- 概
- Spherical Linear Interpolation (Slerp)
- Text-Anchored-Tuning (TAT)
- 代码
Jiang Y. K., Huynh D., Shah A., Chen W. and Lim S. Spherical linear interpolation and text-anchoring for zero-shot composed image retrieval. ECCV, 2024.
概
本文提出了一种非常简单的 Zero-Shot Composed Image Retrieval (ZS-CIR) 方法. 仅通过 image feature 和 text feature 间的球面线性插值就可以得到 SOTA 的结果.
Spherical Linear Interpolation (Slerp)
-
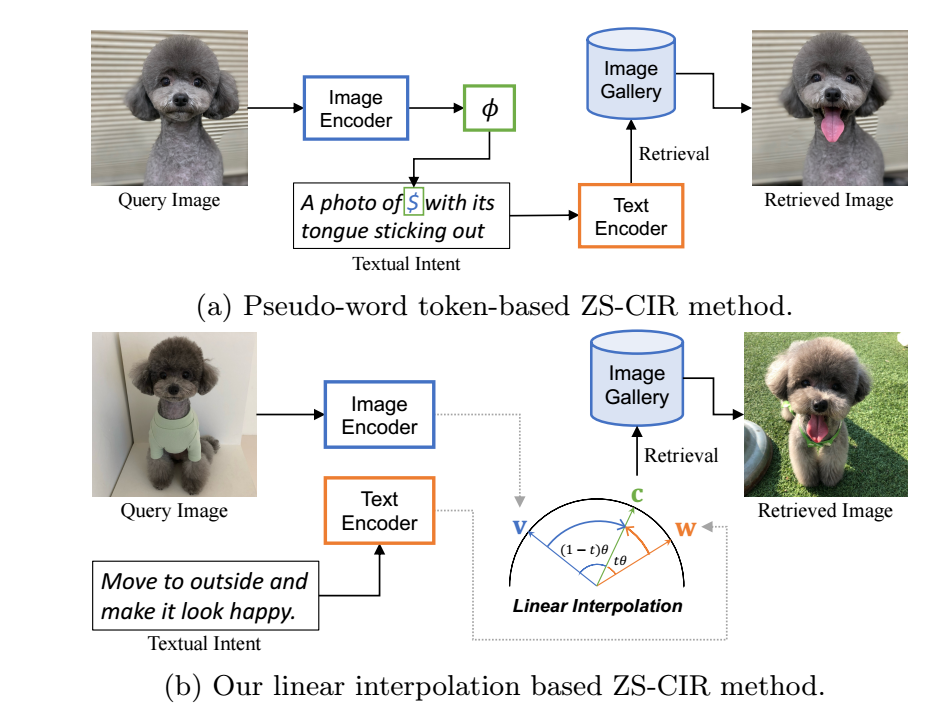
ZS-CIR 的目标是找到匹配图片 \(x\) 和一段文本描述 \(t\) 的其它图片.
-
通过 visual/textual encoder 我们可以得到二者的向量表示 (normalize 过后的):
\[\mathbf{v} = E_I(x) \in \mathbb{R}^d, \\ \mathbf{w} = E_t(t) \in \mathbb{R}^d. \] -
本文提出了一种非常简单的方式: Slerp. 即通过两个向量的球面线性插值得到
\[\mathbf{c}: \text{Slerp}(\mathbf{v}, \mathbf{w}; \alpha) =\frac{\sin((1 - \alpha) \theta)}{\sin(\theta)} \mathbf{v} +\frac{\sin(\alpha \theta)}{\sin(\theta)} \mathbf{w}, \]其中 \(\theta = \cos^{-1} (\mathbf{v} \cdot \mathbf{w})\) 为两个向量间的夹角.
注: 上面的系数是通过三角形三边三角如下的关系得到的:
$$
\frac{a}{\sin(\alpha)} = \frac{b}{\sin(\beta)} = \frac{c}{\sin(\gamma)},
$$
其中 \(a, b, c\) 分别为角 \(\alpha, \beta, \gamma\) 所对应的边.
- 作者发现, 通常情况下, text-only 的检索比 image-only 的检索效果要好很多很多, 所以作者推荐设置一个 \(\alpha \ge 0.8\), 从而 \(\mathbf{c}\) 实际上更偏向于文本描述.
Text-Anchored-Tuning (TAT)
-
注意到, 到目前为止, 我们只用到了预训练的 encoder 而没有进行任何额外的训练, 实际上根据实验结果可以发现, 仅此就可以取得非常好的结果了.
-
但是, 作者发现效果可以进一步提升, 提升的空间来自譬如 CLIP 的得到 image/text 表示实际上有很大的 gap. 于是作者希望通过微调 image encoder 来进一步将 image 表示推向文本表示.
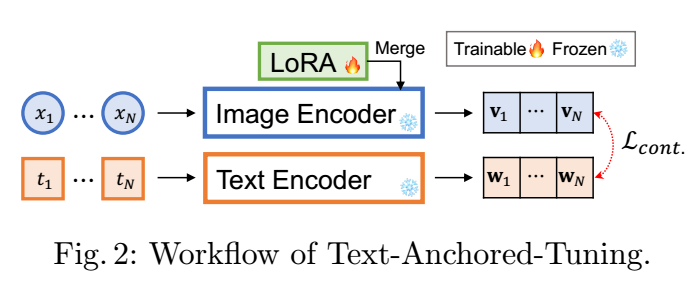
- 如上图所示, 除了用 LoRA 微调 image encoder 外, 其余部分均是固定的. 训练目标和 CLIP 所用的对比学习保持一致, 所以整体上是非常简单的.
代码
[official-code]
注: 作者仅开源了部分代码.