今天我们来看一下神经网络中的反向传播算法,之前介绍了梯度下降与正向传播~ 神经网络的反向传播
专栏:💎实战PyTorch💎
反向传播算法(Back Propagation,简称BP)是一种用于训练神经网络的算法。
反向传播算法是神经网络中非常重要的一个概念,它由Rumelhart、Hinton和Williams于1986年提出。这种算法基于梯度下降法来优化误差函数,利用了神经网络的层次结构来有效地计算梯度,从而更新网络中的权重和偏置。
基本工作流程:
- 通过正向传播得到误差,所谓正向传播指的是数据从输入到输出层,经过层层计算得到预测值,并利用损失函数得到预测值和真实值之前的误差。
- 通过反向传播把误差传递给模型的参数,从而对网络参数进行适当的调整,缩小预测值和真实值之间的误差。
- 反向传播算法是利用链式法则进行梯度求解,然后进行参数更新。对于复杂的复合函数,我们将其拆分为一系列的加减乘除或指数,对数,三角函数等初等函数,通过链式法则完成复合函数的求导。
我们通过一个例子来简单理解下 BP 算法进行网络参数更新的过程🧧:

如图我们在最下边输入两个维度的值进入神经网络:0.05、0.1 ,经过两个隐藏层(每层两个神经元),每个神经元有两个值,左边为输入值,右边是经过激活函数后的输出值;经过这个神经网络后的输出值为:m1、m2,实际值为0.01、0.99 🌠
设置的初始权重w1,w2,...w8分别为0.15、0.20、0.25、0.30、0.30、0.35、0.55、0.60
我们通过计算得到损失函数Error = 1/2 ((m1- target1)2 + (m2 - target2)2) = 0.2988
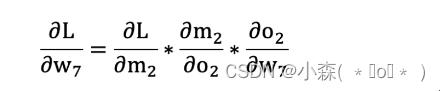
w5和w7均可以通过求三次导来求梯度,而w1,w3则不能直接通过L降序求导,我们需要求从L到m1,m1到o1,o1到k1,k1到h1,h1到w1:
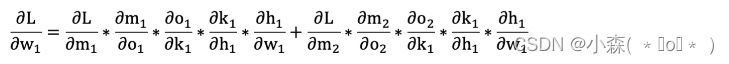
由于w1是输出两个方向分别到o1和o2,所以是两个方向的梯度求和~
我们也发现所以激活函数都是要可微的~
其他的网络参数更新过程和上面的求导过程是一样的,这里就不过多赘述,我们直接看一下代码。
反向传播代码
我们先来回顾一些Python中类的一些小细节:
🌈在Python中,使用
super()函数可以调用父类的方法。这在子类中重写父类方法时非常有用,因为它允许你调用父类的实现,而不是完全覆盖它
class Parent:def __init__(self):print("Parent init")class Child(Parent):def __init__(self):super().__init__()print("Child init")c = Child()# 输出
Parent init
Child init🌈当我们创建一个
Child类的实例时,它会首先调用Parent类的__init__方法(通过super().__init__()),然后执行Child类的__init__方法,与类的__init__方法(构造方法)对应的类关闭时自动调用的方法是__del__方法。对象不再被使用时,Python解释器会自动调用这个方法。通常在这个方法中进行一些清理工作,比如释放资源、关闭文件等。
反向传播实现
import torch
import torch.nn as nn
import torch.optim as optimclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.linear1 = nn.Linear(2, 2)self.linear2 = nn.Linear(2, 2)# 网络参数初始化w1/w2/w3/w4self.linear1.weight.data = torch.tensor([[0.15, 0.20], [0.25, 0.30]])# w5/w6/w7/w8self.linear2.weight.data = torch.tensor([[0.40, 0.45], [0.50, 0.55]])# 截距bself.linear1.bias.data = torch.tensor([0.35, 0.35])self.linear2.bias.data = torch.tensor([0.60, 0.60])# 定义前向传播的行径def forward(self, x):x = self.linear1(x)x = torch.sigmoid(x)x = self.linear2(x)x = torch.sigmoid(x)return xif __name__ == '__main__':inputs = torch.tensor([[0.05, 0.10]])target = torch.tensor([[0.01, 0.99]])# 获得网络输出值net = Net()output = net(inputs)# print(output) # tensor([[0.7514, 0.7729]], grad_fn=<SigmoidBackward>)# 计算误差loss = torch.sum((output - target) ** 2) / 2# print(loss) # tensor(0.2984, grad_fn=<DivBackward0>)# 优化方法optimizer = optim.SGD(net.parameters(), lr=0.5)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 打印 w5、w7、w1 的梯度值print(net.linear1.weight.grad.data)# tensor([[0.0004, 0.0009],# [0.0005, 0.0010]])print(net.linear2.weight.grad.data)# tensor([[ 0.0822, 0.0827],# [-0.0226, -0.0227]])# 打印网络参数optimizer.step()print(net.state_dict())# OrderedDict([('linear1.weight', tensor([[0.1498, 0.1996], [0.2498, 0.2995]])),# ('linear1.bias', tensor([0.3456, 0.3450])),# ('linear2.weight', tensor([[0.3589, 0.4087], [0.5113, 0.5614]])),# ('linear2.bias', tensor([0.5308, 0.6190]))])- optimizer.step() 相当于是将w和b所有参数更新一步的过程
🌈关于nn.Linear的使用
import torch
import torch.nn.functional as F
import torch.nn as nn# 均匀分布随机初始化linear = nn.Linear(5, 3)
# 从0-1均匀分布产生参数
nn.init.uniform_(linear.weight)
print(linear.weight.data)
nn.Linear是PyTorch中用于创建线性层的类,也被称为全连接层。它的主要作用是将输入数据与权重矩阵相乘并加上偏置,然后通常会通过一个非线性激活函数进行转换。
- 在函数内部,创建一个线性层,输入维度为5,输出维度为3;
- 使用nn.init.uniform_()函数对线性层的权重进行均匀分布随机初始化;
- 打印线性层的权重数据。