文章目录
- 1 normalization
- 1.1 batch normalization
- 1.1 motivation
- 2 layer normalizaiton
- 2.1 motivation
- 3、面试题
- 2 pooling
- 2.1 pooling的作用
- 2.2 Pooling 层如何进行反向传播和梯度更新?
- Max Pooling和 Average Pooling的区别,使用场景分别是什么?
本博客总结一下各种normalization
1 normalization
1.1 batch normalization
1.1 motivation
介绍normalization 之前先说一下,为什么需要normalization。
covariate shift问题:
每个隐藏层的输入的分布不一致,导致神经网络很难训练
计算方法:
每个batch 里面
batch:
原理:
https://www.cnblogs.com/skyfsm/p/8453498.html
计算细节:
https://blog.csdn.net/c2a2o2/article/details/83410273
why
从梯度的角度考虑,
缺点:
-
1、不适合RNN。序列长度不可知,但BZ需要某一层的所有输出。计算时很麻烦。
-
2、依赖mini batch大小,在大批量时候效果好,不适合在线学习。
2 layer normalizaiton
2.1 motivation
bn的缺点:
1、BN 需要依赖batch,在online learning这种场景不适用
2、不适用rnn,因为在rnn中,如果测试序列比train的序列大,这部分序列没办法用
一般搭配RNN使用?(why)
3、面试题
1 BN有什么缺陷
2 作者:蒋豆芽
链接:https://www.nowcoder.com/discuss/692404?source_id=discuss_experience_nctrack&channel=-1
来源:牛客网
3 除了BN,改激活函数还有什么解决梯度消失的么
-
预训练加微调
-
梯度剪切
使用合理的参数初始化方案,如He初始化
使用 ReLU、LReLU、ELU、maxout 等激活函数
sigmoid函数的梯度随着x的增大或减小和消失,而ReLU不会。
使用批规范化BN
残差结构
- 加了BN的sigmond还会不会梯度消失
有可能。
我们假设一种极端的情况。初始权重全为0。
2 pooling
- max pooling
- agv pooling
- min pooling
2.1 pooling的作用
降维
2.2 Pooling 层如何进行反向传播和梯度更新?
对于 max pooling 只对 max value 处进行梯度更新,其它都为 0;对于 average pooling 对之前的 pooling 位置处的所有元素做更新,更新值为 average pooling 层对应位置上的梯度除以采样个数(比如 2x2 pooling 则对应 4)
mean pooling
mean pooling 的前向传播就是把一个 patch 中的值求取平均来做 pooling,那么反向传播的过程也就是把某个元素的梯度等分为 n 份分配给前一层,这样就保证池化前后的梯度(残差)之和保持不变,还是比较理解的,图示如下 :
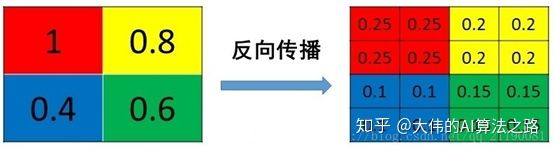
max pooling
max pooling 也要满足梯度之和不变的原则,max pooling 的前向传播是把 patch 中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为 0。所以 max pooling 操作和 mean pooling 操作不同点在于需要记录下池化操作时到底哪个像素的值是最大,也就是 max _id,这个变量就是记录最大值所在位置的,因为在反向传播中要用到,那么假设前向传播和反向传播的过程就如下图所示 :

————————————————
版权声明:本文为CSDN博主「烟雨人长安」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Matrix_cc/article/details/105485488
Max Pooling和 Average Pooling的区别,使用场景分别是什么?
https://blog.csdn.net/ytusdc/article/details/104415261
![[一本Java+一本Java]5月7日简历指导直播](https://img-blog.csdnimg.cn/img_convert/d0bda41a95bdc86930276bf92c843bf4.jpeg)