Transformer 模型
- 输入编码
- 多头自注意力机制
- 前馈网络层
- 编码器
- 解码器
当前主流的大语言模型都基于 Transformer 模型进行设计的。Transformer 是由多层的多头自注意力模块堆叠而成的神经网络模型。原始的 Transformer 模型由编码器和解码器两个部分构成,而这两个部分实际上可以独立使用,例如基于编码器架构的 BERT 模型和解码器架构的 GPT 模型。与 BERT 等早期的预训练语言模型相比,大语言模型的特点是使用了更长的向量维度、更深的层数,进而包含了更大规模的模型参数,并主要使用解码器架构,对于 Transformer 本身的结构与配置改变并不大。本部分内容将首先介绍 Transformer模型的基本组成,包括基础的输入、多头自注意力模块和前置网络层;接着分别介绍 Transformer 模型中的编码器和解码器模块。
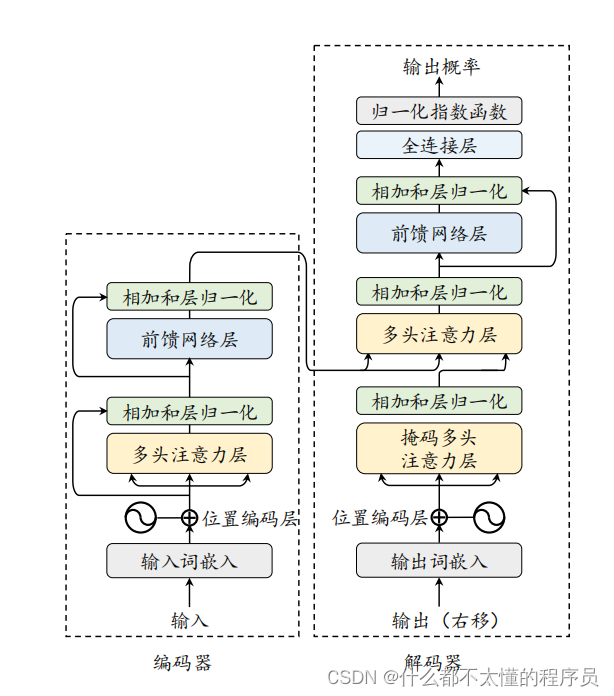
输入编码
在 Transformer 模型中,输入的词元序列 (𝒖 = [𝑢1, 𝑢2, . . . , 𝑢𝑇]) 首先经过一个输入嵌入模块(Input Embeddi