「Kafka」Kafka单机和集群安装(二)
- 一、单机启动
- 1. 下载安装Kafka
- 2. 启动ZooKeeper
- 2. 启动Kafka
- 二 、集群启动
- 1. 安装zookeeper
- 2. 安装kakfa
- 3. 封装启动脚本
一、单机启动
1. 下载安装Kafka
阿里云下载地址:Kafka阿里云镜像站,官方下载地址:Kafka官网下载地址,下载
kafka_2.13-3.7.0.tgz,下载后解压到你选择的目录
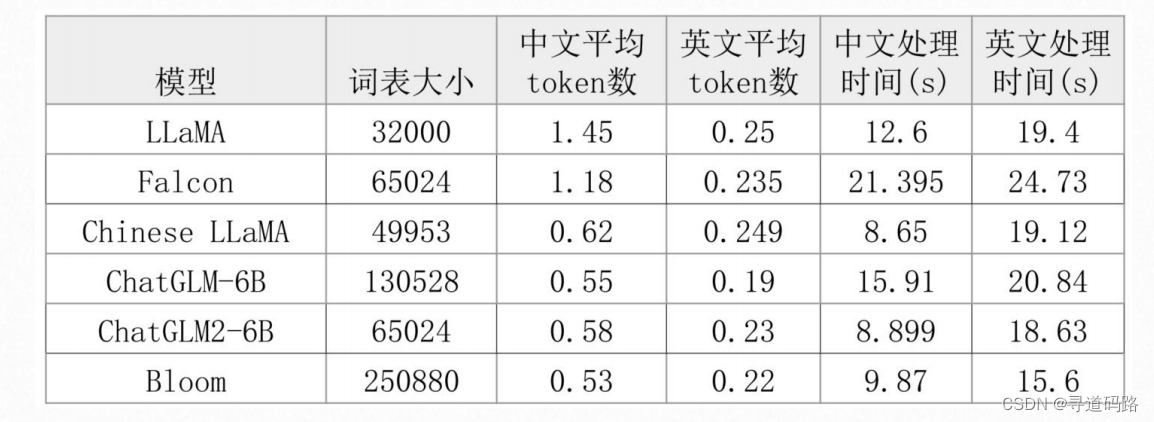
- 这里的3.7.0,是Kafka软件的版本。截至到日期,Kafka最新版本为3.7.0。
- 2.13是对应的Scala开发语言版本。Scala2.13和Java8是兼容的,所以可以直接使用。
- tgz是一种linux系统中常见的压缩文件格式,类似与windows系统的zip和rar格式。所以Windows环境中可以直接使用压缩工具进行解压缩。
- 为了方便将目录改为Kafka
- 目录结构如下所示
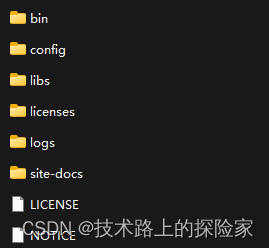
2. 启动ZooKeeper
当前版本Kafka软件内部依然依赖ZooKeeper进行多节点协调调度,所以启动Kafka软件之前,需要先启动ZooKeeper软件。不过因为Kafka软件本身内置了ZooKeeper软件,所以无需额外安装ZooKeeper软件,直接调用脚本命令启动即可。具体操作步骤如下:
- 进入Kafka解压缩文件夹的config目录,修改zookeeper.properties配置文件
# the directory where the snapshot is stored.
# 修改dataDir配置,用于设置ZooKeeper数据存储位置,该路径如果不存在会自动创建。
dataDir=E:/Kafka/data/zk
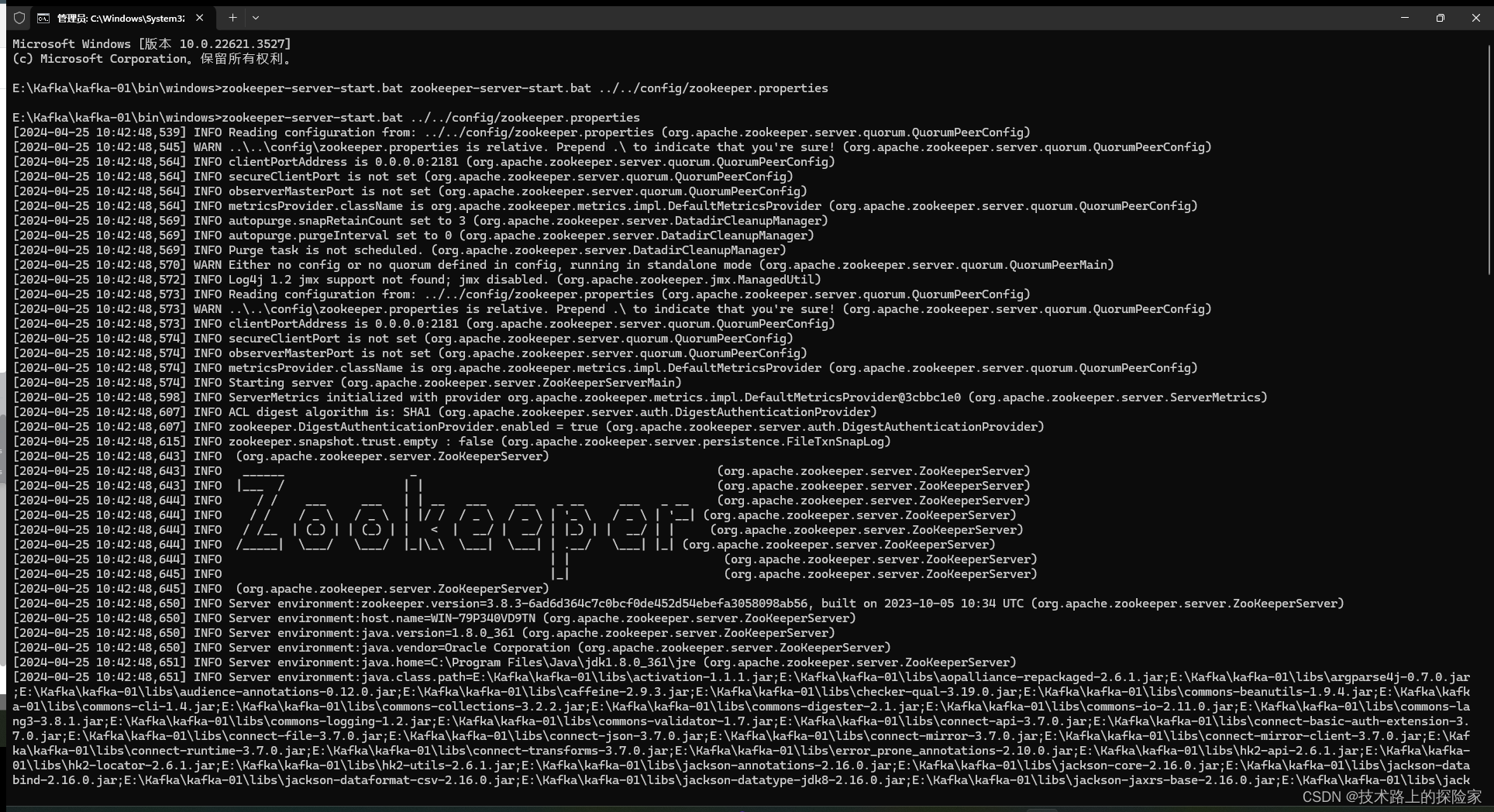
- 进入\bin\windows目录下启动zookeeper
# 启动命令
zookeeper-server-start.bat ../../config/zookeeper.properties
- 为了方便也可以在kafka目录下创建启动脚本
zk.bat,下次启动直接点击zk.bat即可
# 调用启动命令,且同时指定配置文件。
call bin/windows/zookeeper-server-start.bat config/zookeeper.properties
2. 启动Kafka
- 进入Kafka解压缩文件夹的config目录,修改server.properties配置文件
# If not set, it uses the value for "listeners".
# 客户端访问Kafka服务器时,默认连接的服务为本机的端口9092,如果想要改变,可以修改如下配置
# 此处我们不做任何改变,默认即可
#advertised.listeners=PLAINTEXT://your.host.name:9092# A comma separated list of directories under which to store log files
# 配置Kafka数据的存放位置,如果文件目录不存在,会自动生成。
log.dirs=E:/Kafka/data/kafka
- 为了操作方便,也可以在kafka解压缩后的目录中,创建脚本文件
kfk.cmd
call bin/windows/kafka-server-start.bat config/server.properties
二 、集群启动
1. 安装zookeeper
- 在磁盘根目录创建文件夹cluster,
文件夹名称不要太长 - 将全新的文件包放入到cluster目录下,并命名为zookeeper
- 修改config/zookeeper.properties文件
# 日志目录
dataDir=E:/Kafka/cluster/zookeeper/data
# ZooKeeper默认端口为2181
clientPort=2181
2. 安装kakfa
- 将zookeeper目录复制一份到cluster目录下,并且命名为Kafka-node1
- 修改config/server.properties配置文件
# kafka节点数字标识,集群内具有唯一性
broker.id=1
# 监听器 9091为本地端口,如果冲突,请重新指定
listeners=PLAINTEXT://:9091
# 数据文件路径,如果不存在,会自动创建
log.dirs=E:/Kafka/cluster/Kafka-node1/data
# ZooKeeper软件连接地址,2181为默认的ZK端口号 /kafka 为ZK的管理节点
zookeeper.connect=localhost:2181/kafka
- 将kafka-node1文件夹复制两份,改名为kafka-node2,kafka-node3
- 分别修改kafka-node2,kafka-node3文件夹中的配置文件server.properties
将文件内容中的broker.id=1分别改为broker.id=2,broker.id=3
将文件内容中的9091分别改为9092,9093(如果端口冲突,请重新设置)
将文件内容中的kafka-node-1分别改为kafka-node-2,kafka-node-3
3. 封装启动脚本
因为Kafka启动前,必须先启动ZooKeeper,并且Kafka集群中有多个节点需要启动,所以启动过程比较繁琐,这里我们将启动的指令进行封装
- 在zookeeper文件夹下创建zk.bat批处理文件
- 在zk.cmd文件中添加内容
# 添加启动命令
call bin/windows/zookeeper-server-start.bat config/zookeeper.properties
- 在kafka-node-1,kafka-node-2,kafka-node-3文件夹下分别创建kfk.bat批处理文件

- 在kfk.bat文件中添加内容
# 添加启动命令
call bin/windows/kafka-server-start.bat config/server.properties
-
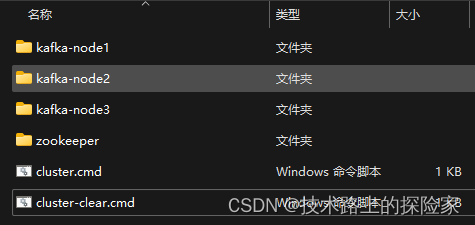
在cluster文件夹下创建cluster.cmd批处理文件,用于启动kafka集群

-
在cluster.cmd文件中添加内容
cd zookeeper
start zk.bat
ping 127.0.0.1 -n 10 >nul
cd ../kafka-node1
start kfk.bat
cd ../kafka-node2
start kfk.bat
cd ../kafka-node3
start kfk.bat
-
在cluster文件夹下创建cluster-clear.cmd批处理文件,用于清理和重置kafka数据

-
在cluster-clear.cmd文件中添加内容
cd zookeeper
rd /s /q data
cd ../kafka-node1
rd /s /q data
cd ../kafka-node2
rd /s /q data
cd ../kafka-node3
rd /s /q data
- 双击执行cluster.cmd文件,启动Kafka集群
集群启动命令后,会打开多个黑窗口,每一个窗口都是一个kafka服务,请不要关闭,一旦关闭,对应的kafka服务就停止了。如果启动过程报错,主要是因为zookeeper和kafka的同步问题,请先执行cluster-clear.cmd文件,再执行cluster.cmd文件即可。