前言
日常在校生或者是工作之余的同学或多或少都会参加一些竞赛,参加竞赛一方面可以锻炼自己的理解与实践能力,也能够增加自己的生活费,竞赛中的一些方案也可以后续作为自己论文的base,甚至是横向课题的框架。在算法竞赛中算法的差别个人感觉差距都不大,主要的差别点就是数据处理方式、数据特征的处理,数据特征与结果直接挂钩。
内容
本科或者是刚读研的学生除了kaggle等这些知名的竞赛平台,可以从一些小的平台开始。个人推荐两个平台,里面的项目与一些解决方案,多少都会对自己有益,本人之前看了一个多模态融合的方法就结合实际项目做出了不错的效果。
平台介绍
1、DLab教学与实训平台

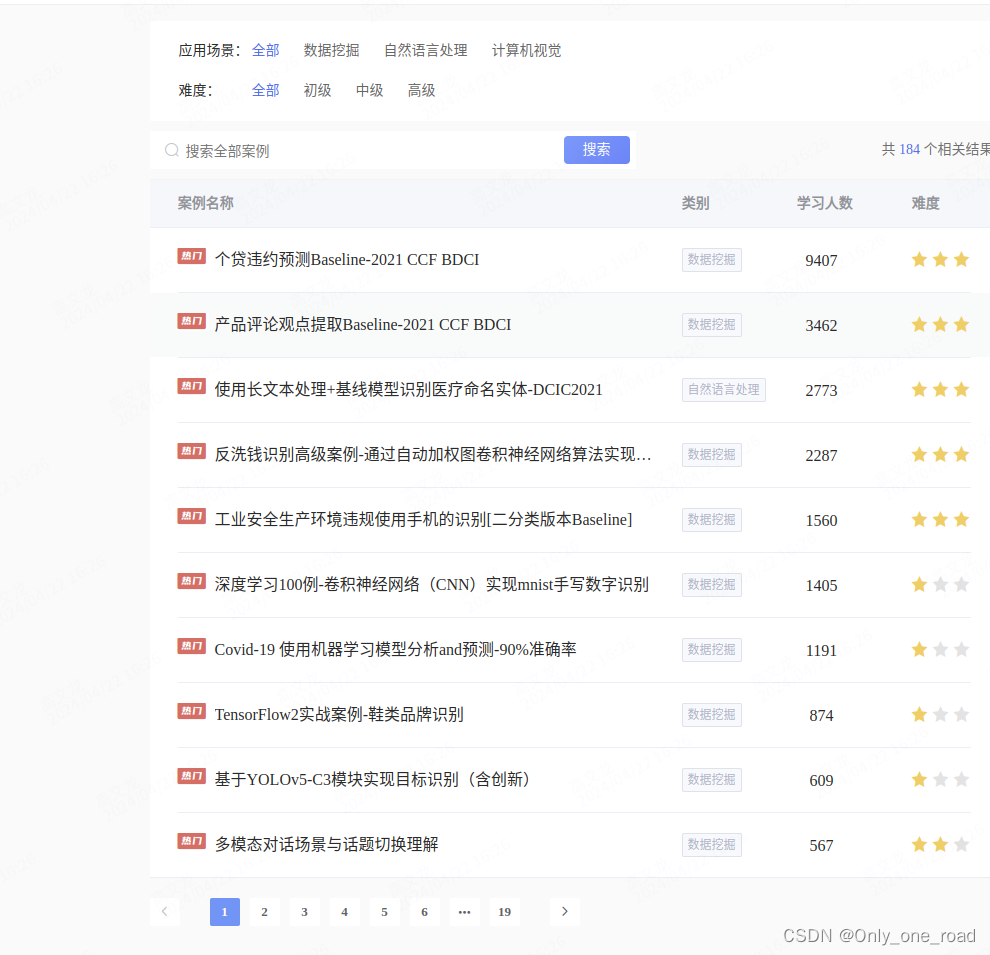
可以看到里面涉及的模块还是挺丰富的,包含视觉、NLP等,另外一些可以瓜分的较大额度奖金,并且很多项目来自企业或者事业的实际业务,在后续的简历中也可以自己的项目,除此之外还有学习圈可以看一些优秀的项目与解决方案。
2、FlyAI-AI竞赛服务平台

内容小结
1)、进行数据分析时,首先要看的就是数据的分布情况,看每个类别的分布是否是均衡,其次对于文本的长度进行统计,比如平均长度,这样在选取数据长度的时可以选取平均长度亦或者是略大于平均长度。
2)、针对于样本分布如果是样本分布不均衡,可这对于样本不均衡作出相应的调整。首先是欠采样或者是过采样。对于样本比较多的进行欠采样,样本比较少的进行过采样。欠采样:删除掉一些文本(对一些不重要文本进行剔除)
常见的文本增强有:
- 句子的随机打乱(随机打乱句子)
- (噪声的加入):在正例中加入一些噪声词,或随机剔除一些词
- 对长文本进行处理(裁剪掉长文本的某一句,比如开头句或结尾句)
- copy复制
- paraphrasing,用序列到序列的方式去生成,在问答系统有一个领域叫做问题复述,根据原始问题生成格式更好的问题,相当于修正不规范的问题,将新问题代替旧问题输入到问答系统中
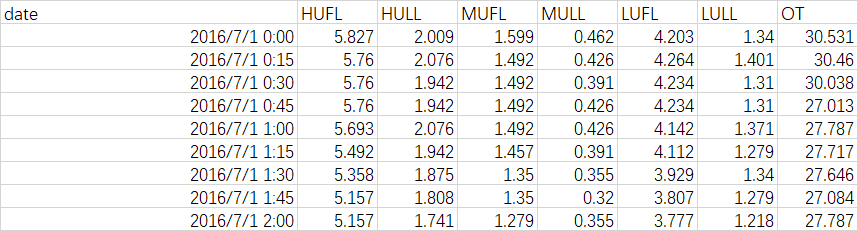
数据分析是首要选择,句子的长度,分类的话包含类别的分布情况。如下所示进行相关统计。

相比没有进行统计的结果,最初数据的分布如下所示:


对数据的分布进行初步的分析发现,数据分布存在很大的问题,可以看出很明显的问题就是数据不均衡,尤其对于分类任务来说,数据量分布最大与最小的差别有上万条,最终会影响最后的结果。
预处理部分:
随机shuffle后以9:1的比例划分线下验证集和训练集,防止数据周期的影响,其次对于不同长度的数据选择合适的长度,可以根据数据分布去中间值,又或比中间值略大的部分。进行对于数据长尾部分的处理,可以采用变换的方式对数据的标签进行转换,(Datawhale 零基础入门数据挖掘-Task4 建模调参-天池实验室-阿里云天池 https://tianchi.aliyun.com/notebook-ai/detail?spm=5176.12586969.1002.18.1cd8593aw4bbL5&postId=95460)

在这里对标签进行了 变换,使标签贴近于正态分布.
train_y_ln = np.log(train_y + 1)
模型融合(Datawhale 零基础入门数据挖掘-Task5 模型融合_天池notebook-阿里云天池)
- 简单加权融合,如回归(分类概率):算术平均融合(Arithmetic mean),几何平均融合(Geometric mean);分类:投票(Voting)综合:排序融合(Rank averaging),log融合
- stacking/blending:构建多层模型,并利用预测结果再拟合预测。
- boosting/bagging(在xgboost,Adaboost,GBDT中已经用到):多树的提升方法
对于样本不平衡常采用focal loss加上f1-score 组成新的损失函数
组成新的损失函数:
具体的代码如下所示:
# focal loss code from https://github.com/umbertogriffo/focal-loss-keras/blob/master/losses.py
# f1 loss code from https://www.kaggle.com/rejpalcz/best-loss-function-for-f1-score-metricdef focal_loss(y_true, y_pred):gamma=2.alpha=.25 # Scale predictions so that the class probas of each sample sum to 1y_pred /= K.sum(y_pred, axis=-1, keepdims=True) # Clip the prediction value to prevent NaN's and Inf'sepsilon = K.epsilon()y_pred = K.clip(y_pred, epsilon, 1. - epsilon)# Calculate Cross Entropycross_entropy = -y_true * K.log(y_pred)# Calculate Focal Lossloss = alpha * K.pow(1 - y_pred, gamma) * cross_entropy# Compute mean loss in mini_batchreturn K.mean(loss, axis=1)def focal_f1_loss(y_true, y_pred):tp = K.sum(K.cast(y_true*y_pred, 'float'), axis=0)tn = K.sum(K.cast((1-y_true)*(1-y_pred), 'float'), axis=0)fp = K.sum(K.cast((1-y_true)*y_pred, 'float'), axis=0)fn = K.sum(K.cast(y_true*(1-y_pred), 'float'), axis=0)p = tp / (tp + fp + K.epsilon())r = tp / (tp + fn + K.epsilon())f1 = 2*p*r / (p+r+K.epsilon())alpha = 0.001return alpha * (1 - K.mean(f1)) + focal_loss(y_true, y_pred)参考:
2017知乎看山杯 从入门到第二 - 知乎