论文名称:《CBAM: Convolutional Block Attention Module》
论文地址:https://arxiv.org/pdf/1807.06521.pdf
我们提出了卷积块注意力模块(CBAM),这是一种简单但有效的前馈卷积神经网络注意力模块。给定一个中间特征图,我们的模块会按顺序沿两个独立的维度进行注意力推理,分别是通道和空间,然后将注意力图与输入特征图相乘,以实现自适应特征优化。由于 CBAM 是一个轻量级且通用的模块,它可以无缝地集成到任何 CNN 架构中,增加的负担微不足道,并且可以与基础 CNN 一起进行端到端的训练。
我们通过在 ImageNet-1K、MS COCO 检测和 VOC 2007 检测数据集上的广泛实验验证了 CBAM。我们的实验显示,各种模型在分类和检测性能上都取得了稳定的改进,证明了 CBAM 的广泛适用性。代码和模型将公开提供。
问题背景
在计算机视觉领域,尤其是图像识别任务中,卷积神经网络(CNN)已经取得了显著的成功。然而,随着研究的深入,学者们开始关注如何通过增强网络的深度、宽度和模型复杂度来进一步提升性能。这篇文章介绍了一个全新的视角——注意力机制(Attention Mechanism),它能够更智能地从输入的特征图中提取有用信息,通过突出重要的特征并抑制不必要的信息来增强模型的表现力。
核心概念
文章的核心概念是引入了一个名为“卷积块注意力模块”(Convolutional Block Attention Module, CBAM),这是一种轻量级但非常有效的注意力机制,设计用来顺序推断通道和空间维度的注意力图,这些注意力图随后被用来乘以输入特征图,以进行自适应特征提炼。CBAM 的设计易于集成到任何 CNN 架构中,几乎不增加额外计算负担。
模块的操作步骤
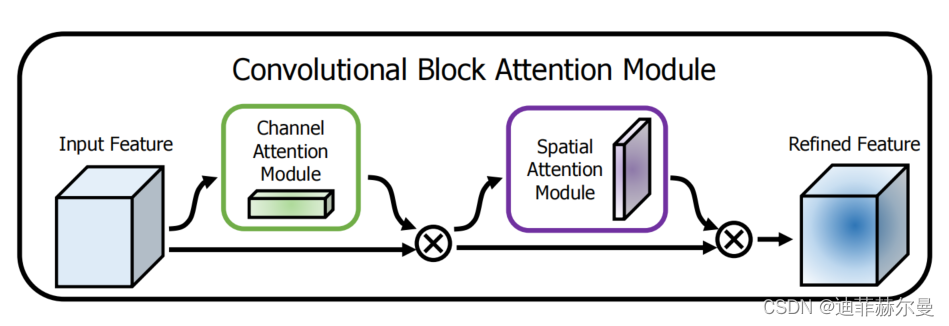
CBAM 的概述。该模块包含两个顺序执行的子模块:通道和空间。在深度网络的每个卷积块中,中间特征图都会通过我们的模块(CBAM)进行自适应优化。
CBAM 模块包括两个主要的子模块:通道注意力模块和空间注意力模块。首先,通道注意力模块通过压缩特征图的空间维度来强调“重要的”通道;其次,空间注意力模块则聚焦于“哪里”是图像的重要部分,这是对通道注意力的补充。这两个模块的顺序应用确保了网络能够综合考虑哪些特征是重要的,从而更精确地调整特征图。
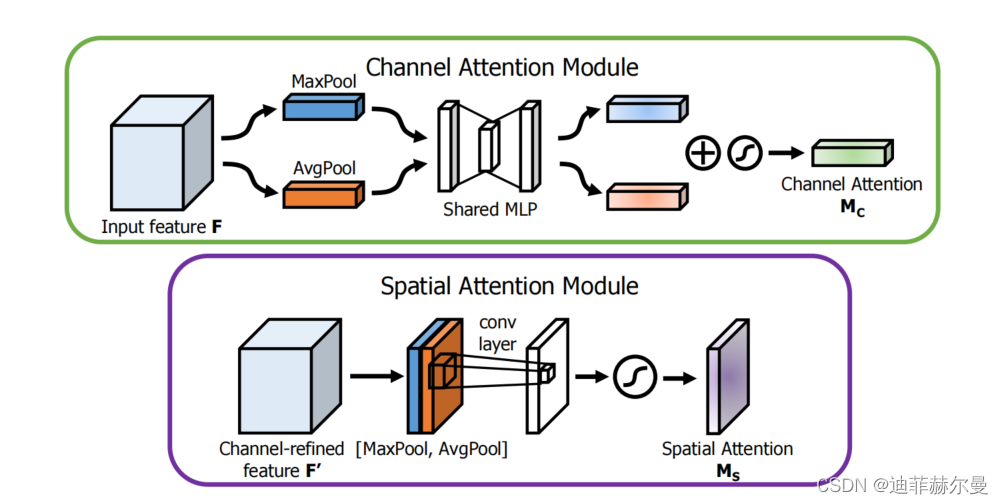
每个注意力子模块的示意图。如图所示,通道子模块同时利用最大池化输出和平均池化输出,并通过一个共享的网络进行处理;而空间子模块则利用在通道轴上进行池化的两个相似输出,并将它们传递给一个卷积层。
文章贡献
这篇文章的主要贡献包括:
- 提出了一个简单而有效的注意力模块
CBAM,能够广泛应用于各种CNN模型以增强其表征能力。 - 通过在
ImageNet-1K、MS COCO和VOC 2007数据集上的广泛实验验证了CBAM的有效性。 - 展示了
CBAM在多种模型上一致地提升分类和检测性能,证明了其广泛的适用性。
实验结果与应用
实验结果表明,CBAM 能在不同的网络架构中提供一致的性能提升。无论是在图像分类还是在对象检测的任务中,CBAM 增强的网络都比基线模型表现更好。例如,在使用 ResNet-50 基线的 ImageNet 分类任务中,CBAM 能显著降低误差,从而提高准确率。此外,CBAM 对计算和参数的额外要求极低,使其非常适合集成到现有的复杂网络中,甚至是轻量级网络中,如 MobileNet。
对未来工作的启示
CBAM 的成功展示了注意力机制在深度学习中的潜力,特别是在自动强调重要特征并抑制次要特征方面。这种机制不仅可以提高模型的表现,还可以提高模型对输入数据中的噪声和不相关信息的鲁棒性。未来的工作可以探索将 CBAM 集成到更多类型的神经网络中,或者开发更先进的注意力机制,以解决更广泛的问题,如视频处理和自然语言处理。CBAM 的设计思想也可能激发研究人员思考如何通过注意力机制来优化模型的计算效率和性能。
代码
# https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf
import numpy as np
import torch
from torch import nn
from torch.nn import initclass ChannelAttention(nn.Module):def __init__(self, channel, reduction=16):super().__init__()self.maxpool = nn.AdaptiveMaxPool2d(1)self.avgpool = nn.AdaptiveAvgPool2d(1)self.se = nn.Sequential(nn.Conv2d(channel, channel // reduction, 1, bias=False),nn.ReLU(),nn.Conv2d(channel // reduction, channel, 1, bias=False),)self.sigmoid = nn.Sigmoid()def forward(self, x):max_result = self.maxpool(x)avg_result = self.avgpool(x)max_out = self.se(max_result)avg_out = self.se(avg_result)output = self.sigmoid(max_out + avg_out)return outputclass SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super().__init__()self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size // 2)self.sigmoid = nn.Sigmoid()def forward(self, x):max_result, _ = torch.max(x, dim=1, keepdim=True)avg_result = torch.mean(x, dim=1, keepdim=True)result = torch.cat([max_result, avg_result], 1)output = self.conv(result)output = self.sigmoid(output)return outputclass CBAM(nn.Module):def __init__(self, channel=512, reduction=16, kernel_size=7):super().__init__()self.ca = ChannelAttention(channel=channel, reduction=reduction)self.sa = SpatialAttention(kernel_size=kernel_size)def forward(self, x):b, c, _, _ = x.size()residual = xout = x * self.ca(x)out = out * self.sa(out)return out + residualif __name__ == "__main__":input = torch.randn(64, 256, 8, 8)model = CBAM(channel=256, reduction=16, kernel_size=7)output = model(input)print(output.shape)