通过爬虫技术抓取网页,动态加载的数据或包含 JavaScript 的页面,需要使用一些特殊的技术和工具。以下是一些常用的技术方法:
-
使用浏览器模拟器:使用像 Selenium、PhantomJS 或其他类似工具可以模拟一个完整的浏览器环境,这些工具都可以执行JavaScript并且返回渲染后的页面内容。使用这种方法可以模拟用户与网站的交互,从而得到完整的运行时状态。
-
分析网络请求:使用网络抓包工具(例如 Fiddler、Wireshark)来监视网站上的网络请求。通过分析网络请求并确定用于检索数据的URL,可以获取请求数据并解析响应数据,从而获得所需的信息。
-
解析 JavaScript 代码:有些网站将数据存储在 JavaScript 中并动态显示在页面上。使用 JavaScript 解析器(例如 jsdom、PyV8 等)可以执行 JavaScript 代码并解析响应结果,以获取所需的数据。
-
接口直接请求:有些网站提供专用的API(应用程序接口),用于向开发人员公开数据。这些API允许开发人员通过发送HTTP请求来获取特定数据,并且网络请求和响应数据通常以JSON格式进行编码。
总之,抓取动态加载的数据或包含JavaScript的页面需要深入了解目标网站的技术细节以及使用现代的网络爬虫技术来获取所需的信息。
本文采用使用浏览器模拟器技术方案。
1. 使用Chrome开发者工具精确定位网页元素位置
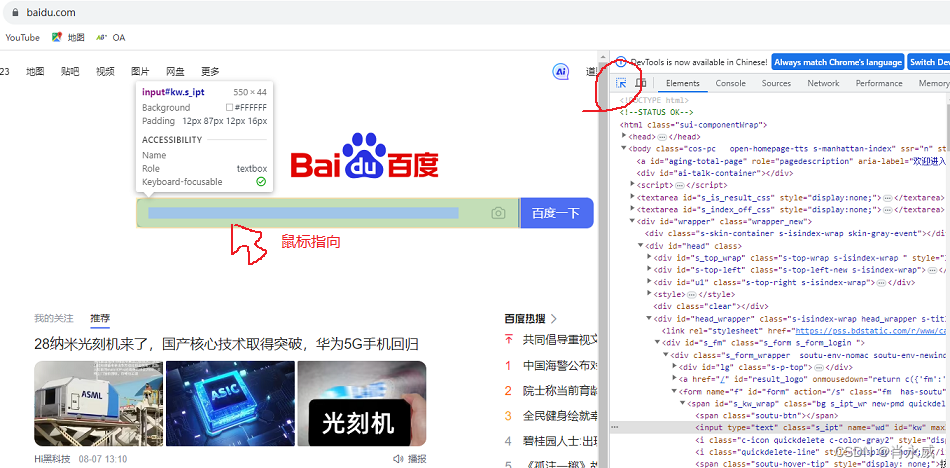
F12键直接打开Chrome开发者模式,或者找到Chrome浏览器的“更多工具”中的“开发者工具”,如下图所示(这里以百度界面为例),使用百度网页查询搜索为例,获取界面元素,进行爬取。
1.1. 定位制定元素
定位原始xpath,在Elements中点击箭头(下图红圆圈圈定位置的箭头),移动鼠标箭头到百度输入框位置定位指定的元素(如下图所示,手工绘制箭头改变了颜色,并且弹出“Input#kw…”)。
1.2. 在定位元素的指定位置
在元素区域选定位置,鼠标右键弹出菜单选择框,选择Copy显示对应的元素定位方法。 点击:Copy Xpath,复制元素路径://[@id=“kw”]。
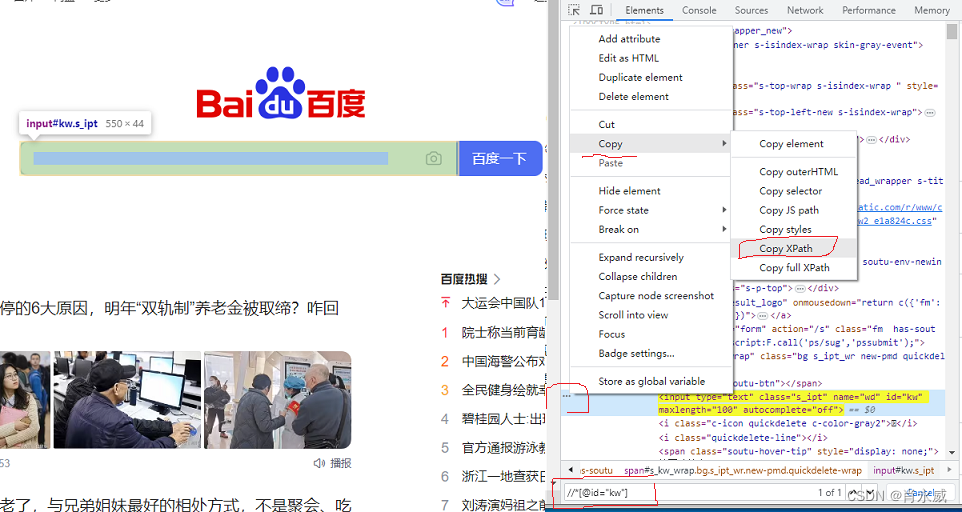
使用快捷查询功能,在Chrome浏览器中:Ctral+F调出查询功能。在下面的输入框,输入刚才的//[@id=“kw”] 路径可以高亮在界面展示对应的元素。
2. Selenium工具爬取内容
Selenium是一种用于Web应用程序测试的自动化工具。它允许用户使用各种编程语言(如Java、Python、C#等)编写测试脚本来模拟实际用户在Web浏览器中的操作,例如点击链接、填写表单等等。Selenium也可以用于爬虫、数据挖掘和Web自动化等领域,因为它可以模拟人类的操作来获取Web页面的内容和数据。Selenium的优势在于它可以与各种主要的Web浏览器和操作系统一起使用,并且可以从多个平台上运行测试脚本。此外,Selenium还具有灵活性和可扩展性,因为它可以与其他测试框架和工具集成使用,从而提高测试效率和可靠性。
Selenium是一款常用的自动化测试工具,其开源地址为:https://github.com/SeleniumHQ/selenium。
2.1. 安装Selenium
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
2.2. 安装浏览器
Selenium是一个用于自动化测试的工具,而自动化测试需要模拟用户操作。而用户操作通常是通过浏览器完成的。所以Selenium需要与浏览器进行交互,模拟用户操作。但是,Selenium本身并不包含浏览器,需要通过浏览器驱动来实现与浏览器的交互。浏览器驱动充当着Selenium与浏览器之间的桥梁,通过驱动程序与浏览器进行通信,从而实现模拟用户操作的自动化测试。
本文仅使用Chrome浏览器,其驱动如下:
ChromeDriver 下载地址:https://chromedriver.storage.googleapis.com/index.html
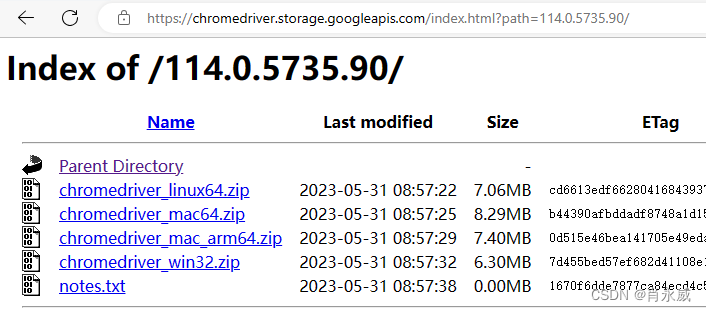
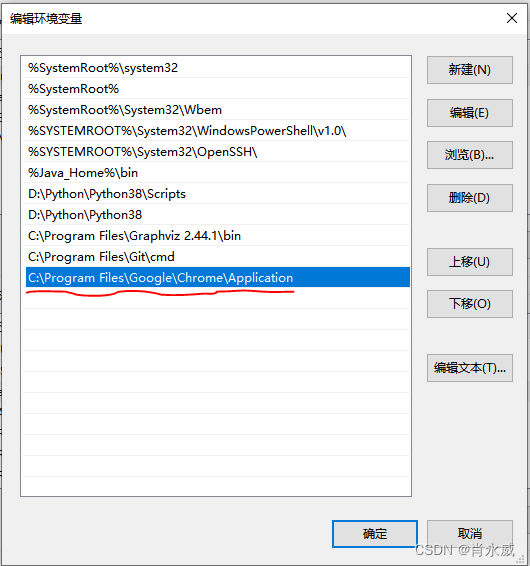
安装时,需要把“chromedriver.exe”放到chrome的目录下…\Google\Chrome\Application\ ,然后设置path环境变量,增加chrome的目录(本文为C:\Program Files\Google\Chrome\Application)。
chromedriver.exeStarting ChromeDriver 114.0.5735.90 (386bc09e8f4f2e025eddae123f36f6263096ae49-refs/branch-heads/5735@{#1052}) on port 9515
Only local connections are allowed.
Please see https://chromedriver.chromium.org/security-considerations for suggestions on keeping ChromeDriver safe.
ChromeDriver was started successfully.
windows10上的环境变量配置如下:
2.3. 示例代码
仍以爬取百度查询结果为例,模拟百度过程如下:
- 打开百度网页
- 输入查询内容,本文查询输入为“python”
- 点击打开第一行结果
示例代码:
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import timedriver = webdriver.Chrome() url = 'https://www.baidu.com/'
driver.get(url)
driver.maximize_window()# 获取百度搜索框元素
search_box = driver.find_element(By.ID ,"kw") # 按ID查询
#search_box = driver.find_element(By.NAME,'wd') # 按Name查询# 在搜索框中输入关键词
search_box.send_keys("Python")# 模拟按下回车键进行搜索
search_box.send_keys(Keys.RETURN)# 或者通过这种方法回车搜索
# ---------------------------------------
# 获取搜索按钮元素
# search_button = driver.find_element(By.ID, "su")# 点击搜索按钮
# search_button.click()
#-----------------------------------------# 等待页面加载完成
driver.implicitly_wait(10)# 获取搜索结果列表元素
search_results = driver.find_elements(By.CSS_SELECTOR, ".result")# 输出搜索结果标题和链接
for result in search_results:title = result.find_element(By.CSS_SELECTOR,"h3").textlink = result.find_element(By.CSS_SELECTOR,"a").get_attribute("href")print(title, link)# 点击第一个搜索结果链接
first_result = search_results[0].find_element(By.CSS_SELECTOR,"a")
first_result.click()# 返回上一页
driver.back()# 刷新当前页面
driver.refresh()# 最大化浏览器窗口
driver.maximize_window()# 关闭浏览器实例
driver.quit()#time.sleep(1)
注:因为
find_element_by_css_selector方法已经被弃用,最新版本的 Selenium 推荐使用find_element方法。因此,这段代码使用了更新后的方法来定位页面元素。
结果如下所示:

需要注意的是,动态生成的页面可能需要更长的时间来加载和解析。因此,您可能需要增加等待时间或使用其他技术来加快页面加载速度。
3. 小结
本文介绍了如何使用Selenium技术进行爬虫实践,以百度网页查询为例。首先,我们将学习如何在Chrome浏览器开发者模式下获取元素。接下来,我们将指导您安装Selenium和Chromedriver。最后,我们将通过一个简单的示例来演示如何模拟百度搜索"Python"的过程。
通过以上示例代码,您可以实现使用Selenium技术模拟百度搜索"Python"的功能。这只是爬虫技术的入门,您还可以学习更多高级功能,如模拟登录、处理动态加载内容等。
参考:
虫师. selenium + python自动化测试环境搭建. 博客园. 2013.05
lovingsoft.chrome浏览器f12快速定位元素的技巧. CSDN博客. 2021.01