本文介绍了一种名为DB-GPT的新技术,它将大型语言模型(LLM)与传统数据库系统相结合,提高了用户使用数据库的体验和便利性。DB-GPT可以理解自然语言查询、提供上下文感知的回答,并生成高准确度的复杂SQL查询,适用于不同水平的用户。其核心创新在于采用了私有化的LLM技术,在特定领域的语料库上进行微调,以确保用户隐私和数据安全的同时,获得最先进的LLM的好处。DB-GPT的架构包括一个新颖的知识检索增强生成系统、一种自适应学习机制以及一个基于服务的多模型框架。实验和用户研究表明,DB-GPT代表了数据库交互方式的一种范式转变,提供了更自然、高效和安全的方式与数据仓库互动。该论文还讨论了DB-GPT框架对未来人类数据库交互的影响,并提出了进一步改进和应用的方向。
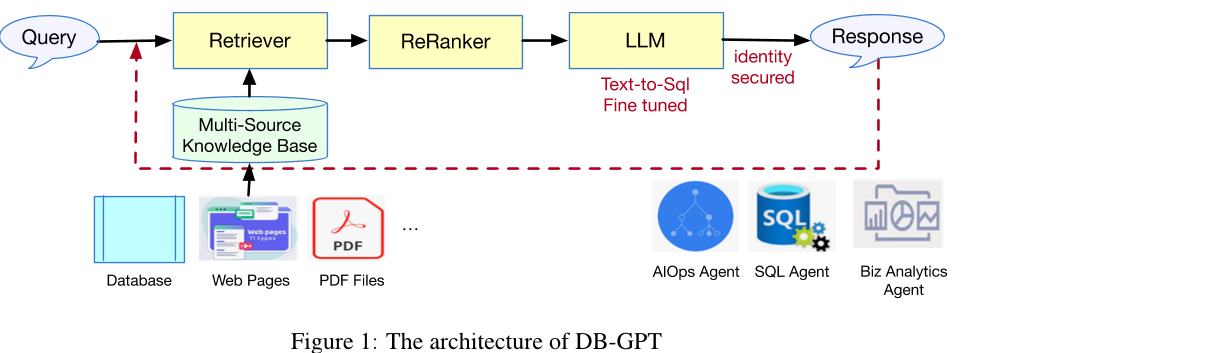

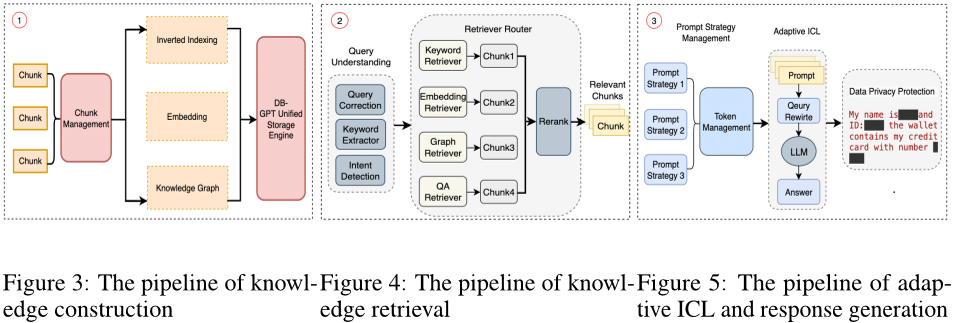
论文方法
方法描述
本文提出了一种名为DB-GPT的多模型框架,用于数据库操作流程中的数据查询、管理和分析。该框架采用了多种技术手段,包括Model-as-a-Service(MaaS)、MetaGPT等,并设计了多个组件,如API服务器、模型控制器、模型工作者等,以实现高效的数据处理和管理。
具体来说,DB-GPT支持多种角色的交互,例如数据分析师、软件工程师和数据库架构师等,提供了完整的数据库操作流程和标准操作程序(SOP)。此外,DB-GPT还使用了元学习技术和自然语言推理能力,使得系统能够更好地理解用户的查询需求并提供更准确的结果。
方法改进
与现有的类似系统相比,DB-GPT具有以下优点:
-
支持多种角色的交互:通过为不同的角色分配特定的任务和职责,DB-GPT可以更好地满足不同用户的需求。
-
强大的自然语言推理能力:DB-GPT使用了预训练的文本到SQL模型,并通过元学习技术进一步提高了其性能。
-
灵活的插件机制:DB-GPT支持基于数据库交互模式的插件,可以方便地扩展系统的功能和应用场景。
解决的问题
DB-GPT主要解决了以下问题:
-
数据库操作流程繁琐:传统的数据库操作需要经过多个步骤,包括数据导入、数据清洗、数据分析等,而DB-GPT将这些步骤整合在一起,简化了整个过程。
-
用户查询需求不明确:由于用户通常使用自然语言来表达查询需求,因此需要一个强大的自然语言推理系统来理解和解析用户的意图。
-
应用场景受限:现有的数据库管理系统往往只能应用于特定领域或场景,而DB-GPT可以通过灵活的插件机制来适应更多的应用场景。
论文实验
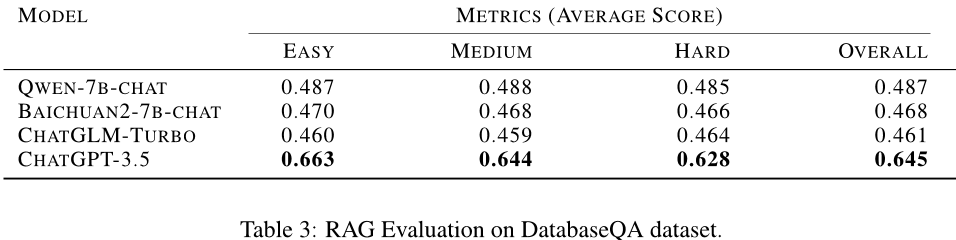
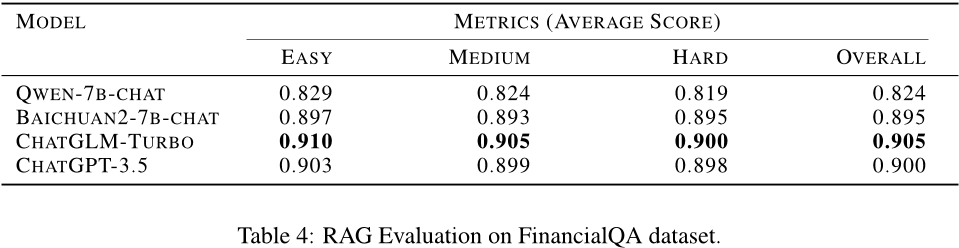
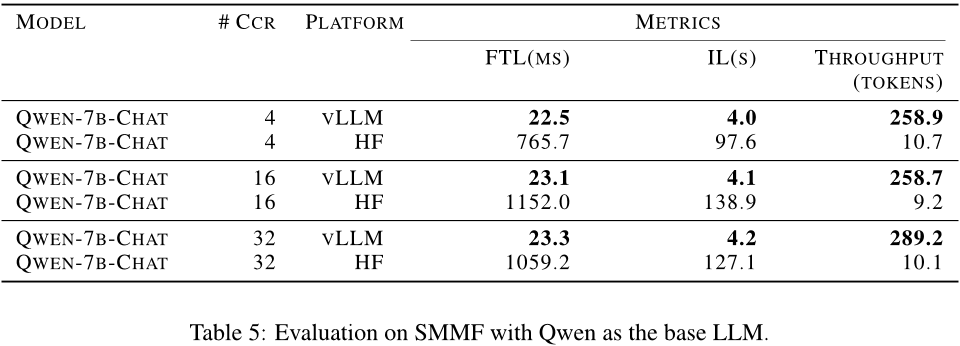
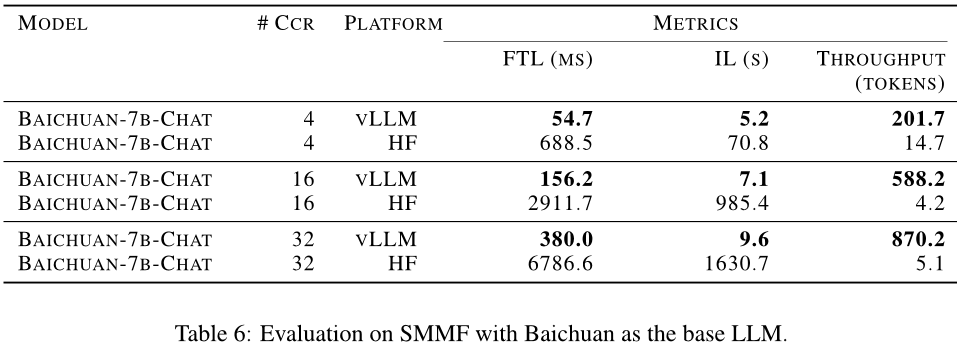
本文主要介绍了针对数据库相关任务的生成式模型DB-GPT系统进行了三个方面的实验,包括文本到SQL评价、RAG机制和SMMF效率性能等,并提供了相应的评估指标和实验结果。
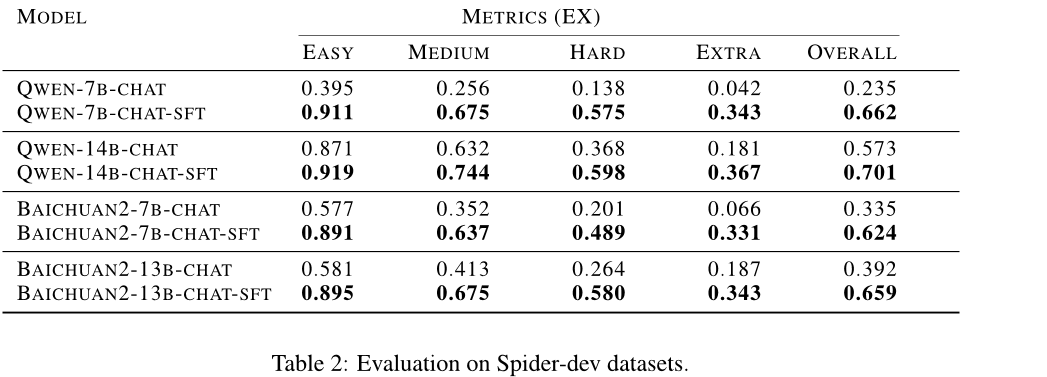
首先,在文本到SQL方面,作者使用了Spider数据集对DB-GPT系统的Fine-tuning效果进行了评估。实验结果显示,Fine-tuned版本相对于原始的预训练模型在执行准确率(EX)上有了显著的提升。
其次,在RAG机制方面,作者通过构建两个QA数据集(DatabaseQA和FinancialQA),并使用四个不同的基础语言模型(Qwen、Baichuan、ChatGLM-Turbo和ChatGPT3.5)进行实验。实验结果显示,不同数据集上的表现没有一致的优胜者,但用户可以根据自己的需求选择最适合的基础语言模型。
最后,在SMMF效率性能方面,作者采用了vLLM作为主推理框架,并对其进行了实验。实验结果显示,使用vLLM框架可以显著提高模型的吞吐量,同时减少首次解码时间和整体推理时间。随着并发用户的增加,利用vLLM框架进行推理所带来的性能改进更加明显。
综上所述,本文通过对DB-GPT系统在文本到SQL、RAG机制和SMMF效率性能等方面的实验,证明了其在这些任务中的有效性和实用性。
论文总结
文章优点
-
DB-GPT是一个智能且开放源代码的数据库对话系统,它能够解决各种任务,并在多个基准测试中表现出色。
-
DB-GPT采用了多种技术手段来提高其性能和效率,如知识构造、知识检索、文本到SQL微调等。
-
DB-GPT还具有隐私保护功能,可以在没有互联网连接的情况下运行,并通过代理去识别化技术保护用户数据的安全。
方法创新点
-
DB-GPT使用了多源知识库问答优化技术,将来自不同来源的数据整合成结构化的知识库,并通过适应性学习策略生成自然语言响应。
-
DB-GPT还采用了文本到SQL微调技术,提高了生成能力,并支持双语查询。
-
DB-GPT还集成了知识代理人和插件机制,使用户可以开发和应用先进的数据分析工具。
未来展望
-
DB-GPT为数据库操作提供了新的解决方案,但仍需要进一步改进以满足更广泛的实际需求。
-
可能需要更多的研究来探索如何更好地保护用户隐私,并防止未经授权的数据访问和利用。
-
进一步的研究还可以探索如何更好地将DB-GPT与其他技术和应用程序集成,以便实现更广泛的应用场景。