一,刷新率和帧率,60hz和60fps的区别
在Android系统中,刷新率和帧率是两个不同的概念,它们各自在显示过程中扮演着不同的角色。以下是对它们的详细解释:
刷新率,单位是Hz,是指屏幕在一秒内刷新的次数,也就是一秒内显示了多少帧图像。这是显示器(如LCD或OLED)的硬件性能参数。例如,60Hz的刷新率意味着屏幕每秒可以刷新60次。刷新率的高低直接决定了屏幕画面的流畅度,高刷新率通常能带来更为流畅的视觉体验。
帧率,单位是fps(frames per second),指GPU(图形处理器)在一秒内绘制操作的帧数。在Android系统中,60fps意味着每秒钟GPU最多绘制60帧画面。帧率是动态变化的,取决于GPU的渲染速度和应用的需求。例如,当画面静止时,GPU可能没有绘制操作,屏幕刷新的还是缓存中的帧数据。
因此,60Hz和60fps虽然数值上相同,但它们代表的含义完全不同。60Hz是指屏幕每秒钟的刷新次数,而60fps则是GPU每秒钟的绘制帧数。在实际应用中,如果帧率超过屏幕刷新率,那么超过的部分实际上是无法被显示器捕捉并显示出来的,因为显示器不能以这么快的速度更新。这种情况下,超过刷新率的帧率就浪费了图像处理能力。
总的来说,刷新率和帧率是Android系统中影响显示效果的两大关键因素,它们相互关联但又各自独立。为了获得最佳的显示效果,通常需要确保应用的帧率和屏幕的刷新率相匹配。
帧率FPS是Frame Per Second的缩写,意思是每秒产生画面的个数。这是一个软件的概念,与屏幕刷新率这个硬件概念要区分开。FPS是由软件系统决定的。如果帧率为60fps,那么意味着每1/60秒,即大约16.67毫秒,屏幕就需要更新一次。需要注意的是,显示器并不是一次性将整个画面显示到屏幕上,而是采用逐行扫描的方式,从左到右、从上到下顺序显示整屏的像素点。然而,这一过程发生得非常快,快到人眼几乎无法察觉到变化。
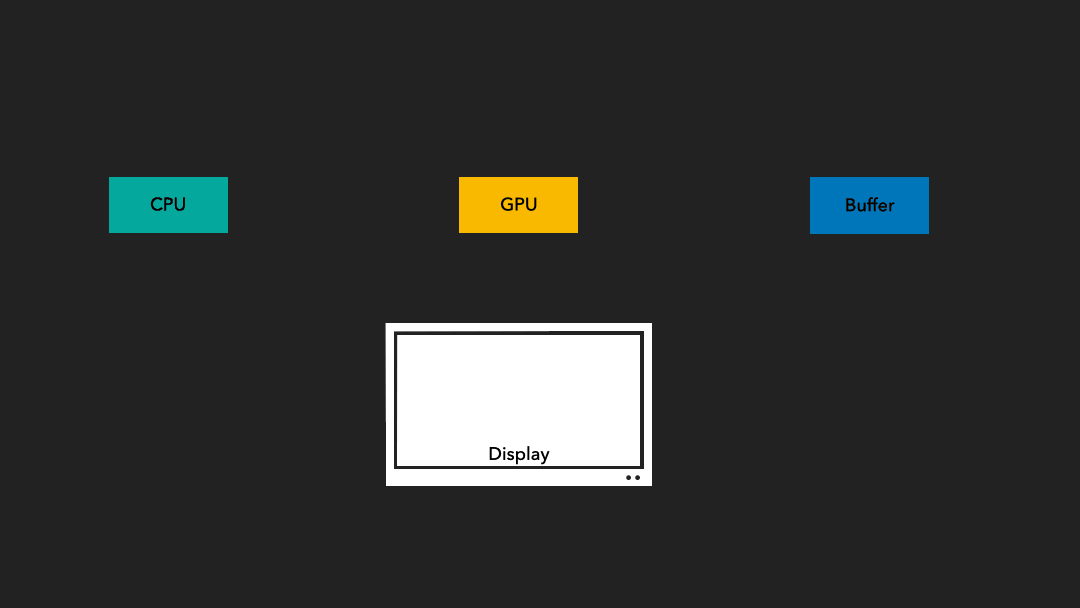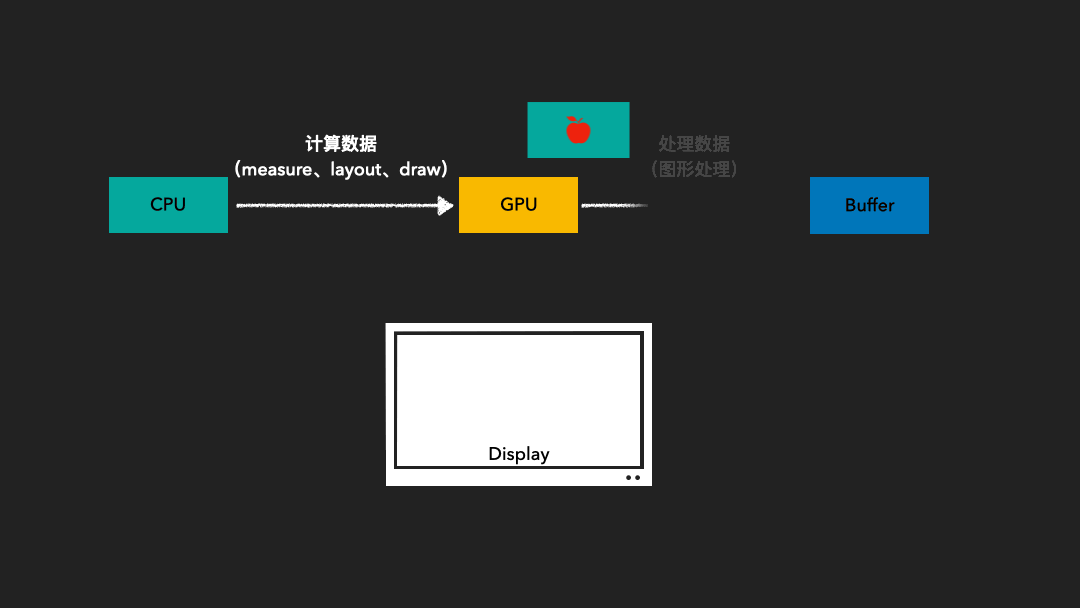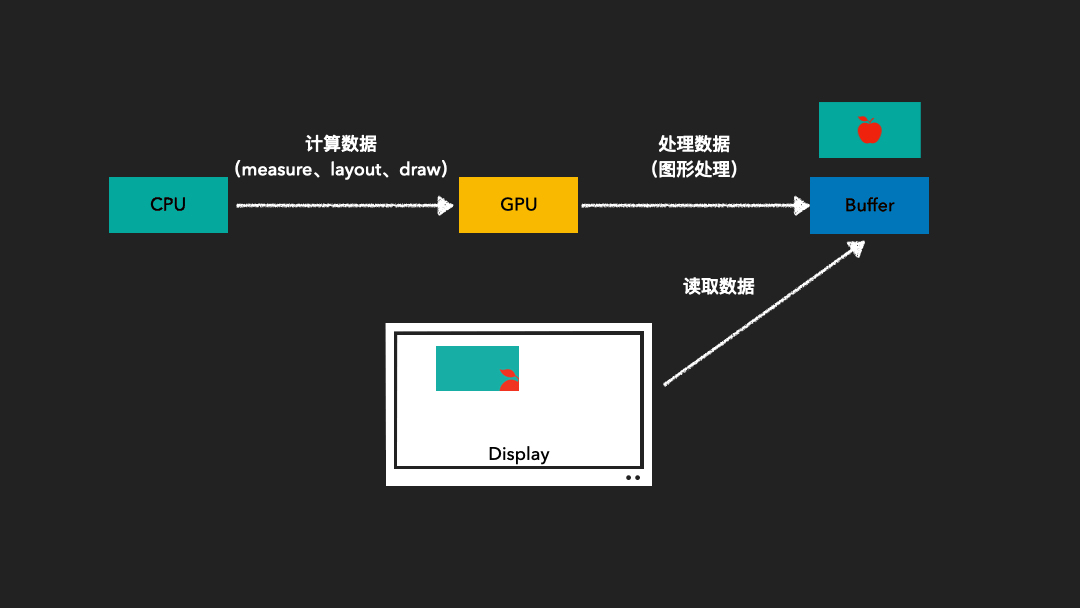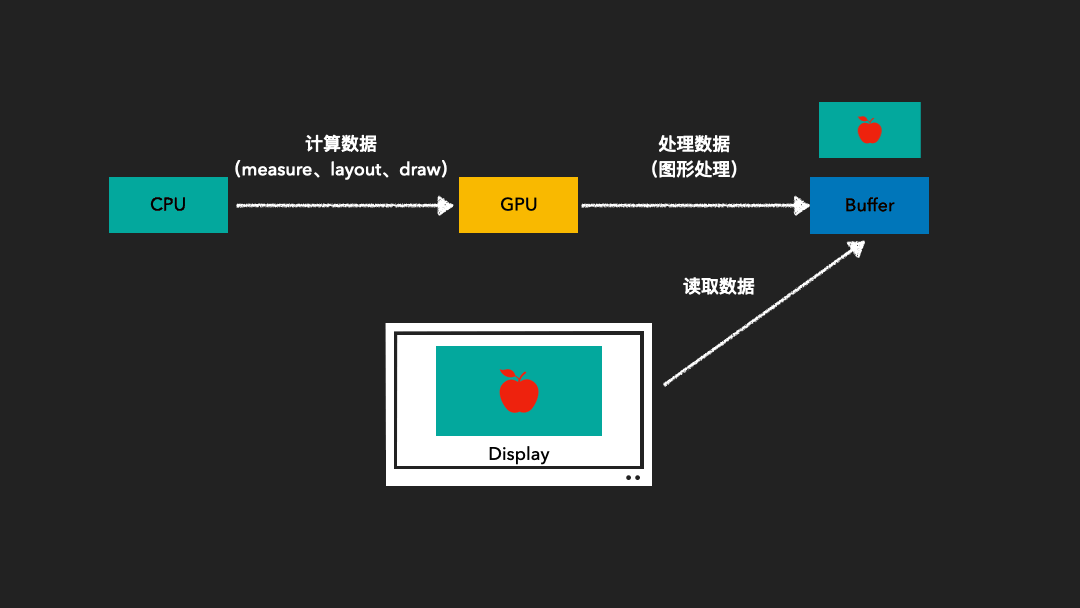
当帧率和刷新率不一致时,可能会发生以下两种情况:
屏幕刷新速率 > 系统帧速率时。在这种情况下,当前帧的前缓冲区内容完全映射到屏幕上后,后缓冲区可能尚未准备好下一帧。因此,屏幕无法读取到下一帧的内容,只能继续显示当前帧的图形。这会导致一帧被显示多次,从而产生卡顿现象。
系统帧速率 > 屏幕刷新率时。这时,屏幕尚未完全将缓冲区中的一帧映射到屏幕上,而系统已经准备好了下一帧,并将其写入到缓冲区中。当系统要求读取下一帧到屏幕时,会导致屏幕上半部分仍然显示上一帧的图形,而下半部分则显示下一帧的图形。这种情况会造成屏幕上同时显示多帧,产生屏幕撕裂现象。
二,双缓冲Buffer
前面我们说到画面撕裂是由于单buffer引起的,使用了双缓冲来解决画面撕裂。
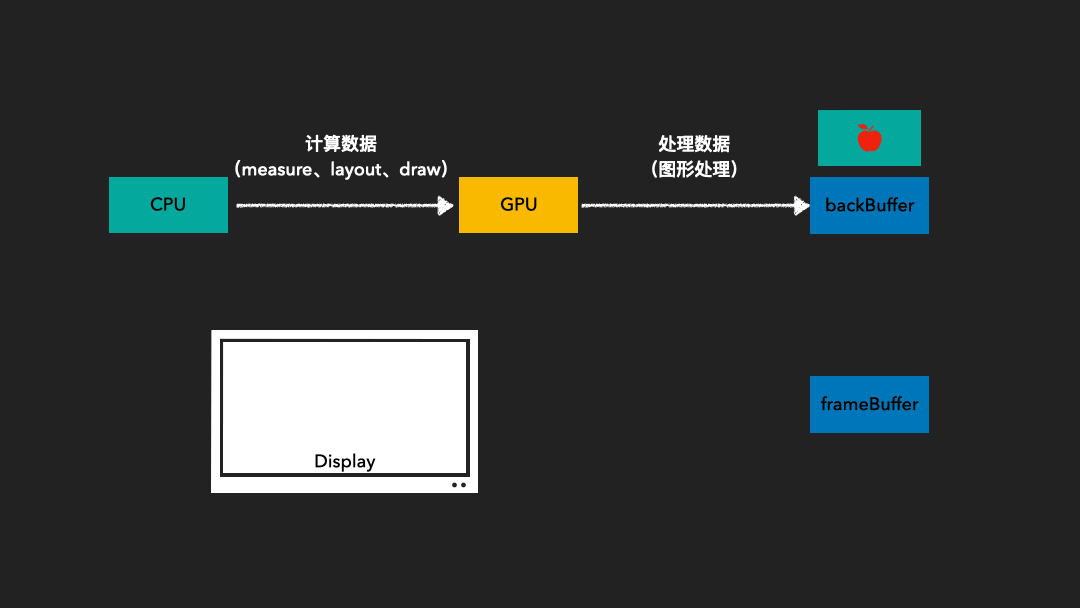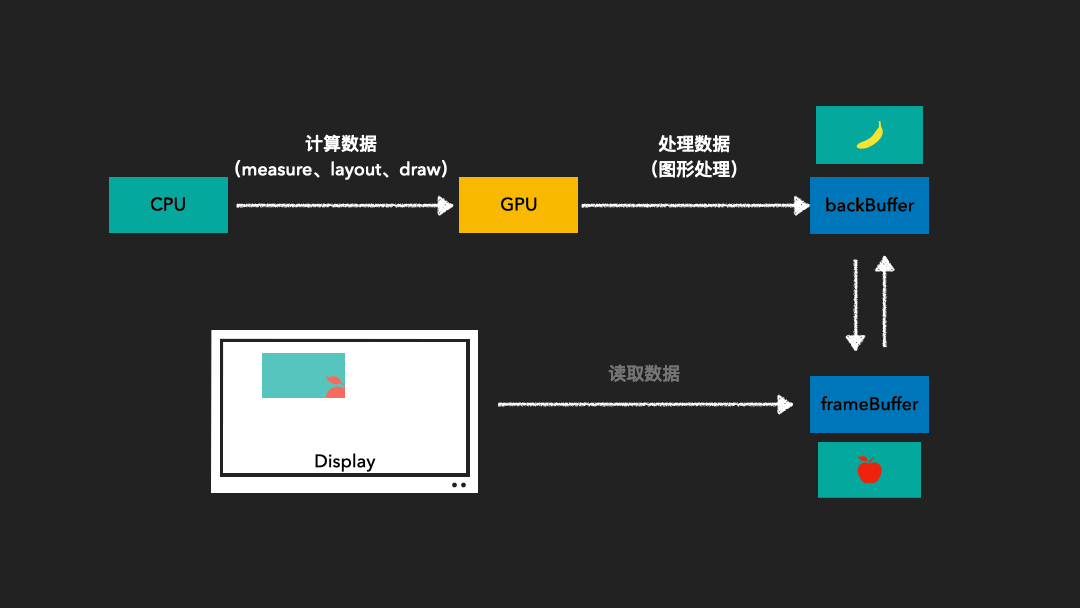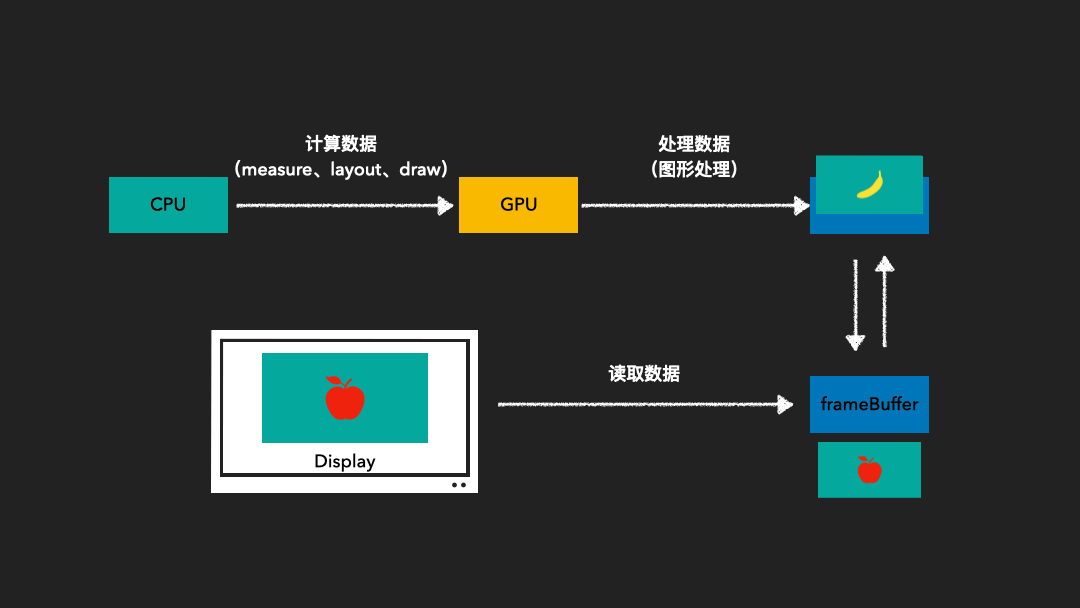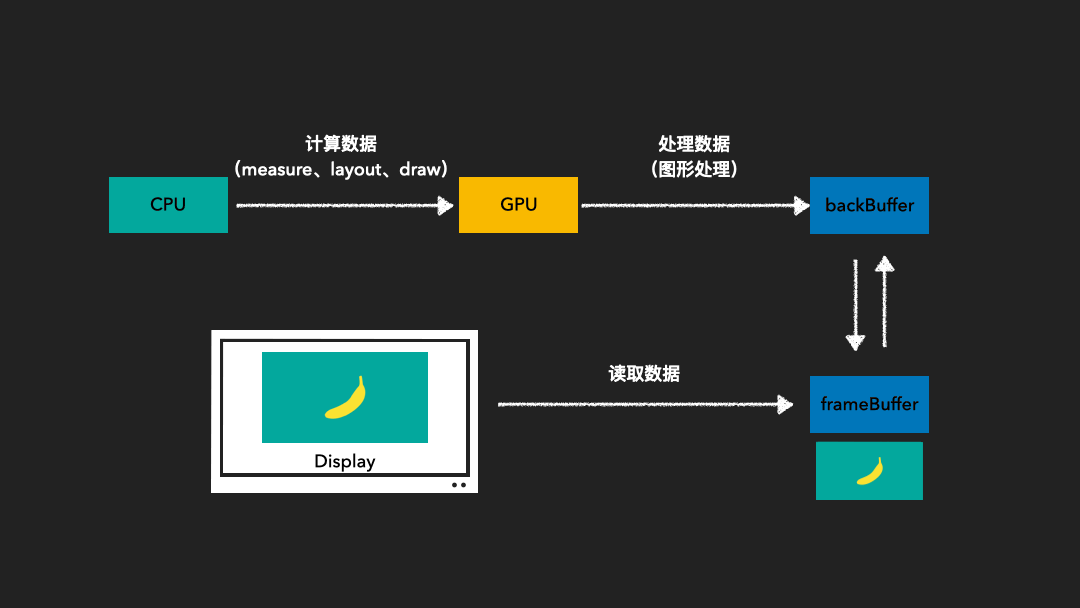
GPU写入的缓存为:Back Buffer
屏幕刷新使用的缓存为:Frame Buffer
如下图:
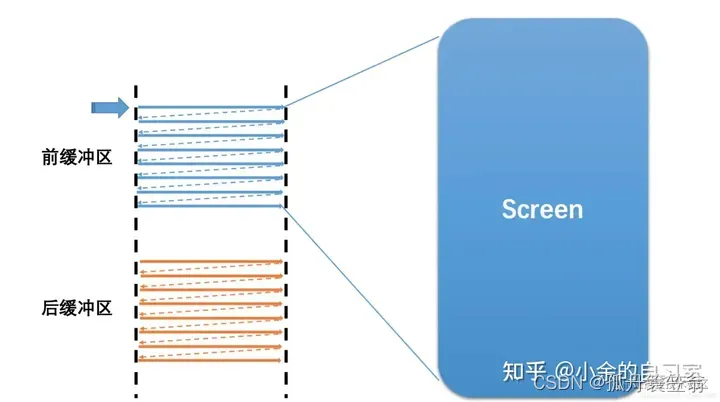 因为使用双buffer,屏幕刷新时,frame buffer不会发生变化,通过交换buffer来实现帧数据切换,那什么时候交换buffer呢?
因为使用双buffer,屏幕刷新时,frame buffer不会发生变化,通过交换buffer来实现帧数据切换,那什么时候交换buffer呢?
这就要引入Vsync的概念了。
三,VSync(垂直同步)+ Double Buffer
为解决撕裂问题,Android引入了VSync(垂直同步)+ Double Buffer技术。
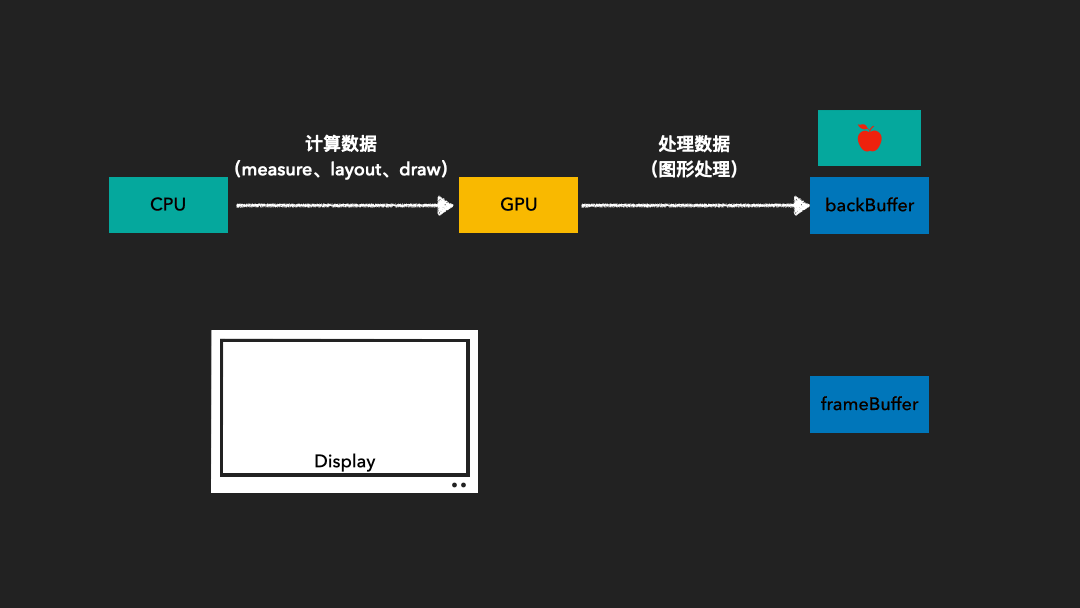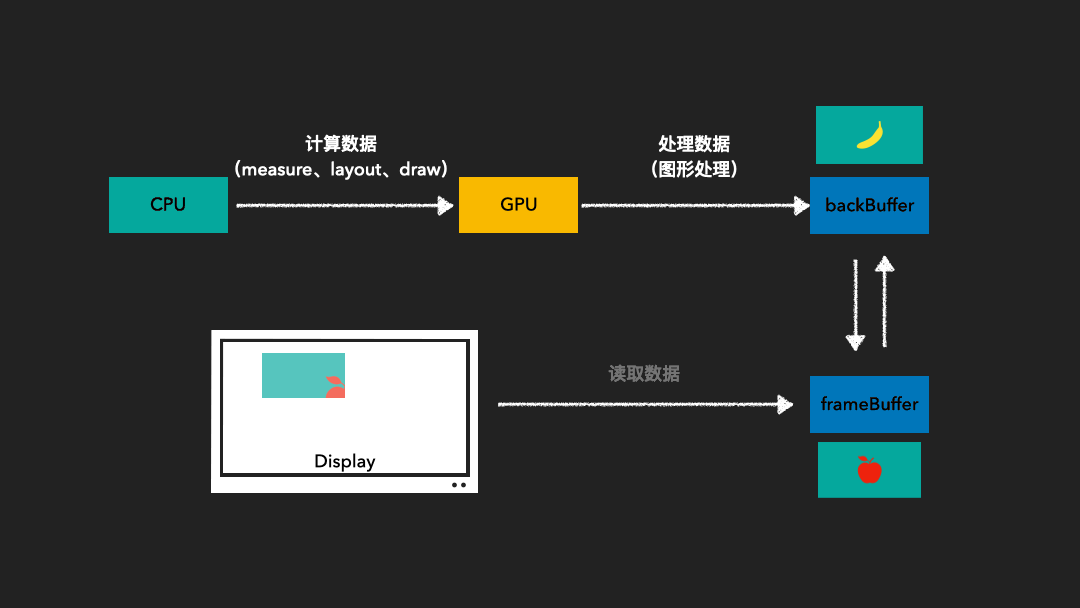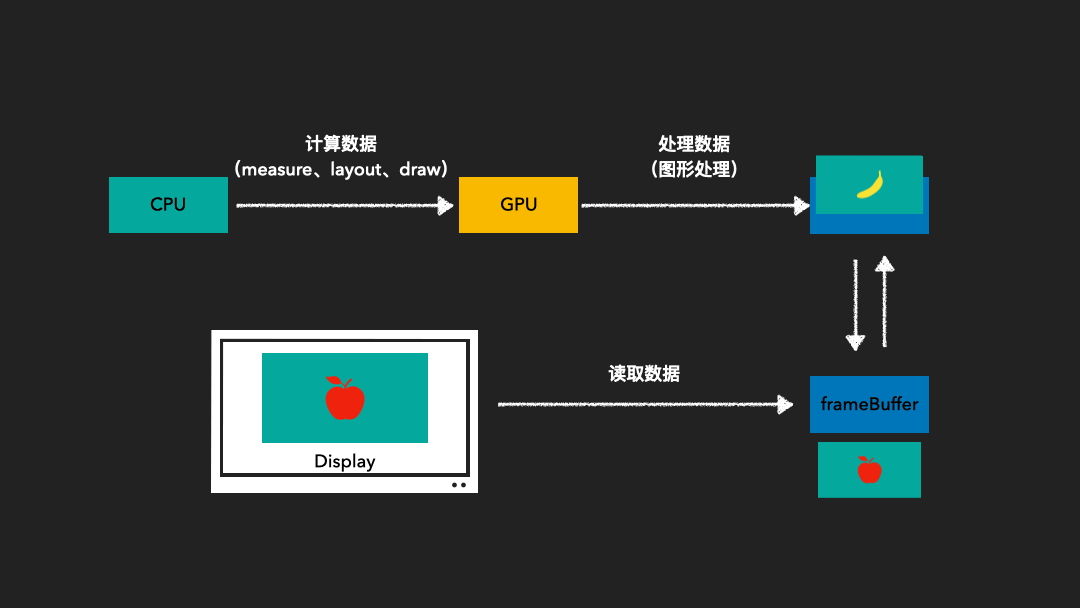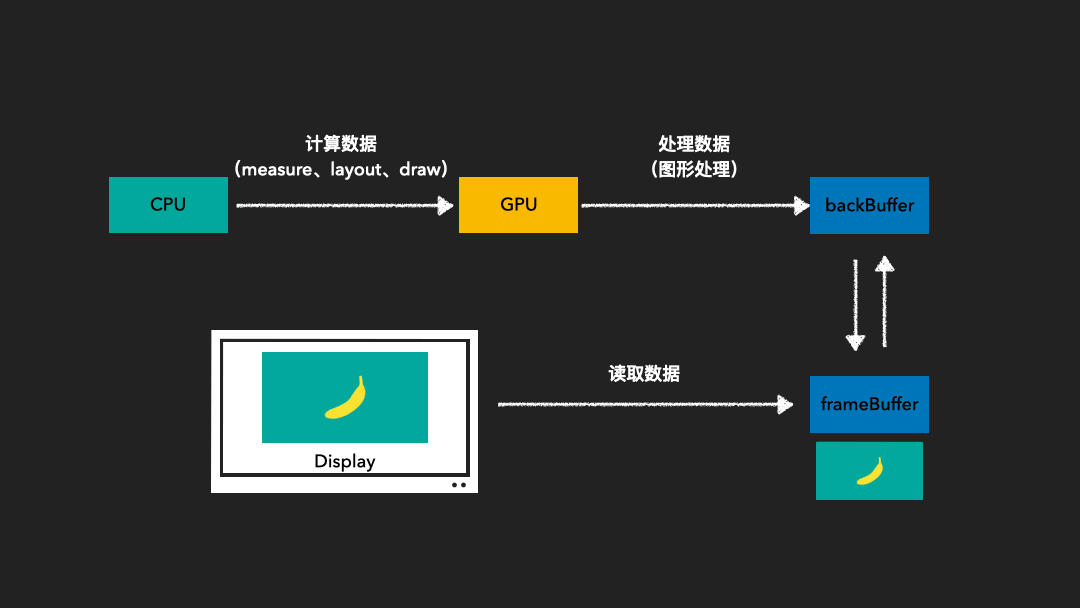
由于图像绘制和屏幕读取使用的是同一个缓存区,因此在屏幕刷新过程中可能会读取到不完整的一帧画面。为了解决这一问题,我们采用了双缓存技术。这种技术使得图像绘制和屏幕显示各自拥有独立的缓存区。CPU或GPU总是将绘制完成的一帧图像写入到Back Buffer中,而显示器则读取使用Frame Buffer。这样,当屏幕进行刷新时,Frame Buffer的内容并不会发生变化。只有当Back Buffer准备就绪时,我们才会进行两个缓存区的交换。
那么,何时进行这两个缓存区的交换呢?这就涉及到了Vsync的概念。
Vsync是垂直同步(Vertical Synchronization)的简称。它负责调度从Back Buffer到Frame Buffer的复制操作。我们可以认为这一复制操作在瞬间完成,因为实际上双缓冲的实现方式是交换Back Buffer和Frame Buffer的内存地址。
通过这一机制,我们可以确保屏幕上显示的每一帧图像都是完整的,从而避免了因图像读取不完整而产生的各种问题。
具体流程如下图描述:
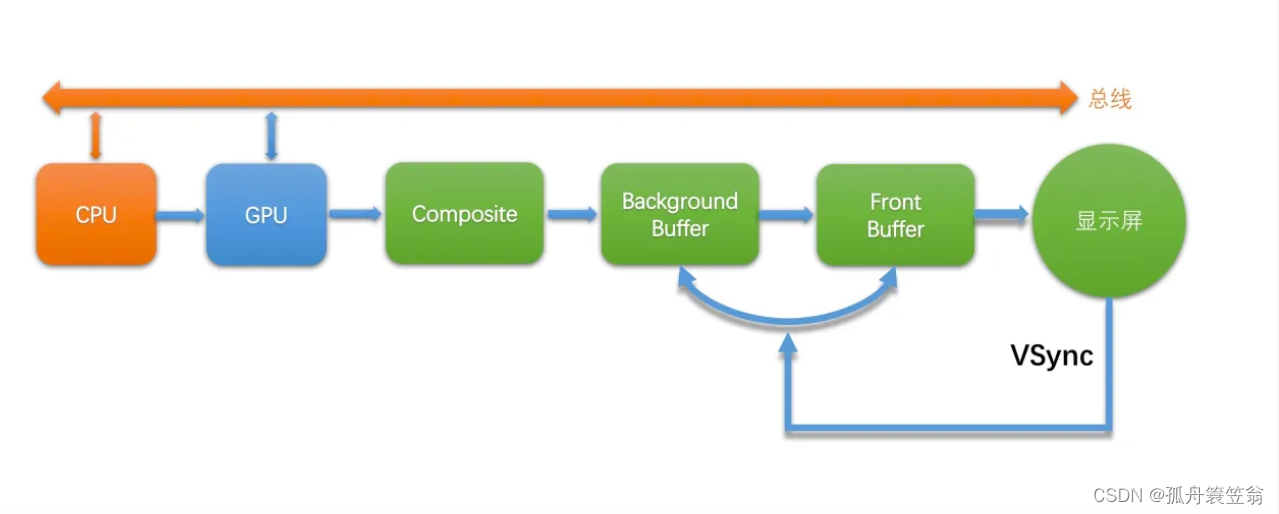
其中:
·CPU和GPU代表上层的绘制执行者,各做一部分工作,本文章中对CPU和GPU的工作不进行介绍。
·Composite代表的是Android系统服务对多个Surface的合成。
·BackgroundBuffer和FrontBuffer(FrameBuffer)分别代表的是硬件帧缓冲区中的前缓冲和后缓冲。
·显示屏扫描完一帧之后,会发出VSync信号来切换并显示下一帧。
上面的流程中,存在一个问题,屏幕的VSync信号只是用来控制帧缓冲区的切换,并未控制上层的绘制节奏,也就是说上层CPU/GPU的生产节奏和屏幕的显示节奏是脱离的。
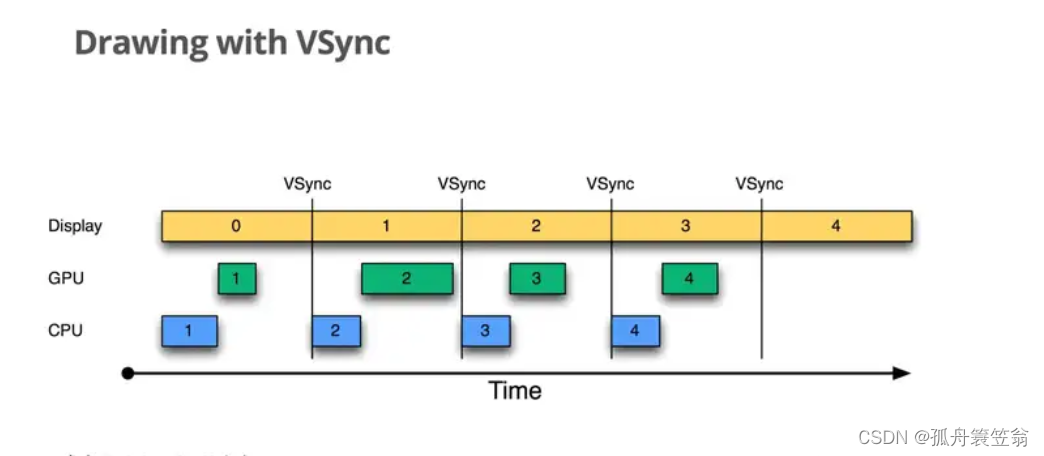
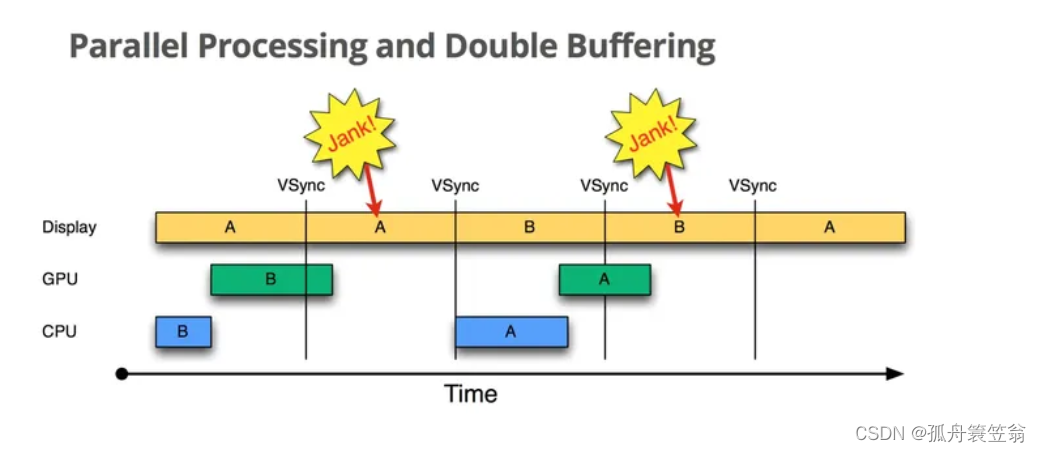
2.1:在引入VSync前(Drawing without VSync)
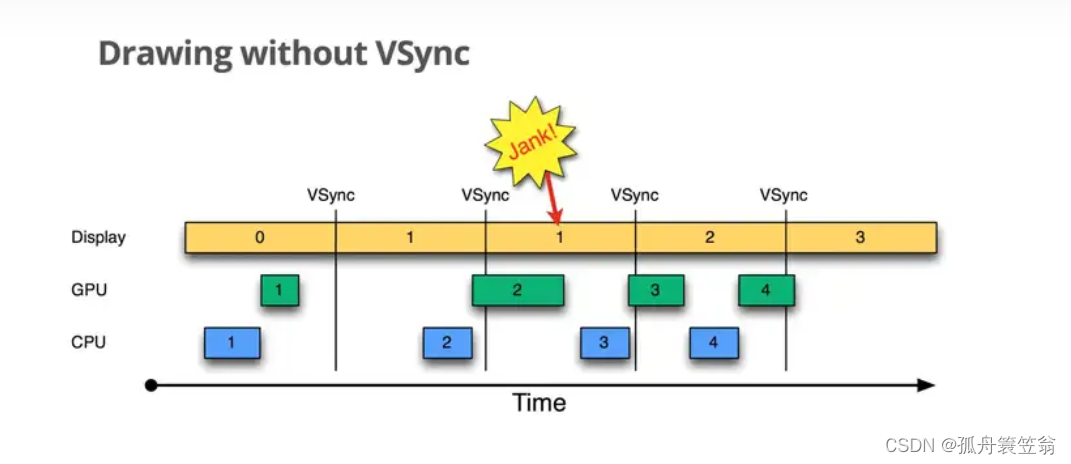
按时间顺序:
1.Display显示第0帧画面,而CPU和GPU正在合成第1帧,且在Display显示下一帧之前完成了。
2.由于GPU在Display第一个VSync来之前完成了back buffer的填充,此时交换back buffer和frame buffer,屏幕进行刷新,可以正常显示第一帧数据。 - 3.再来看第2个VSync,第二个VSync到来之时,GPU并没有及时的填充back buffer,这个时候不能交互buffer,屏幕刷新的还是第1帧的画面。就说这里发生了“jank”
4.在第3个VSync信号到来时,第2帧的数据已经写入back buffer,第3帧的数据GPU还没写入,所以这个时候交互buffer显示的是第2帧的数据
5.同理,在第4个VSync时,第3帧数据已经处理完毕,交换buffer后显示的是第2帧的数据
这里发生jank的原因是:在第2帧CPU处理数据的时候太晚了,GPU没有及时将数据写入到buffer中,导致jank的发生。
如果可以把CPU绘制流程提前到每个VSync信号来的时候进行CPU的绘制,那是不是就可以让CPU的计算以及GPU的合成写入buffer的操作有完整的16.6ms。
2.1:在引入VSync后(Drawing with VSync)
为了进一步优化性能,谷歌在4.1之后对屏幕绘制与刷新过程引入了Project Butter(黄油工程),系统在收到VSync信号之后,马上进行CPU的绘制以及GPU的buffer写入。 这样就可以让cpu和gpu有个完整的16.6ms处理过程。最大限度的减少jank的发生。
VSync是垂直同步的缩写,它是一种技术,允许CPU在显卡完成一帧渲染后立即发送更新请求,确保刷新率与显示器的刷新率相匹配。从屏幕显示第0帧开始,CPU开始准备第1帧图形的处理,然后将处理好的内容交给GPU。当上层收到下一个VSync信号后,CPU会立即开始第2帧的处理,这样上层绘图的节奏就和VSync信号保持一致,使得整个绘图过程非常流畅。
VSync的主要作用体现在以下几个方面:当屏幕扫描完第1帧画面之后,系统会发送VSync信号。此时,会发生三件事:
首先,交换两个缓存区(framebuffer和backbuffer)的内容;
接着,显示器开始显示第2帧内容,即交换后的framebuffer内容;
最后,CPU/GPU开始计算处理第三帧的内容,并在处理好后将其放入backbuffer中。这样的过程保证了屏幕显示的连贯性和流畅性,提高了用户体验。
三,三buffer时代
引入VSync后,新的问题又出现了:如下图:
由于主线程做了一些相对复杂耗时逻辑,导致CPU和GPU的处理时间超过16.6ms,由于此时back buffer写入的是B帧数据,在交换buffer前不能被覆盖,而frame buffer被Display用来做刷新用,所以在B帧写入back buffer完成到下一个VSync信号到来之前两个buffer都被占用了,CPU无法继续绘制,这段时间就会被空着, 于是又出现了三缓存。
为了进一步优化用户体验,Google在双buffer的基础上又增加了第三个buffer(Graphic Buffer), 如图:
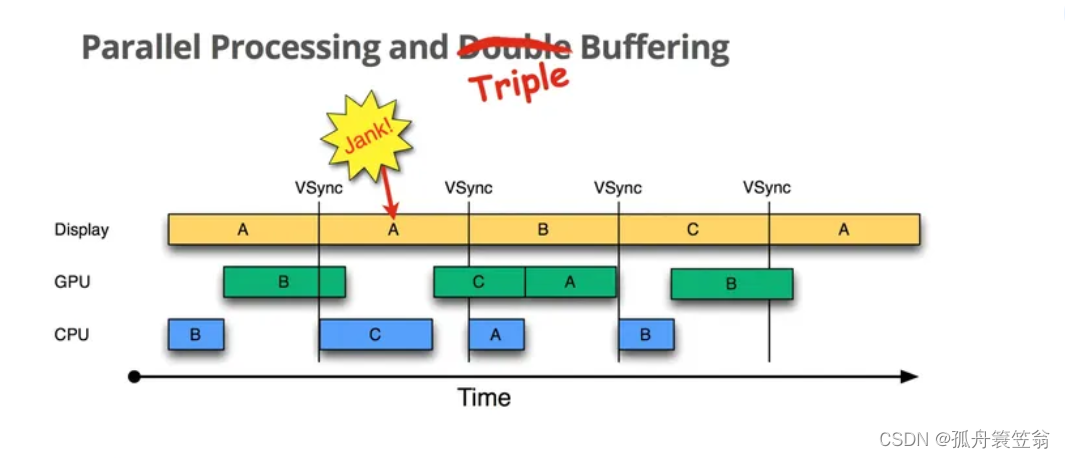
按时间顺序: - 1.第一个jank是无法避免的,因为第一个B帧处理超时,A帧肯定是会重复的。 - 2.在第一个VSync信号来时,虽然back buffer以及frame buffer都被占用了,CPU此时会启用第三个Graphic Buffer,避免了CPU的空闲状态。
这里可以最大限度避免2中CPU空闲的情况,记住只是最大限度,没有说一定能避免。
那又有人要说了,那就再多开几个不就可以了,是的,buffer越多jank越少,但是你得考虑性价比: 3 buffer已经可以最大限度的避免jank的发生了,再多的buffer起到的作用就微乎其微,反而因为buffer的数量太多,浪费更多内存,得不偿失。