springboot整合log4j2
log4j2相信大家非常常见了,以前基本去了项目每个都有,然后也都直接用,很少有时间研究过它,这不这两天稍微空了点,学习了下,然后写下了这篇文章记录。
本文主要大纲
- springboot整合log4j2
- 一. Spring基本配置
- 二. 一个完整的log4j2.xml文件展示
- 三. xml文件中重要标签详解
- 四. level属性的含义和层级关系详解
一. Spring基本配置
1.springboot有个默认的日志框架,首先我们要在Maven依赖中移除它:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId><exclusions><exclusion><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-logging</artifactId></exclusion></exclusions>
</dependency>
2.加入log4j2的依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-log4j2</artifactId></dependency>
3.灵活配置。我们知道springboot的配置,可以用spring.profiles.active去灵活配置开发环境和线上环境,日志配置也有相同的实现方法。
只需要在application.properties中去指定配置的文件名就好
logging.config=classpath:log4j2.xml
所以log4j2.xml的命名可以多个,比如log4j2-dev.xml,log4j2-release.xml等,然后在这里灵活切换。我这里因为就单一环境,所以直接用log4j2.xml。
4.添加一个启动类(启动类命名为了偷懒,就用以前的demo),加入测试代码,就可以进行下一步了。
@SpringBootApplication
public class LeetcodeTestApplication{private static final Logger logger = LoggerFactory.getLogger(LeetcodeTestApplication.class);public static void main(String[] args) {SpringApplication.run(LeetcodeTestApplication.class, args);logger.trace("test:{}",1);logger.debug("test:{}",2);logger.info("test:{}",3);logger.warn("test:{}",4);logger.error("test:{}",5);}
}
二. 一个完整的log4j2.xml文件展示
<?xml version="1.0" encoding="UTF-8"?>
<configuration><!--变量配置--><Properties><!-- 定义日志存储的路径 --><property name="FILE_PATH" value="./logs"/><property name="FILE_NAME" value="Log4j2Test"/></Properties><appenders><Console name="Console" target="SYSTEM_OUT"><!-- 日志级别过滤策略 --><Filters><ThresholdFilter level="info" onMatch="ACCEPT" onMismatch="DENY"/></Filters><!--设置日志格式及颜色--><PatternLayoutpattern="%style{%d{ISO8601}}{bright,green} %highlight{%-5level} [%style{%t}{bright,blue}] %style{%C{}}{bright,yellow}: %msg%n%style{%throwable}{red}"disableAnsi="false" noConsoleNoAnsi="false"/></Console><!-- 这个会打印出所有的info及以下级别的信息,每次大小超过size,则这size大小的日志会自动存入按年份-月份建立的文件夹下面并进行压缩,作为存档--><RollingFile name="RollingFileInfo" fileName="${FILE_PATH}/info.log"filePattern="${FILE_PATH}/${FILE_NAME}-INFO-%d{yyyy-MM-dd}_%i.log.gz"><!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch)--><ThresholdFilter level="info" onMatch="ACCEPT" onMismatch="DENY"/><PatternLayout pattern="${LOG_PATTERN}"/><Policies><!--interval属性用来指定多久滚动一次,默认是1 hour--><TimeBasedTriggeringPolicy interval="1"/><SizeBasedTriggeringPolicy size="10MB"/></Policies><!-- DefaultRolloverStrategy属性如不设置,则默认为最多同一文件夹下7个文件开始覆盖--><DefaultRolloverStrategy max="15"/></RollingFile><!-- 这个会打印出所有的warn及以下级别的信息,每次大小超过size,则这size大小的日志会自动存入按年份-月份建立的文件夹下面并进行压缩,作为存档--><RollingFile name="RollingFileWarn" fileName="${FILE_PATH}/warn.log"filePattern="${FILE_PATH}/${FILE_NAME}-WARN-%d{yyyy-MM-dd}_%i.log.gz"><!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch)--><ThresholdFilter level="warn" onMatch="ACCEPT" onMismatch="DENY"/><PatternLayout pattern="${LOG_PATTERN}"/><Policies><!--interval属性用来指定多久滚动一次,默认是1 hour--><TimeBasedTriggeringPolicy interval="1"/><SizeBasedTriggeringPolicy size="10MB"/></Policies><!-- DefaultRolloverStrategy属性如不设置,则默认为最多同一文件夹下7个文件开始覆盖--><DefaultRolloverStrategy max="15"/></RollingFile><!-- 这个会打印出所有的error及以下级别的信息,每次大小超过size,则这size大小的日志会自动存入按年份-月份建立的文件夹下面并进行压缩,作为存档--><RollingFile name="RollingFileError" fileName="${FILE_PATH}/error.log"filePattern="${FILE_PATH}/${FILE_NAME}-ERROR-%d{yyyy-MM-dd}_%i.log.gz"><!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch)--><ThresholdFilter level="error" onMatch="ACCEPT" onMismatch="DENY"/><PatternLayout pattern="${LOG_PATTERN}"/><Policies><!--interval属性用来指定多久滚动一次,默认是1 hour--><TimeBasedTriggeringPolicy interval="1"/><SizeBasedTriggeringPolicy size="10MB"/></Policies><!-- DefaultRolloverStrategy属性如不设置,则默认为最多同一文件夹下7个文件开始覆盖--><DefaultRolloverStrategy max="15"/></RollingFile></appenders><!--Logger节点用来单独指定日志的形式,比如要为指定包下的class指定不同的日志级别等。--><!--然后定义loggers,只有定义了logger并引入的appender,appender才会生效--><loggers><root level="info"><appender-ref ref="Console" level="info"/><appender-ref ref="RollingFileInfo"/><appender-ref ref="RollingFileWarn"/><appender-ref ref="RollingFileError"/></root></loggers></configuration>
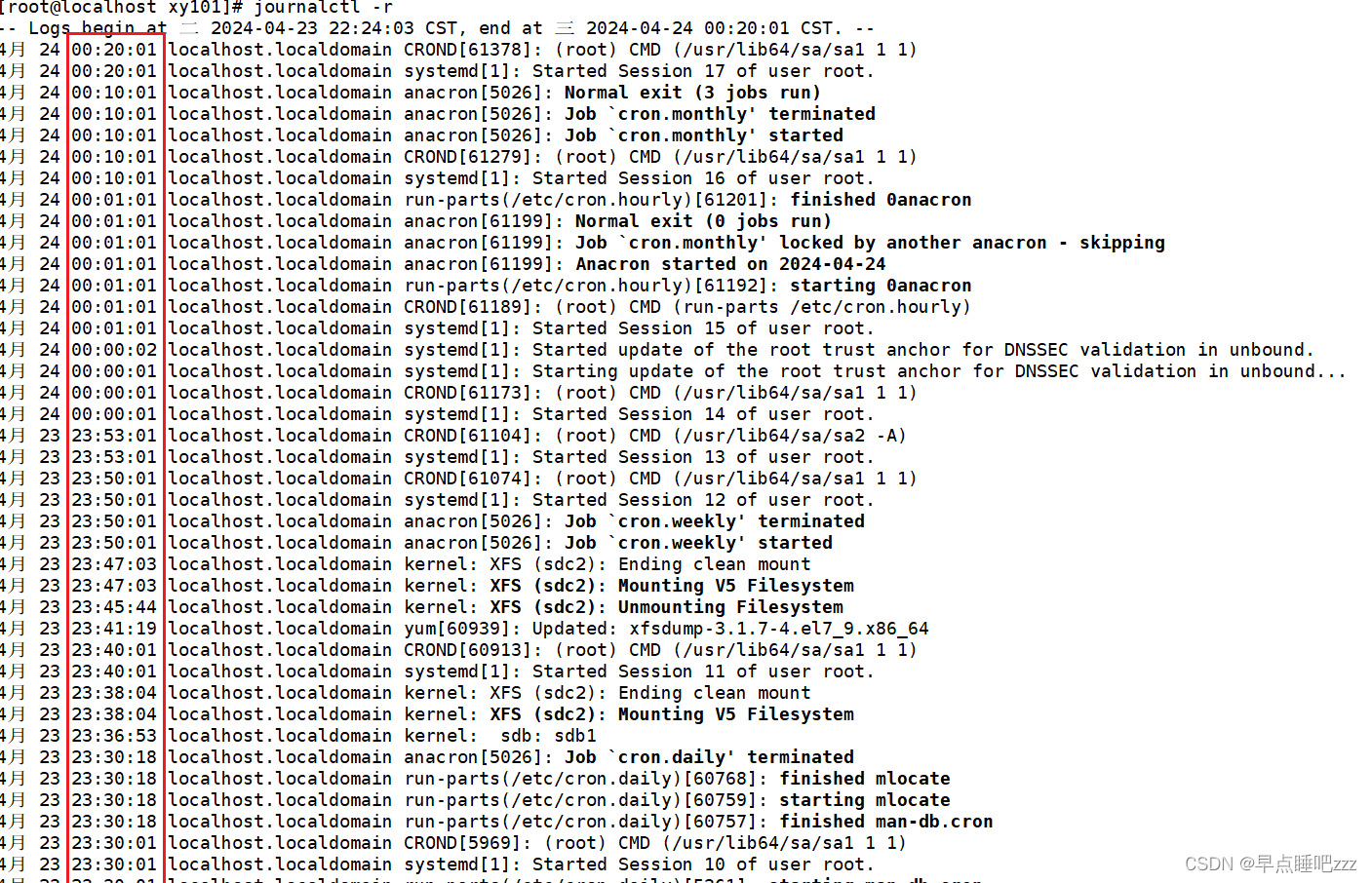
运行我们刚刚的测试代码,效果图如下:

三. xml文件中重要标签详解
-
<configuration>:整个xml文件最外层的标签,上面常见的属性有两个,<Configuration status=“WARN” monitorInterval=“30”>
- status:是用于指定log4j的级别,不常用,因为我们会在其它更细致的地方去指定级别。
- monitorterval:是用于指定log4j自动重新检测读取配置内容的间隔时间,单位为秒(s),最小值为5秒。如果你的项目有自动检测刷新的需求,就把这个参数加上。
-
<Properties>:属性标签,也可以叫变量标签,在这里定义我们常用的一些变量,比如日志生成目录的地址,一些特殊的前缀名等,可以理解为声明变量,比如int a = 1,然后在后面的内容中去使用变量a。
- 这个例子就定义了生成日志文件的目录:<property name=“FILE_PATH” value=“./logs”/>,后面用${FILE_PATH}就能获取到这个路径。
-
<Appenders>:核心区域部分,里面定义了很多Appender去自定义我们的日志内容。
-
<Console>:Appender的一种,设置控制台的输出,
-
<Filters>:过滤器,里面常用的就是日志级别过滤标签《ThresholdFilter》,后面的内容会详细讲解level,这里先略过。
-
<PatternLayout>:Appender中设置输出格式的标签,这里可以设置日期、不同的level输出颜色等。不设置的话,默认为:%m%n
-
<RollingFile>:我们的线上服务器,查过往日志的时候,都会发现按照年月日很工整的存放起来的,然后里面是个gz压缩文件,这个功能的实现,就是这个标签来控制的。 这个标签的属性
- name:Appender的名字,每个Appender的通用属性。
- fileName,要打包的日志文件名。
- filePattern:打包后的gz文件目录和格式
例如:<fileName=“${FILE_PATH}/info.log” filePattern=“${FILE_PATH}/${FILE_NAME}-INFO-%d{yyyy-MM-dd}_%i.log.gz”>,这样设置的含义就是:将fileName为info.log的文件以特定格式打包到filePattern目录下,如果还不理解的就看看效果图:
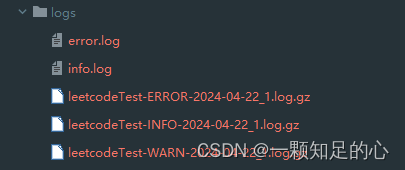
由于本文第二大点的xml文件中设置了info、error、warn三个,所以这里会分别出现三个gz文件。当然我们这里还可以设置文件夹名,让他通过时间来创建不同的文件夹:filePattern=“logs/$${date:yyyy-MM}/${FILE_NAME}-INFO-%d{yyyy-MM-dd}_-%i.log.gz”>
- <Policies>:RollingFile标签的内标签,表述打包写文件的策略,常用的两个设置就是基于日志文件大小的策略和基于时间的策略。注意:压缩完成后将清空当前文件(fileName指定的文件)
- <SizeBasedTriggeringPolicy size=“20MB”/>:日志先写入logs/info.log中,每当文件大小达到20MB时或经过1天,按照在logs/2024-04/目录下以app-2024-04-23-1.log.gz格式对该日志进行压缩重命名并归档,并生成新的文件info.log进行日志写入
- <TimeBasedTriggeringPolicy interval=“6” modulate=“true”/>:表示每过6小时,就进行一次当前文件压缩打包并重新生成新文件进行日志写入。
- <DefaultRolloverStrategy max=“10”/>,和上面filePattern的%i对应类似于整数计数器,当文件个数达到10个的时候会循环覆盖前面已归档的1-10个文件。若不设置该参数,默认为7。
-
<loggers>:日志系统的根记录器
- Root:用于指定项目的根日志,level属性表示日志输出级别,子节点AppenderRef用于指定输出到某个Appender,子节点的ref属性也就是前面的RollingFile中指定的name名称,子节点的level也是日志输出级别。2.7版本后,可以换成AsyncRoot去异步处理,不会阻塞应用程序的主线程,提高性能。
- Logger :用于指定日志的形式,指定不同包的日志级别,level属性表示日志输出级别,name属性用来指定该Logger所适用的类或者类的全路径。子节点AppenderRef用于指定日志输出到哪个Appender,若没有指定,默认集成自Root。
<loggers><root level="trace"><appender-ref ref="Console" level="trace"/><appender-ref ref="RollingFileInfo"/><appender-ref ref="RollingFileWarn"/><appender-ref ref="RollingFileError"/></root></loggers><Logger name="com.alibaba.cloud.dubbo" level="error"/>高级扩展,异步日志:使用下面标签需要加入 disruptor依赖。
- AsyncRoot:<AsyncRoot level=“info” additivity=“false” includeLocation=“true”> ,additivity:需不需要打印此logger继承的父logger,false则只打印当前Logger
- RollingRandomAccessFile:有缓冲区的RollingFile,性能更好。
四. level属性的含义和层级关系详解
-
常用日志级别排序:trace<debug<info<warn<error**
-
日志level层级关系
在目录二中的log4j2.xml文件中,我们可以看到很多地方都在用level字段,到底依哪个为准?下面就将给你说说,按照层级顺序:
第一:root标签上的level,最高标准(排除configuration),下面的appender-ref标签,如果不指定level的话,默认使用root标签上的level,如果某个日志消息的级别低于此级别,它将被忽略。
第二:appender-ref标签上的level,它只能设置比root的level高,不然会被忽略。
第三:ThresholdFilter标签上的level,它只能设置比appender-ref的level高,不然会被忽略。 -
ThresholdFilter详解:
(1)属性详解
onMatch="ACCEPT"匹配该级别及以上级别;
onMatch="DENY"不匹配该级别及以上级别;onMismatch=“ACCEPT” 表示匹配该级别以下的级别;
onMismatch=“DENY” 表示不匹配该级别以下的级别;
“NEUTRAL”:中立策略,不讨论。(2). 单一应用
匹配INFO级别以及以上级别,不匹配INFO级别以下级别,即: 匹配 >= INFO的级别
<ThresholdFilter level="INFO" onMatch="ACCEPT" onMismatch="DENY"/>不匹配WARN级别以及以上级别,匹配WARN级别以下级别,即: 匹配 < WARN的级别
<ThresholdFilter level="WARN" onMatch="DENY" onMismatch="ACCEPT"/>
几个例子总结一下:
1.root的level为error,ppender-ref为info,ThresholdFilter为info,最后只输出error。
2.root的level为info,ppender-ref为warn,ThresholdFilter为info,最后只输出大于等于warn的。
2.root的level为info,ppender-ref为info,ThresholdFilter为warn,最后只输出大于等于warn的。
最后一句话,root最高优先级,appender-ref第二优先级,ThresholdFilter最低优先级。