1、实战问题
球友提问:我想停用所有纯数字的分词 , 官网上的这个方法好像对ik分词器无效!

有没有什么别的方法啊, chart gpt 说分词可以用正则匹配 但是测试好像是不行的 我的es版本是 8.5.3。
2、进一步沟通后,得到问题最精准描述
我的查询内容可能是:"北京市海淀区清华园10栋105",ik_smart 中文分词结果为:“北京市”、“海淀区”、“清华园”、“10栋”、105。

用户期望:只想把分词后,是纯数字的排除掉。也就是说:期望最终分词结果为:“北京市”、“海淀区”、“清华园”、“10栋”。
更进一步说:10栋是个分词,用户期望检索分词结果:“10栋”。但是105的意义不大,用户期望分词阶段把类似“105”的纯数字分词单元去掉。
3、解决方案探讨
有没有现成分词器可以满足用户的需求呢?目前看,没有!
那怎么办?只能自定义分词器。咱们之前讲过,自定义分词器核心就如下图三部分组成。
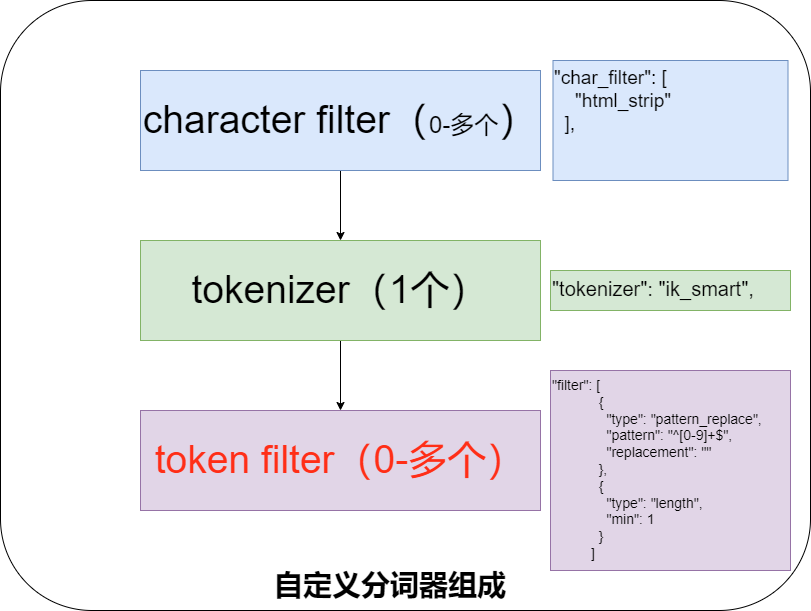
三部分含义如下,结合上面的图会更好理解。
| 部分 | 含义 |
|---|---|
| Character Filter | 在分词之前对原始文本进行处理,例如去除 HTML 标签,或替换特定字符。 |
| Tokenizer | 定义如何将文本切分为词条或 token。例如,使用空格或标点符号将文本切分为单词。 |
| Token Filter | 对 Tokenizer 输出的词条进行进一步的处理,例如转为小写、去除停用词或添加同义词。 |
Character Filter 和 Token Filter 的区别如下:
它俩在 Elasticsearch 中都是文本预处理的组件,但它们的处理时机和目标略有不同:
| 属性 | Character Filter | Token Filter |
|---|---|---|
| 处理时机 | 在 Tokenizer 之前 | 在 Tokenizer 之后 |
| 作用对象 | 原始字符序列 | 词条或 token |
| 主要功能 | 预处理文本,如去除 HTML、转换特定字符 | 对词条进行处理,如转为小写、去除停用词、应用同义词、生成词干等 |
| 输出 | 修改后的字符序列 | 处理后的词条列表 |
本质区别:Character Filter 针对原始的字符级别进行处理,而 Token Filter 针对分词后的词项级别进行处理。
到此为止,再看用户的需求,期望分词后去掉“数字”。那也就是在分词后的 Token filter 处理为上乘方案。
Token filter 怎么处理呢?考虑数字级别统一处理的正则表达式,数字的正则为:“^[0-9]+$”。
^[0-9]+$ 可以被分解为几个部分来解读:
^:这个符号表示匹配的起始位置。也就是说,匹配的内容必须从目标字符串的开头开始。
[0-9]:这是一个字符类。它匹配从 0 到 9 的任何一个数字字符。
+:这是一个量词。它表示前面的内容(在这里是 [0-9] 字符类)必须出现一次或多次。
$:这个符号表示匹配的结束位置。也就是说,匹配的内容必须直到目标字符串的结尾。
所以,整体上,这个正则表达式的含义是:字符串的开头到结尾之间只包含一到多个数字字符,并且没有其他任何字符。
例如:
"123" 符合该正则。
"0123" 也符合。
"abc"、"123a" 或 "a123" 都不符合。
一句话,该正则表达式基本达到用户的需求。
实际实现的时候我们发现,对应 filter 环节的:"pattern_replace-tokenfilter"过滤器。该过滤会实现字符级别的替换,我们可以将正则匹配的数字替换为某个字符,比如“”空格字符。
但,还没有达到要求,空格字符用户期望是剔除。这时候,我们又得考虑“”空格如何剔除。
查阅 filter 官方文档知道,有个“analysis-length-tokenfilter”的过滤器,将最小长度设置为1,就能过滤掉长度为0的空格字符。
自此,方案初步敲定。
4、敲定和初步验证解决方案
经过上述的讨论。我们分三步走战略。
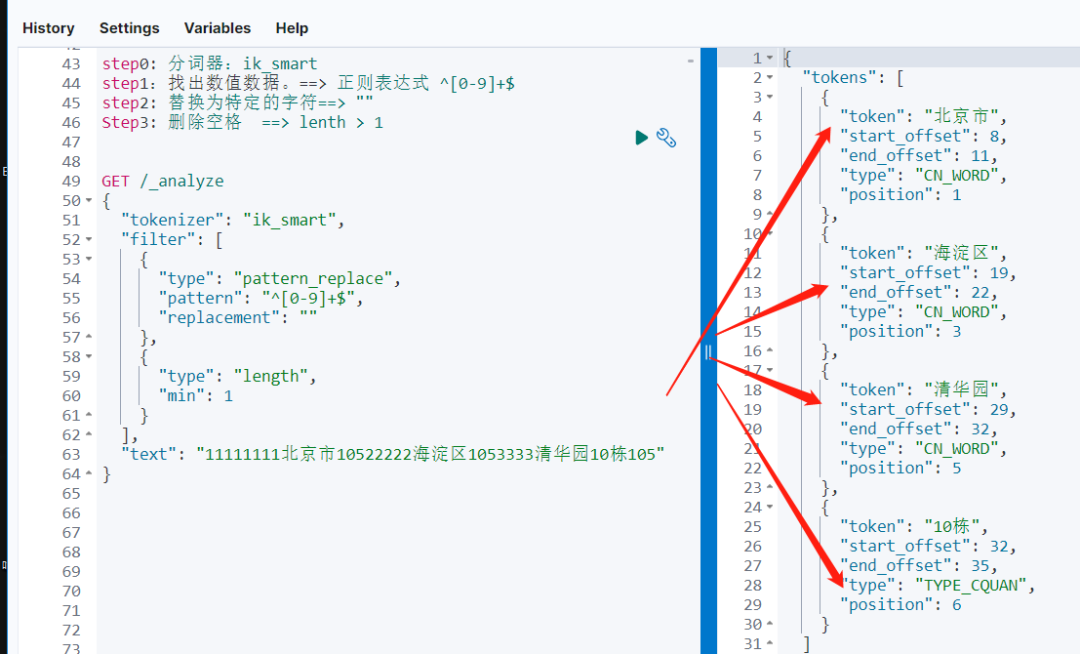
step 0: 分词器依然选择 ik_smart,和用户需求高度一致。
step 1:找出数值数据,使用正则过滤 "pattern_replace filter” 实现。==> 正则表达式 ^[0-9]+$ 替换为特定的字符==> ""。
Step 2: 删除空格,借助 length filter 实现。==> lenth > 1 小范围验证一下:
GET /_analyze
{"tokenizer": "ik_smart","filter": [{"type": "pattern_replace","pattern": "^[0-9]+$","replacement": ""},{"type": "length","min": 1}],"text": "11111111北京市10522222海淀区1053333清华园10栋105"
}在将输入文本复杂化处理后,分词结果依然能达到预期。
5、实操实现自定义分词
有了前面的初步实现,自定义分词就变得容易。
DELETE my-index-20230811-000002
PUT my-index-20230811-000002
{"settings": {"analysis": {"analyzer": {"my_custom_analyzer": {"tokenizer": "ik_smart","filter": ["regex_process","remove_length_lower_1"]}},"filter": {"regex_process": {"type": "pattern_replace","pattern": "^[0-9]+$","replacement": ""},"remove_length_lower_1": {"type": "length","min": 1}}}},"mappings": {"properties": {"address":{"type":"text","analyzer": "my_custom_analyzer"}}}
}POST my-index-20230811-000002/_analyze
{"text": ["1111北京市3333海淀区444444清华园10栋105"],"analyzer": "my_custom_analyzer"
}索引定义解读如下:
| 部分 | 子部分 | 名称 | 描述 |
|---|---|---|---|
| Settings | Analyzer | my_custom_analyzer | 使用的分词器: ik_smart- 使用的过滤器: regex_process, remove_length_lower_1 |
| Settings | Filter | regex_process | 类型: pattern_replace匹配全数字的模式,并替换为空字符串 |
| Settings | Filter | remove_length_lower_1 | 类型: length确保仅保留长度大于或等于1的词条 |
| Mappings | Properties | address | 类型: text使用的分析器: my_custom_analyzer |
上 述配置的主要目的是:创建一个自定义的analyzer,该analyzer可以处理中文文本,将纯数字的token替换为空,并确保分析结果中不包含空token。
最终结果如下,达到预期效果。

6、小结
当传统默认分词不能达到我们特定的、复杂的需求的时候,记得还有一招:自定义分词。
自定义分词记住三部分组成后,拆解一下复杂问题的需求,问题就会迎刃而解。
视频解读如下:
欢迎大家关注下我的视频号,不定期分享 Elasticsearch 实战进阶干货!
7、参考
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-overview.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-length-tokenfilter.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-pattern_replace-tokenfilter.html
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
2023,做点事
Elasticsearch自定义分词,从一个问题说开去
Elasticsearch 自定义分词同义词环节的这个细节不大好理解......

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

大模型时代,抢先一步学习进阶干货!