Title
题目
End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography
低剂量胸部计算机断层扫描上的三维深度学习端到端肺癌筛查
01文献速递介绍
2018年估计有160,000例死亡病例,肺癌是美国最常见的癌症死因。低剂量计算机断层扫描进行肺癌筛查已经被证明可以将死亡率降低20–43%,现已纳入美国筛查指南。现存的挑战包括评分者之间的差异性和高假阳性和假阴性率。我们提出了一个深度学习算法,利用患者的当前和先前的计算机断层扫描体积来预测肺癌的风险。我们的模型在6,716例全国肺癌筛查试验案例中达到了最先进的性能(94.4%曲线下面积),并在一个独立的临床验证集中表现相似,该集合包含1,139例病例。我们进行了两项读者研究。当先前的计算机断层扫描图像不可用时,我们的模型优于所有六名放射科医生,假阳性率降低了11%,假阴性率降低了5%。在先前的计算机断层扫描图像可用时,模型的性能与相同的放射科医生相当。这为通过计算机辅助和自动化来优化筛查流程创造了机会。虽然绝大多数患者仍未接受筛查,但我们展示了深度学习模型提高全球肺癌筛查的准确性、一致性和采纳率的潜力。
2013年,美国预防服务任务部队基于国家肺癌筛查试验(NLST)中报告的改善死亡率,推荐在高风险人群中进行低剂量计算机断层扫描(LDCT)肺癌筛查。2014年,美国放射学院发布了LDCT肺癌筛查的Lung-RADS指南,以标准化放射科医生的图像解释并规定管理建议。评估基于各种图像发现,但主要是结节大小、密度和生长。在筛查站点,使用Lung-RADS和其他模型(如PanCan)来确定驱动临床管理建议的恶性风险评级。改善肺癌筛查的灵敏度和特异度至关重要,因为由于假阴性和假阳性而导致的漏诊、延迟诊断和不必要的活检程序会带来高昂的临床和财务成本。尽管Lung-RADS的一致性得到了改善,但持续存在的评分者之间的变异性和对综合性图像发现的不完全表征仍然是其局限性。这些局限性提出了更复杂的系统改进性能和评分者间一致性的机会。深度学习方法提供了自动化更复杂的图像分析、检测微妙的整体性图像发现并统一图像评估方法的激动人心的潜力。
Method
方法
Development and validation datasets. We used data from the NLST study, consisting of 42,290CT cases from 14,851patients, 638 of whom developed biopsyconfrmed cancer within 1 year of a LDCT screening (see Extended Data Fig. 1 for more details on NLST dataset selection)41. Patients were randomly assigned to a training set (70%), a tuning set (15%) or a test set (15%). Because not all negative cases from NLST have been made publicly available, the training, tuning and test sets had cancer percentages of 3.9, 4.5 and 3.7, respectively (slightly higher than the 1–2% range reported for NLST in general and in real-world practice). Supplementary Tables 1, 2 and 3 describe demographics, scanner information and nodule and cancer characteristics for relevant subsets of this dataset. All participants enrolling in NLST signed an informed consent developed and approved by the screening centers’ IRBs, the National Cancer Institute (NCI) IRB and the Westat IRB. Additional details regarding cases in the dataset are available through the National Institutes of Health Cancer Data Access System. Briefy, LDCTs were collected from multiple institutions, with slice spacing varying from 1.25 to 5mm and scanner vendors varying by site. We fltered out the 5-mm scans to better represent the slice spacing of a typical modern screening protocol42, and the largest remaining slice spacing was 2.5mm. A diagnosis of lung cancer established by biopsy at any time during the same year as a screening case counted as a ground truth true-positive case. Tis included cases identifed as incidental cancers diagnosed during the same screening year as an initially negative screening exam. An exam was considered negative if the patient proved cancer-free on 1-year follow-up; patients in the trial had multi-year follow-up. Patients had up to 3 years of screening, all via LDCT and, in nearly all cases, only one visit occurred per year with exceptions made for patients with inadequate imaging or interval development of symptoms concerning for cancer. In cases where prior imaging was used for testing and development purposes, the screening exam from the preceding year was selected. As screening read data from NLST were gathered once per year for each patient, it was important also to evaluate the model once per year for each patient for our tuning and testing sets. We chose the latest case per screening year, since this was the most likely case to have generated the screening read because patients typically were asked to return only if imaging was inadequate. Within each case we used the best available reconstruction kernel (See Supplementary Information, Kernel selection) with the highest number of slices.
开发和验证数据集。我们使用了NLST研究的数据,包括来自14,851名患者的42,290例CT病例,其中638例在接受低剂量CT筛查后1年内确诊患有活检阳性的肺癌(有关NLST数据集选择的更多细节,请参见扩展数据图1)[41]。患者被随机分配到训练集(70%)、调整集(15%)或测试集(15%)中。由于并非所有来自NLST的阴性病例都已公开,因此训练、调整和测试集的癌症百分比分别为3.9%、4.5%和3.7%(略高于NLST一般和实际世界实践中报告的1–2%范围)。补充表1、2和3描述了该数据集的相关子集的人口统计学、扫描仪信息以及结节和癌症特征。所有参与NLST的患者都签署了由筛查中心的IRB、国家癌症研究所(NCI)IRB和Westat IRB开发和批准的知情同意书。有关数据集中病例的附加详细信息可通过国家卫生研究院癌症数据访问系统获得。简而言之,LDCT来自多个机构,切片间距从1.25到5mm不等,扫描仪供应商也因地点而异。我们过滤了5mm的扫描以更好地表示典型的现代筛查协议的切片间距[42],剩下的最大切片间距为2.5mm。在同一年内通过活检确诊为肺癌的诊断被视为真正阳性的基准事例。这包括在最初阴性筛查检查期间被诊断为偶发性癌症的病例。如果患者在1年的随访中被证实无癌症,那么检查被认为是阴性的;试验中的患者进行了多年的随访。患者进行了最多3年的筛查,全部通过LDCT进行,几乎所有情况下,每年只进行一次访视,对于影像不足或症状发展与癌症有关的患者,会有例外情况。在使用先前影像进行测试和开发的情况下,选择了前一年的筛查检查。由于NLST的筛查读数是每年一次收集一次的,因此对于我们的调整和测试集,对每个患者每年进行一次模型评估是很重要的。我们选择了每个筛查年度的最新案例,因为这是最有可能生成筛查读数的案例,因为通常只有在影像不足时才要求患者返回。在每个案例中,我们使用了最佳的可用重建核心(见补充信息,核心选择),其中包括最多的切片。
Figure
图
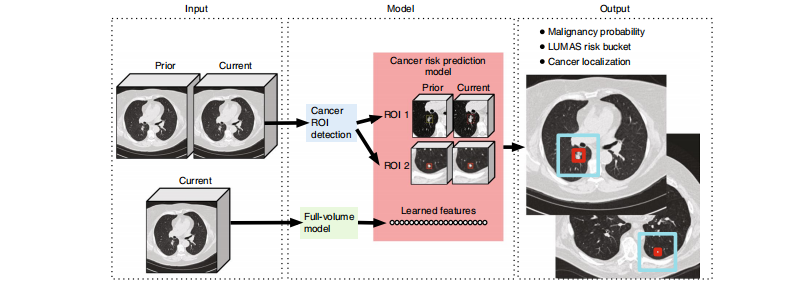
Fig. 1 | Overall modeling framework. For each patient, the model uses a primary LDCT volume and, if available, a prior LDCT volume as input. The model then analyzes suspicious and volumetric ROIs as well as the whole-LDCT volume and outputs an overall malignancy prediction for the case, a risk bucket score (LUMAS) and localization for predicted cancerous nodules.
图1 | 整体建模框架。对于每个患者,模型使用主要的低剂量CT体积,如果可用,还使用先前的低剂量CT体积作为输入。然后,该模型分析可疑和容积的感兴趣区域(ROI),以及整个低剂量CT体积,并输出该案例的总体恶性预测、风险桶得分(LUMAS)和预测的癌性结节的定位。
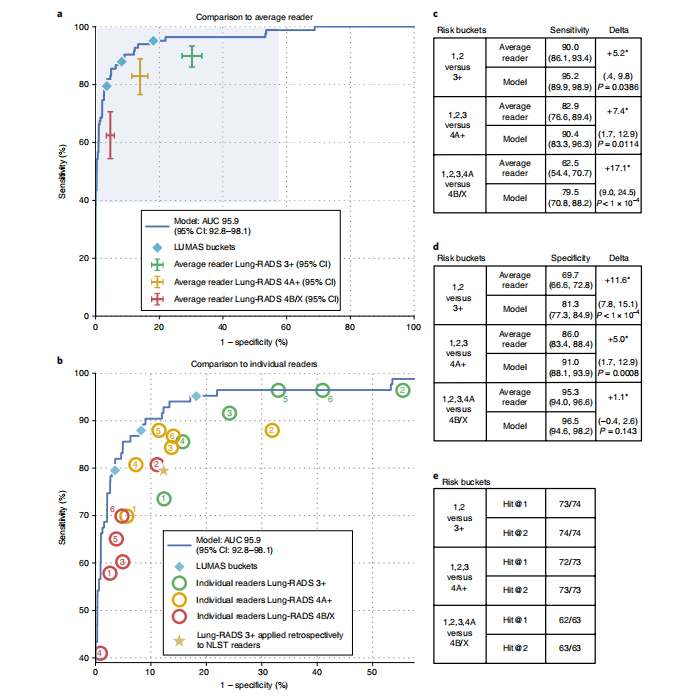
Fig. 2 | Results from the reader study—lung cancer screening on a single CT volume. a–e, Performance of radiologists and model in predicting malignancy using single screening CT volumes. Model performance shown in the AUC and summary tables is based on case-level malignancy score. LUMAS buckets refers to operating points selected to match the predicted probability of cancer for Lung-RADS 3+, 4A+ and 4B/X. a, Performance of model (blue line) versus average radiologist for various Lung-RADS categories (crosses) using a single CT volume. The length of the crosses represents the confidence Intervals (CIs). The area highlighted in blue is magnified in b to show the performance of each of the six radiologists at various Lung-RADS risk buckets. *c, Sensitivity comparison between model and average radiologist. d, Specificity comparison between model and average radiologist. Both sensitivity and specificity analyses were conducted with n= 507 volumes from 507 patients, with P values computed using a two-sided permutation test with 10,000 random resamplings of the data. e, Hit rate localization analysis used to measure how often the model correctly localized a cancerous lesion.
图2 |读者研究结果—单个CT体积的肺癌筛查。a–e,使用单个筛查CT体积预测恶性肿瘤的放射科医生和模型的性能。在AUC和摘要表中显示的模型性能是基于病例级别的恶性评分。LUMAS桶是指选择的操作点,以匹配Lung-RADS 3+、4A+和4B/X的癌症预测概率。a,使用单个CT体积,模型(蓝线)与平均放射科医生在不同Lung-RADS类别(十字)上的性能。十字的长度表示置信区间(CI)。蓝色突出显示的区域在b中放大,以显示六名放射科医生在不同Lung-RADS风险桶中的性能。c,模型与平均放射科医生的敏感性比较。d,模型与平均放射科医生的特异性比较。敏感性和特异性分析均使用来自507名患者的507个体积进行,使用双侧置换检验计算P*值,数据进行10,000次随机重采样。e,用于衡量模型正确定位癌性病变的命中率定位分析。
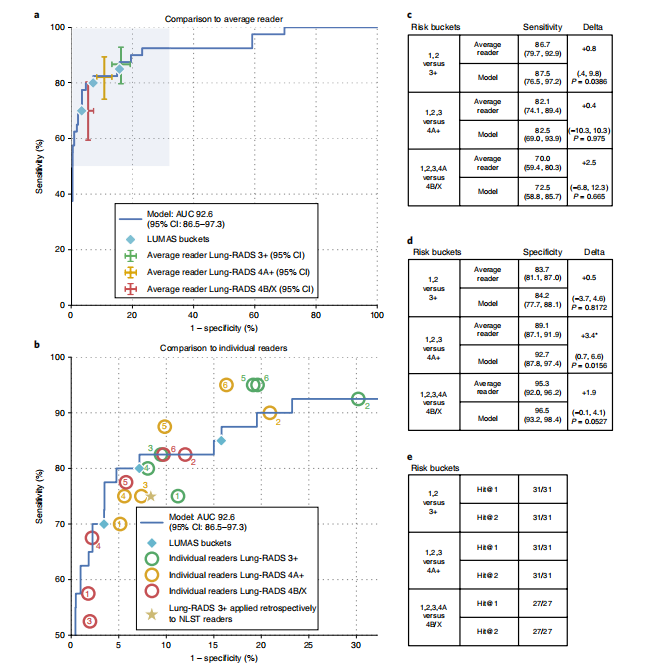
Fig. 3 | Results from the reader study—lung cancer screening using current and prior CT volume. a–e, Model performance in the AUC curve and summary tables is based on case-level malignancy score. The term ‘LUMAS buckets’ refers to operating points selected to represent sensitivity/specificity at the 3+, 4A+ and 4B/X thresholds. a, Performance of model (blue line) versus average radiologist at various Lung-RADS categories (crosses) using a CT volume and a prior CT volume per patient. The length of the crosses represents the 95% confidence interval. The area highlighted in blue is magnified in b to show the performance of each of the six radiologists at various Lung-RADS categories in this reader study. c, Sensitivity comparison between model and average radiologist. d, Specificity comparison between model and average radiologist. Both sensitivity and specificity analyses were conducted with n*= 308 volumes from 308 patients, with P values computed using a two-sided permutation test with 10,000 random resamplings of the data. e, Hit rate localization analysis to measure how often the model correctly localized a cancerous lesion.
图3 | 读者研究结果—使用当前和先前的CT体积进行肺癌筛查。a–e,AUC曲线和摘要表中的模型性能基于病例级别的恶性评分。术语“LUMAS桶”是指选择的操作点,用于表示在3+、4A+和4B/X阈值处的敏感性/特异性。a,使用每个患者的一个CT体积和一个先前的CT体积,模型(蓝线)与平均放射科医生在不同的Lung-RADS类别(十字)上的性能。十字的长度表示95%的置信区间。蓝色突出显示的区域在b中放大,以显示在本读者研究中每个六名放射科医生在不同Lung-RADS类别中的性能。c,模型与平均放射科医生的敏感性比较。d,模型与平均放射科医生的特异性比较。敏感性和特异性分析均使用来自308名患者的308个体积进行,使用双侧置换检验计算P值,数据进行10,000次随机重采样。e,命中率定位分析,用于衡量模型正确定位癌性病变的频率。
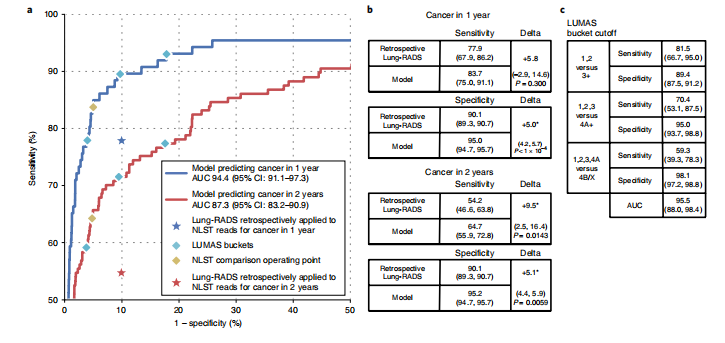
Fig. 4 | Results of the full NLST and independent test sets. a, Comparison of model performance to NLST reader performance on the full NLST test set. NLST reader performance was estimated by retrospectively applying Lung-RADS 3 criteria to the NLST reads. b, Sensitivity and specificity comparisons between the model and Lung-RADS retrospectively applied to NLST reads. The comparison was performed on n= 6,716 cases, using a two-sided permutation test using 10,000 random resamplings of the data. c, Sensitivity and specificity of different LUMAS buckets on an independent dataset comprising n= 1,139 cases using the same two-sided set with 10,000 random resamplings. The full AUC plot is shown in Extended Data Fig. 5a.
图4 | 全面的NLST和独立测试集的结果。a,将模型性能与完整的NLST测试集上的NLST读者性能进行比较。NLST读者性能是通过回顾性地应用Lung-RADS 3标准到NLST读数中来估计的。b,模型与回顾性应用于NLST读数的Lung-RADS之间的敏感性和特异性比较。该比较在n= 6,716个案例上进行,使用两侧的置换检验进行10,000次随机重采样数据。c,不同LUMAS桶的敏感性和特异性在一个包含n= 1,139个案例的独立数据集上的比较,使用相同的双侧置换检验进行10,000次随机重采样。完整的AUC图在扩展数据图5a中显示。



![[Diffusion Model笔记] DDPM数学推导版 2024.04.23](https://img-blog.csdnimg.cn/direct/98e2bd2cc76b4d6bb5c3ddafc7eb96d3.png)