协程结构体定义
之前我们使用linux下协程函数实现了线程切换,使用的是ucontext_t结构体,和基于这个结构体的四个函数。现在我们要用这些工具来实现我们自己的一个线程结构体,并实现线程调度和线程切换、挂起。
首先我们来实现以下线程结构体:
struct thread_t {ucontext_t ctx;void (*func)();void* args;int state;char stack[1024 * 128]; //128kB栈空间
};其中state有四种值,RUNNABLE,RUNING,SUSPEND,END,分别对应0,1,2,3,即就绪,运行,挂起、终止这四种状态,对应操作系统下一个进程执行和终止之间的三种状态。
再写一个调度的结构体
struct scheduler {ucontext_t main;std::vector<thread_t> threads;int running_thread;scheduler():running_thread(-1) {};
};调度器需要保存主函数上下文,需要调度的线程集合threads,用一个vector实现,和当前运行线程id;运行线程id初始时赋为-1,表示无线程正在运行。
这样线程结构体和线程调度器就已经实现和完成了。
接下来我们要实现下我们自己的线程创建函数,参数为调度器scheduler,执行函数func和执行函数的参数args
int thread_create(scheduler& myscheduler, void (*func)(), void* args) {thread_t *newthread = new thread_t();newthread->ctx.uc_link = &myscheduler.main;newthread->ctx.uc_stack.ss_sp = newthread->stack;newthread->ctx.uc_stack.ss_size = 1024*128;newthread->func = func;newthread->args = args;newthread->state = 0;myscheduler.threads.push_back(*newthread);return myscheduler.threads.size() - 1;
}首先创建一个thread_t类型变量作为新线程,将其ctx变量的后继函数设定为调度器中主函数,栈空间和栈大小设置为其默认成员变量。对应参数赋值为给定参数方便后续使用。初始状态设置为就绪态,并将其放入调度器线程集合,线程id设置为当前线程集合大小-1.
线程挂起函数
int thread_yield(scheduler& myscheduler) {if (myscheduler.running_thread == -1) return 0;myscheduler.threads[myscheduler.running_thread].state = 2;setcontext(&myscheduler.main);return 1;
}线程挂起函数首先判断调度器中当前运行线程id是否为-1,如果是的话就直接返回0,表示协程挂起失败。否则将正在运行线程id对应到调度器中线程集合中相应下标的元素,将其值置为2(挂起),将当前上下文设置为主函数,返回1;
线程恢复运行函数
int thread_resume(scheduler& myscheduler,int threadId) {if (threadId < 0 || threadId >= myscheduler.threads.size()) return -1;if (myscheduler.threads[threadId].state == 2) {// if (myscheduler.running_thread != -1) thread_yield(myscheduler);myscheduler.running_thread = threadId;myscheduler.threads[threadId].state = 1;swapcontext(&myscheduler.main,&myscheduler.threads[threadId].ctx);} else if (myscheduler.threads[threadId].state == 0) { // if (myscheduler.running_thread != -1) thread_yield(myscheduler);myscheduler.running_thread = threadId;myscheduler.threads[threadId].state = 1;getcontext(&myscheduler.threads[threadId].ctx);makecontext(&myscheduler.threads[threadId].ctx, myscheduler.threads[threadId].func, 1, myscheduler.threads[threadId].args);swapcontext(&myscheduler.main,&myscheduler.threads[threadId].ctx);}
}
线程恢复运行函数首先判断给定线程Id是否<0或者>调度器线程集合大小,如果是就说明不满足条件,直接返回。否则判断其状态,我们需要处理的有挂起态和就绪态两种状态,两种情况下都需要将当前运行线程(如果有的话)挂起,将需要运行的线程状态置为1。如果当前需要运行线程之前是挂起,直接切换栈空间即可。否则需要将取当前栈空间并用makecontext函数处理下,再进行切换。
线程全部结束判断函数
int scheduler_finished(scheduler& myscheduler) {for (int i = 0; i < myscheduler.threads.size(); i++) {if (myscheduler.threads[i].state != 3) return 0;}return 1;
}判断调度器内部线程集合里线程状态是否全为0,是就说明全部执行完,返回0,否则返回1。
线程结束状态设置函数
void thread_exit() {myscheduler.threads[running_thread].state = 3;myscheduler.running_thread = -1;
}在每个线程函数尾调用,设置该线程状态为终止,设置调度器当前运行线程id为-1
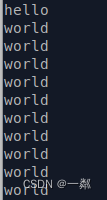
运行结果如下.
测试代码如下:
#include <iostream>
#include <ucontext.h>
#include <vector>struct thread_t {ucontext_t ctx;void (*func)();void* args;int state;char stack[1024 * 128]; //128kB栈空间
};struct scheduler {ucontext_t main;std::vector<thread_t> threads;int running_thread;scheduler():running_thread(-1) {};
};scheduler myscheduler;int thread_create(scheduler& myscheduler, void (*func)(), void* args) {thread_t *newthread = new thread_t();newthread->ctx.uc_link = &myscheduler.main;newthread->ctx.uc_stack.ss_sp = newthread->stack;newthread->ctx.uc_stack.ss_size = 1024*128;newthread->func = func;newthread->args = args;newthread->state = 0;myscheduler.threads.push_back(*newthread);return myscheduler.threads.size() - 1;
}int thread_yield(scheduler& myscheduler) {if (myscheduler.running_thread == -1) return 0;myscheduler.threads[myscheduler.running_thread].state = 2;swapcontext(&myscheduler.threads[myscheduler.running_thread].ctx, &myscheduler.main);return 1;
}void thread_exit() {myscheduler.threads[running_thread].state = 3;myscheduler.running_thread = -1;
}int thread_resume(scheduler& myscheduler,int threadId) {if (threadId < 0 || threadId >= myscheduler.threads.size()) return -1;if (myscheduler.threads[threadId].state == 2) {//if (myscheduler.running_thread != -1) thread_yield(myscheduler);myscheduler.running_thread = threadId;myscheduler.threads[threadId].state = 1;swapcontext(&myscheduler.main,&myscheduler.threads[threadId].ctx);} else if (myscheduler.threads[threadId].state == 0) { //if (myscheduler.running_thread != -1) thread_yield(myscheduler);myscheduler.running_thread = threadId;myscheduler.threads[threadId].state = 1;getcontext(&myscheduler.threads[threadId].ctx);makecontext(&myscheduler.threads[threadId].ctx, myscheduler.threads[threadId].func, 1, myscheduler.threads[threadId].args);swapcontext(&myscheduler.main,&myscheduler.threads[threadId].ctx);}
}int scheduler_finished(scheduler& myscheduler) {for (int i = 0; i < myscheduler.threads.size(); i++) {if (myscheduler.threads[i].state != 3) return 0;}return 1;
}void thread1() {std::cout << "hello" << std::endl;thread_exit();
}void thread2() {int n = 10;thread_yield(myscheduler);while (n--)std::cout << "world" << std::endl;thread_exit();
}int main() {getcontext(&myscheduler.main);thread_create(myscheduler, &thread1, nullptr);thread_create(myscheduler, &thread2, nullptr);if (!scheduler_finished(myscheduler)) {thread_resume(myscheduler, 0);}if (!scheduler_finished(myscheduler)) {thread_resume(myscheduler, 1);}if (!scheduler_finished(myscheduler)) {thread_resume(myscheduler, 1);}return 0;
}上面注释掉了两行代码,这两行代码如果不注释掉,就会反映出上面所写代码的一个致命问题——线程运行结束后无法自动设置状态为结束态,导致下一个线程在调用该函数的时候在该线程栈空间和主函数栈空间之间来回切换,会直接结束而不会执行线程2函数体。而且由于某些原因,其实我们只能同时运行一个线程,而无法多线程同时运行,所以挂起只能是由该线程自己主动释放的。
但是每个线程结束时都加了thread_exit之后就不会触发这个判断条件,可以正常使用了。