概念
一种用于提高数据库查询性能的有序的数据结构。通过使用索引,数据库引擎可以快速定位到存储表中的特定数据,而不必逐行遍历整个表。在处理大量数据的时候可以显著加快数据检索的速度。
通过索引列队数据进行排序,降低数据排序的成本,降低了cpu的消耗(索引列会自动对数据进行排序)
索引是在存储引擎中实现的,不同的存储引擎,索引的结构不同。
存储引擎是控制数据如何存、如何取、如何组织,而具体的数据最终是存储在磁盘中的。
存储引擎是存储数据,建立索引,更新数据/查询数据的实现方式。存储引擎是基于表的,不是基于库的。换句话说一个数据库下可以有多个存储引擎。
B+树和B树的结点:
B+树非叶子节点只存储key,不存储值,直到叶子节点才存储值,非叶子节点主要起到索引作用,叶子节点包含了所有插入的元素。
B树每个结点即存值又存key,导致每个结点存储的key的个数少,进而导致树的层数很深。
索引是帮助MySQL高效获取数据的 数据结构(有序)。
提高查询效率,提高排序效率,但是索引也占用空间,虽然能提高查询效率,但是降低了更新表的速度,因为在更新的时候也要维护索引。所以说不是索引越多越好!!
InnoDB为什么使用B+树,而不是Hash等其他的索引结构?
①不用二叉树,因为如果是顺序存储,则层级会特别深,链表。
②不用B树,因为:对于同一个页单位【页单位大小固定】,如果又存放Key又存放指针,那么存放的指针会很少,导致数值数量一样的情况下,B树会比B+树更深,查询的更慢,而B+树因为在非叶子结点中的页单位里,只存放指针,那么一个页单位可以存放很多个指针(相对B树),那么B+树的层级就会低,查询效率提高。
③不用Hash,因为Hash索引只能做到精确查找,不能进行范围查找,同时Hash不能对数据进行排序操作。
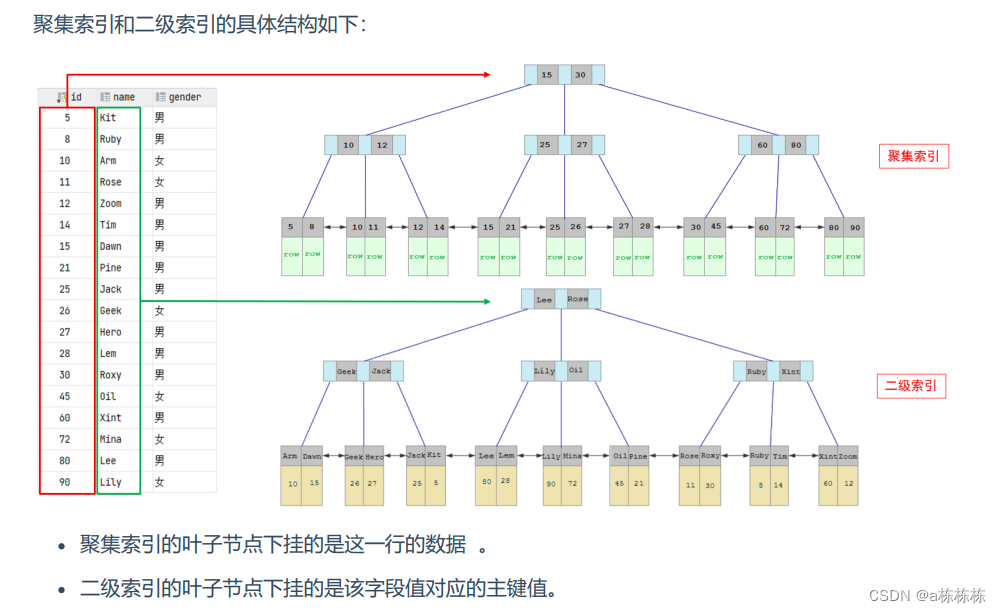
聚集索引和二级索引
在InnoDB存储引擎中,根据索引的存储形式,分为聚集索引(指针)和二级索引(二级指针)
索引结构中,叶子结点存放的是整行的行数据。必须有,且只有一个。
索引结构中,叶子结点存放的是对应的主键。可以有多个。除了聚集索引以外的索引都是二级索引
聚集索引选取规则
如果存在主键,主键就是聚集索引。
如果没有设置主键,默认第一个唯一索引就是聚集索引。
如果又没有主键,又没有唯一索引,那么InnoDB会自动生成一个rowid作为隐藏的聚集索引。
对于叶子节点:聚集索引存放的是一行的全部信息,而二级索引存放的是主键值(然后通过主键值,再回表)
 回表查询
回表查询
:先查二级索引,得到主键值,再拿该主键值去查聚集索引。【先介绍下聚集索引和二级索引】
前缀索引
create index idx_xxxx on table_name(column(n)) ;
对于行文本,字符串类型,通过取前n位,作为区分
联合索引
一个索引涉及到多个列,查询条件涉及多个列,意义就是减少回表查询,覆盖索引,提高查询效率。
覆盖索引
:查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到。如select id,name from a where name = jack ,因为name是二级索引,通过该索引查到了id,也就是主键值,不需要回表查询,所以叫做覆盖索引,因此尽量不要使用select *。
索引失效的场景
用到复合(联合)索引的时候,违反最左前缀法则【查询的时候必须从索引的最左列开始,如果跳过了中间某一列,则跳过之后的索引都失效】
当查询条件有范围查询的时候,其右边的条件,如where id > 1 and xxx 【and后面的索引都会失效】
在索引列上进行运算操作
隐式类型转换(如表中数据是字符串类型,而你给他一个int类型,即不加单引号)
以%开头的模糊查询
索引设计原则
①数据量大,且查询比较频繁的表建立索引,如果一个表全是增删改,就没必要了
②常作为查询条件where、order by、group by操作的字段建立索引,如果一次查询条件的字段为多个,也可以考虑设置联合索引,但记住它们的顺序不能改变,要遵守最左配对原则
③选择区分度高的列作为索引,像性别男女就没必要。
④如果是字符串类型的字段,且长度较长,可以针对字段的特点,建立前缀索引。
⑤尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,避免回表,提高查询效率。
⑥控制索引的数量,索引越多,维护索引结构的代价也越大,会影响增删改的效率