共识机制的背景
加密货币都是去中心化的,去中心化的基础就是P2P节点众多,那么如何吸引用户加入网络成为节点,有那些激励机制?同时,开发的重点是让多个节点维护一个数据库,那么如何决定哪个节点写入?何时写入?一旦写入,又怎么保证不被其他的节点更改(不可逆)?回答这些问题的答案,就是共识机制。
容错性:目前的客户-服务商模型一般是中心化的网络形态
而区块链提倡的是无中心形态,网络中的每个节点都是平等的,因此天生具有良好的容错性,如下图:

而为了保证众多非中心节点的数据同步/安全,如何让大部分节点达成一致?
共识机制应运而生
公有链代表算法:
1.PoW
**(Proof of Work):工作量证明机制. 可以理解为按劳分配. **
- 相对公平/公正,但耗能巨大
- 51%算力风险
- 比特币 以太坊 莱特币 狗狗币
2.PoS
(Proof of Stake):股权证明机制。
- 根据币龄(持有代币+持有时间)影响共识
- 一旦权益用来进行签约区块,币龄将清零,避免规模经济影响
- 节能
- 以太坊Next Peercoin Nxt

3.PoB
焚烧证明 - 通过焚烧代币确认领导地位,相当于PoW
4.DPoW
延迟工作量证明 - 类似于PoB,挖矿获得wood,并通过收集woods影响下一次的决策
- 小矿工也有春天
5.DPoS
(Delegated Proof of Stake):授权股权证明机制
- 类似于人民代表大会制度,但区域划分是灵活/动态的
- 节能/快速/高校 出块0.5s
- EOS BitShares Lisk Ark
小结
- POW 工作量证明机制. 类似于按劳分配
- POS 股权证明机制. 持有股票的人, 就有对应的权利, 持有的越多, 权利越大 .
- DPOS 授权股权证明机制. 类似于董事会. 董事会成员数量有限, 由大家选举产生. 被选中的董事会成员可以行使权利.
联盟链代表算法:
6.PBFT:拜占庭容错算法
N >= 3F + 1 N为总计算机数,F为有问题的计算机总数
拜占庭容错能够容纳将近1/3的错误节点误差,IBM创建的Hyperledger就是使用了
该算法作为共识算法(<1.0)
- 其他使用者 Ripple Stella Dispatch
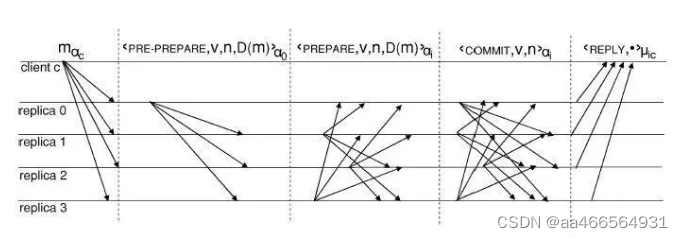
SBFT: Hyperledger(>1.0)采用了SBFT算法:SBFT提出了一个使用收集器(collector)的线
性通信模式。这种模式下不再将消息发给每一个replica,而是发给collector,然后
再由collector广播给所有replicas。减少client端的信息数量,增加可管理节点数
注:Zyzzyva也使用了collector,但是将collector的职责放到了client,而SBFT将collector的职责放到了replica
RBFT:在PBFT的基础上前置了propagate阶段且client需要广播消息而不是只
给“primary”,用以保证好的replica一定能够收到请求。
DBFT: 授权BFT算法
- Neo
7.Paxos:怕诺斯算法 - 分布式一致性算法
Paxos需要一半以上的节点同意即可确认,(非容错型)

(1)Proposer:接收客户的请求,代表客户向Acceptor发起提案。
(2)Acceptor:监听来自Proposer的提案,并决定是否接受和回复。
(3)Learner:提案被接受后,提交并执行提案的内容。


关键点:
1. 每个节点均会记录最大的编号并比较;如编号小于目前节点的最大编号,拒绝,反之,处理
2. 提案者在非成功的状态下,会提交新的提案
3. 提案者接收到多条不同消息时,以编号大的为准
4. 接收者接收到多条不同消息时,拒绝编号小的请求,接受编号大的请求
8.RAFT:分布式一致性算法
非容错型,通过选举Leader的方式进行决策,其余的为follower。
是Paxos的另一种选择,与 Paxos 相比,Raft 有着基本相同运行效率,但是更容易理解,也更容易被用在系统开发上。
RAFT运行中最重要的两个活动:
1. 选主 Leader Election - 只要有超过一半的节点投支持票了,Candidate 才会被选举为 Leader
特殊情况1:主掉线后,剩余的将自发选主 - 如原主回来,原主会降级为follower
特殊情况2:并发情况存在多个candidate的场景上,会持续发起vote,优先原则
2. 复制日志 Log Replication -
日志存在commit - uncommit状态,
如出现多个leader的数据不一致的情况,以commit为准重新选主,保证数据的一致性