CyberData统一元数据服务功能完善,实现了湖仓平台元数据在整个平台的统一管理以及外部数据源元数据的主动发现和多计算引擎间元数据的互通互联。
同时,我们支持跨多元计算场景,以及在元数据基础上的统一数据权限管理和数据湖的自动化优化加速。
满足多元异构大数据计算引擎对元数据的需求。支持与Hive Metastore集成,通过Hive的标准化的元数据能力,为不同的分析计算引擎提供元数据管理和服务;支持基于Spark和Flink的自定义Catalog扩展机制,支持支持更大范围的数据源元数据管理能力,使Spark和Flink引擎能够访问关系型数据库,以及实现与湖仓数据源之间的跨源数据访问。
通过统一调度引擎的能力,满足元数据采集高性能、高可用,通过全文搜索引擎和图引擎能力提高元数据全文快速、高可用查询。
数据血缘支持API自定义血缘模型,灵活性高;基于Antlr语法解析,扩展性高;支持异构数据源间血缘构建;架构简洁,易接入,不强绑定和依赖数据底座引擎;准确率能够达到98%以上。
元数据部署规格可根据用户元数据体量灵活适配。
01 元数据架构设计
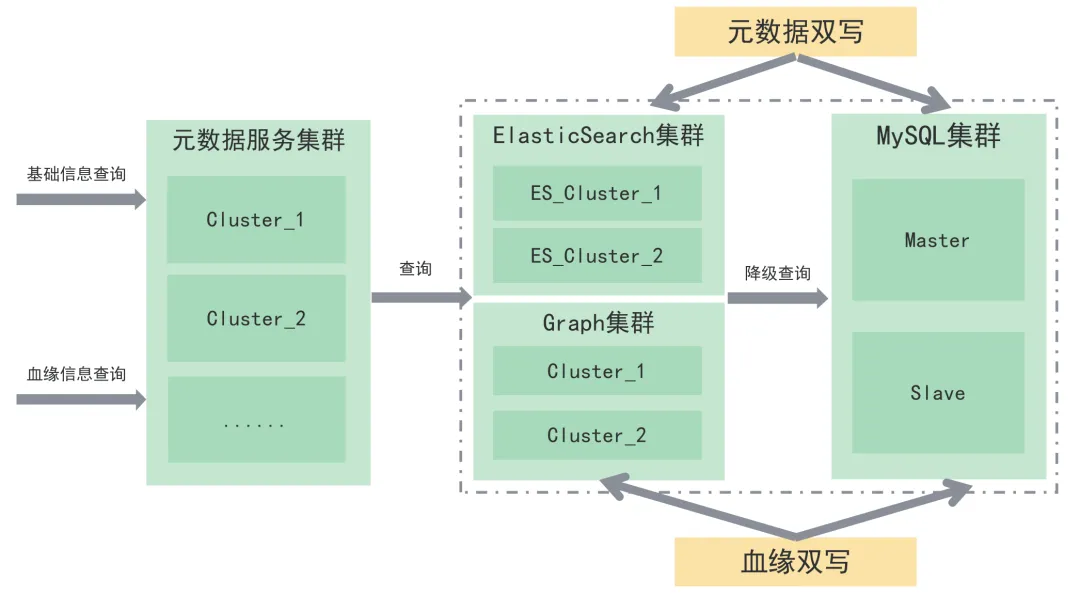
元数据统一存储:
MySQL+ElasticSearch+Graph Engine;
统一元数据服务,高度抽象元数据对外API、支持高可用集群部署。
统一Catalogo模型设计优势:
-
支持用户自定义Catalog;
-
同源数据源自动绑定已有Catalog;
-
元数据集中管理,统一Catalog数据目录:规范元数据检索、存储;
-
支持异构数据源间数据交互场景:如通过Catalog数据·目录去做Oracle数据源JOIN MySQL数据源查询;
-
联邦查询:更好的跨数据源的查询。
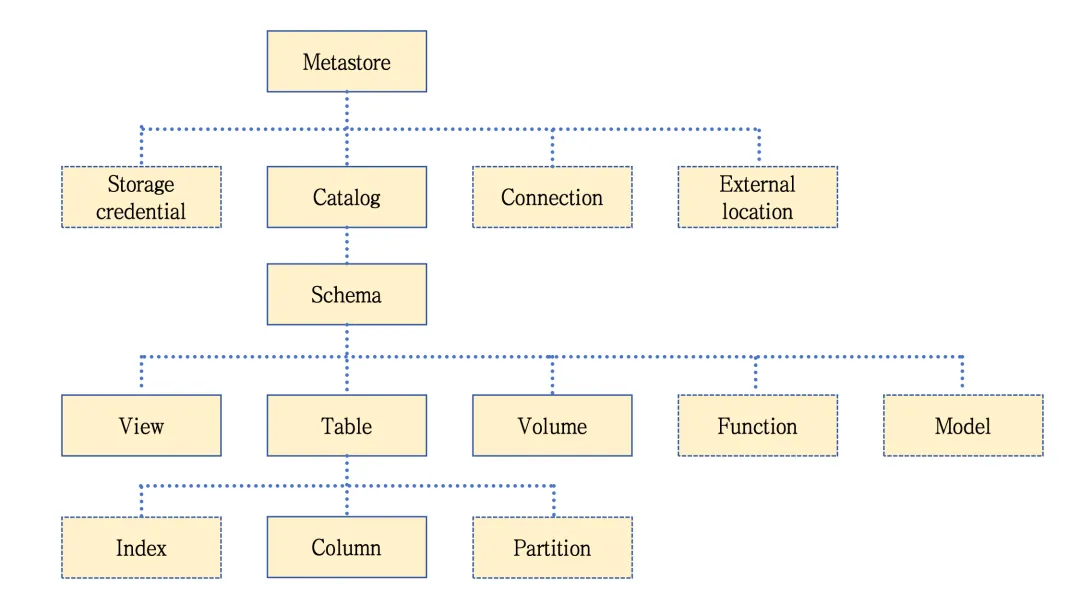
元数据guid的唯一模型设计:
通过guid快速的定位一个表或者列,例如定位元数据表列信息可通过catalogName、schema、tableName、columnName 快速定位,从而确保元数据的唯一性,避免了数据重复、冲突和混淆,更方便的对外透出统一查询元数据的能力。
02 统一数据血缘技术
通过数据开发、埋点、API导入与血缘应用四种方式触发血缘,以消息队列(MQ)的形式接受血缘;通过API(Http/REST)的方式构建统一血缘入口,进行统一血缘的解析后转化为统一的模型进行存储。
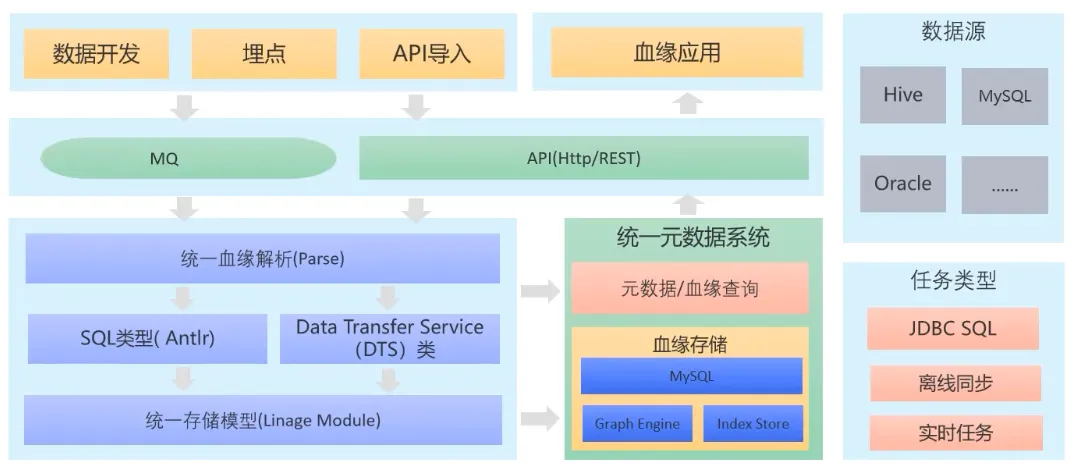
目前血缘支持JDBCSQL、离线同步、实时任务、FlinkSQL四种任务类型。
当下血缘解析具有以下优势:
-
灵活性高,支持API自定义血缘模型,通过API快速构建血缘;
-
扩展性高,基于Antlr语法进行解析,灵活适配不同的数据库SQL语法;
-
支持异构数据源间血缘构建,如MySQL到Hive,Oracle到Starrocks等;
-
架构简洁,易接入;
-
不强绑定和依赖数据底座引擎(如HiveHook机制);
-
当下血缘解析淮确率>98%。
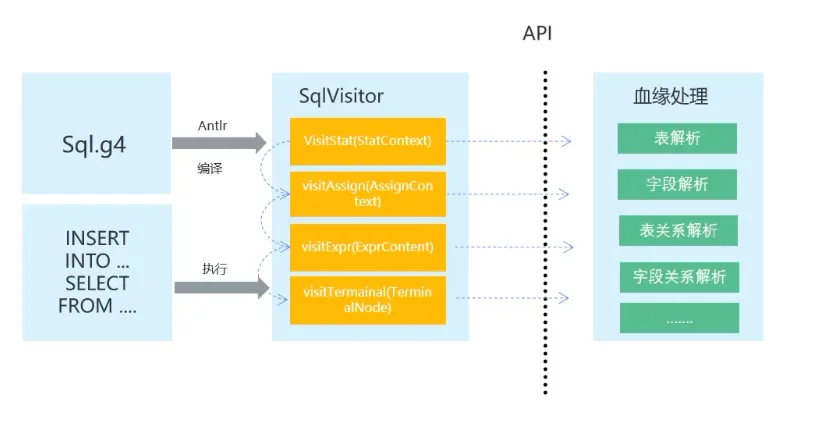
通过Antlr定义的语法树编译自动构建解析代码后,用户通过Antllr Vistor访问模式构建血缘信息。
基于Antlr的血缘解析流程高度灵活,可兼容所有SQl语法;扩展性极高,支持自定义的抽象语法;同时具有强大的自动生成代码后实现解析逻辑。
03 元数据技术优势
元数据采集高可用容灾
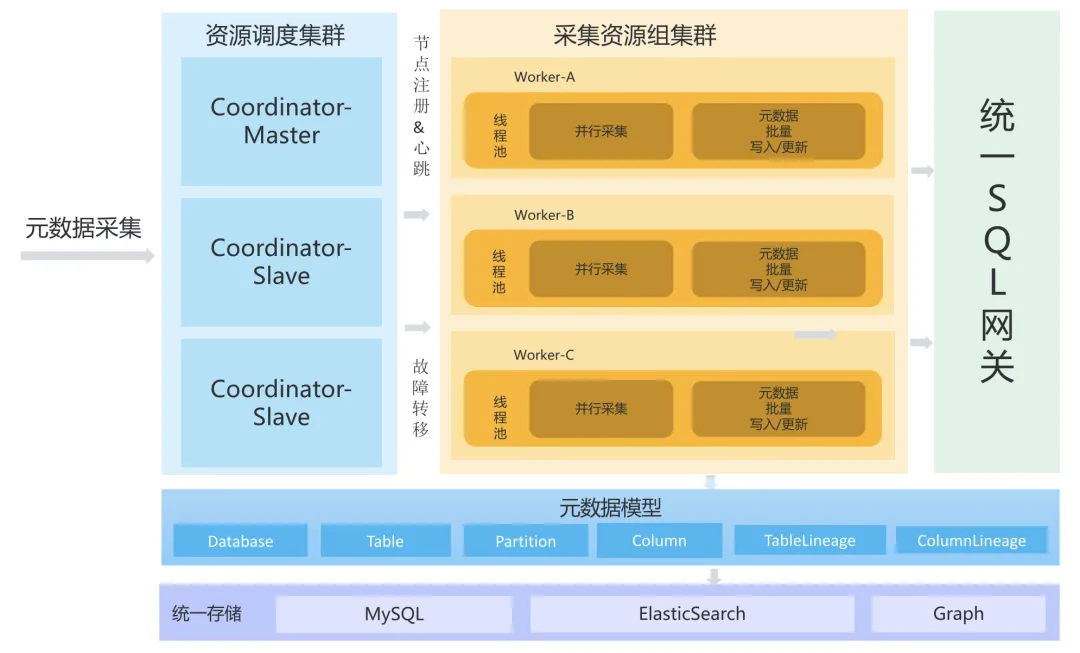
元数据高性能、高可用查询
-
集群部署多节点,支持多种维度检索元数据,查询速度快,血缘全链路查询,根据用户元数据体量灵活部署;
-
血缘构建方式多样:DTS、SQL解析、API构建、Hook引擎;
-
血缘准实时解析;
-
血缘解析支持的引擎:Hive、SparkSQL、FlinkSQL、 Gauss、StarRocks, Doris、OceanBase、ClickHouse、MaxCompute等15+;
-
数据源支持情况 MySQL、SQLServer、Oracle、PG、DM、DB2、PolarDB、Sysbase、GBase + 等。