文章目录
- 框架的安装包
- 数据仓库概念
- 项目需求及架构设计
- 项目需求分析
- 项目框架
- 技术选型
- 系统数据流程设计
- 框架版本选型
- 集群资源规划设计
- 数据生成模块
- 数据埋点
- 主流埋点方式
- 埋点数据上报时机
- 服务器和JDK准备
- 搭建三台Linux虚拟机(VMWare)
- 编写集群分发脚本xsync
- SSH无密登录配置
- JDK准备
- 模拟数据
- 集群日志生成脚本
框架的安装包
链接:https://pan.baidu.com/s/18-WmBBgoTwOyucs-0Rmfew?pwd=4wf9
提取码:4wf9
数据仓库概念
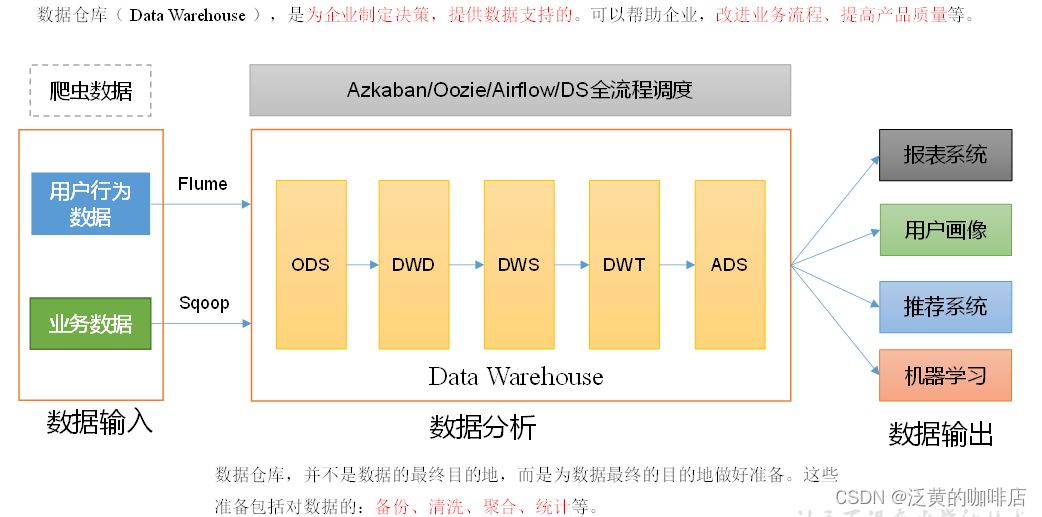
数据仓库( Data Warehouse ),是为企业制定决策,提供数据支持的。可以帮助企业,改进业务流程、提高产品质量等。
数据仓库的输入数据通常包括:业务数据、用户行为数据和爬虫数据等
-
业务数据:就是各行业在处理事务过程中产生的数据。比如用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在MySQL、Oracle等数据库中。
-
用户行为数据:用户在使用产品过程中,通过埋点收集与客户端产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。用户行为数据通常存储在日志文件中。
-
爬虫数据:通常事通过技术手段获取其他公司网站的数据。
项目需求及架构设计
项目需求分析

项目框架
技术选型
技术选型主要考虑因素:数据量大小、业务需求、行业内经验、技术成熟度、开发维护成本、总成本预算
- 数据采集传输:Flume,Kafka,Sqoop,Logstash,DataX
- 数据存储:MySQL,HDFS,HBase,Redis,MongoDB
- 数据计算:Hive,Tez,Spark, Flink, Storm
- 数据查询:Presto,Kylin,Impala,Druid,ClickHouse,Doris
- 数据可视化:Echarts,Superset,QuickBI,DataV
- 任务调度:Azkaban,Oozie,DolphinScheduler,Airflow
- 集群监控:Zabbix,Prometheus
- 元数据管理:Atlas
- 权限管理:Ranger,Sentry
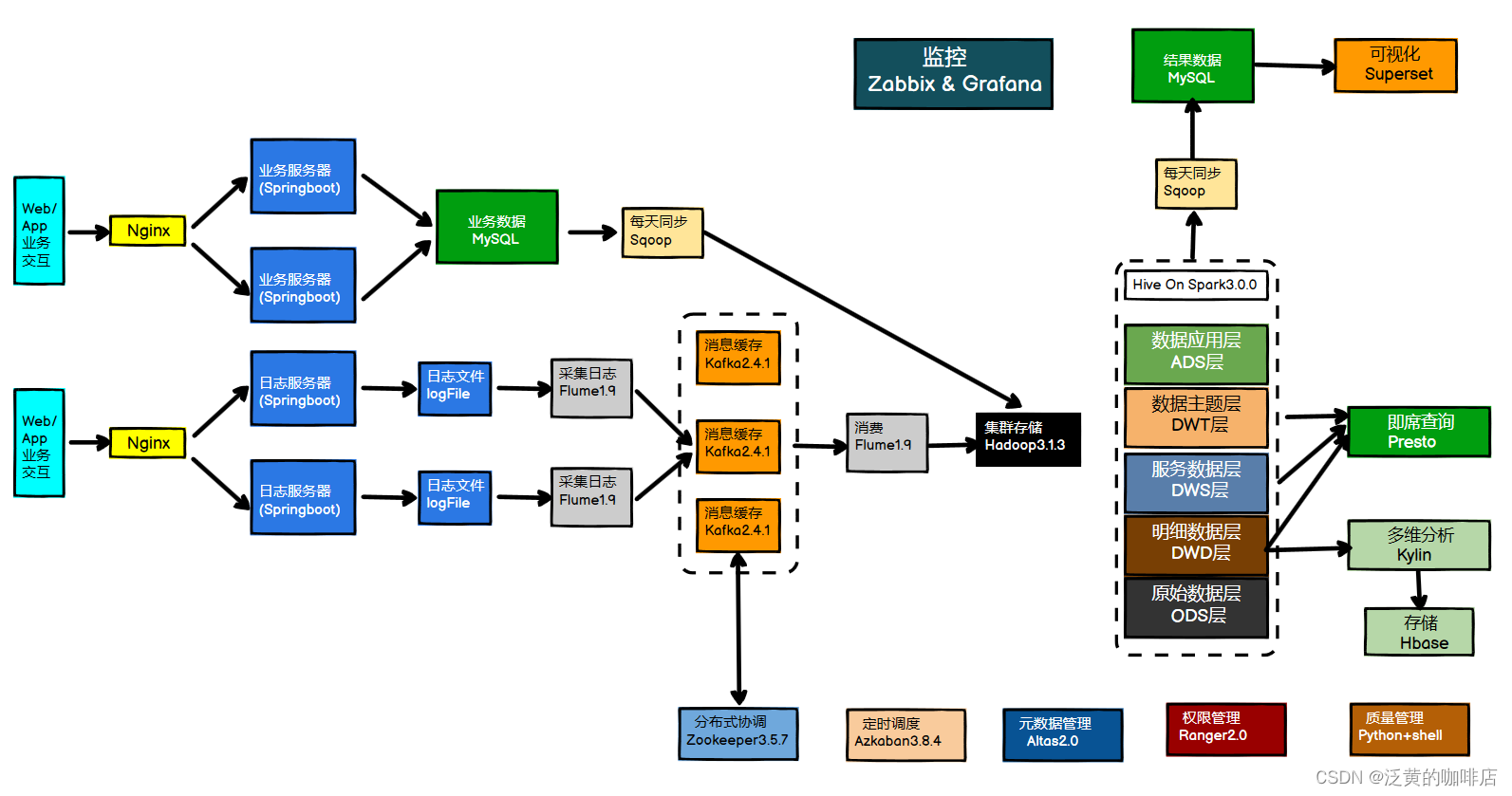
系统数据流程设计
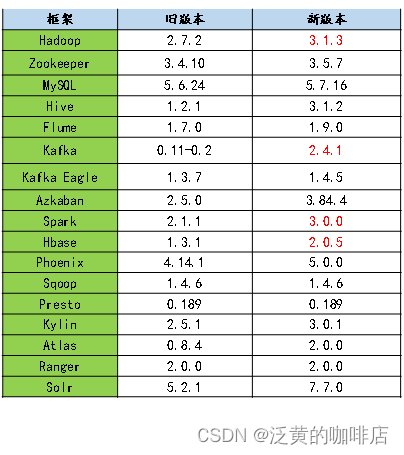
框架版本选型
1)如何选择Apache/CDH/HDP版本?
(l)Apache:运维麻烦,组件间兼容性需要自己调研。(一般大厂使用,技术实力雄厚,有专业的运维人员)(建议使用)
(2)CDH:国内使用最多的版本,但CM不开源,今年开始收费,一个节点1万美金/年。
(3) HDP:开源,可以进行二次开发,但是没有CDH稳定,国内使用较少
2)云服务选择
(1)阿里云的EMR、MaxCompute、DataWorks
(2)亚马逊云EMR
(3)腾讯云EMR
(4)华为云EMR
Apache框架版本
集群资源规划设计
通常会搭建一套生产集群和一套测试集群。生产集群运行生产任务,测试集群用于上线前代码编写和测试。
生产集群
- 消耗内存的分开
- 数据传输数据比较紧密的放在一起(Kafka 、Zookeeper)
- 客户端尽量放在一到两台服务器上,方便外部访问
- 有依赖关系的尽量放到同一台服务器(例如:Hive和Azkaban Executor)
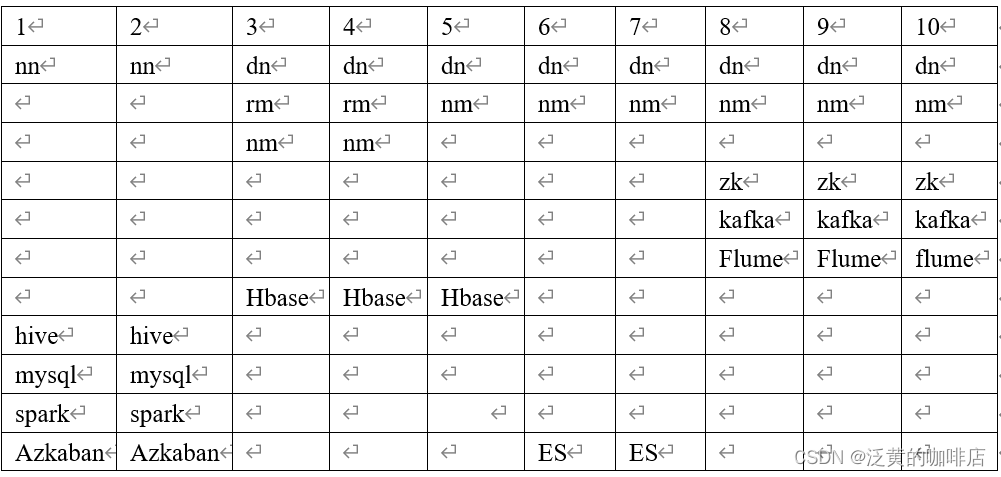
测试集群服务器规划
| 服务名称 | 子服务 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|---|
| HDFS | NameNode | √ | ||
| HDFS | DataNode | √ | √ | √ |
| HDFS | SecondaryNameNode | √ | ||
| Yarn | NodeManager | √ | √ | √ |
| Yarn | Resourcemanager | √ | ||
| Zookeeper | Zookeeper Server | √ | √ | √ |
| Flume(采集日志) | Flume | √ | √ | |
| Kafka | Kafka | √ | √ | √ |
| Flume(消费Kafka) | Flume | √ | ||
| Hive | Hive | √ | ||
| MySQL | MySQL | √ | ||
| Sqoop | Sqoop | √ | ||
| Presto | Coordinator | √ | ||
| Presto | Worker | √ | √ | |
| Azkaban | AzkabanWebServer | √ | ||
| Azkaban | AzkabanExecutorServer | √ | ||
| Spark | √ | |||
| Kylin | √ | |||
| HBase | HMaster | √ | ||
| HBase | HRegionServer | √ | √ | √ |
| Superset | √ | |||
| Atlas | √ | |||
| Solr | Jar | √ | ||
| 服务数总计 | 19 | 8 | 8 |
数据生成模块
数据埋点
主流埋点方式
目前主流的埋点方式,有代码埋点(前端/后端)、可视化埋点、全埋点三种。
代码埋点是通过调用埋点SDK函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对应的 OnClick 函数里面调用SDK提供的数据发送接口,来发送数据。
可视化埋点只需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就可以通过访问分析平台的“圈选”功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集 SDK 按照圈选的配置自动进行用户行为数据的采集和发送。
全埋点是通过在产品中嵌入SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。
埋点数据上报时机
埋点数据上报时机包括两种方式。
方式一,在离开该页面时,上传在这个页面产生的所有数据(页面、事件、曝光、错误等)。优点,批处理,减少了服务器接收数据压力。缺点,不是特别及时。
方式二,每个事件、动作、错误等,产生后,立即发送。优点,响应及时。缺点,对服务器接收数据压力比较大。
服务器和JDK准备
搭建三台Linux虚拟机(VMWare)
搭建教程
编写集群分发脚本xsync
1)xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析
①rsync命令原始拷贝:
rsync -av /opt/module root@hadoop103:/opt/
②期望脚本:
xsync要同步的文件名称
③说明:在/home/atguigu/bin这个目录下存放的脚本,yudan用户可以在系统任何地方直接执行。
(3)脚本实现
①在用的家目录/home/yudan下创建bin文件夹
[yudan@hadoop102 ~]$ mkdir bin
②在/home/yudan/bin目录下创建xsync文件,以便全局调用
[yudan@hadoop102 ~]$ cd /home/yudan/bin
[yudan@hadoop102 ~]$ vim xsync
在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
done
③修改脚本xsync具有执行权限
[yudan@hadoop102 bin]$ chmod +x xsync
④测试脚本
[yudan@hadoop102 bin]$ xsync xsync
SSH无密登录配置
(1)hadoop102上生成公钥和私钥:
[yudan@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(2)将hadoop102公钥拷贝到要免密登录的目标机器上
[yudan@hadoop102 .ssh]$ ssh-copy-id hadoop102
[yudan@hadoop102 .ssh]$ ssh-copy-id hadoop103
[yudan@hadoop102 .ssh]$ ssh-copy-id hadoop104
(3)hadoop103上生成公钥和私钥:
[yudan@hadoop103 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(4)将hadoop103公钥拷贝到要免密登录的目标机器上
[yudan@hadoop103 .ssh]$ ssh-copy-id hadoop102
[yudan@hadoop103 .ssh]$ ssh-copy-id hadoop103
[yudan@hadoop103 .ssh]$ ssh-copy-id hadoop104
JDK准备
1)卸载现有JDK(3台节点)
[yudan@hadoop102 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps[yudan@hadoop103 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps[yudan@hadoop104 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
(1)rpm -qa:表示查询所有已经安装的软件包
(2)grep -i:表示过滤时不区分大小写
(3)xargs -n1:表示一次获取上次执行结果的一个值
(4)rpm -e --nodeps:表示卸载软件
2)解压JDK到/opt/module目录下
[yudan@hadoop102 software]# tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
3)配置JDK环境变量
(1)新建/etc/profile.d/my_env.sh文件
[yudan@hadoop102 module]# sudo vim /etc/profile.d/my_env.sh
添加如下内容,然后保存(:wq)退出
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
(2)让环境变量生效
[yudan@hadoop102 software]$ source /etc/profile.d/my_env.sh
4)测试JDK是否安装成功
[yudan@hadoop102 module]# java -version
如果能看到以下结果、则Java正常安装
java version “1.8.0_212”
5)分发JDK
[yudan@hadoop102 module]$ xsync /opt/module/jdk1.8.0_212/
6)分发环境变量配置文件
[yudan@hadoop102 module]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh
7)分别在hadoop103、hadoop104上执行source
[yudan@hadoop103 module]$ source /etc/profile.d/my_env.sh
[yudan@hadoop104 module]$ source /etc/profile.d/my_env.sh
模拟数据
1)将application.yml、gmall2020-mock-log-2021-01-22.jar、path.json、logback.xml上传到hadoop102的/opt/module/applog目录下
(1)创建applog路径
[yudan@hadoop102 module]$ mkdir /opt/module/applog
(2)上传文件application.yml到/opt/module/applog目录
2)生成日志
(1)进入到/opt/module/applog路径,执行以下命令
[yudan@hadoop102 applog]$ java -jar gmall2020-mock-log-2021-01-22.jar
(2)在/opt/module/applog/log目录下查看生成日志
[yudan@hadoop102 log]$ ll
集群日志生成脚本
在hadoop102的/home/atguigu目录下创建bin目录,这样脚本可以在服务器的任何目录执行。
[yudan@hadoop102 ~]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/atguigu/.local/bin:/home/yudan/bin
(1)在/home/atguigu/bin目录下创建脚本lg.sh
[yudan@hadoop102 bin]$ vim lg.sh
(2)在脚本中编写如下内容
#!/bin/bash
for i in hadoop102 hadoop103; doecho "========== $i =========="ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2021-01-22.jar >/dev/null 2>&1 &"
done
注:
①/opt/module/applog/为jar包及配置文件所在路径
②/dev/null代表Linux的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”。
标准输入0:从键盘获得输入 /proc/self/fd/0
标准输出1:输出到屏幕(即控制台) /proc/self/fd/1
错误输出2:输出到屏幕(即控制台) /proc/self/fd/2
(3)修改脚本执行权限
[yudan@hadoop102 bin]$ chmod u+x lg.sh
(4)将jar包及配置文件上传至hadoop103的/opt/module/applog/路径
(5)启动脚本
[yudan@hadoop102 module]$ lg.sh
(6)分别在hadoop102、hadoop103的/opt/module/applog/log目录上查看生成的数据