本文作者:仟传网络科技技术专家 刘贵宗 & 肖旺生
一、业务需求及选型背景
仟传网络科技(TargetSocial),是国内知名的内容社交平台整合营销服务商,为企业级客户提供高效的KOL(关键意见领袖)和公/私域流量管理方案。公司旗下拥有四大核心业务,包括企微生态、品牌私域、社媒采买以及抖音生态,这些业务分别由企微SCRM系统、会员营销管理系统、社媒KOL智能采买系统以及抖音SCRM整合运营平台等自主研发的系统支撑。致力于为广告主打造一个覆盖传播、投放、监测、评估等全链路的立体内容生态,从而创造更具价值的营销服务。
由于其业务场景丰富,涉及客户管理、用户行为分析、标签管理、粉丝管理、互动管理、素材管理、私域流量和员工管理、内容精准推送、裂变传播和传播效果监测、热点监测、品牌舆情监测、线上商城等诸多领域,仟传对数据处理产品的支撑能力要求灵活、精细、快速。为了满足业务发展对数据处理能力的不断增长,仟传网络科技对其 KV 方案进行了升级,从 HBase 迁移至 OceanBase。
本文将分享仟传 KV 方案从 HBase 升级为基于 OceanBase 的 OBKV 实践经验。
为了满足业务发展需求,我们在技术层面对新的数据库方案提出了以下 6 点关键需求:
- 支持动态 Schema:在我们的场景中,字段数量可能会频繁变更,传统关系型数据库采用固定 Schema 的方式无法适合我们的需求,因此业务要求存储方案必须支持动态 Schema,能够随业务需要动态增减字段。
- 支持部分列更新:一条数据可能拥有上百个字段,我们希望能够便捷地更新其中的一部分字段,所以要求数据操作的粒度能够细化到字段级。
- 单表支持千亿级记录存储:在存储能力方面,我们需要单表支持千亿级别的记录行存储。
- 支持数据高速摄入:数据可快速灌入数据库,避免上游数据陡增导致数据流积压的情况。
- 毫秒级点查响应:我们的 KV 应用于点查场景,要求点查一条完整的业务数据的响应时间在几十毫秒以内。我们希望数据库做到 5 毫秒内响应点查需求,即便在集群高负载下,也能够保持快速响应,即短时间内要点查 1000 万个 ID。
- 单字段大小支持 1MB:由于业务数据中可能存在超长文本,因此我们需要单字段存储支持 1MB 大小。
根据上述需求,我们对比了 Doris、HBase、OceanBase。然而,由于 Doris 在执行部分列更新时会消耗大量 CPU 资源,且重复数据多次热点写入时存在性能缺陷,与我们的场景明显不匹配,因此没有对 Doris 进行更深入的调研。以下是 HBase、OceanBase 在性能、部署、运维、架构以及数据分布方面进行对比分析。

经过综合评估,我们最终选择了OceanBase 作为其 KV 方案的数据库,选择 OceanBase 的主要原因如下。
- 成本更低:存储资源消耗小,基于 zone 实现 3 副本冗余,保证数据可靠性,存储资源消耗更小,相于 HBase 更具成本优势。
- 运维简单:OcenBase 提供丰富的文档及界面化操作工具,部署、运维更简单,减轻了运维负担。
- 部分列更新性能更优:正常的 put 操作即支持部分列更新,对性能消耗较小,满足了业务对数据操作灵活性的要求。
- 热点数据写入性能更佳:通过对时间戳字段的设计、数据去重、TTL 以及不同粒度的合并等操作,可避免重复数据多次写入时的性能问题,保证了数据写入的流畅性。
- 数据分布均匀:数据均匀分布在各分区上,分区均匀分布在各 OBServer上,保证各 OBServer 上的数据分布是均衡的,提升了系统的稳定性和性能。
很多时候大家把 OceanBase 作为一个关系型数据库来使用,中间层有 OBSQL,上层有 JDBC,从客户端做一整套从前到后的调用。然后,实际上 OceanBase 分为多个层次,如下图所示:
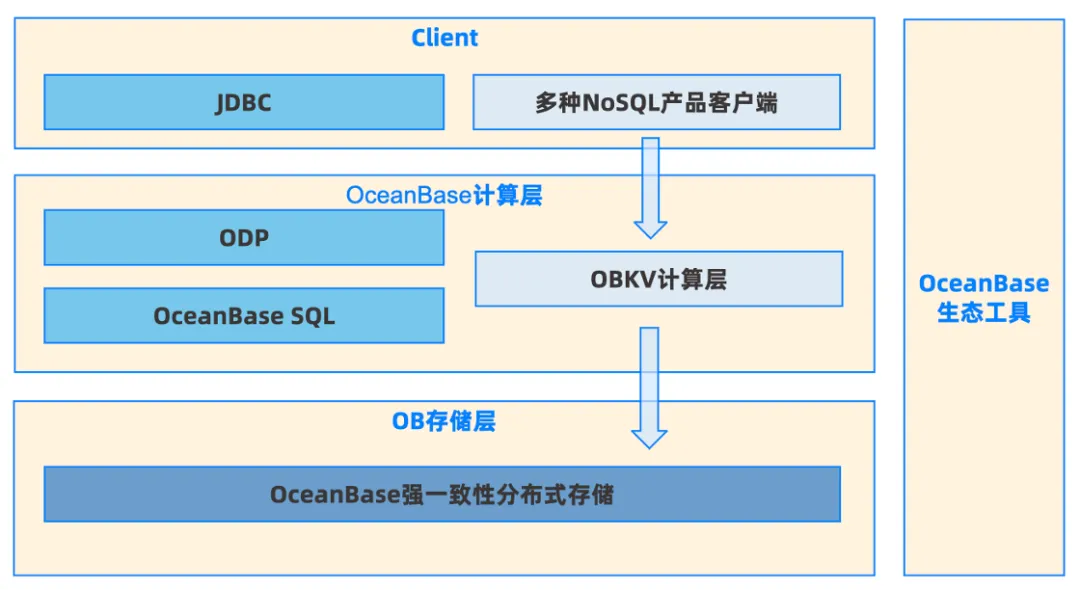
在这种架构下,底层的 OBKV 和 OBSQL 共享一个 OceanBase 强一致性分布式存储,同时分别通过独立的客户端及计算层进行通信,这种独特架构赋予了 OceanBase 以下 5 个显著优势。
- 多模融合:通过一套数据库管理多种模型数据(OBKV & OBSQL)。
- 运维视图统一:共享一套完备的数据库运维工具(OCP、ODC、OMS等)。
- 完备的容灾方案:支持单 Zone 或跨 Zone 容灾,并提供主备库容灾能力。
- 资源隔离:支持原生多租户,提高资源利用率。
- 高级特性:包括安全加密、回收站、冷热数据分离、备份恢复等功能。
值得一提的是,OceanBase 的 OBKV 具有两类产品能力,原生OBKV和兼容HBase 的 OBKV。

原生 OBKV 支持直接调用 OBKV 提供的 API,直接访问存储事务层,非常的简洁易用。这种情况下,时延很低,吞吐量很高,主要适用于给开源及自研计算层提供高可靠、可扩展的强一致性存储引擎。兼容 HBase 版本的 OBKV 则更适合专注于上层业务的场景,可以将 OBKV 作为工具使用,不仅兼容 HBase 协议和模型,还具备相比 HBase 更高的性能、更稳定的存储、更平滑的时延、更易用&完备的运维工具,是替代开源 HBase 的理想选择。
二、OceanBase在测试和生产环境的性能表现
以下是我们对 OceanBase 在测试环境和生产环境的性能观测情况进行的详细分析。
在测试环境,我们使用 OceanBas 4.2.1 版本,部署了 2-2-2 集群架构,其中包含3个 Zone。每个 Zone 里放置了 2 台配置为 80 核 256GB 的机器,日志盘为 1TB 的 NVME SSD 盘,三块盘组成 Raid 0,总存储空间是 21TB,由于整个集群只面向一个业务,因此只创建了一个 64 核 180GB 的业务租户。
下面两张图分别展示了测试阶段读性能和写性能的表现。总体而言,TPS 可以稳定在每秒 6 万左右,事务响应时间维持在 2~4 毫秒之间,大多数时间响应速度为 2 毫秒。可见,测试阶段的性能表现非常出色。
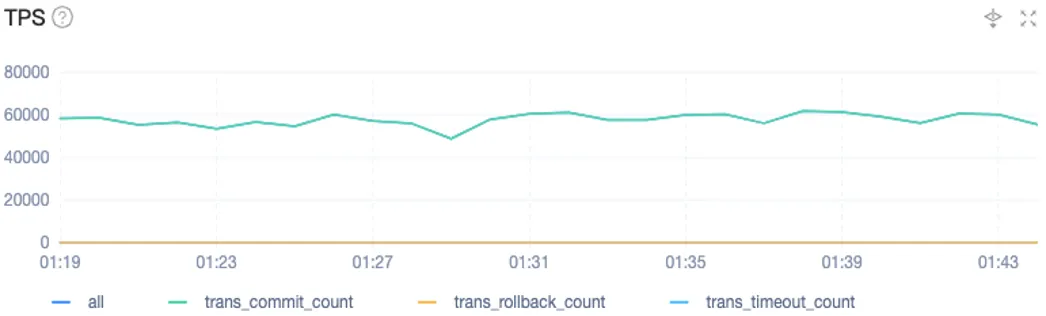
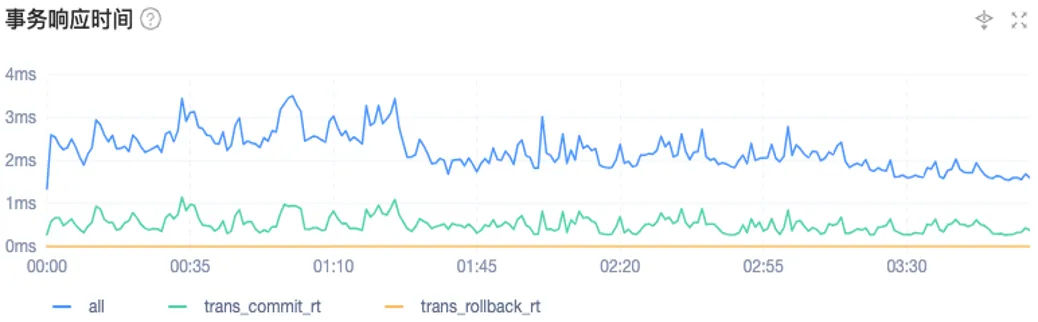
下面两张图展示了 OceanBase 在我们实际生产场景下的性能表现。
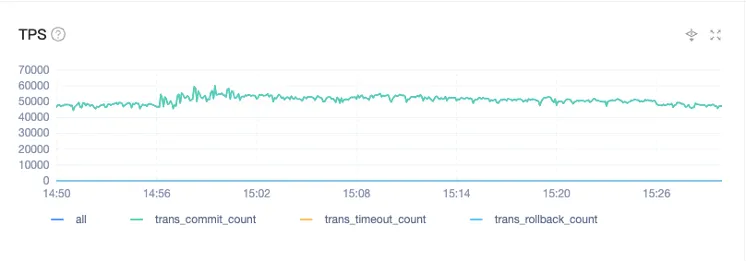
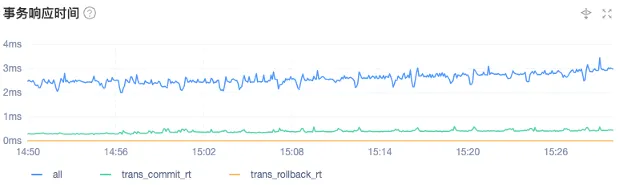
在实际生产场景中,TPS 基本可以稳定在每秒 5 万,但并不是它的上限,而是一个稳定值。当上游数据出现积压时,TPS 会有明显爬升,甚至可以达到每秒 11 万。也就是说,在上游压力增大的时,OceanBase 的 OBKV 可以快速追平数据,解决积压情况。在这个过程中,事务响应时间基本维持在 2~3 毫秒之间。
综合测试环境及实际场景的性能表现,尤其是在运行期间,无 HBase GC 问题, 运行非常稳定。因此,OceanBase 完全可以满足我们的需求。
三、OBKV使用实践及优化
自 2023 年 10 月开始,我们成为了 OceanBase OBKV 模式的早期使用者之一。到目前为止,已经过去了五个月,我们在使用过程中积累了一些实践经验和优化心得,希望与更多 OceanBase 用户分享我们的经验。
如下图所示,这是我们的数据处理流程。我们将数据分为行为数据(事件数据)和维度数据两类,以用户表为例,紫色模块代表 Kafka 的流式数仓,绿色模块代表OBKV,作为缓存层与红色模块的 Flink 流式任务进行交互,红色线条代表事件数据或日志数据的流转过程。我们的用户数据(维度数据)是从事件表中抽取,但抽取的数据不完整,需要通过 API 模式补数据再回写到 OBKV。同时,在向下游发送事件数据时,我们会关联最新的用户信息,最终将数据写入下游系统。
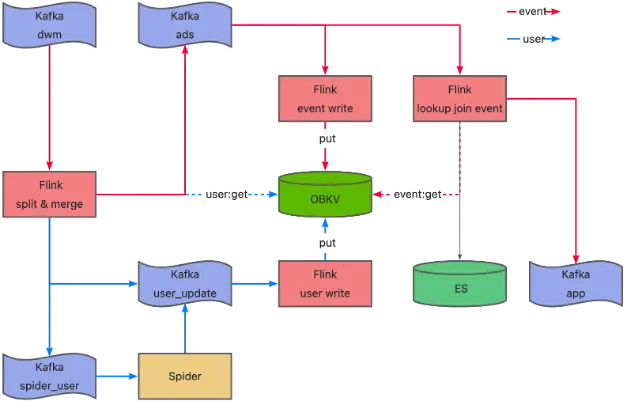
我们的数据主要有以下三个特点:
- 数据量比较大,每天在Kafka里单个 topic 有 10 亿+的数据量。
- 数据是 JSON 格式,其中的 scheme 字段不固定,包含一些嵌套类型和引用关系。
- 数据有重复,这些重复的数据有可能是整个 JSON 的一部分,其中的部分字段会被更新。
受上述数据特点的影响,我们在测试 OBKV 的过程中遇到了几个问题。
问题1:TPS下降。在正常流量情况下,TPS 能够稳定在每秒 3 万,但随着时间的推移,TPS 会开始逐渐下降。经过 5~6 小时,TPS 从 3 万降到 1 万。经过排查,发现故障原因为使用方式不当,我们将在后续详细描述。
问题2:超时读写。随着 TPS 的下降,客户端开始出现超时读写。默认超时时间为 3 秒,这意味着 Flink 任务在 3 秒后会报错。
问题3:OCP 某监控节点的 CPU 异常。具体表现为部分节点 CPU 使用率长时间能维持在 90% 以上,导致集群整体性能。下降。例如,从下图可以看到我们有六个节点,其中一个节点是 root service 所在节点,就会造成木桶效应引发系列反应,对于我们的生产测试来说是不可行的。
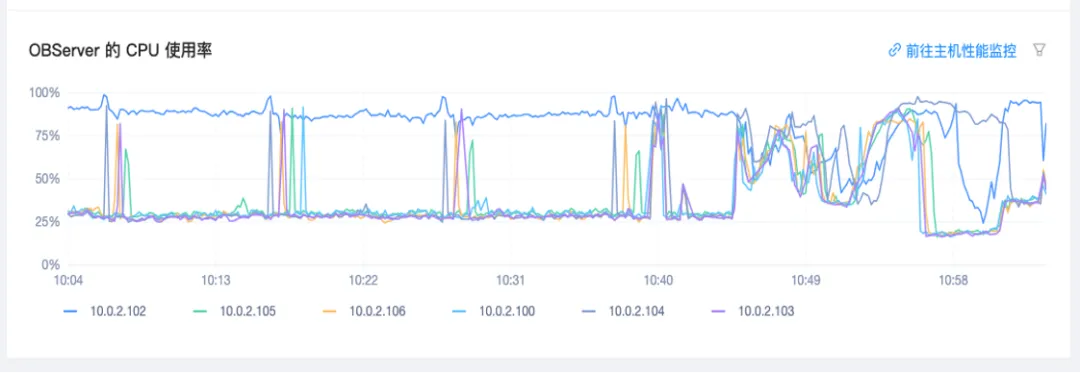
经过我们与 OceanBase 工程师的排查定位,最终发现根本原因是:
- 数据中存在大量热点数据。
- 热点数据高频更新,在一个非常短的时间内(秒级别)大量更新,导致写入版本太多。
- 与此同时,系统在并行执行大量的区间扫描操作。
后续我们在读写方面做了一系列优化操作,重点对热点数据进行优化, 并执行数据去重操作,以下是我们的优化步骤供大家参考。
- 第一次设计时,优化方案没有定位到版本的问题,主要提升了 sink 算子的并行度。
- 第二次优化时,在 sink 算子内部使用线程池消费往 OBServer 并行发 Put,进一步增大写 OceanBase 的并发。
- 第三次优化时,关闭 autoflush 并配置 writeBuffer 进行批量写入。在这个过程中遇到当前版本 OceanBase 服务端不支持的问题,原因是一个事务内不允许同一个 key 的不同版本一起写入。
在后续的版本迭代中,OceanBase 发布了 HBase max version 和 TTL 的功能特性。我们创建了一张表进行了测试,并在客户端写入时候时指定了时间戳。对于我们的特殊业务,比如作品表,需要从 JSON 数据里面提取 eventTime,timestamp=eventTime 作为这条数据的一个版本。而用户表是一个维度信息,不像作品表可以直接提取时间,并且默认值是Long.MaxValue最终用的timestamp=Long.MaxValue - 1。在服务端可以理解为是一种宏或会自动转换为当前的时间戳,就会导致用户表出现版本过多的问题,如果同一个用户写入很多次,那在 OceanBase 里面存的版本就有多种。
最终,我们的调整方案是用户表的一个 T 就是一个 Long.MaxValue - 1,最后 1 位转换成 16 进制,和最后一位是 E,以确保唯一性。
写优化:作品表
作品表是我们的一个事实表,根据字段来提取一个时间戳作为版本。在优化完版本问题后,我们还需要刷新历史数据。如下图所示,我们使用TTL功能对历史数据进行刷新。从14号10点到17号11点跑了三天,scan count大概是4.3亿。这个数量是每一个分区的数量,共997个分区上千亿数据,导致TTL持续跑了一周时间。
为了最大程度地加快数据清理速度,我们加大了 TTL 并行度,每个节点分配 64 个线程,并将租户 CPU 利用率提高到 100%。最终我们有效地优化了作品表历史数据的刷新,在最短时间内完成了数据的自动清理,性能非常可观,优化效果非常显著。
在 OceanBase 中我们存储了近一个月的数据,每天的增量数据为 10 亿,再分散到每一个字段,总计上千亿数据量。最终跑完之后再看每一个 Qualify (列名)的版本,已经刷到正常的状态。从 Flink 任务的角度来看,任务数据没有积压,任务也能稳定运行,不会出现读写超时。从 Kafka 监控的数据来看,生产速度和消费速度都符合我们的需求。
由于我们的业务需求是点查,因此我们在 OceanBase 中做了一个监控,观测整体基线的点查耗时,延时基本在 10 毫秒以内,有部分抖动也是正常情况。
写优化:维度表
在解决作品表的优化后,我们再回到维度表。维度表跑完 TTL 之后,我们看一下数据量,并将表按照 scan_cnt 进行两次排序,分别是升序排序和降序排序。我们发现最大的分区数据量达到 2.2 亿数据,最小的分区数据量为 1.4 千万,表明分区存在热点写的情况。这可能是由于数据用户的 key 分布不均匀,也可能是因为用户表本身就存在热点写。
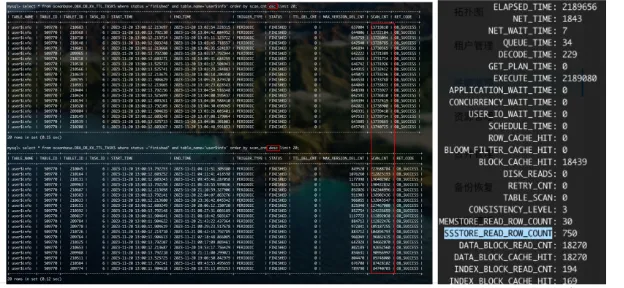
为了进一步了解情况,我们查询了系统表 sql_audit,发现关键参数SSstore_read_row_count 的值是 750,这个参数对应的是 SSTable 个数,代表如果查一个 key 需要扫 750 个 SSstore,说明该表有热点写。其实热点写再对应到我们的数据上来说,就是有多版本。
根据上述优化,我们设计了三种方案解决分区间总条数差异大,说明用户表有热点数据和转储 SSTable 的数量过多的问题。
方案一:利用 Flink 的滚动窗口 TumblingWindow。该方案的不足是无论窗口时间设为多大,当窗口结束时触发写都有流量波峰问题,不可行。
方案二:对数据进行特征提取。按用户数做 SessionWindow,相当于一个用户作为一个合并。但由于我们的数据特点是部分用户更新频率特别快,大概每天有 12 小时在不间断更新。如果用 SessionWindow,会话窗口的 gap 不好把握,大数据量更新会有较大延时。
方案三:用 Process 做注册。然后在 Process 里对每一个新用户注册一个定时器。当他第一次进入时注册一个定时器,并将用户属性放在状态中。当用户第二次进入,只更新状态,直到定时器触发才把用户写到 OceanBase。这种方案也有一个问题,当我们的程序第一次启动或数据积压时,就有一波新用户,然而周期性的写入也会有波峰问题。我们的解决方案是在定时器基础上加个随机数,即Process Timer + Random time。比如定时器基数是十分钟,那么再加五分钟的随机值,哪怕一次来了 100 万个用户,在 10~15 分钟内也能把 100 万个用户做平均值写入OceanBase,最终能起到消峰的作用。
从下图的优化结果看,我们优化去重的效果是减少了三分之二,比如写入 30 亿数据,输出时只有 10 亿的数据量。
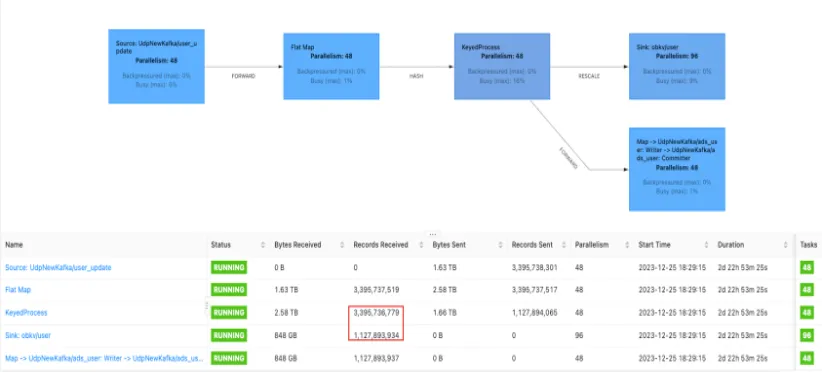
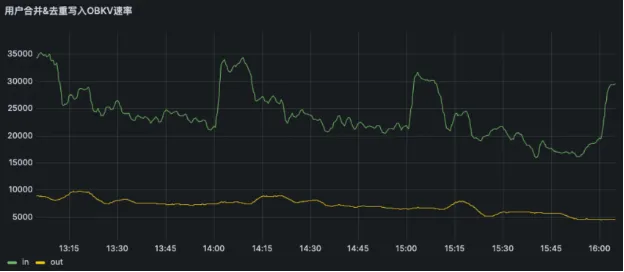
从下图监控数据来看,黄线代表每秒写入 OceanBase 数据的输出数据量,绿线是每秒从 Kafka 接收到的用户量。整体来说,输出基线在 6000~8000,输入为22000~25000,大约是三分之一的需求量。至于流量波峰,比如说 2 点到 2 点 15 分时激增流量,到输出的时候,推迟 10~15 分钟,这样的波动不是很大,这就是加随机数的效果。
读优化
针对读优化,我们对 OBKV 的定位是缓存层,点查需毫秒级响应。因为我们用的是HBase API,可以在 gap 的同时对 qualifier 进行裁剪。这样做的好处有两个,一个是减少扫描 SSTable 数量,降低扫描数据带来的超时风险,二是减少一个网络 I/O,比如对机器、OBServer 或 Flink 任务网络 I/O 的压力。
优化后用户数据不需要实时更新。我们可以在任务中加一个状态 Flink-State 来做本地缓存,并且对状态配置 TTL。相当于只有在一定时间内和第一次才会把这些点查的请求打到 OceanBase,99% 都能在本地状态去做。
OBKV 作为一个缓存层,需要存储最近30天的数据,而我们之前使用的 Pika 只能存最近 7~14 天的数据。如果缓存层拿不到,才会去 Elasticsearch 所在的存储层,这样可以拦截掉 90% 的 Elasticsearch 查询请求。而且最近 30 天是满足我们的业务需求的,就舍弃查询 Elasticsearch 的操作。
我们之前在 Elasticsearch 做查询,响应速度在 10 秒钟左右。如果集群负载较高,可能会达到 1 分钟,对业务造成很大的影响。舍弃 Elasticsearch 查询后,数据全部从 OceanBase 层和本地状态层读,TPS 可以拉到很高。后续我们对这种情况做了一个压测,TPS 能够稳定在 6 万/秒 上下,峰值是 11 万/秒。对比于其他产品比如 Redis、HBase 等,OBKV 的性能表现力压群雄。
读优化后效果如下。

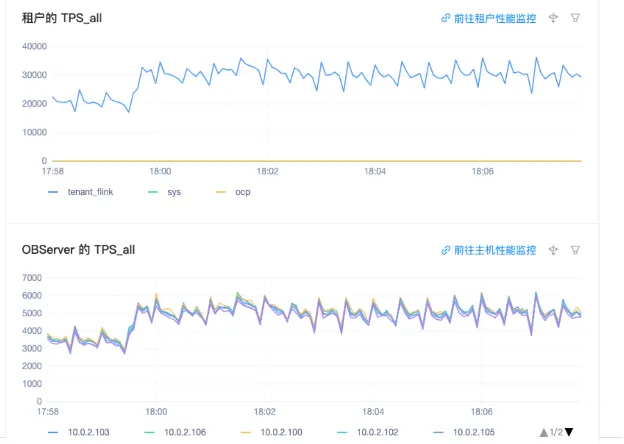
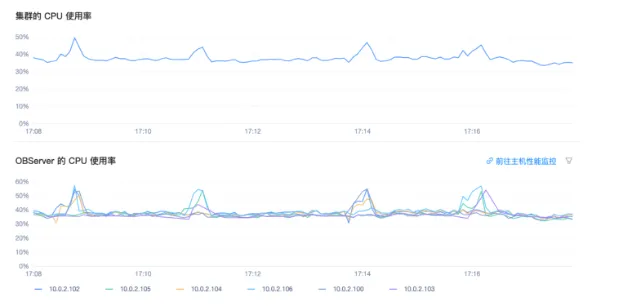
整体来说,我们读写都做优化后、流量稳定后,TPS 基本上能够稳定在 30000 左右,每一个 OBServer 的 TPS 节点,也能够稳定在 50000~60000。CPU 使用率也完全符合我们的期望(见下图)。
四、OceanBase&OBKV落地收益
OceanBase 的 OBKV 在仟传业务落地的过程中,我们经历了一些挑战,非常感谢 OceanBase 团队的大力支持,让我们得以实现性能的大幅提升。
- 出色的插入&点查性能:在当前集群规模及配置下,我们实现了稳定的 60000 TPS,可同时满足业务数据高速摄入和高速点查需求;在上游数据陡增时,TPS峰值可达 110000,能够快速追平数据,避免数据积压。
- 简洁的架构:基于 OBServer 构建整个集群;基于 OBAgent 管理集群、采集监控数据。
- 基于 OCP 的界面化操作工具:可实现对集群、主机、OBServer、租户、数据库等的界面化管理,非常方便运维操作。
- 快速响应的技术支持团队:OceanBase 技术支持团队快速响应客户需求,并积极帮忙排查问题,根据业务特点给出有效解决方案。
此外,是我们对 OceanBase 当前版本的一些优化建议,希望可以评估采纳进入未来的产品规划。
- TTL 粒度细化到表级:当前 TTL 机制会覆盖到租户下所有的表,会消耗较长时间,建议将粒度细化到表,即可对租户下指定的表执行 TTL。
- 读写 TPS 监控分离:当前 OCP 界面上 TPS 监控信息主要显示总 TPS,建议将读和写 TPS 分离出来,更加直观反映读写性能。
- 多语言客户端 API 支持:obkv-client put 目前不支持同时写入多条数据,建议支持攒批写,可减轻网络 I/O;Flink connector 建议进一步完善,集成相关操作,方便用户使用;Python API 建议持续完善,支持 Python 程序开发。
- OCP 页面跳转:当前 OCP 页面上点击时经常发生跳转,建议不要跳转,避免多窗口导致混乱。
OceanBase OBKV 目前在仟传已经正式落地,在性能、稳定性、扩展性等方面均表现出色,有效支撑了业务的快速发展。经过生产系统的真实实践,并得到了仟传业务开发、运营和管理团队的一致认可。我们相信,OceanBase 将会不断完善,为用户提供更加优质的产品和服务。我们期待与 OceanBase 继续合作,共同推动分布式数据库在关键业务负载的突破和发展。