冒泡排序
起泡排序,别名“冒泡排序”,该算法的核心思想是将无序表中的所有记录,通过两两比较关键字,得出升序序列或者降序序列。
算法步骤
- 比较相邻的元素。如果第一个元素大于第二个元素,就交换它们。
- 对每一对相邻的元素作相同的操作,从开始第一对到末尾的最后一对。
- 针对所有的元素重复以上操作,每次出来最后一个
算法理解
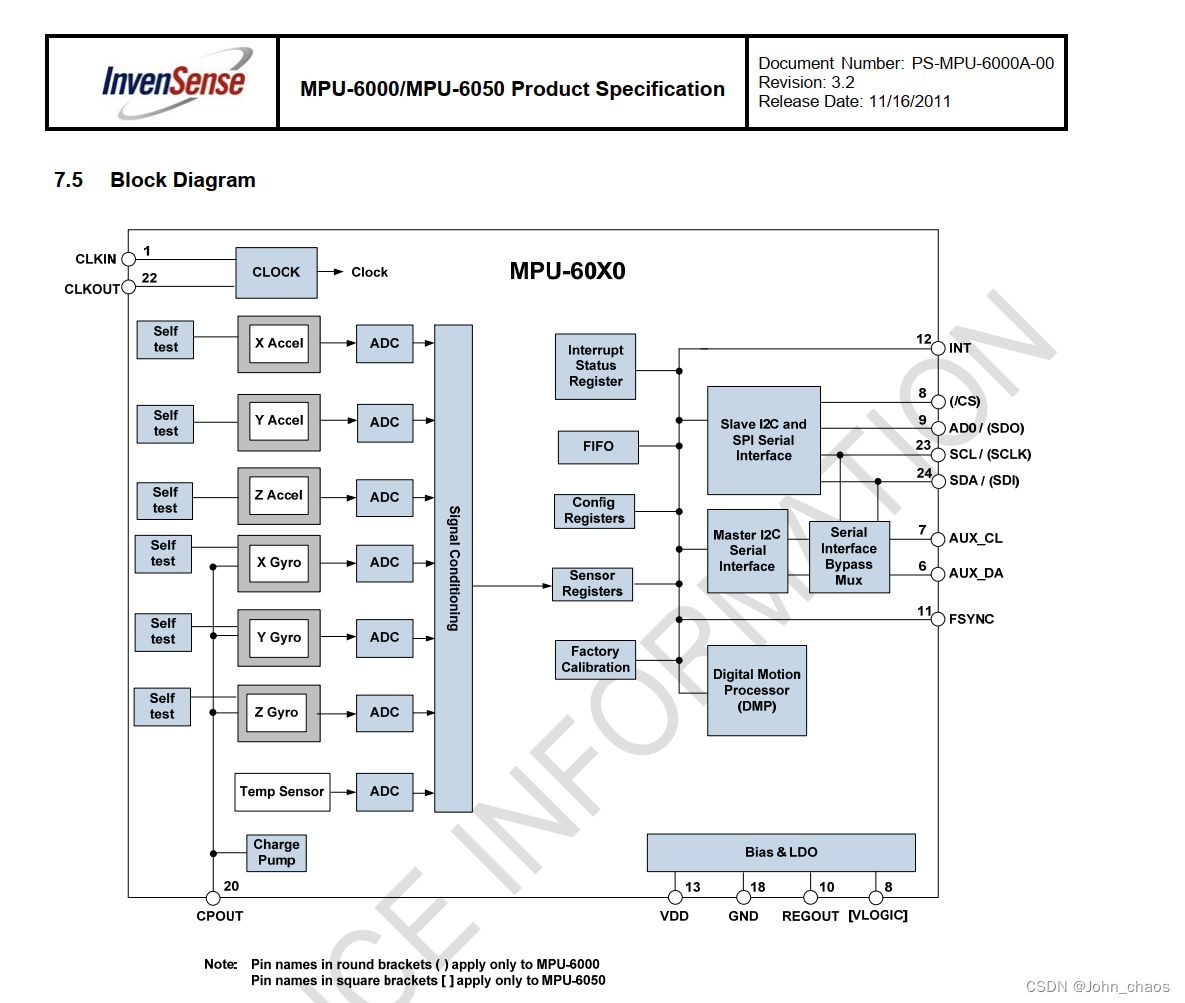
例如,对无序表{49,38,65,97,76,13,27,49}进行升序排序的具体实现过程如图 1 所示:

图 1 第一次起泡
如图 1 所示是对无序表的第一次起泡排序,最终将无序表中的最大值 97 找到并存储在表的最后一个位置。具体实现过程为:
- 首先 49 和 38 比较,由于 38<49,所以两者交换位置,即从(1)到(2)的转变;
- 然后继续下标为 1 的同下标为 2 的进行比较,由于 49<65,所以不移动位置,(3)中 65 同 97 比较得知,两者也不需要移动位置;
- 直至(4),97 同 76 进行比较,76<97,两者交换位置,如(5)所示;
- 同样 97>13(5)、97>27(6)、97>49(7),所以经过一次冒泡排序,最终在无序表中找到一个最大值 97,第一次冒泡结束;
由于 97 已经判断为最大值,所以第二次冒泡排序时就需要找出除 97 之外的无序表中的最大值,比较过程和第一次完全相同。

经过第二次冒泡,最终找到了除 97 之外的又一个最大值 76,比较过程完全一样,这里不再描述。
通过一趟趟的比较,一个个的“最大值”被找到并移动到相应位置,直到检测到表中数据已经有序,或者比较次数等同于表中含有记录的个数,排序结束,这就是起泡排序。
代码实现
#include "iostream"
using namespace std;void swap(int *a, int *b){//交换a和b的位置int temp;temp = *a;*a = *b;*b = temp;
}
int main()
{int array[8] = {49,38,65,97,76,13,27,49};//有多少记录,就需要多少次冒泡,当比较过程,所有记录都按照升序排列时,排序结束for (int i = 0; i < 8; i++){int key=0;//每次开始冒泡前,初始化 key 值为 0//每次起泡从下标为 0 开始,到 8-i 结束for (int j = 0; j+1<8-i; j++){if (array[j] > array[j+1]){key=1;swap(&array[j], &array[j+1]);}}//如果 key 值为 0,表明表中记录排序完成if (key==0) {break;}}for (i = 0; i < 8; i++){cout << array[i] << " ";}return 0;
}
运行结果:
13 27 38 49 49 65 76 97
总结
使用起泡排序算法,其时间复杂度同实际表中数据的无序程度有关。若表中记录本身为正序存放,则整个排序过程只需进行 n-1(n 为表中记录的个数)次比较,且不需要移动记录;若表中记录为逆序存放(最坏的情况),则需要 n-1趟排序,进行 n(n-1)/2 次比较和数据的移动。所以该算法的时间复杂度为O(n2)。
快速排序
快速排序本质上是可以说是冒泡排序基础上的递归分治法,它也是分治算法在排序算法上的一种经典应用。
算法思想
快速排序是通过多次比较和交换来实现有序的。在一次排序中把将要排序的元素分成两个独立的子数组,其中一个子数组的所有元素全大于另一个组数组的所有元素,然后继续递归排序这两部分。
算法思想步骤:
- 从序列中挑出一个元素,称之为边界或者基准
- 重新排序数列,所有元素比基准值小的放在基准前面,所有元素比基准值大的放在基准后面(相同的数可以放在任意一边)。这个操作结束后,该基准就处于序列的中间位置,这个操作称之为分区操作
- 递归吧小于基准元素的组数组和大于基准元素的子数组排序
算法理解

代码实现
#include "iostream"
using namespace std;#define MAX 9
//单个记录的结构体
typedef struct {int key;
}SqNote;
//记录表的结构体
typedef struct {SqNote r[MAX];int length;
}SqList;
//此方法中,存储记录的数组中,下标为 0 的位置时空着的,不放任何记录,记录从下标为 1 处开始依次存放
int Partition(SqList *L,int low,int high){L->r[0]=L->r[low];int pivotkey=L->r[low].key;//直到两指针相遇,程序结束while (low<high) {//high指针左移,直至遇到比pivotkey值小的记录,指针停止移动while (low<high && L->r[high].key>=pivotkey) {high--;}//直接将high指向的小于支点的记录移动到low指针的位置。L->r[low]=L->r[high];//low 指针右移,直至遇到比pivotkey值大的记录,指针停止移动while (low<high && L->r[low].key<=pivotkey) {low++;}//直接将low指向的大于支点的记录移动到high指针的位置L->r[high]=L->r[low];}//将支点添加到准确的位置L->r[low]=L->r[0];return low;
}
void QSort(SqList *L,int low,int high){if (low<high) {//找到支点的位置int pivotloc=Partition(L, low, high);//对支点左侧的子表进行排序QSort(L, low, pivotloc-1);//对支点右侧的子表进行排序QSort(L, pivotloc+1, high);}
}
void QuickSort(SqList *L){QSort(L, 1,L->length);
}
int main() {SqList *L = new SqList;L->length=8;L->r[1].key=49;L->r[2].key=38;L->r[3].key=65;L->r[4].key=97;L->r[5].key=76;L->r[6].key=13;L->r[7].key=27;L->r[8].key=49;QuickSort(L);for (int i=1; i<=L->length; i++) {cout << L->r[i].key << " ";}return 0;
}
运行结果:
13 27 38 49 49 65 76 97
总结
快速排序算法的时间复杂度为O(nlogn),是所有时间复杂度相同的排序方法中性能最好的排序算法。