10-分组数据
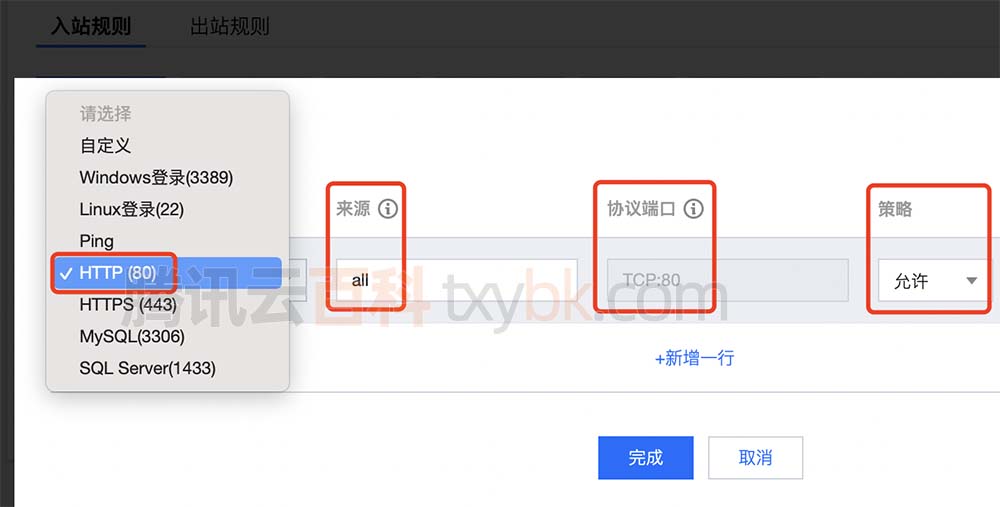
两个新的select子句:group by子句和having子句。
10.1-数据分组
上面我们学到了,使用SQL中的聚集函数可以汇总数据,这样,我们就能够对行进行计数,计算和,计算平均数。
目前为止,所有的计算都是在表的所有数据或者匹配特定的where子句的数据上进行的。
select count(*) as num_prods
from products
where vend_id = 'DLL01';如上述SQL语句,返回供应商为DLL01的所有产品数目。
但是,现在有一个功能,就是想要返回每个供应商的产品数目;或者返回只提供一种商品的供应商数目。
这个时候就需要用到这次要写的分组的内容了。
使用分组可以将数据分为多个逻辑组,对每个组进行聚集计算。
10.2-创建分组
分组是使用select语句和group by子句进行创建的。
select vend_id,count(*) as num_prods
from products
group by vend_id;
上述SQL语句执行后,会分别查出来供应商为BRS01的产品数目,供应商为DLL01的产品数目,供应商为FNG01的产品数目。
group by子句指示DBMS按照vend_id排序并分组数据。这么做就会对每个不同的vend_id进行分别查询。
因为使用了group by子句,就不必指定要计算和估值的每个组了,系统会自动完成。group by子句提示DBMS对数据按照vend_id进行分组,然后对每个组而不是整个结果集进行聚集。根据上述的SQL语句,DBMS按照我们的指示,分为三组,然后每组进行分别计算。
使用group by之前,需要知道下面内容:
-
gruop by子句可以包含任意数目的列,因而可以对分组进行嵌套,更细致地进行分组。
-
如果group by 子句中嵌套了分组,数据将在最后指定的分组上进行汇总。在建立分组时,所有列都一起计算,所以不能从个别列取数据。
-
group by 子句中累出的每一列都必须是检索列或者有效的表达式,但是不能为聚集函数。如果在select中使用表达式,则必须在gruop by子句中指定相同的表达式,不能使用别名。
-
大多数SQL实现不允许group by 列带有长度可变的数据类型(如文本字段,备注型字段)。
-
除聚集计算语句外,select语句中的每一列都必须在group by子句中给出。
-
如果分组列中包含具有NULL值的行,则NULL将作为一个分组返回。如果列中有多行NULL值,他们将分为一组。
-
group by子句必须出现在where子句之后,order by子句之前。
10.3-过滤分组
除了使用group by分组数据外,SQL还能过滤分组,可以规定包括哪些分组,排除哪些分组。例如,我们查找至少有两个订单的顾客;商品数量大于100的供应商等。必须基于完整的分组而不是个别的行进行过滤。
看到过滤,就想起了where子句,但是过滤分组这个功能可能不能使用where,因为where过滤的是某些不符合条件的行,而不是组。
SQL提供的另一个子句:having子句,是专门用来过滤分组的。having类似于where。
目前为止,所有where子句都可以使用having进行替换。只不过having用户过滤组,where用于过滤行。
having支持所有where操作符:where子句的条件,包括通配符条件和带多个操作符的子句,学过的这些有关where的所有技术和选项都使用having。句法是相同的,只是关键字不同而已。
select cust_id,count(*) as orders
from orders
group by cust_id
having count(*) >= 2;
上述SQL语句通过分组查询订单量大于等于2的顾客id和订单数量。可以看到,我们是通过having过滤组数据的。
having和where的差别:where在数据分组前进行过滤,having在数据分组后进行过滤。经过where过滤后的数据,就不包含在组中了。
select vend_id,count(*) as num_prods
from products
where prod_price >= 4
group by vend_id
having count(*) >= 2;
上述SQL语句用于查询产品列表中,某个供应商供应的产品数量大于等于2,并且产品价格大于等于4的供应商的数量。
第一行正常使用selec子句,使用聚集函数count(*)。第三行过滤产品价格大于等于4的行;第四行按照vend_id进行分组;然后第五行过滤计数大于等于2的组。
如果没有where子句,会怎么样呢?
select vend_id,count(*) as num_prods
from products
group by vend_id
having count(*) >= 2;
上述SQL语句除去了where子句,可以看到数据比上面多了一条。
关于使用where和having:如果没有group by子句,大多数DBMS会同等对待这两个子句。但是实际开发过程中应该知道,只用having时,后面要跟group by子句。
10.4-分组和排序
group by 和 order by
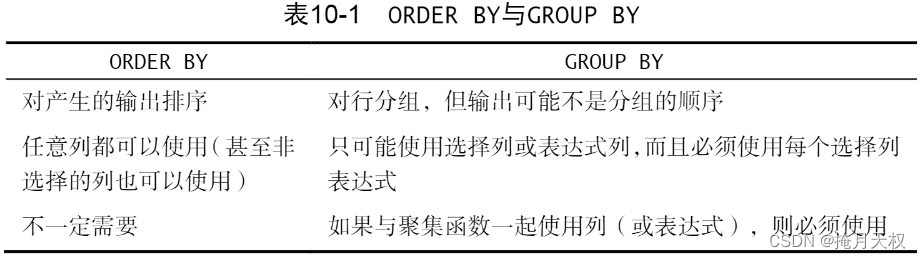
对于第一条区别,有时我们使用group by,大部分情况是按照分组顺序进行排序的,但并不是总是这样。如果想要指定输出的数据为某种指定的排序,那么还是要指定order by子句,即使它的效果等同于group by子句。
select order_num,count(*) as items
from orderitems
group by order_num
having count(*) >=3; 
但是,如果我们按照订购物品的数目进行排序输出。
select order_num,count(*) as items
from orderitems
group by order_num
having count(*) >= 3
order by items,order_num; 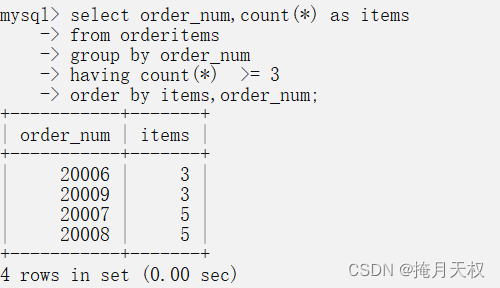
上述SQL语句按照order_num分组数据,查询符合大于等于3的数据,然后按照数量进行排序。
10.5-select子句顺序

练习
-
OrderItems表包含每个订单的每个产品。编写SQL语句,返回每个订单号(order_num)各有多少行数(order_lines),并 按order_lines对结果进行排序。
select order_num,count(*) as order_lines from orderitems group by order_num order by order_lines;
-
编写SQL语句,返回名为cheapest_item的字段,该字段包含每个供应商成本最低的产品(使用Products表中的prod_price), 然后从最低成本到最高成本对结果进行排序。
select vend_id,min(prod_price) as cheapest_item from products group by vend_id order by cheapest_item;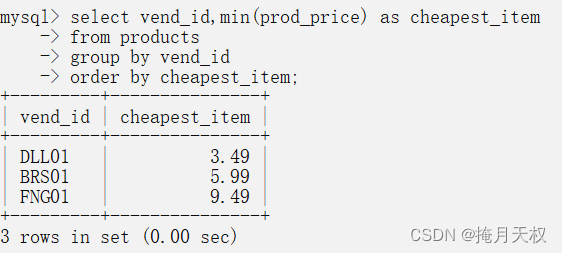
-
确定最佳顾客非常重要,请编写SQL语句,返回至少含100项的所有订单的订单号(OrderItems表中的order_num)。
select order_num,count(*) as orders from orderitems where quantity >= 100 group by order_num;
-
确定最佳顾客的另一种方式是看他们花了多少钱。编写SQL语句,返回总价至少为1000的所有订单的订单号(OrderItems表中的order_num)。提示:需要计算总和(item_price乘以quantity)。按订单号对结果进行排序。
select order_num from orderitems where (item_price * quantity) >= 1000 group by order_num;
-
下面的SQL语句有问题吗?(尝试在不运行的情况下指出。)
SELECT order_num, COUNT(*) AS items FROM OrderItems GROUP BY items HAVING COUNT(*) >= 3 ORDER BY items, order_num;
group by 子句应当时候表中的字段名,而不是别名,正确:
group by order_num;