说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。

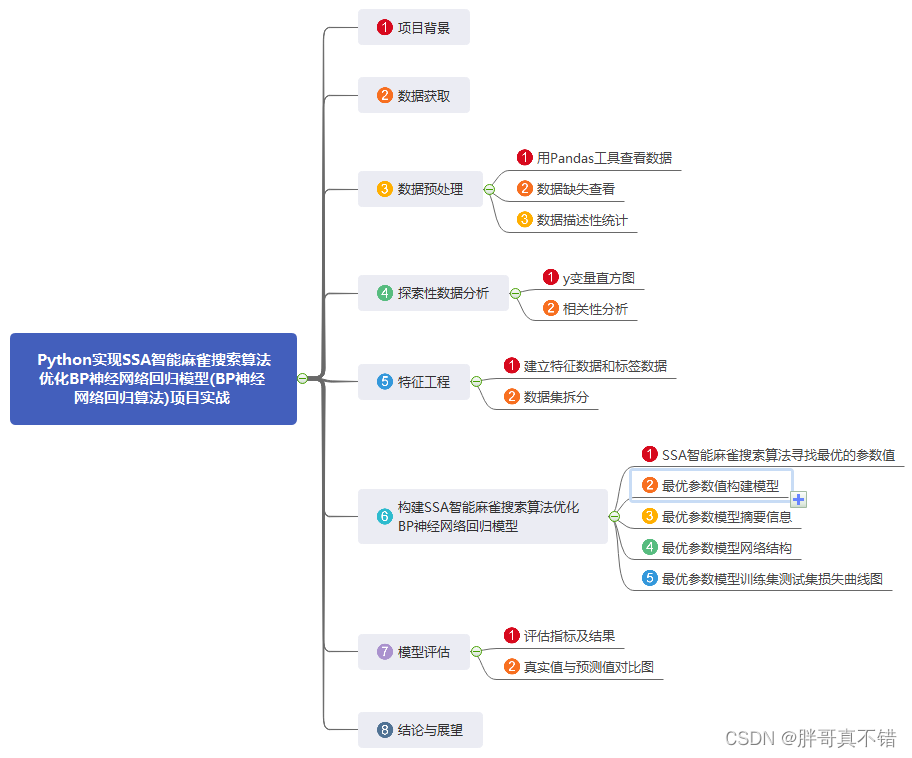
1.项目背景
麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种新型的群智能优化算法,在2020年提出,主要是受麻雀的觅食行为和反捕食行为的启发。
在麻雀觅食的过程中,分为发现者(探索者)和加入者(追随者),发现者在种群中负责寻找食物并为整个麻雀种群提供觅食区域和方向,而加入者则是利用发现者来获取食物。为了获得食物,麻雀通常可以采用发现者和加入者这两种行为策略进行觅食。种群中的个体会监视群体中其它个体的行为,并且该种群中的攻击者会与高摄取量的同伴争夺食物资源,以提高自己的捕食率。此外,当麻雀种群意识到危险时会做出反捕食行为。
本项目通过SSA智能麻雀搜索算法优化BP神经网络回归模型。
2.数据获取
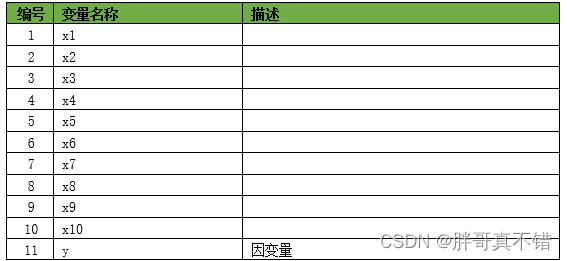
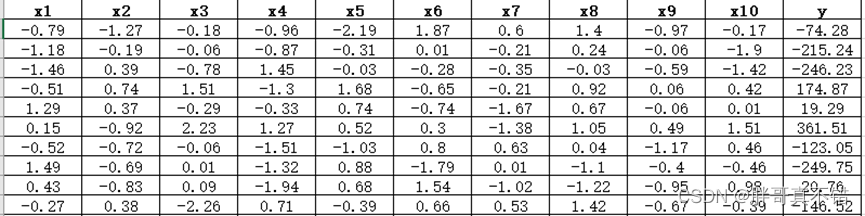
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
数据详情如下(部分展示):
3.数据预处理
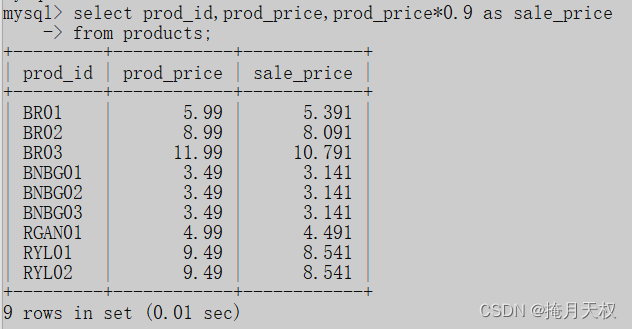
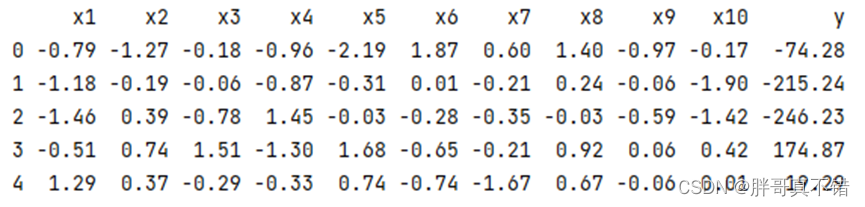
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:
3.2 数据缺失查看
使用Pandas工具的info()方法查看数据信息:
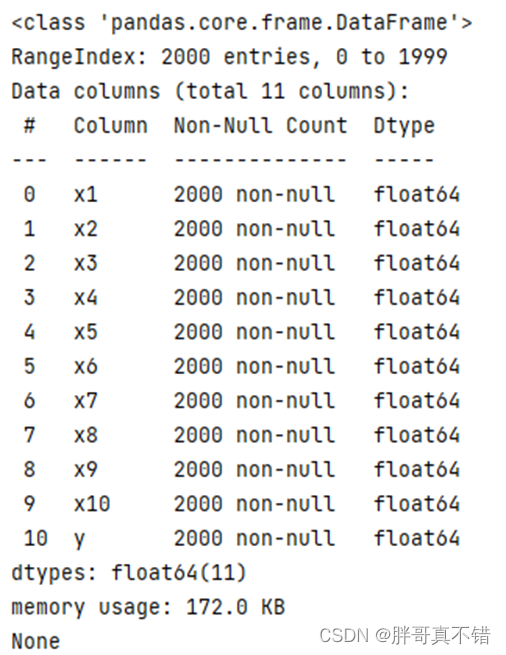
从上图可以看到,总共有11个变量,数据中无缺失值,共2000条数据。
关键代码:

3.3 数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
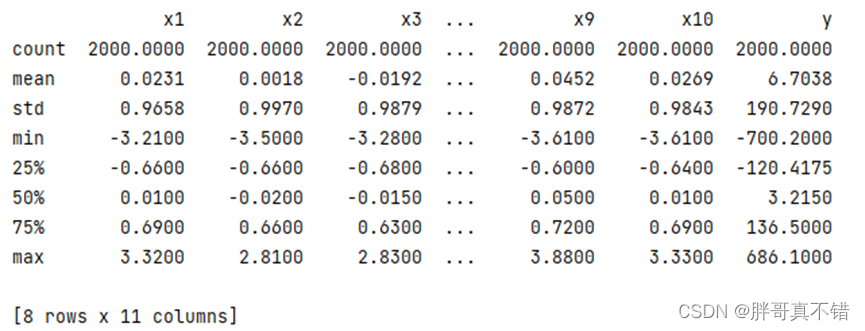
关键代码如下:

4.探索性数据分析
4.1 y变量直方图
用Matplotlib工具的hist()方法绘制直方图:

从上图可以看到,y变量主要集中在-400~400之间。
4.2 相关性分析
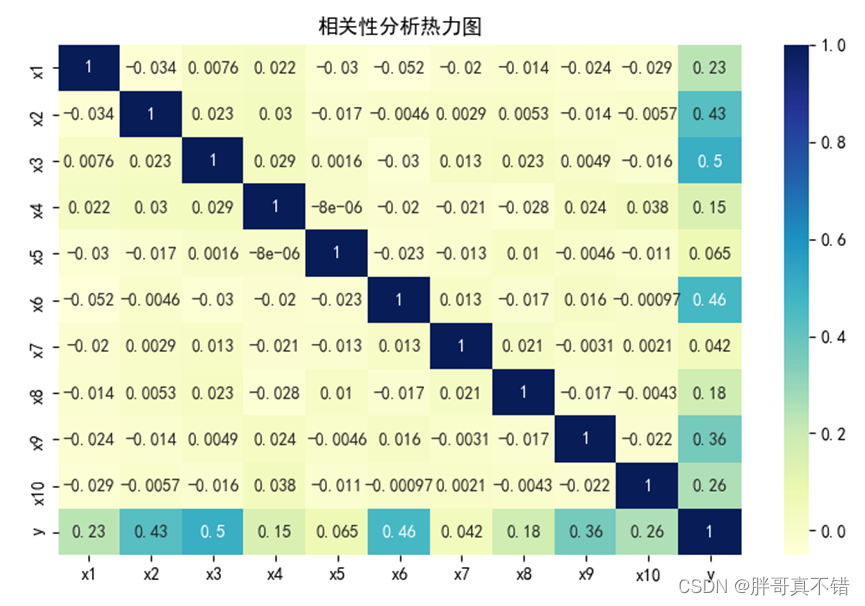
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:

6.构建SSA智能麻雀搜索算法优化BP神经网络回归模型
主要使用SSA智能麻雀搜索算法优化BP神经网络回归算法,用于目标回归。
6.1 SSA智能麻雀搜索算法寻找最优的参数值
最优参数:

6.2 最优参数值构建模型

6.3 最优参数模型摘要信息

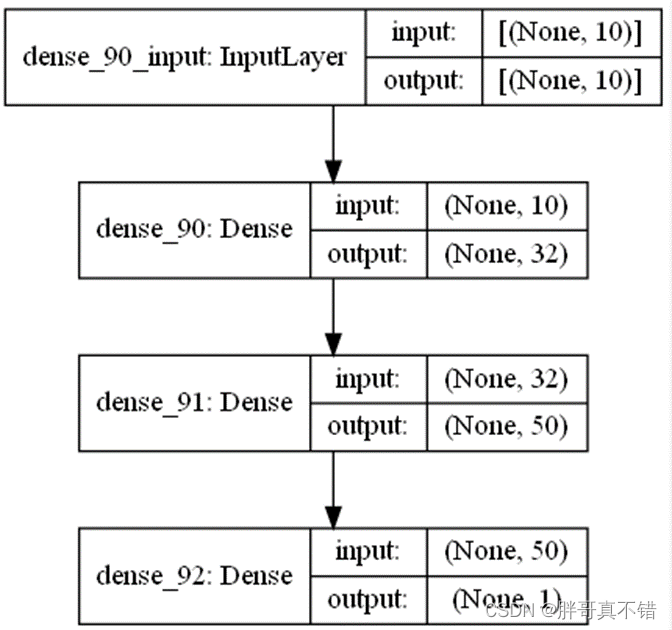
6.4 最优参数模型网络结构
6.5 最优参数模型训练集测试集损失曲线图

7.模型评估
7.1 评估指标及结果
评估指标主要包括可解释方差值、平均绝对误差、均方误差、R方值等等。
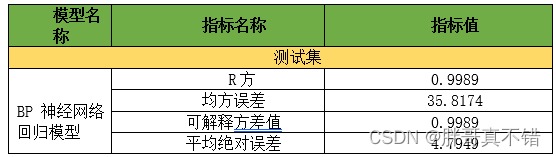
从上表可以看出,R方0.9989,为模型效果良好。
关键代码如下:

7.2 真实值与预测值对比图

从上图可以看出真实值和预测值波动基本一致,模型拟合效果良好。
8.结论与展望
综上所述,本文采用了SSA智能麻雀搜索算法寻找BP神经网络算法的最优参数值来构建回归模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。
# 定义边界函数
def Bounds(s, Lb, Ub):temp = sfor i in range(len(s)):if temp[i] < Lb[0, i]: # 小于最小值temp[i] = Lb[0, i] # 取最小值elif temp[i] > Ub[0, i]: # 大于最大值temp[i] = Ub[0, i] # 取最大值# ******************************************************************************# 本次机器学习项目实战所需的资料,项目资源如下:# 项目说明:# 链接:https://pan.baidu.com/s/1c6mQ_1YaDINFEttQymp2UQ# 提取码:thgk# ******************************************************************************# y变量分布直方图
fig = plt.figure(figsize=(8, 5)) # 设置画布大小
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
data_tmp = data['y'] # 过滤出y变量的样本
# 绘制直方图 bins:控制直方图中的区间个数 auto为自动填充个数 color:指定柱子的填充色
plt.hist(data_tmp, bins='auto', color='g')更多项目实战,详见机器学习项目实战合集列表:
机器学习项目实战合集列表_机器学习实战项目_胖哥真不错的博客-CSDN博客
项目代码咨询、获取,请见下方公众号。





![[数据分析与可视化] Python绘制数据地图5-MovingPandas绘图实例](https://img-blog.csdnimg.cn/img_convert/27d0e108fa1ee2c9ea997ab4c1812057.png)