TransNetR Transformer-based Residual Network for Polyp Segmentation with Multi-Center Out-of-Distribution Testing 阅读笔记
1. 论文名称
《TransNetR Transformer-based Residual Network for Polyp Segmentation with Multi-Center Out-of-Distribution Testing》
用于多中心分布外测试的息肉分割的基于transformer的残差网络
论文来源:https://arxiv.org/pdf/2303.07428.pdf
源码: https://github.com/DebeshJha.
2. 摘要
结肠镜检查被认为是检测结直肠癌 (CRC) 及其癌前病变(即息肉)最有效的筛查测试。然而,由于息肉异质性和观察者间的依赖性,该手术的漏诊率很高。因此,考虑到临床实践中息肉检测和分割的重要性,提出了几种深度学习驱动的系统。尽管取得了改进的结果,但现有的自动化方法在实现实时处理速度方面效率较低。此外,在对患者间数据(尤其是从不同中心收集的数据)进行评估时,他们的性能显着下降。因此,我们打算开发一种新颖的基于实时深度学习的架构,即基于 Transformer 的残差网络(TransNetR),用于结肠息肉分割并评估其诊断性能。所提出的架构 TransNetR 是一个编码器-解码器网络,由作为编码器的预训练 ResNet50、三个解码器块以及网络末端的上采样层组成。 TransNetR 获得了 0.8706 的高骰子系数和 0.8016 的平均交集,并在 Kvasir-SEG 数据集上保持了 54.60 的实时处理速度。除此之外,这项工作的主要贡献在于通过在分布外(测试分布未知且与训练分布不同)数据集上测试所提出的算法来探索 TransNetR 的通用性。作为一个用例,我们在 PolypGen(6 个独特中心)数据集和其他两个流行的息肉分割基准数据集上测试了我们提出的算法。在分布外测试期间,我们在所有三个数据集上都获得了最先进的性能。 TransNetR 的源代码将在 https://github.com/DebeshJha 公开发布。
简单来讲:开发一个实时的分割网格,基于transformer的残差网络,编码器使用预训练ResNet50,有三个解码器块,最后网络末端有一个上采样层。实验表明,实时处理速度高,泛化能力强。
3. 介绍与相关工作
结直肠癌死亡率高,可通过结肠镜检查识别然后切除息肉以防止癌变,识别息肉要求医生能获得息肉的准确位置信息和精确边界细节,但传统结肠镜检查中,漏检率高。因为评估过程快,息肉外观高度变化,与周围粘膜相似。
现有成果面临的困境:
- 在实际场景中性能受限制;
- 息肉形状与性别、年龄、种族和地区相关,息肉位置与种族有关;
- 不同结肠镜检查中心的视频捕获方式会造成域转移问题;
- 只考虑性能,而不考虑泛化问题,即使用不同检查中心的数据集,因为无数据。
本文:
提出基于transformer的残差网络,以实现准确、实时的息肉分割,并推广得到分布外的数据(验证集是其他的),并保持了高性能和实时处理速度。
在iD 和OOD数据集上得到验证,不同中心的数据集的结果表明,泛化能力更强。
4.方法
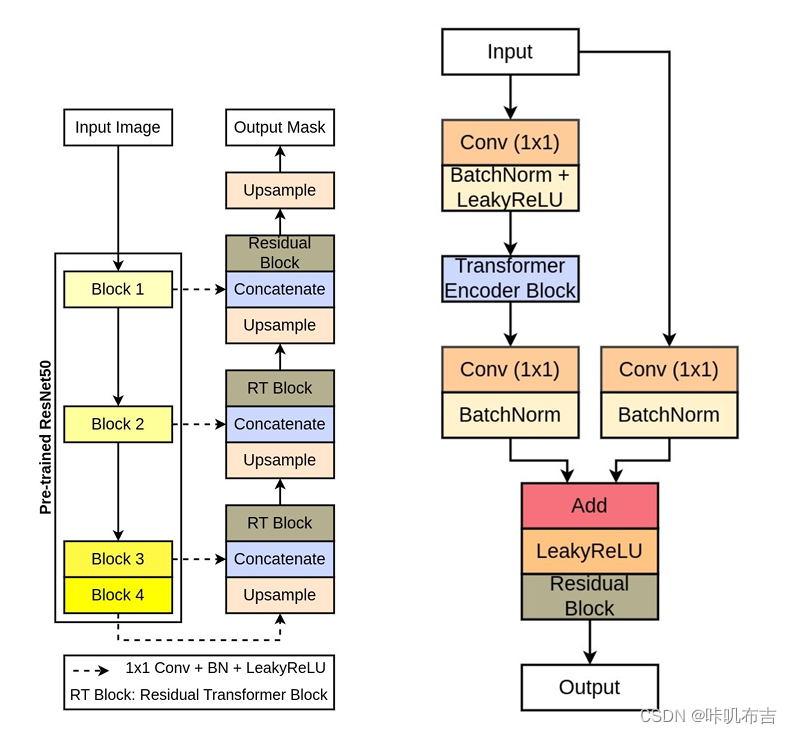
TransNetR框架图与Residual Transformer模块图
输入的数据经过预训练的ResNet50,从中提起四个不同的中间特征图,中间特征图经过1x1卷积层,然后经过批量归一化和LeakyReLU激活函数。1x1卷积层可以减少特征通道数量,从而减少参数数量。然后进入三个解码器模块,缩减后的特征图被送入第一个解码器块,首先经过双线性上采样层,上采样层将特征图的空间维度增加了两倍,然后将其与下一个简化的特征图连接起来,进入Residual Transformer块。在Residual Transformer中,首先经过1x1卷积层,批量归一化和LeakyReLU激活函数,被重新整成补丁,然后进入transformer层,transformer层由多头自注意力组成,以学习更好的特征表示,再整回与之前一致的大小,再经过1x1卷积层,加批量归一化,add输入的特征图,经过LeakyReLU激活函数,再经过残差网络输出。第一个解码器块的输出被传递到第二个解码器块,再传递到最后一个。在最后一个解码器块中,残差transformer替换成简单的残差块,可以减少可训练的参数的数量,最终解码器的输出通过双线性上采样层,将特征图的空间维度增加两倍,再通过带有sigmoid激活函数的1x1卷积层。
残差transformer:
以1x1的卷积层开始,然后是批量归一化和LeakyReLU激活函数,然后使用大小为4的补丁展平(铺成一行或者一列)特征图,然后传递到有四个头两层的transformer中,transformer块提供自注意力,使得更加鲁棒,然后重新整形成输入的形状,再经过1x1卷积,批量归一化,与输入特征图相加,然后通过LeakyReLU激活函数,再经过残差网络输入。
5.实验结果
使用了四个数据集完成实验:Kvasir-SEG、PolypGen、PolypGen、BKAI-IGH、Kvasir-SEG。Kvasir-SEG有1000张图片,其中880张作为训练集,其余作为测试集;再使用其他三个数据集做泛化能力评估,其中PolypGen是来自三个检测中心的不同人群,所以这样会更真实,贴近真实世界场景。
该模型使用Pytorch框架实现,并在NVIDIA RTX3090 GPU系统上进行实验。使用Anadam优化器,学习率为1e4,batch大小设置为8。使用的损失函数是二元交叉熵和dice损失的组合。使用广泛使用的评估指标(例如mIoU、mDSC、Recall)对TransNetR与SOTA方法的性能进行了定量比较、精度、F2 和处理速度(FPS)。
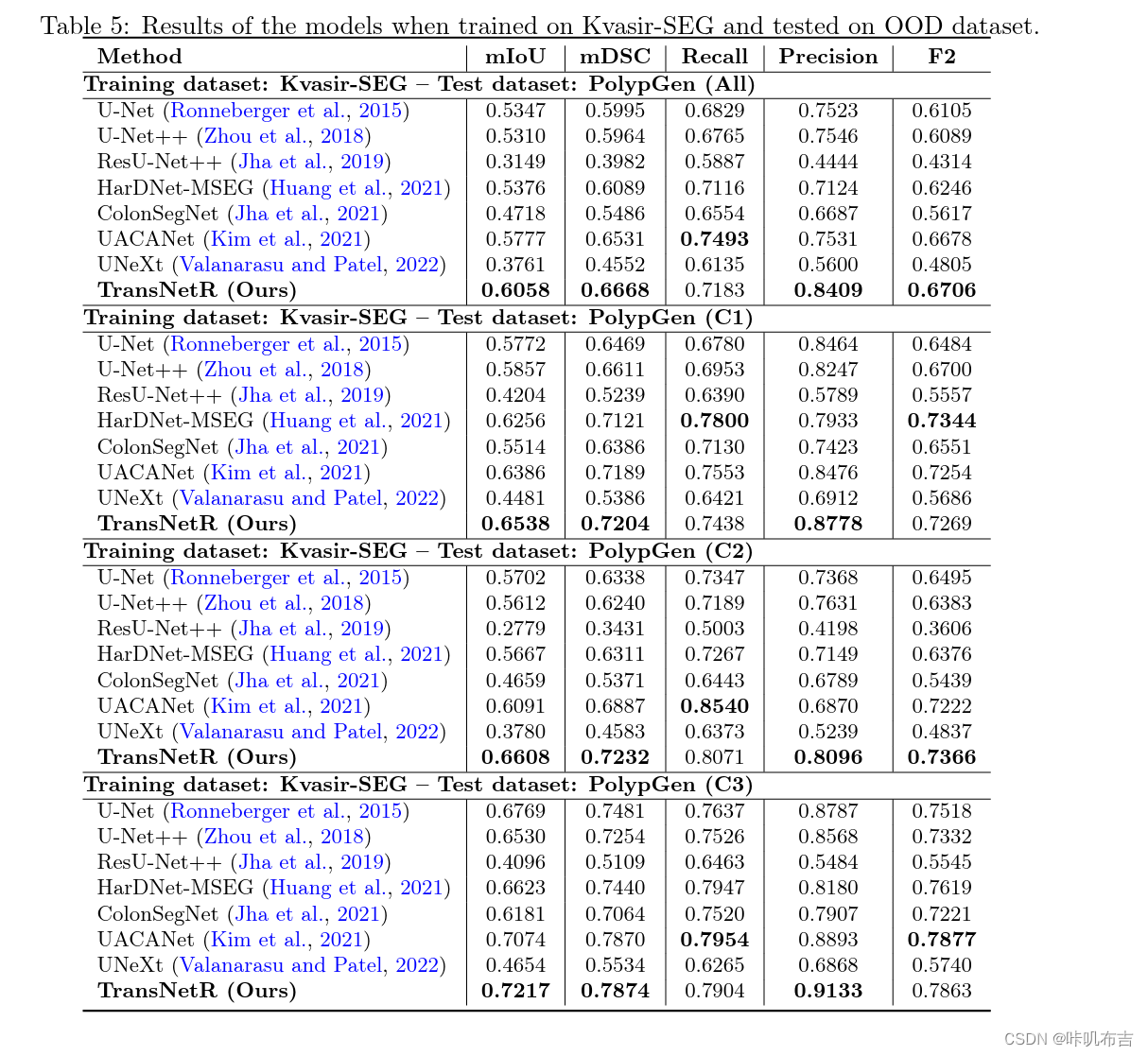
结果
学习能力:在测试集上,定性与定量结果如下:
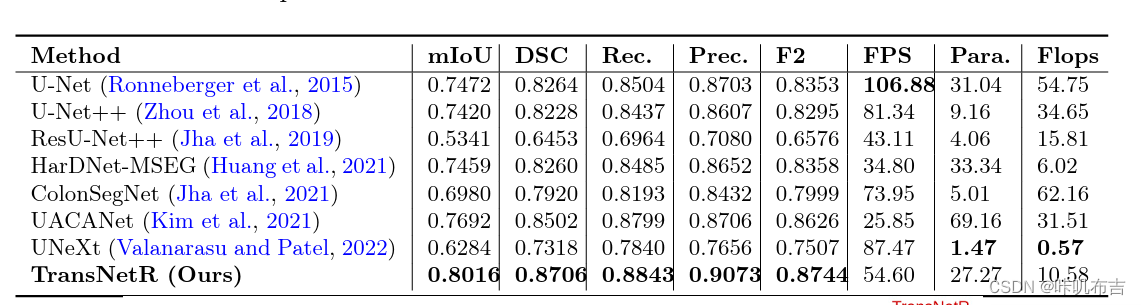

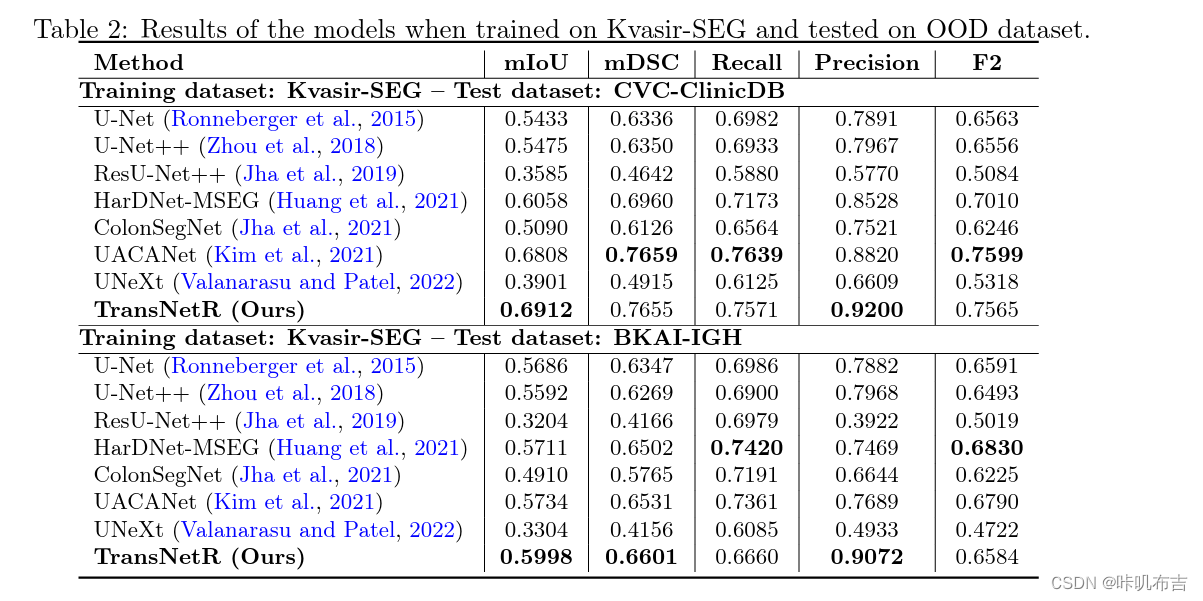
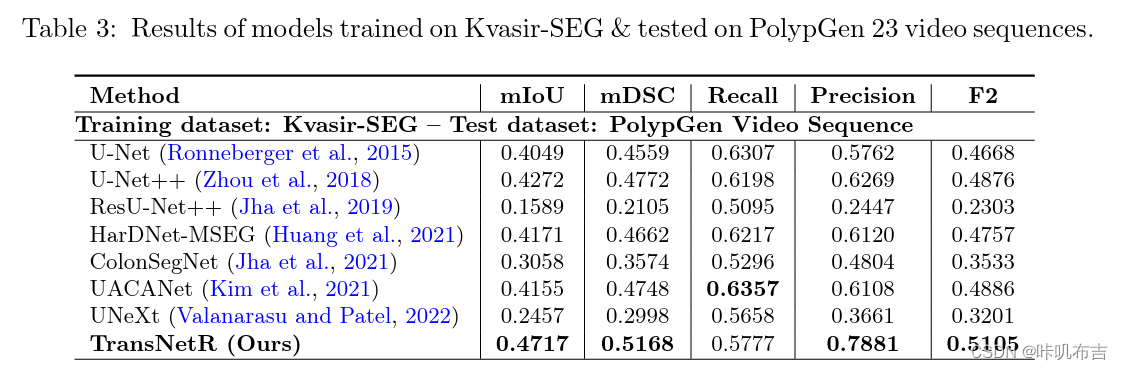
泛化能力:在其他未见过的数据集上测试
消融实验:评估RT块的影响

6.总结
提出了一个基于transformer的残差网络,具有更高的处理速度(FPS=54.60,其实从数据表中可以看出,也并没有特别高,文中只强调了优于UACANet),更强的学习能力和泛化能力。