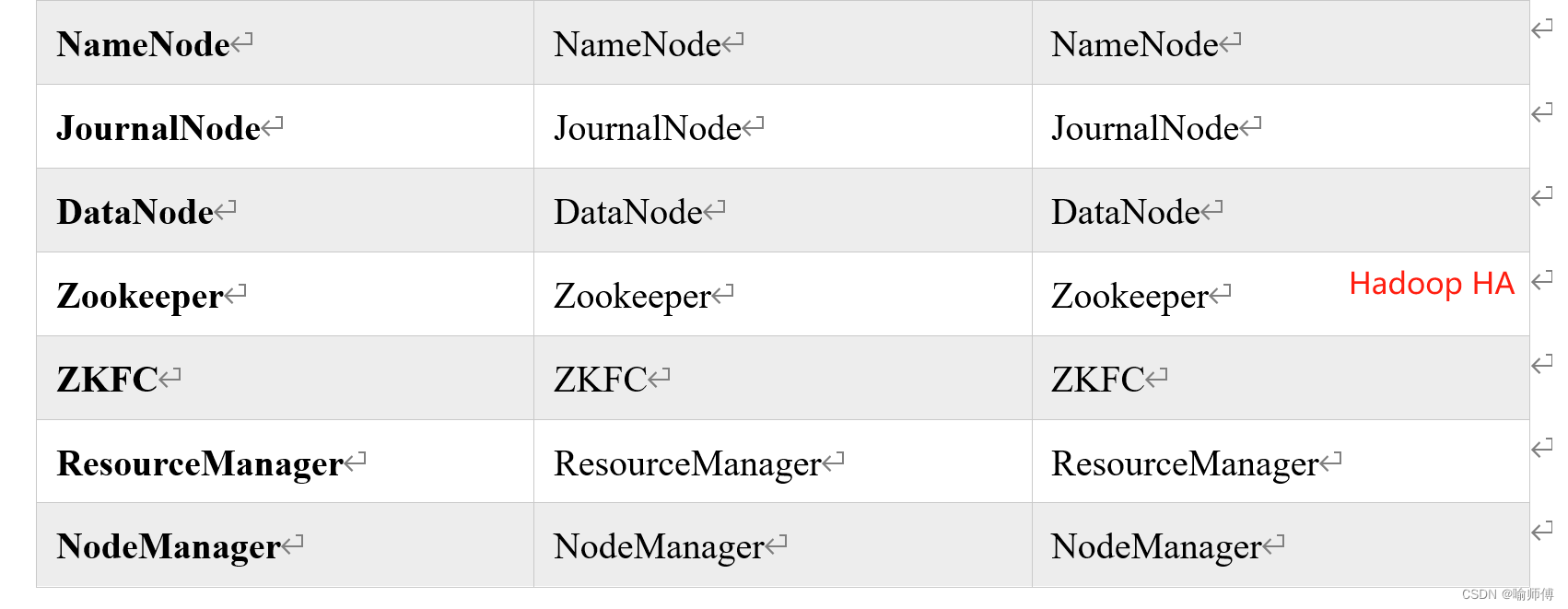
Hadoop HA(High Availability)
Hadoop 的高可用性,重点是确保存储(HDFS)和计算(YARN)资源在面对节点故障时能够继续正常运行。
1.概述
- 所谓HA(High Availablity),即高可用(7 * 24小时不中断服务)。
- 实现高可用最关键的策略是消除单点故障。
- HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
2.HDFS HA
HDFS(Hadoop 分布式文件系统)的高可用性,可以通过数据复制机制和HA NameNode(高可用性 NameNode)来实现。
1. 数据复制机制:
HDFS 采用了数据复制的策略来保证数据的高可用性和容错性。具体来说,它有以下特点:
-
数据块切分:HDFS 将文件切分成固定大小的数据块,通常默认大小为128 MB或更大。这样做的好处是可以更好地管理大文件,并允许并行处理和传输数据块。
-
数据复制:每个数据块都会被复制到集群中的多个节点上,通常默认情况下会复制到三个节点上。这些节点通常位于不同的机架上,以增加数据的冗余性和容错能力。
-
副本放置策略:HDFS 会尽量将数据块的副本分布在不同的机架上,以防止在机架级别发生故障时导致数据不可用。同时,HDFS 还会考虑节点的负载和网络拓扑结构来选择最佳的副本放置策略。
-
副本调度:当某个节点上的数据块副本发生故障或不可访问时,HDFS 会自动从其他节点上的副本进行读取,确保数据的可用性和一致性。
数据复制机制使得即使在节点发生故障时,数据仍然可以从其他节点上的副本读取,从而确保了数据的高可用性和容错性。
2. HA NameNode:
NameNode主要在以下两个方面影响HDFS集群:
(1)NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启。
(2)NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用。
在 Hadoop 2.x 版本中引入了高可用性 NameNode(HA NameNode)来解决单点故障问题。
HDFS HA功能通过配置多个NameNodes(Active/Standby)实现在集群中对NameNode的热备来解决上述问题。
如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
(1)多NameNode 架构:
- HA NameNode 由多个独立的 NameNode 组件组成,一个是活动的(Active NameNode),另一些是备份的(Standby NameNode)。
(2)ZooKeeper 协调:
- HA NameNode 使用 ZooKeeper 来协调和管理活动和备份 NameNode 之间的状态。
- ZooKeeper 是一个分布式协调服务,可以提供分布式应用程序的一致性、可靠性和容错性。
(3)自动故障转移:
- 只有活动 NameNode 才能处理客户端的文件系统操作请求。
- 备份 NameNode 处于待命状态,并监视活动 NameNode 的状态。
- 如果活动 NameNode 发生故障或失去联系,备份 NameNode 将自动接管工作,并成为新的活动 NameNode,从而实现了故障转移和高可用性。
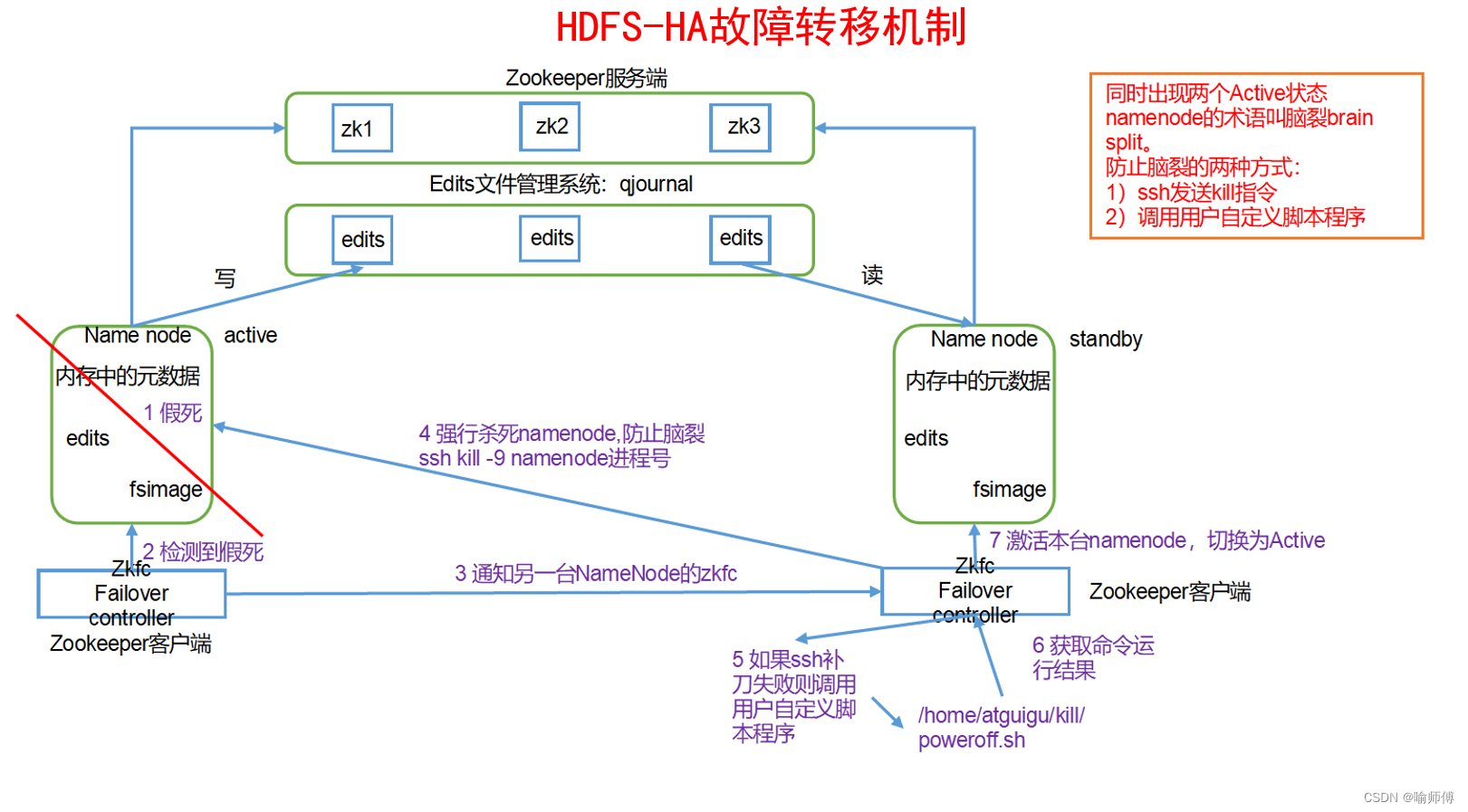
通过 HA NameNode,HDFS 在面对 NameNode 单点故障时能够实现快速的故障转移和恢复,从而确保了文件系统的高可用性和可靠性。
Tips:
(1)怎么保证多台namenode的数据一致?
- Fsimage:让一台namenode生成数据,让其他机器namenode同步。
- Edits:需要引进新的模块JournalNode来保证edtis的文件的数据一致性。
(2)怎么让同时只有一台nn是active,其他所有是standby的?
- Zookeeper居中协调,选举active
(3)2nn在ha架构中并不存在,定期合并fsimage和edtis的活谁来干?
- 由standby的namenode来干
(4)如果namenode真的发生了问题,怎么让其他的namenode上位干活?
- 自动故障转移
3.Yarn HA
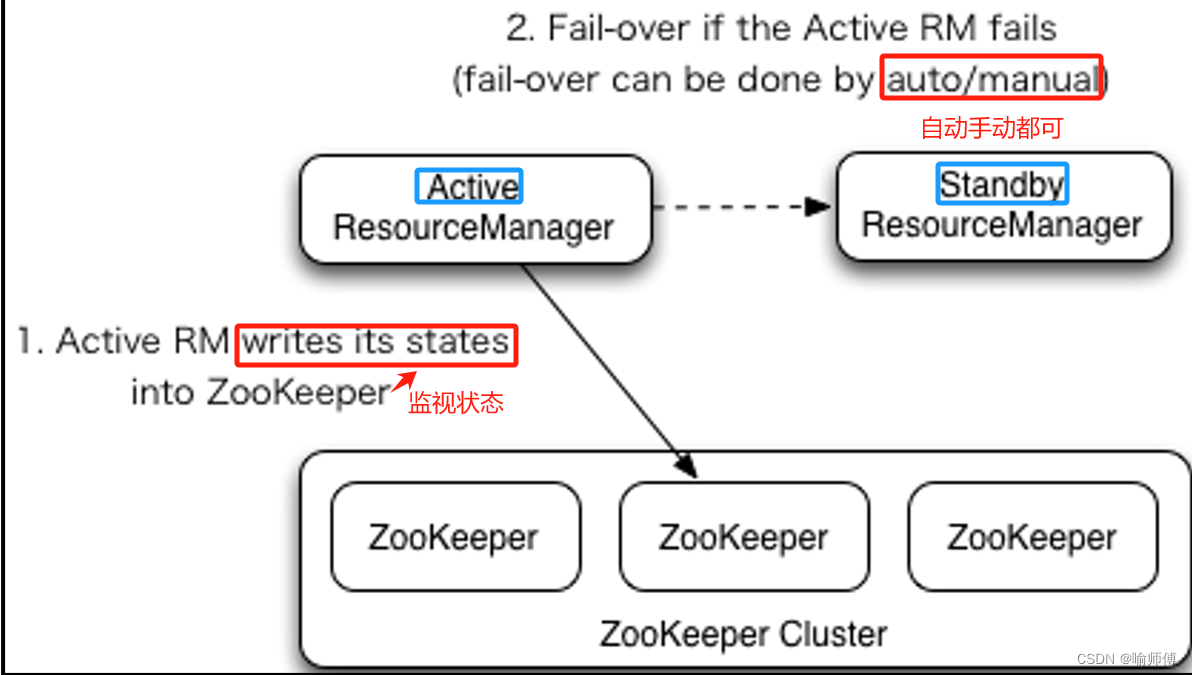
1. ResourceManager 高可用性:
ResourceManager(RM)是 YARN 的核心组件之一,**负责整个集群资源的管理和分配。**为了提高 ResourceManager 的可用性,可以采用以下方法:
(1)ResourceManager HA(RM HA):
- 类似于 HA NameNode,RM HA 也采用了主备模式来确保 ResourceManager 的高可用性。
- 主备 ResourceManager 分别运行在不同的节点上,其中一个是活动的(Active RM),另一个是备份的(Standby RM)。
(2)ZooKeeper 协调:
- RM HA 需要依赖 ZooKeeper 进行状态协调和故障检测。
- ZooKeeper 负责监视活动和备份 ResourceManager 的状态,并在主节点失效时触发故障转移。
(3)自动故障转移:
- 如果活动的 ResourceManager 发生故障或失去联系,ZooKeeper 会自动触发备份 ResourceManager 成为新的活动 ResourceManager,从而实现快速的故障转移。

2. NodeManager 高可用性:
NodeManager(NM)是 YARN 的另一个重要组件,负责在每个节点上管理资源和执行作业。为了提高 NodeManager 的可用性,可以采用以下方法:
(1)NodeManager 多实例:
-
可以在每个节点上运行多个 NodeManager 实例,这样即使一个 NodeManager 实例发生故障,其他实例仍然可以继续管理资源和执行任务。
-
监控和自愈:通过监控 NodeManager 运行状态和资源利用情况,及时发现故障并进行自动恢复,以确保节点资源的可用性和高效利用。
Tips:
(1)如果当前active RM挂了,怎么将其他standby RM上位
- 核心原理跟HDFS一样,利用了zk的临时节点。
(2)当前rm上有很多的计算程序在等待运行,其他的rm怎么将这些程序接手过来接着跑
- rm会将当前的所有计算程序的状态存储在zk中,其他rm上位后会去读取,然后接着跑。