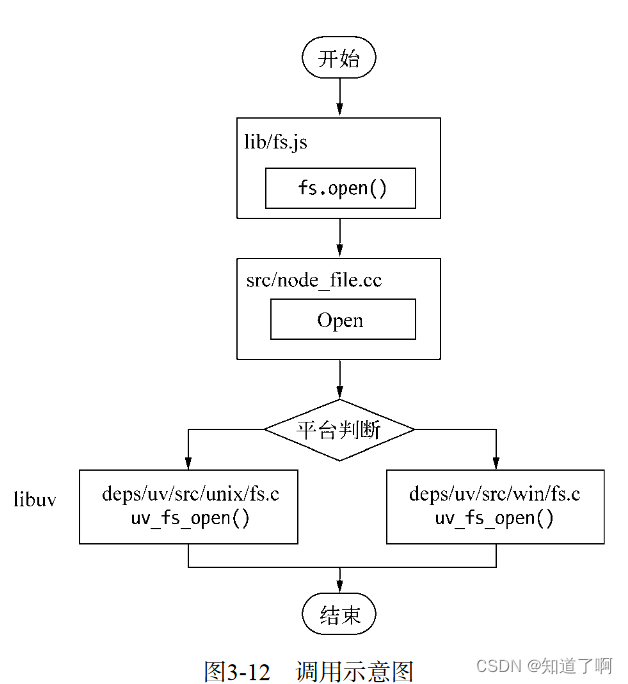
从JavaScript中调用node 的核心模块,核心模块中调用c++内建模块,内建模块通过libuv进行系统调用,这里的libuv作为封装层,有两个平台的实现,实际上是调用了uv_fs_open()的方法,在uv_fs_open()的调用过程中,创建了一个FSReqWrap请求对象,从JavaScript传入的参数和当前方法都被封装在这个请求对象中,最为关注的回调函数则被设置在这个对象的oncomplete_sym属性上。
- 请求对象是异步io中的重要中间产物,所有的状态都保存在这个对象中,包括送入线程和io操作完毕之后的回调处理
-
执行回调
组装好请求对象,送入io线程池等待执行, 实际上完成了异步io第一部分
线程池中的io操作调用完毕之后,会将获取的对象存储在req-result属性上。
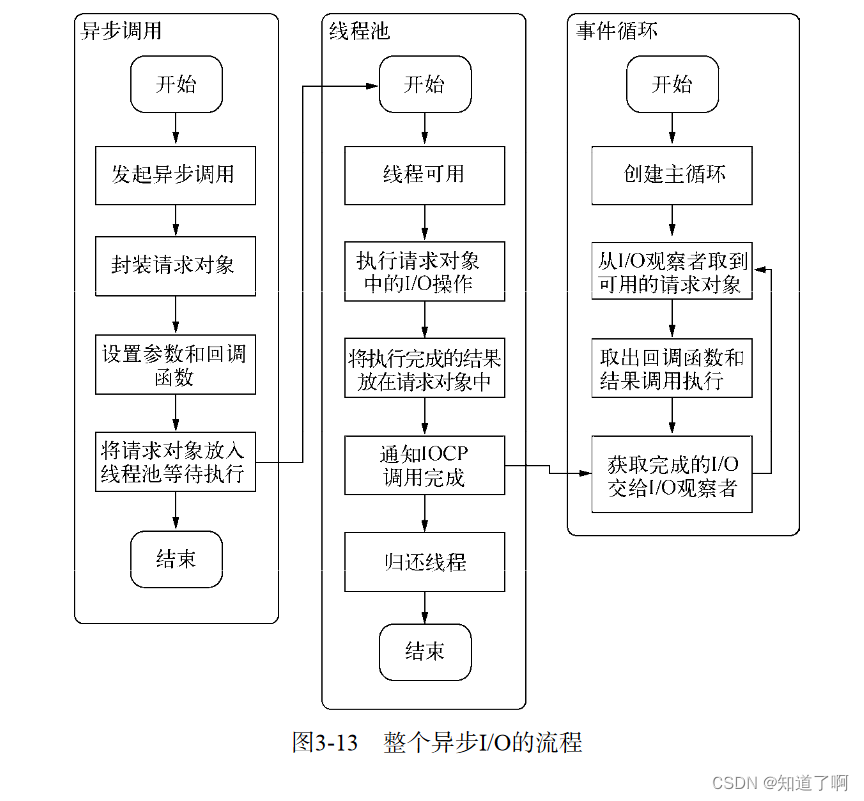
事件循环,观察者,请求对象,io线程池这四者共同构成了node异步io模型的四要素
非io的异步api
-
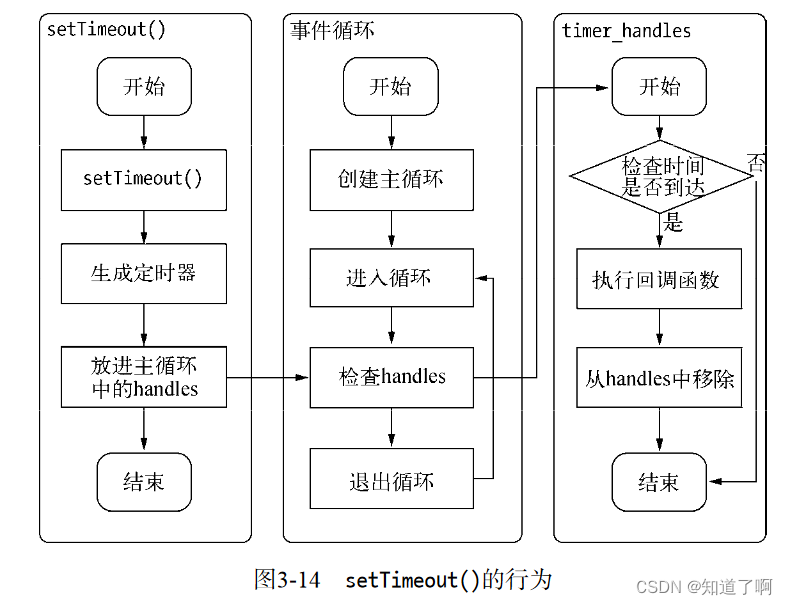
setTimeout() setInterval()
分别用于单次和多次定时执行任务。 实现的原理和异步io比较相似,只是不需要io线程池的参与。
调用setTimeout()和setInterval() 创建的迭代器会被插入到是定时器观察者内部的一个红黑树中,每次tick执行,会从该红黑树中迭代取出定时器对象,检查是否超过定时时间。如果超过就形成一个事件,回调函数会立即执行
定时器的问题在于,并非精确的在容忍事件范围内,尽管事件循环十分快,但是如果某次循环占用的时候过多,下次循环的时候,也会超时很久。
-
process.nextTick()
process.nextTick = function(callback) {if(process._exiting) return if(tickDepth >= process.maxTickDepth)maxTickWarn()var tock = { callback: callback } if (process.domain) tock.domain = process.domainnextTickQueue.push(tock)if (nextTickQueue.length) {process._needTickCallback()} } -
setImmediate()
setImmediate()和process.nextTick()方法十分类似,都是将回调函数延迟执行process.nextTick(function() {console.log("延迟执行") }) console.log("正常执行") // 正常执行 延迟执行setImmediate(function() {console.log('延迟执行') }) console.log("正常执行") // 正常执行 延迟执行process.nextTick(function () {console.log('nextTick延迟执行') }) setImmediate(function () {console.log('setImmediate延迟执行') }) console.log('正常执行') // 正常执行 // nextTick 延迟执行 // setImmediate 延迟执行process.nextTick()中的回调函数执行的优先级要高于setImmediate() 时间循环对于观察者的检查是由先后顺序的,process.nextTick()属于idle观察者。setImmediate()属于check观察者,在每一次循环检查中,idle观察者先于io观察者,io观察者先于check观察者、
process.nextTick() 的回调函数保存在一个数组中,setImmediate()的结果保存在链表中。process.nextTick()在每轮循环中会将数组中的回调函数全部执行完,setImmediate()在每轮循环中执行链表中的一个回调函数process.nextTick(function() {console.log('nextTick延迟执行1') }) process.nextTick(function()) {console.log('nextTick延迟执行2') } setImmediate(function() {console.log('setImmediate延迟执行1')process.nextTick(function () {console.log('强势插入')}) }) setImmediate(function() {console.log('setImmediate延迟执行2') }) console.log('正常执行') // 正常执行 // nextTick延迟执行1 // nextTick延迟执行2 // setImmediate延迟执行1 // 强势插入 // setImmediate延迟执行2