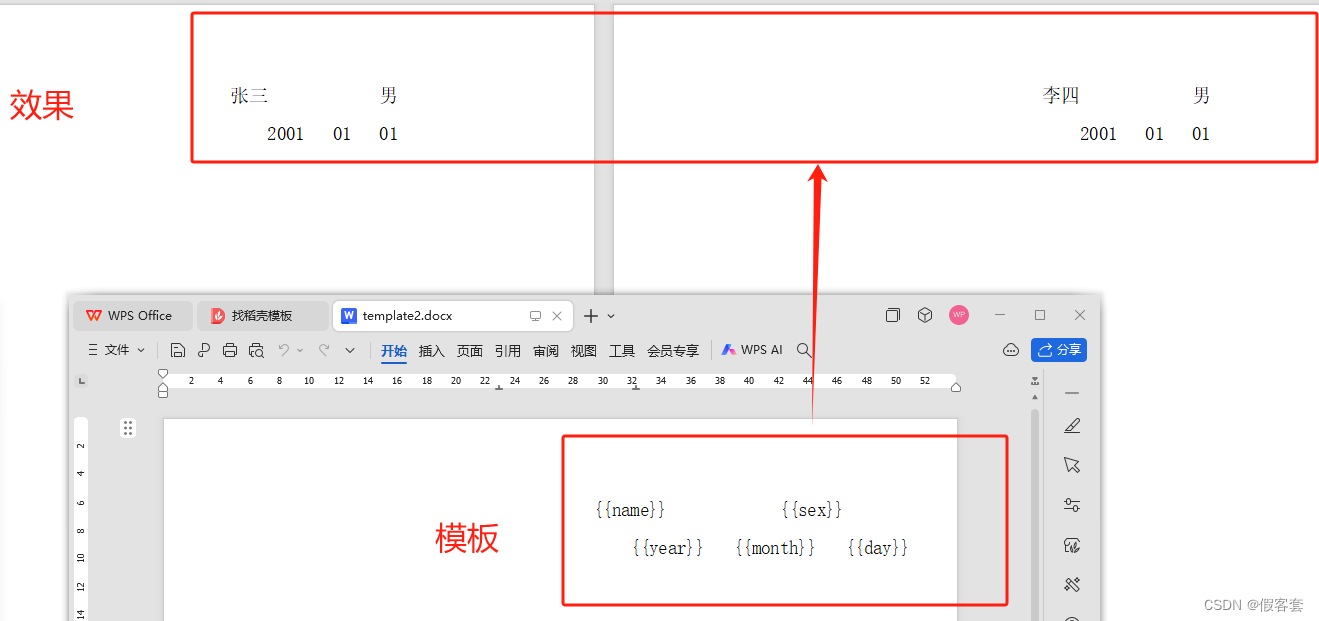
先看效果
一、准备工作
1.word模版
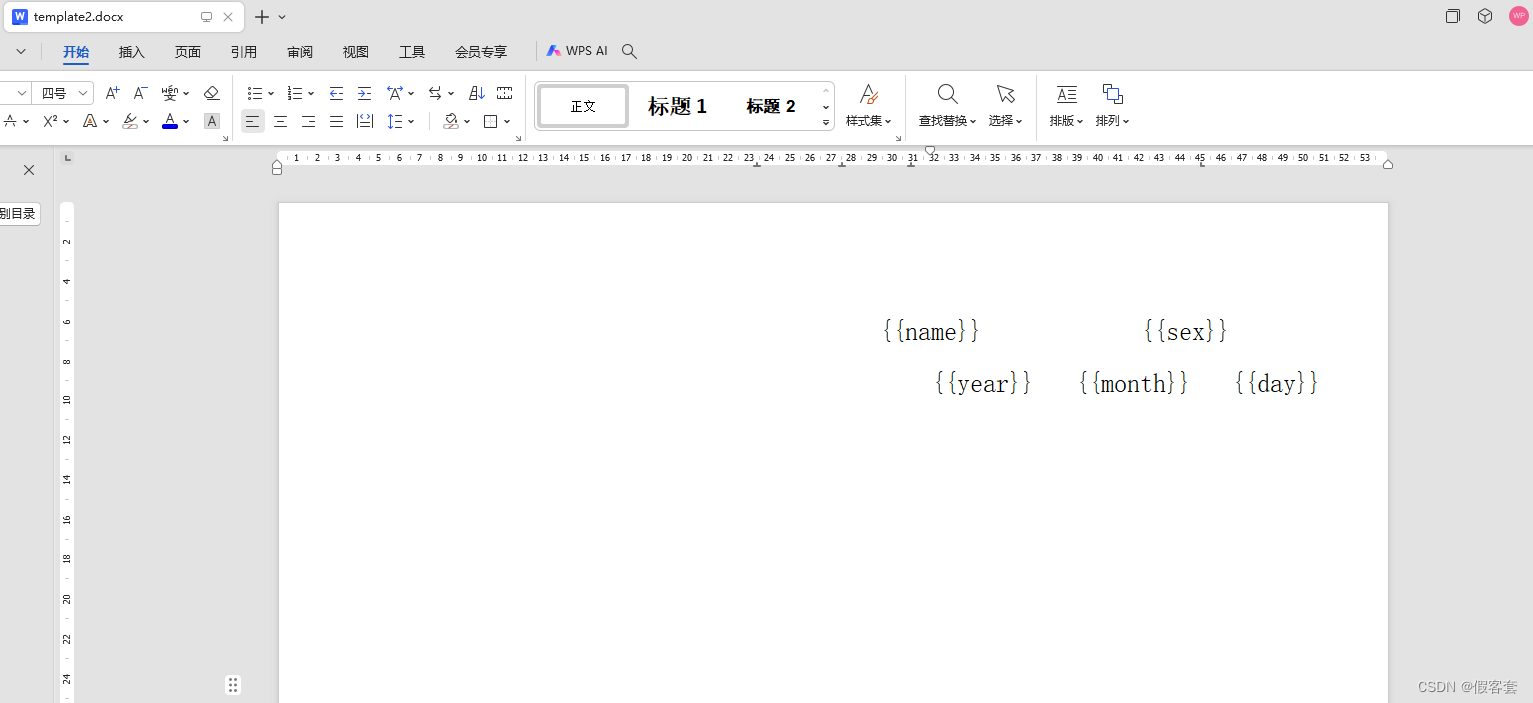
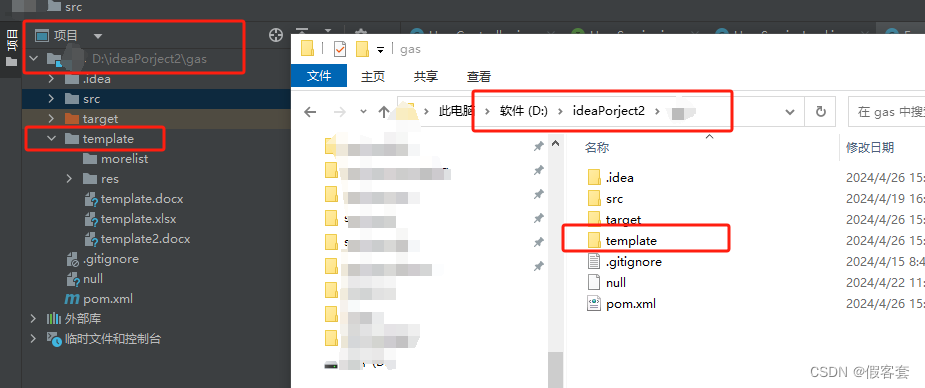
2.文件路径
二、pom依赖
<!-- easyexcel --><dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>2.1.7</version></dependency><dependency><groupId>javax.servlet</groupId><artifactId>servlet-api</artifactId><version>2.5</version></dependency><!-- word export --><dependency><groupId>com.deepoove</groupId><artifactId>poi-tl</artifactId><version>1.12.0</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.poi/poi --><dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>5.2.2</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.poi/poi-ooxml --><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.2.2</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml-schemas</artifactId><version>4.1.2</version></dependency>
三、两个工具类+自己的实体类(这里是用户作为示例)
1.自己的实体类
import com.mybatisflex.annotation.Id;
import com.mybatisflex.annotation.KeyType;
import com.mybatisflex.annotation.Table;import java.io.Serializable;import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;/*** 用户信息 实体类** @author zhaoyan* @since 2024-04-19*/
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Table(value = "user")
public class User implements Serializable {/*** 用户id*/@Id(keyType = KeyType.Auto)private Integer id;/*** 姓名*/private String name;/*** 身份证号*/private String cardId;/*** 性别*/private String sex;}
2.合并word工具类
import java.io.*;
import java.util.*;import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.xwpf.usermodel.*;
import org.apache.xmlbeans.XmlOptions;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTBody;/*** 合并word工具类*/
public class MergeWordUtil {/*** 将多个Word文档文件合并成一个新的Word文档文件,* 并将合并后的内容保存到指定的目标路径中。** @param files 多个word文件* @param targetPath 目标存放地址* @throws Exception*/public static void mergeMroeWord(List<File> files, String targetPath) throws Exception {// 1. 打开目标路径对应的文件输出流 `dest`,并使用 try-with-resources 语句确保流在使用完毕后会被正确关闭。try (OutputStream dest = new FileOutputStream(targetPath);) {// 2. 创建一个 `ArrayList` 类型的 `documentList`,用于存储读取的多个Word文档对象。ArrayList<XWPFDocument> documentList = new ArrayList<>();XWPFDocument doc = null;// 3. 遍历传入的文件列表 `files`,对每个文件执行以下操作:for (File file : files) {try (FileInputStream in = new FileInputStream(file.getAbsoluteFile())) {// - 使用 `FileInputStream` 读取文件内容,并通过 `OPCPackage` 打开文件流,创建一个新的XWPFDocument对象 `document`。OPCPackage open = OPCPackage.open(in);XWPFDocument document = new XWPFDocument(open);// - 将读取的文档对象 `document` 添加到 `documentList` 中。documentList.add(document);} catch (FileNotFoundException e) {// - 如果读取文件时发生 `FileNotFoundException` 异常,则捕获并打印异常信息。e.printStackTrace();}}// 4. 遍历 `documentList` 中的文档对象:for (int i = 0; i < documentList.size(); i++) {doc = documentList.get(0);// - 如果是第一个文档(`i == 0`),在文档中创建一个新段落,并在新段落中添加一个换页符。if (i == 0) {documentList.get(i).createParagraph().createRun().addBreak(BreakType.PAGE);// appendBody(doc,documentList.get(i));// - 如果是最后一个文档(`i == documentList.size() - 1`),调用 `appendBody` 方法将当前文档内容追加到 `doc` 文档中。} else if (i == documentList.size() - 1) {appendBody(doc, documentList.get(i));// - 如果既不是第一个文档也不是最后一个文档,分别在文档中创建一个新段落并添加换页符,然后调用 `appendBody` 方法将当前文档内容追加到 `doc` 文档中。} else {documentList.get(i).createParagraph().createRun().addBreak(BreakType.PAGE);appendBody(doc, documentList.get(i));}}// 5. 最终将合并后的文档内容写入到目标路径对应的文件中,并确保 `doc` 不为null。assert doc != null;// 6. 如果在写入过程中发生异常,则会抛出异常。doc.write(dest);}}/*** 将一个文档对象的内容追加到另一个文档对象中,* 同时处理了文档中的图片数据,* 确保图片在合并后的文档中能够正确显示** @param src* @param append* @throws Exception*/public static void appendBody(XWPFDocument src, XWPFDocument append) throws Exception {// 1. 通过 `src.getDocument().getBody()` 和 `append.getDocument().getBody()` 分别获取源文档和追加文档的主体内容(CTBody对象)。CTBody src1Body = src.getDocument().getBody();CTBody src2Body = append.getDocument().getBody();// 2. 调用 `append.getAllPictures()` 方法获取追加文档中的所有图片数据,并将其存储在 `allPictures` 列表中。// 记录图片合并前及合并后的IDList<XWPFPictureData> allPictures = append.getAllPictures();// 3. 创建一个 `HashMap` 对象 `map`,用于记录图片在合并前和合并后的关系。Map<String, String> map = new HashMap<String, String>();// 4. 遍历追加文档中的所有图片数据 `allPictures`,对每个图片执行以下操作:for (XWPFPictureData picture : allPictures) {// - 获取图片在追加文档中的关系ID,并将其存储在 `before` 变量中。String before = append.getRelationId(picture);// - 将图片数据添加到源文档中,并指定图片类型为PNG,获取添加后的图片关系ID,并将其存储在 `after` 变量中。String after = src.addPictureData(picture.getData(), Document.PICTURE_TYPE_PNG);// - 将 `before` 和 `after` 的对应关系存储在 `map` 中。map.put(before, after);}// 5. 调用另一个方法 `appendBody`,传入源文档的主体内容、追加文档的主体内容和图片关系ID的映射,将追加文档的内容合并到源文档中。appendBody(src1Body, src2Body, map);}/*** 将两个文档对象的主体内容进行合并,* 并在合并过程中替换图片ID,* 最终更新源文档对象的主体内容** @param src 源文档的主体内容,类型为 `CTBody`。* @param append 追加文档的主体内容,类型为 `CTBody`。* @param map 存储图片ID替换关系的映射,类型为 `Map<String, String>`。* @throws Exception*/private static void appendBody(CTBody src, CTBody append, Map<String, String> map) throws Exception {// 1. 创建一个 `XmlOptions` 对象 `optionsOuter`,并设置其保存外部内容的选项。XmlOptions optionsOuter = new XmlOptions();optionsOuter.setSaveOuter();// 2.将追加文档对象 append 转换为XML字符串,并将结果存储在 appendString 变量中。String appendString = append.xmlText(optionsOuter);// 3.将源文档对象 src 转换为XML字符串,并将结果存储在 srcString 变量中。String srcString = src.xmlText();// 4.通过字符串操作,将源文档的XML内容分为四部分:prefix、mainPart、sufix 和 addPart,具体操作和含义与前述相同。String prefix = srcString.substring(0, srcString.indexOf(">") + 1);String mainPart = srcString.substring(srcString.indexOf(">") + 1, srcString.lastIndexOf("<"));String sufix = srcString.substring(srcString.lastIndexOf("<"));String addPart = appendString.substring(appendString.indexOf(">") + 1, appendString.lastIndexOf("<"));// 5.如果 map 不为null且不为空,遍历 map 中的键值对,将 addPart 中的图片ID替换为对应的新ID。if (map != null && !map.isEmpty()) {// 对xml字符串中图片ID进行替换for (Map.Entry<String, String> set : map.entrySet()) {addPart = addPart.replace(set.getKey(), set.getValue());}}// 6.将 prefix、mainPart、addPart 和 sufix 拼接为一个完整的XML内容字符串,并通过 CTBody.Factory.parse() 方法将其解析为 CTBody 对象 makeBody。CTBody makeBody = CTBody.Factory.parse(prefix + mainPart + addPart + sufix);// 7.最后将合并后的 makeBody 设置为源文档对象 src 的内容。src.set(makeBody);}
}
3.下载工具类
import com.deepoove.poi.XWPFTemplate;
import com.test.entity.User;
import org.apache.commons.compress.utils.IOUtils;
import org.apache.commons.io.FileUtils;import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;/**下载工具类* */
public class ExportToWrodUtils {/*** 下载** @param response* @param sourceFilePath 源文件* @param moreFilePath 多个文件路径文件夹,template\\morelist\\* @param mergeFilePath 合并后文件路径,template\\res\\* @param finalFileName 合并后文件名字* @param downloadFileName 下载时的文件名字* @param userList* @throws Exception*/public static void downloadWord(HttpServletResponse response, String sourceFilePath, String moreFilePath, String mergeFilePath,String finalFileName, String downloadFileName, List<User> userList) throws Exception {// 1.获取文件流InputStream stream = new FileInputStream(sourceFilePath);// 2.数据列表XWPFTemplate template = XWPFTemplate.compile(stream);List<File> fileList = new ArrayList<>();for (User user : userList) {//可以改成自己的业务逻辑↓↓↓↓↓↓↓↓↓↓↓// 填充数据Map<String, String> data = new HashMap<>();data.put("name", user.getName());data.put("sex", user.getSex());// 根据身份证号或去年月日data.put("year", extractYearMonthDayOfIdCard(user.getCardId()).split("-")[0]);data.put("month", extractYearMonthDayOfIdCard(user.getCardId()).split("-")[1]);data.put("day", extractYearMonthDayOfIdCard(user.getCardId()).split("-")[2]);template.render(data);File file = new File(moreFilePath + user.getCardId() + ".docx");//可以改成自己的业务逻辑↑↑↑↑↑↑↑↑↑↑↑fileList.add(file);// 保存为单个Word文档FileOutputStream out = new FileOutputStream(file);template.write(out);out.close();}// 3.合并多个word,为一个wordMergeWordUtil.mergeMroeWord(fileList, mergeFilePath + finalFileName);// 4.删除合并后之前用到的多个单独word文件// 创建一个File对象,表示文件夹路径File folder = new File(moreFilePath);// 获取文件夹中的所有文件File[] files = folder.listFiles();// 遍历文件数组,删除Word文件for (File file : files) {if (file.isFile() && file.getName().endsWith(".docx")) {try {FileUtils.forceDelete(file);System.out.println("删除文件 " + file.getName());} catch (Exception e) {System.out.println("删除文件失败: " + file.getName());e.printStackTrace();}}}// 5.下载操作File file = null;FileInputStream is = null;try {response.setContentType("text/html;charset=utf-8");response.setCharacterEncoding("UTF-8");// 下载文件时的文件名字response.setHeader("content-disposition", "attachment;filename=\"" + URLEncoder.encode(downloadFileName + ".docx", "utf-8") + "\"");// 要下载的目标文件file = new File(mergeFilePath + finalFileName);is = new FileInputStream(file);ServletOutputStream os = response.getOutputStream();IOUtils.copy(is, os);} catch (IOException e) {e.printStackTrace();} finally {if (is != null) {is.close();}// if (file != null) {// file.delete();// }}}/*** 省份证的正则表达式^(\d{15}|\d{17}[\dx])$ 方法类** @param id 省份证号* @return 生日(yyyy - MM - dd)*/public static String extractYearMonthDayOfIdCard(String id) {String year = null;String month = null;String day = null;// 正则匹配身份证号是否是正确的,15位或者17位数字+数字/x/Xif (id.matches("^\\d{15}|\\d{17}[\\dxX]$")) {year = id.substring(6, 10);month = id.substring(10, 12);day = id.substring(12, 14);} else {System.out.println("身份证号码不匹配!");return null;}return year + "-" + month + "-" + day;}}
四、业务逻辑使用工具类
// 1.controller层/*** 导出为word数据列表** @throws IOException*/@GetMapping("/downloadWord")public void downloadWord(HttpServletResponse response) throws Exception {userService.downloadWord(response);}// 2.service层/*** 导出为word数据列表** @return* @throws IOException*/void downloadWord(HttpServletResponse response) throws Exception;// 3.serviceImpl层/*** 导出为word数据列表** @return* @throws IOException*/@Overridepublic void downloadWord(HttpServletResponse response) throws Exception {// 数据列表QueryWrapper queryWrapper = QueryWrapper.create().where(USER.POWER.eq("用户"));List<User> userList = userMapper.selectListWithRelationsByQuery(queryWrapper);ExportToWrodUtils.downloadWord(response, "template\\template2.docx", "template\\morelist\\", "template\\res\\", "合并后数据", "word数据列表", userList);}
五、调用接口,查看效果
浏览器直接get请求