目录
Set-Cookie
引入
介绍
原理
描述
图解
内存级
文件级
示例
实现
介绍
代码
核心代码
全部代码
示例
介绍
存在的必要性
如何解决
问题梳理
引入
会话机制 -- 解决信息泄漏问题
介绍
用途
Set-Cookie
引入
http协议默认是无状态的,每一次的请求都是独立事件
但是,我们回想一下:
- 当我们登录某个网站后,他就像记住了我们的用户信息一样,无论访问它的哪个页面,我们都是已经登录的状态
- 即使我们关闭网页/电脑,重新打开,依然是已登录的状态
- 但这似乎和http协议的无状态特性冲突了,服务器怎么能记住我们的用户信息的呢?
其实靠的就是set-cookie字段
- 它可以帮助实现http对登录用户的会话保持功能
介绍
是http协议中报头字段的一部分,用于在Web服务器和客户端之间传输HTTP cookie信息
- 它里面可以设置一些属性值
- 用;隔开多个属性


原理
描述
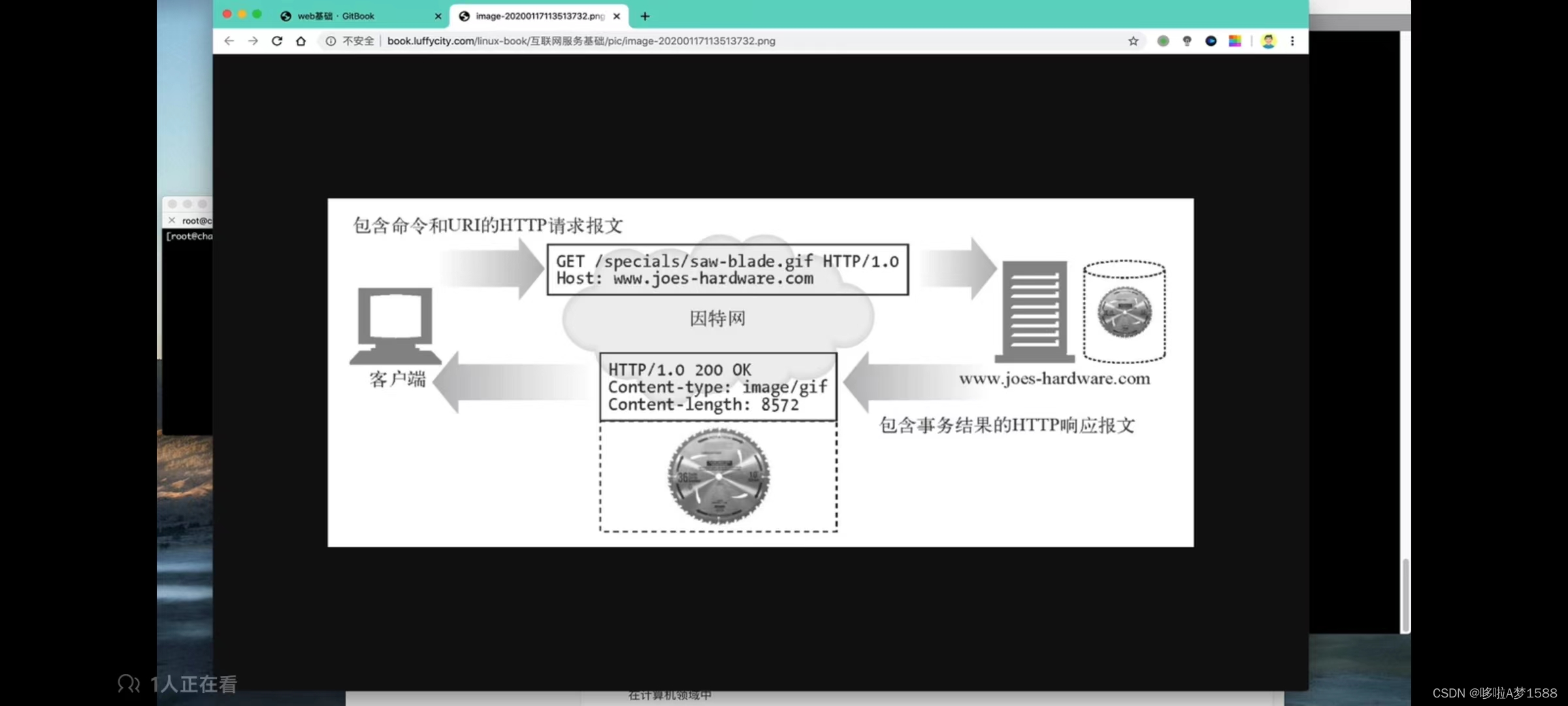
当我们登录某网站时
- 会将[输入的账号密码等数据]随着请求发过去(有get(url中) / post(正文中)方法)
然后服务器收到请求
- 将请求解析,提取出用户信息
- 完成用户认证后,会将其重定向至首页(因为此时客户端处于服务器的登录页面)
- 然后将输入的数据填充到set-cookie字段里,发回给客户端
当浏览器收到服务器发回的响应
- 浏览器会在它内部的cookie文件中保存字段里的数据
- (set-cookie相当于是命令客户端让它把这个字段携带的数据写入到cookie里)
这样当浏览器再次访问相同的服务器时
- 浏览器会自动帮我们将cookie文件中的数据填充到请求里
- 然后在服务器里自动进行用户认证,这样就不需要用户手动输入了
而如果请求里没有携带cookie信息
- 则会跳转到登录页面让你登录
- 然后就是重复上述操作
图解
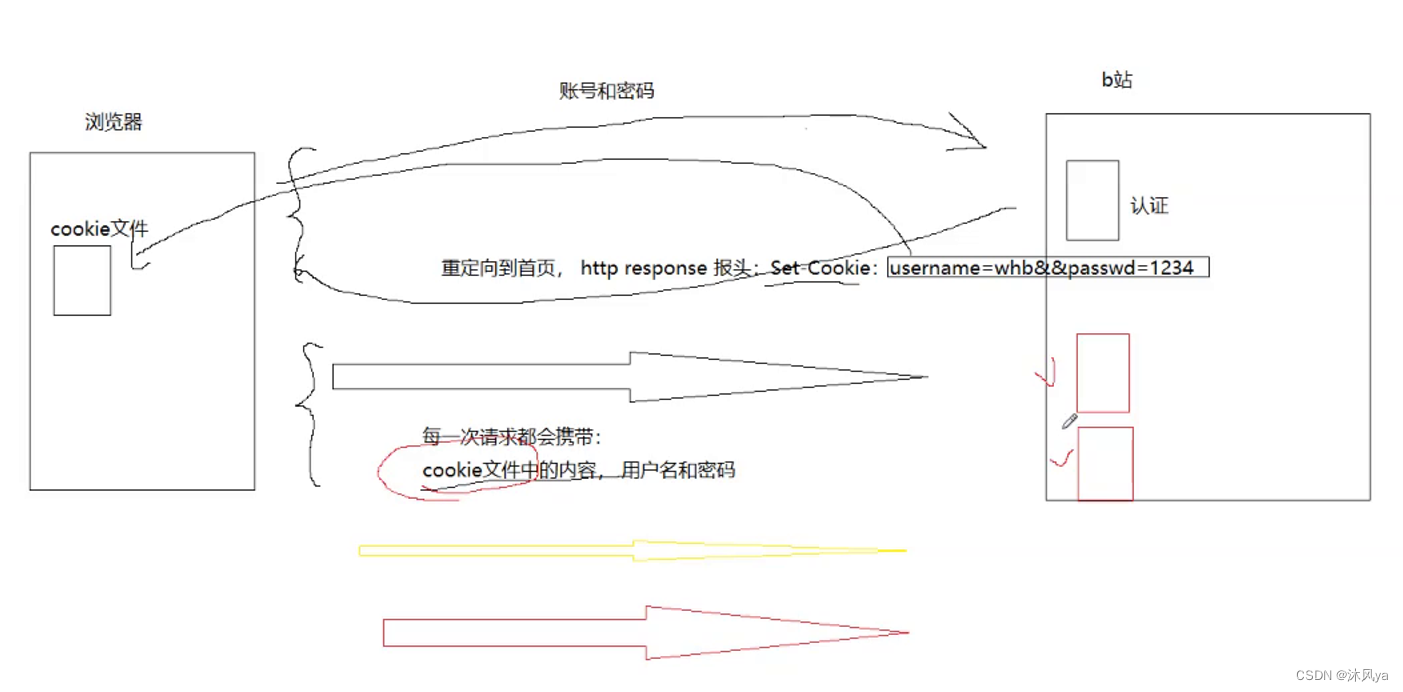
保存"cookie文件"的方法
虽然说是文件,但也不一定以文件的方式存放数据
内存级
为什么可以是内存?
- 因为浏览器也是一个进程,是进程就可以进行内存空间的分配(new / malloc)
- 在Web开发中,有时需要在客户端会话期间在内存中存储cookie,而不是持久化到硬盘上
- 当用户关闭浏览器时就会被删除
文件级
将数据往磁盘中写
- 即使把浏览器关闭,cookie文件里的数据依然存在
- 下次启动浏览器后依然可以使用(也就是之前登录过的网站不需要重新登陆)
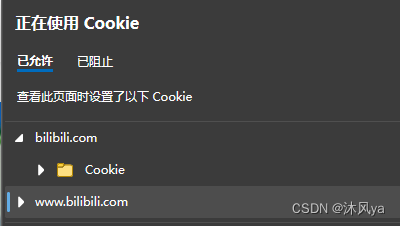
查看cookie文件
我们可以从左上角的图标那里点击查看正在使用的cookie文件

示例
b站此时已经缓存了我的用户信息
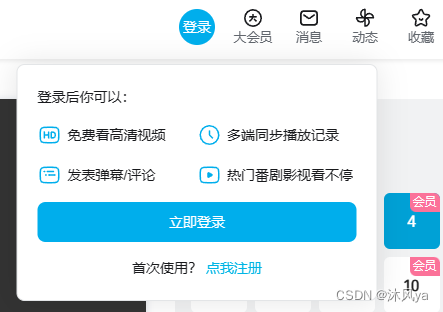
如果我们把这个文件删除,并刷新页面,就会看到登录提示:
而且,每个cookie文件都是有到期时间的,时间到了,就会自动删除

实现
介绍
我们这里使用post方式提交输入数据
- 所以需要在有请求正文的情况下,再填充set-cookie字段
- 总之就是处理字符串
代码
核心代码
void handle_response(response &res, request &req){int code = req.code_;std::string path = req.path_;std::string content_type_data = content_type_[req.suffix_];// lg(DEBUG, "content_type_data: %s", content_type_data.c_str());res.version_ = "HTTP/1.1";if (code == 302){res.code_ = 302;res.desc_ = "Found";std::string cl = "Location: ";cl += "https://www.qq.com";(res.title_).push_back(cl);return;}if (code == 404){res.code_ = 404;res.desc_ = "Not Found";}else{res.code_ = 200;res.desc_ = "OK";}// 将读取网页和图片资源的方式分开if (req.suffix_ == ".html"){res.text_ = get_page(path);// lg(DEBUG, "text: %s", (res.text_).c_str());}else{res.text_ = b_get_page(path);}// 构建响应报头std::string cl = "Content-Length: ";cl += std::to_string((res.text_).size());// lg(DEBUG, "text_size: %d", (res.text_).size());(res.title_).push_back(cl);cl = "Content-Type: ";cl += content_type_data;(res.title_).push_back(cl);// 增加cookieif (!(req.text_).empty()){// lg(DEBUG, "TEXT: %s", req.text_.c_str());size_t left = 0, right = 0;while (true) // 把请求的正文部分的内容读出来{cl = "Set-Cookie: ";right = (req.text_).find("&", left);if (right == std::string::npos){//最后一个字段是submit,我这里就不把它保存到cookie里了break;}cl += (req.text_).substr(left, right - left);left = right + 1;(res.title_).push_back(cl);}}}全部代码
#pragma once#include <signal.h> #include <unistd.h> #include <cstring> #include <functional> #include <pthread.h> #include <unordered_map>#include "socket.hpp" #include "Serialization.hpp"static MY_SOCKET my_socket;#define buff_size 1024 * 30class http_server; struct thread_data {int sockfd_;std::string ip_;std::string &in_buffer_;http_server *this_; };class http_server { public:http_server(const uint16_t port, const std::string &ip = "0.0.0.0"): port_(port), ip_(ip){content_type_[".html"] = "text/html";content_type_[".png"] = "image/png";content_type_[".jpg"] = "image/jpeg";content_type_[".jpeg"] = "image/jpeg";}~http_server() {}void run(){init();while (true){uint16_t client_port;std::string client_ip;// 一个线程处理一次请求(短连接)pthread_t pid;std::string in_buffer;int sockfd = 0;int count = 5;do{lg(DEBUG, "accepting ...");sockfd = my_socket.Accept(client_ip, client_port);if (sockfd != -1 || --count == 0){break;}} while (true);if (sockfd == -1){lg(ERROR, "accepting error");}lg(INFO, "get a new link..., sockfd: %d, client ip: %s, client port: %d", sockfd, client_ip.c_str(), client_port);thread_data *td = new thread_data{sockfd, client_ip, in_buffer, this};lg(DEBUG, "create pthread");pthread_create(&pid, nullptr, entry, reinterpret_cast<void *>(td));// 一个进程服务一个客户端// lg(DEBUG, "accepting ...");// int sockfd = my_socket.Accept(client_ip, client_port);// if (sockfd == -1)// {// continue;// }// lg(INFO, "get a new link..., sockfd: %d, client ip: %s, client port: %d", sockfd, client_ip.c_str(), client_port);// int ret = fork();// if (ret == 0)// {// my_socket.Close();// char buffer[buff_size];// std::string in_buffer;// while (true)// {// memset(buffer, 0, sizeof(buffer));// int n = read(sockfd, buffer, sizeof(buffer)); //"size"\n"a op b"\n// if (n > 0)// {// buffer[n] = 0;// in_buffer += buffer; // 连续读取// lg(INFO, "get request: \n%s", in_buffer.c_str());// // 构建请求// request req;// req.deserialize(in_buffer);// // lg(DEBUG, "path: %s ,url: %s ", (req.path_).c_str(), (req.url_).c_str());// // 构建响应// response res;// handle_response(res, req);// // 响应序列化// std::string content;// res.serialize(content);// write(sockfd, content.c_str(), content.size());// }// else if (n == 0)// {// lg(INFO, "%s quit", client_ip.c_str());// break;// }// else // 读出错误// {// break;// }// }// exit(0);// close(sockfd);// }}}private:void init(){signal(SIGPIPE, SIG_IGN);signal(SIGCHLD, SIG_IGN);my_socket.Socket();my_socket.Bind(port_);my_socket.Listen();lg(INFO, "server init done");}void handle_response(response &res, request &req){int code = req.code_;std::string path = req.path_;std::string content_type_data = content_type_[req.suffix_];// lg(DEBUG, "content_type_data: %s", content_type_data.c_str());res.version_ = "HTTP/1.1";if (code == 302){res.code_ = 302;res.desc_ = "Found";std::string cl = "Location: ";cl += "https://www.qq.com";(res.title_).push_back(cl);return;}if (code == 404){res.code_ = 404;res.desc_ = "Not Found";}else{res.code_ = 200;res.desc_ = "OK";}// 将读取网页和图片资源的方式分开if (req.suffix_ == ".html"){res.text_ = get_page(path);// lg(DEBUG, "text: %s", (res.text_).c_str());}else{res.text_ = b_get_page(path);}// 构建响应报头std::string cl = "Content-Length: ";cl += std::to_string((res.text_).size());// lg(DEBUG, "text_size: %d", (res.text_).size());(res.title_).push_back(cl);cl = "Content-Type: ";cl += content_type_data;(res.title_).push_back(cl);// 增加cookieif (!(req.text_).empty()){// lg(DEBUG, "TEXT: %s", req.text_.c_str());size_t left = 0, right = 0;while (true) // 把请求的正文部分的内容读出来{cl = "Set-Cookie: ";right = (req.text_).find("&", left);if (right == std::string::npos){//最后一个字段是submit,我这里就不把它保存到cookie里了break;}cl += (req.text_).substr(left, right - left);left = right + 1;(res.title_).push_back(cl);}}}static void *entry(void *args){pthread_detach(pthread_self());thread_data *td = reinterpret_cast<thread_data *>(args);int sockfd = td->sockfd_;std::string ip = td->ip_;std::string in_buffer = td->in_buffer_;http_server *it = td->this_;// 读取请求char buffer[buff_size];bool flag = true;request req;while (true) // 虽说是短连接,但也得确保读出来的内容是一个完整的请求{memset(buffer, 0, sizeof(buffer));int n = read(sockfd, buffer, sizeof(buffer));if (n > 0){buffer[n] = 0;in_buffer += buffer; // 连续读取lg(INFO, "get request: \n%s", in_buffer.c_str());// 构建请求flag = req.deserialize(in_buffer);if (flag == false){continue;}else{break;}}else if (n == 0){lg(INFO, "%s quit", ip.c_str());return nullptr;}else{lg(ERROR, "%s read error", ip.c_str());return nullptr;}}// lg(DEBUG, "path: %s ,url: %s ", (req.path_).c_str(), (req.url_).c_str());// 构建响应response res;it->handle_response(res, req);// 响应序列化std::string content;res.serialize(content);write(sockfd, content.c_str(), content.size());// 销毁资源delete td;close(sockfd);return nullptr;}private:uint16_t port_;std::string ip_;std::unordered_map<std::string, std::string> content_type_; };
更多代码介绍在 -- 基于http协议的服务端代码(简易版,动态编码网页版),user-agent介绍+爬虫/反爬虫原理,web根目录解释,html的基本格式介绍,输入格式介绍(form,input,不同提交方式的区别)-CSDN博客 基于http协议的服务器代码编写(可以访问指定路径的资源版+添加跳转网页功能+临时重定向+加载图片的原理/方法+多线程版),http请求/响应的序列化/反序列化,href介绍-CSDN博客
示例
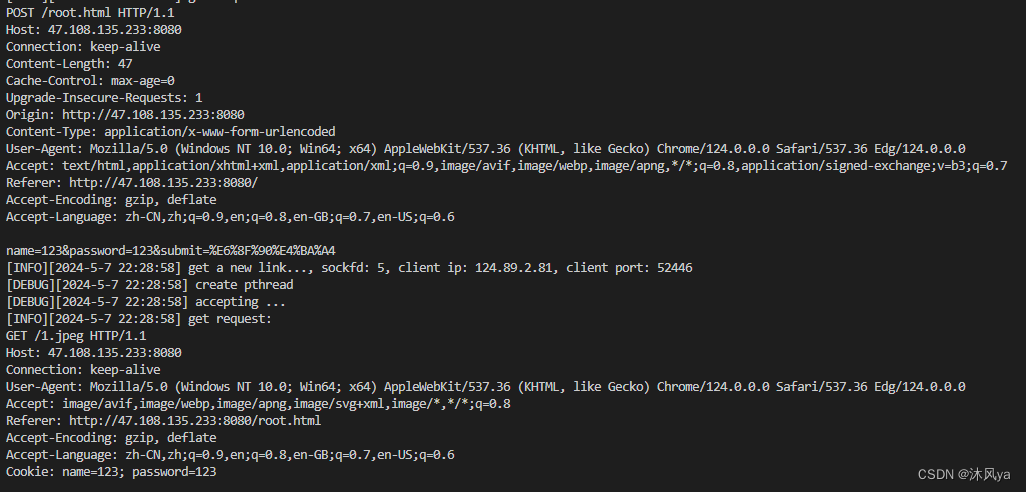
这是我们输入名字和密码后的请求和响应的内容:
- 可以看到,set-cookie字段被正确填充
这是我们之后的请求,会看到请求里自动带上了cookie字段:
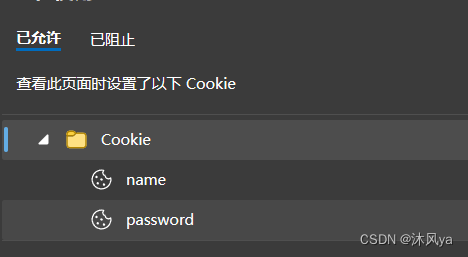
查看cookie文件,也是成功创建出来了:

cookie存在的问题
介绍
如果电脑被别人中了病毒,读取了我们电脑上的cookie文件
- 这样他们那边就可以用着我们的用户数据,来登录我们登陆过的网站
这也就是qq盗号的原理
- 我们应该都见到过,自己的qq有被异地登录啥的
那这说明cookie文件很容易丢失啊
- 而且一旦丢失,都是最敏感的用户信息
存在的必要性
所以,既然这么容易丢,为什么cookie文件还会存在呢?
- 是因为,如果没有cookie文件的话,用户每一次访问某个网页,都需要验证用户信息
- 相当于一步一验证,那可太太太麻烦了
- 所以就需要它来辅助实现会话保持功能
- 所以,cookie的存在是必要的
如何解决
那如何解决它存在的问题呢?
问题梳理
我们先将它存在的问题梳理出来:
- 容易被盗取
- 导致个人私有信息泄漏
引入
其实,客户端的防范能力基本为0
- 所以,我们直接把私密信息放在客户端(也就是浏览器的cookie文件里),本身就是不合理的
所以,我们来重新回顾一下整个设置cookie的过程:
- 当用户输入登录信息后,服务器会收到这些数据进行身份认证
- 此时,如果不做修改的话,就直接将私密数据发送给客户端让它保存到cookie里了
- 我们在这里引入一个新的机制 -- session(会话)机制
会话机制 -- 解决信息泄漏问题
介绍
服务器端会维护一些数据结构,这里成为session
- 它里面会存放用户的各种信息
- 并且拥有唯一标识符session id(由服务器分配和管理)
这样的话,服务器返回给客户端的就可以是session的唯一标识符
- 那么在客户端之后的请求中,会自动带上session id,然后发给服务器
- 服务器在session集群(服务器会以某种结构管理多个session的(因为session肯定不止一个,一个用户对应一个session))中寻找是否存在这个id
- 找到则认证成功

用途
这样也能实现我们的会话保持功能,而且还不会泄漏隐私
- 虽然依然可以拿走cookie里的数据,然后冒充我们访问服务器
- 但拿走的并不是我们的隐私信息,只是一个id
- 因为隐私信息被留在了服务器内部,而没有发回给客户端保存
- 而服务器是有防护能力的,所以黑客很难攻破服务器盗取数据
那么,个人信息泄露的问题就解决了,cookie文件容易被盗取的问题该怎么办呢?
解决cookie被盗取
其实,cookie文件被盗取是无法绝对避免的
- 所以他还是可能会以某种方式拿走session id
- 虽然隐私信息他访问不到,但还是可以冒充我们登录服务器
如何解决呢?
- 还是要从服务器入手,因为黑客拿到的session id是由服务器管理的,可以分配,自然可以回收
- 如果服务器检测到ip地址异常(比如ip地区突然从一个地区->另一个地区,这肯定不可能嘛),就将它对应的session文件设置为暂停状态,并且让用户重新输入登录信息
- 如果验证失败,说明有被盗取的可能,于是把这个session直接删除
所以,即使我们无法彻底解决冒充用户的问题,但也可以通过其他手段尽可能地降低风险