2023 neurips
完全是零样本(zero-shot)的,不需要微调
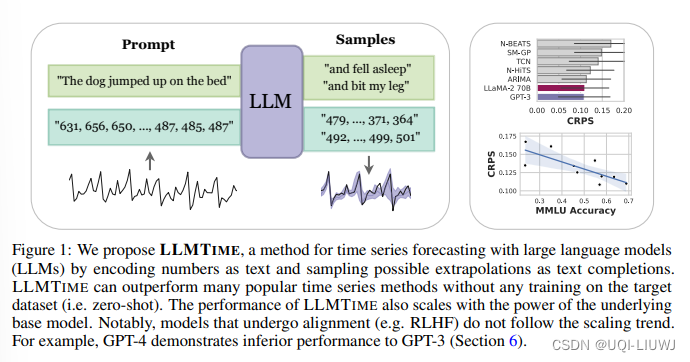
1 方法
1.1 Tokenization(分词和编码)
- 现有的LLM(比如GPT3)的tokenizer不能直接用来编码时间序列的句子
- 比如对数字42235630,tokenizer处理之后为三个token:[422,35,630]
- 如果数字中某一位改变了,那tokenizer后的token可能完全不一样。
- ——>论文为时间序列提出了特殊的tokenization方式
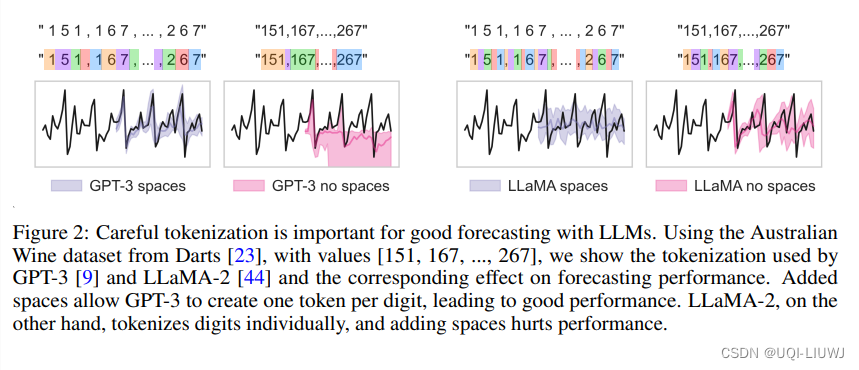
- 对于GPT3来说,给数的每位之间加上空格,效果要比不加空格要好。
- 对于LLaMA来说,它本身的tokenizer就已经会把每位数当成一个token,因此无需再加空格,加了反而损害性能。、
1.2 minmaxscaler
- 时间序列数值有可能非常大,要覆盖那么多数值需要很多的token。
- 因此,在输入之前,会用MinMaxScaler将数值进行缩放,限制数值的范围
1.3 Forecasting
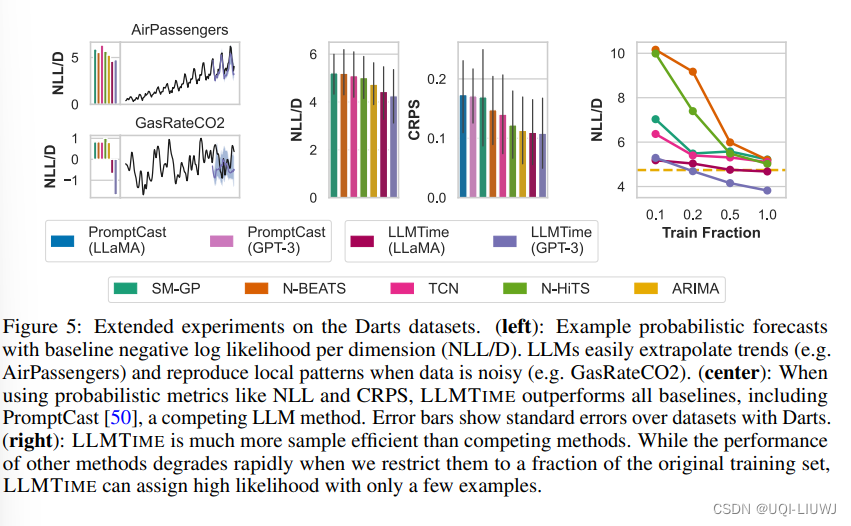
在每次预测时,都会多次实验采样很多组预测值,这么多组的预测值的中位数或均值可以作为点预测的结果,使结果更加鲁棒
1.4 为什么LLM能做序列预测
- 这是因为序列预测本质上就是对未来值的条件分布进行建模,简单的RNN都能拟合复杂的数字数据分布,更何况LLM
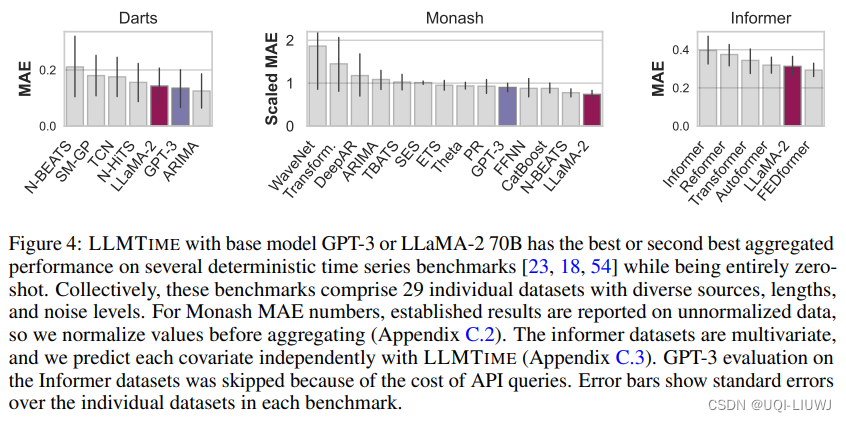
2 实验