Kafka安装与操作
安装与配置
版本说明
安装包下载地址: http://archive.apache.org/dist/kafka/3.5.0/
源码包下载地址: http://archive.apache.org/dist/kafka/3.5.0/
安装配置
1)解压: tar -zxvf kafka_2.12-3.5.0.tgz -C /opt/module/
2)重命名: mv kafka_2.12-3.5.0/ kafka-3.5.0/
3)hadoop101执行以下命令创建数据文件存放目录: mkdir -p /opt/module/kafka-3.5.0/datas
4)修改配置文件:
// 修改$KAFKA_HOME/config/server.properties //
当前kafka实例的id,必须为整数,一个集群中不可重复 broker.id=0 //
生产到kafka中的数据存储的目录,目录需要手动创建 log.dirs=/opt/module/kafka-3.5.0/datas //
kafka数据在zk中的存储目录
zookeeper.connect=hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka
// 添加配置,用来删除topic delete.topic.enable=true host.name=hadoop101
5)同步到其他机器:
scp -r kafka/ hadoop102:$PWD
scp -r kafka/ hadoop103:$PWD
6)修改broker.id:
//修改broker.id
broker.id=1 broker.id=2
//修改host.name
host.name=hadoop102 host.name=hadoop103
服务启动
服务启动:每台都要运行此命令:
nohup bin/kafka-server-start.sh config/server.properties 2>&1 &
启动结果如图-5所示:

图-5 kafka启动
Kafka基本操作
Kafka的topic操作
topic是kafka非常重要的核心概念,是用来存储各种类型的数据的,所以最基本的就需要学会如何在kafka中创建、修改、删除的topic,以及如何向topic生产消费数据。
关于topic的操作脚本:kafka-topics.sh:
bin/kafka-topics.sh --create
–topic hadoop \ // 指定要创建的topic的名称
–bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092\ //指定kafka关联的zk地址
–partitions 3 \ //指定该topic的分区个数
–replication-factor 3 //指定副本因子
创建topic
注意:指定副本因子的时候,不能大于broker实例个数,否则报错,如图-6所示:
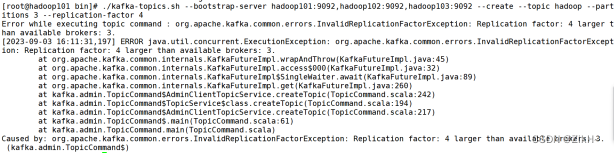
图-6 kafka创建topic
当使用正确的方式,即将replication-factor设置为3,之后执行脚本命令,创建topic成功,如图-7所示。

图-7 zookeeper中的topic列表
与此同时,在kafka数据目录data.dir=/opt/module/kafka-3.5.0/datas/中有了新变化,如图-8所示。

图-8 kafka数据目录
查看topic列表
bin/kafka-topics.sh --list
–bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092
执行结果如图-9所示。

图-9 kafka topic列表
查看每一个topic的信息
bin/kafka-topics.sh --describe
–topic hadoop
–bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092
执行结果如图-10所示。

图-10 kafka topic信息
其中partition,replicas,leader,isr代表的是什么意思呢。
1)Partition:当前topic对应的分区编号。
2)Replicas:副本因子,当前kafka对应的partition所在的broker实例的broker.id的列表。
3)Leader:该partition的所有副本中的leader领导者,处理所有kafka该partition读写请求。
4)ISR:该partition的存活的副本对应的broker实例的broker.id的列表。
修改一个topic
[root@hadoop101 kafka]$ bin/kafka-topics.sh --alter
–topic hadoop
–partitions 4
–bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092
执行结果如图-11所示,可以看出partition由原先的3个变成了4个。
图-11 kafka topic修改partition
但是注意:partition个数,只能增加,不能减少,如图-12所示。
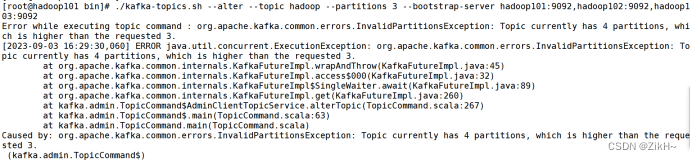
图-12 kafka topic partition只能增加
删除一个topic
[root@hadoop101 kafka]$ bin/kafka-topics.sh --delete
–topic test
–bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092
执行结果如图-13所示

图-13 kafka topic删除
Kafka终端数据生产与消费
脚本简介
在$KAFKA_HOME/bin目录下面提供了很多脚本,其中kafka-console-producer.sh和kafka-console-consumer.sh分别用来在终端模拟生产和消费数据,即作为kafka topic的生产者和消费者存在。
生产数据
生产数据,执行以下的命令:
[root@hadoop101 kafka]$ bin/kafka-console-producer.sh
–topic hadoop
–bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092
如图-14所示:

图-14 kafka-console-producer生产数据
消费数据
类似的,消费刚刚生产的数据需要执行以下命令:
[root@hadoop102 kafka]$ bin/kafka-console-consumer.sh
–topic hadoop
–bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092
如图-15所示:

图-15 kafka-console-producer生产数据
但遗憾的是,我们并没有看到刚刚生产的数据,这很好理解,比如新闻联播每晚7点开始了,结果你7点15才打开电视看新闻,自然7点到7点15之间的新闻你就会错过,如果你想要看这之间的新闻,那么就需要其提供回放的功能,幸运的是kafka不仅提供了从头开始回放数据的功能,还可以做到从任意的位置开始回放或者读取数据,这点功能是非常强大的。
那么此时重新在生产端生产数据,比如4,5,6,再看消费端,如图-16所示,就可以看到有数据产生了。
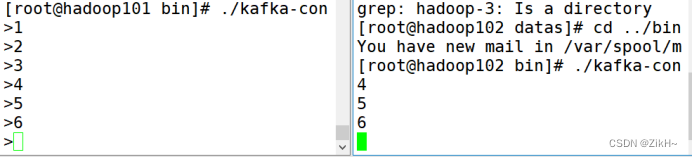
图-16 kafka-console-consumer消费数据
那么我想要读取1,2,3的数据,那该怎么办呢?此时只需要添加一个参数–from-beginning从最开始读取数据即可,如图-17所示:
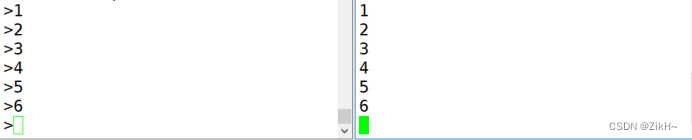
图-17 kafka-console-consumer从头消费数据
Kafka的数据消费的总结
消费者与分区之间的关系
kafka消费者在消费数据的时候,都是分组别的。不同组的消费不受影响,相同组内的消费,需要注意,如果partition有3个,消费者有3个,那么便是每一个消费者消费其中一个partition对应的数据;如果有2个消费者,此时一个消费者消费其中一个partition数据,另一个消费者消费2个partition的数据。如果有超过3个的消费者,同一时间只能最多有3个消费者能消费得到数据,如图-18所示。
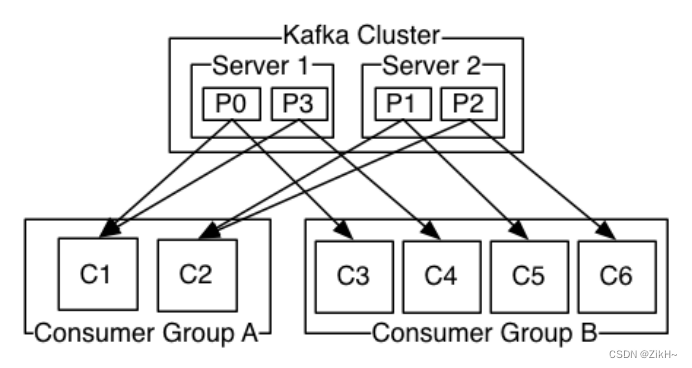
图-18 kafka消费数据的特点
如下命令查看不同分区中产生的数据:
第一个消费者:
[root@hadoop102 kafka]$ bin/kafka-console-consumer.sh
–topic hadoop
–bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092
–partition 0
–offset earliest
第二个消费者:
[root@hadoop102 kafka]$ bin/kafka-console-consumer.sh
–topic hadoop
–bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092
–partition 1
–offset earliest
第三个消费者:
[root@hadoop102 kafka]$ bin/kafka-console-consumer.sh
–topic hadoop
–bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092
–partition 2
–offset earliest
offset:是kafka的topic中的partition中的每一条消息的标识,如何区分该条消息在kafka对应的partition的位置,就是用该偏移量。offset的数据类型是Long,8个字节长度。offset在分区内是有序的,分区间是不一定有序。如果想要kafka中的数据全局有序,就只能让partition个数为1,如图-19所示。
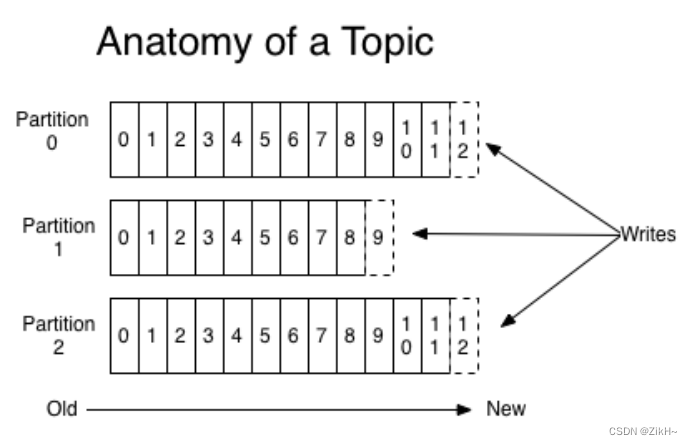
图-19 kafka offset概念
在组内,kafka的topic的partition个数,代表了kafka的topic的并行度,同一时间最多可以有多个线程来消费topic的数据,所以如果要想提高kafka的topic的消费能力,应该增大partition的个数。