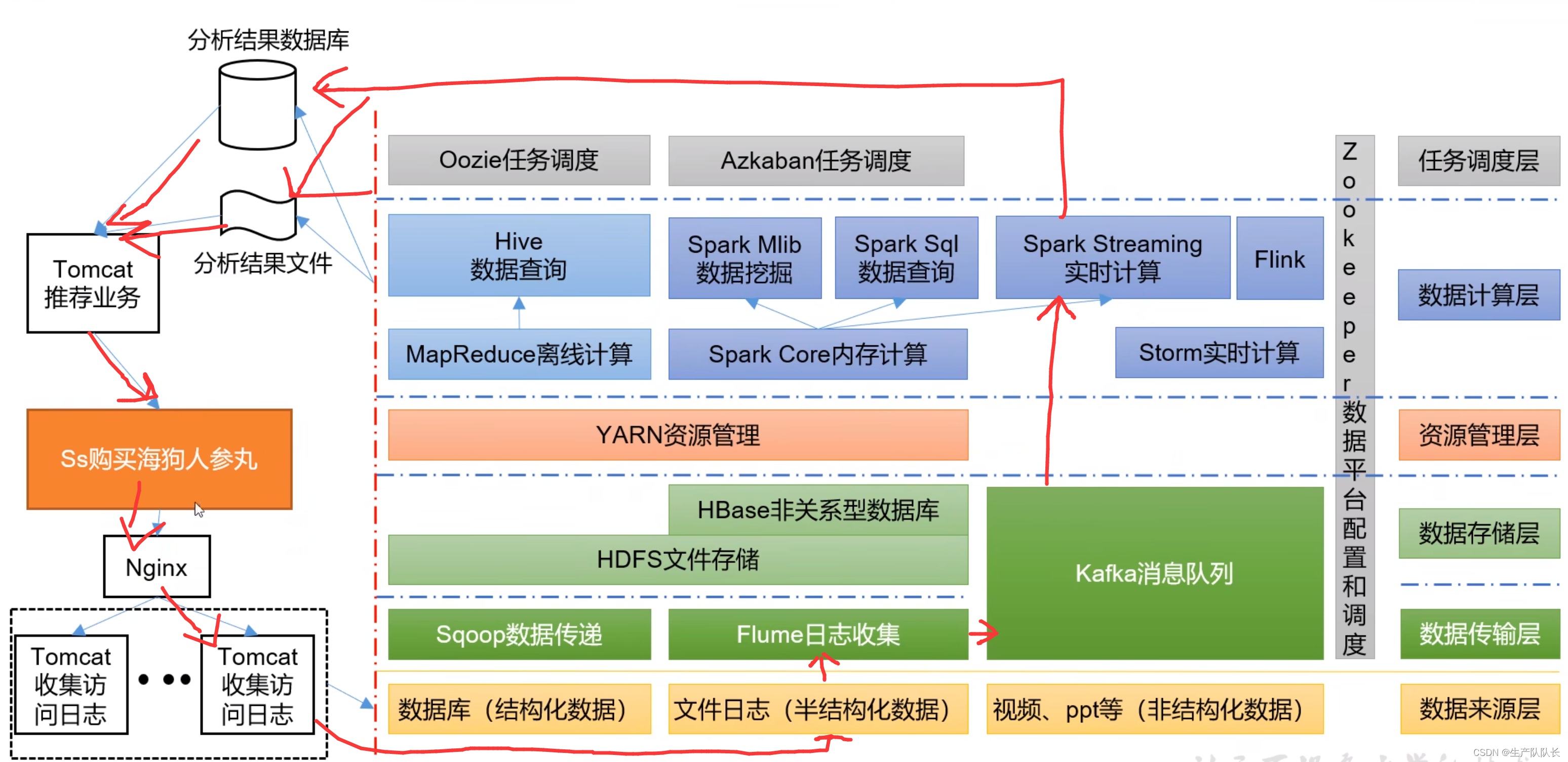
1、select语句
select colums from table_name2、条件语句

#查询出查询出用户id为1和3的用户记录 IN 操作符允许我们在 WHERE 子句中规定多个值。
select * from student where id in (1,3)
#查询出所有姓王的同学 模糊查询 like 通配符(% 任意多个字符 _单个字符)
#下例中的'王%'将相当于'王xxxx',也可能是'王x',但不可能是'x王'
SELECT * FROM student WHERE name like '王%';
#查询姓王且名字只有两个字的学生,此时就只能是'王x'
SELECT * FROM student WHERE name like '王_';
#查询出所有含有花子的同学的名称,此时就可以随意,只要带'花'就可以
SELECT * FR OM student WHERE name like '%花%';3、聚合函数

#求学生年龄的总和
select sum(age) from student;
#查询所有的学生数量
SELECT count(*) from student;
#查询出班级号不为空的学生数
SELECT count(class_num) from student注意,count(*)表示取得当前查询表所有记录 ,同时count(字段名称),不会统计为null的记录
4、分组查询 grounp by
作用:通过哪个字段(或哪些)字段来分组
#查询出各个班年龄的最大值,以班级号来分组
SELECT max(age),class_num from student GROUP BY class_num
#求每个班的平均年龄,以班级号来分组
SELECT avg(age),class_num from student GROUP BY class_num5、排序 order by
#按照年龄从低到高进行排序:
SELECT * FROM student ORDER BY age;
#默认的排序规则是ASC:“升序”,即从小到大。ASC可以省略,即ORDER BY score ASC和ORDER BY score效果一样。
#如果要反过来,按照年龄从高到底排序,我们可以加上DESC表示“倒序”:
SELECT * FROM student ORDER BY age DESC;
#如果想按照年龄降序,并且按照学号升序怎么弄?
SELECT * FROM student ORDER BY age DESC,sno;6、分页查询(限制查询)
使用SELECT查询时,如果结果集数据量很大,比如几万行数据,放在一个页面显示的话数据量太大,不如分页显示,每次显示100条。
要实现分页功能,实际上就是从结果集中显示第1~100条记录作为第1页,显示第101~200条记录作为第2页,以此类推。
因此,分页实际上就是从结果集中“截取”出第M~N条记录。这个查询可以通过LIMIT OFFSET 子句实现。我们先把所有学生按照成绩从高到低进行排序:
现在,我们把结果集分页,每页3条记录。要获取第1页的记录,可以使用LIMIT 3 OFFSET 0:
SELECT * FROM student LIMIT 3 OFFSET 0;上述查询LIMIT 3 OFFSET 0表示,对结果集从0号记录开始,最多取3条。注意SQL记录集的索引从0开始。
#如果要查询第2页,那么我们只需要“跳过”头3条记录,也就是对结果集从3号记录开始查询,把OFFSET设定为3:
SELECT * FROM student LIMIT 3 OFFSET 3;可见,分页查询的关键在于,首先要确定每页需要显示的结果数量pageSize(这里是3),然后根据当前页的索引pageIndex(从1开始),确定LIMIT和OFFSET应该设定的值:
LIMIT总是设定为pageSize
OFFSET计算公式为pageSize * (pageIndex - 1)
7、联表查询
SQL92语法 select xxx from A 表名,B表名 where 表连接条件 and 数据查询条件;
SELECT s.name,c.class_name from student s,class c where s.class_num = c.class_num缺点:表连接条件与查询条件放在一起,没有分离
SQL99语法 select xxx from A 表名 join B 表名 on 表的连接条件;
select student.name,class.class_name from student join class on student.class_num = class.class_num;优点:表连接独立,结构清晰,如果结果数据不满足要求,可再追加where条件进行过滤;
内连接 inner join
用于根据两个或多个表之间的共同字段将表组合在一起,两个表都要有的数据才能展现
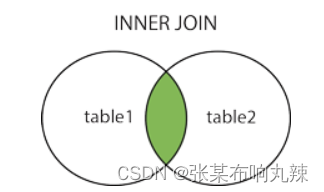
#取两个表都有的数据
SELECT student.name,class.class_name from student
INNER JOIN class on student.class_num = class.class_num;左外连接 Right join
包含左边表的全部行(不管右边的表中是否存在与他们匹配的行),以及右边表中全部匹配的行。
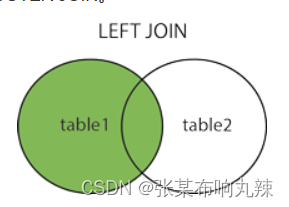
#以左表为基础
SELECT student.name,class.class_name from student
LEFT JOIN class on student.class_num = class.class_num;右外连接 Left join
包含右边表的全部行(不管右边的表中是否存在与他们匹配的行),以及左边表中全部匹配的行。
#以右表为基础
SELECT student.name,class.class_name from student
RIGHT JOIN class on student.class_num = class.class_num;8、嵌套查询
一般在子查询中,程序先运行在嵌套在最内层的语句,再运行外层。因此在写子查询语句时,可以先测试下内层的子查询语句是否输出了想要的内容,再一层层往外测试,增加子查询正确率。否则多层的嵌套使语句可读性很低。
关于嵌套查询,都是从最内层开始的
#找到所有选选择课程号为1001的同学的名称
select t1.name FROM
(SELECT student.name,relationship.cno FROM student
INNER JOIN relationship on student.sno = relationship.sno) t1
WHERE t1.cno = '1001';#找到所有选选择课程号为 数学 的同学的名称
SELECT t2.name FROM
(select t1.name,course.gradeName from
(SELECT student.name,relationship.cno FROM student INNER JOIN relationship on student.sno = relationship.sno) t1INNER JOIN course on t1.cno = course.cno) t2where gradeName = '数学';