目录
- 数据仓库是什么
- 数据仓库和数据库的区别
- 为什么要对数据仓库分层
- 数仓分层,以及每一层的作用
- 维度建模的三种模型
- 范式建模、维度建模
- 维度建模过程,如何确定这些维度 ***
- 维度模型的各个维度之间是怎么聚合的
- 聚合过程的数据倾斜怎么解决?
- 数据质量是怎么保证的,有哪些方法保证
- 数据治理
- 传统数仓和大数据数仓的区别 ***
- 数据湖
- 数据湖、数据仓库之间的区别
- 电商业务常见的数据域
数据仓库是什么
数据仓库是一个面向主题的、集成的、相对稳定的,反映历史变化的数据集合,主要用于存储历史数据,然后通过分析整理进而提供数据支持和辅助决策。
数据仓库和数据库的区别
(1)数据库中主要存放的是一些在线的数据,数据仓库中主要存放的是历史数据,并且存放的数据要比数据库多;
(2)数据库主要用于业务处理(比如交易系统),数据仓库主要用于数据分析;
(3)数据库的设计就是要避免冗余,而数据仓库通常会专门引入冗余,减少后面进行分析时大量的 join 操作。
在数据仓库中,冗余指的是相同的数据在多个表中重复存储。比如预聚合数据,为了提高查询性能,数据仓库可能会事先计算并存储聚合数据。
为什么要对数据仓库分层
(1)将复杂问题简单化:将复杂的问题分解为多层来完成,每一层只处理简单的任务,方便定位问题;
(2)提高数据的复用性:比如在已经得到最终结果之后,又需要中间层的一些数据,可以直接查询中间层的数据,不必重新进行计算。
(3)隔离原始数据:将真实数据与统计数据解耦开。
补充说一下:我觉得数据仓库就是一种以空间换取时间的架构!
数仓分层,以及每一层的作用
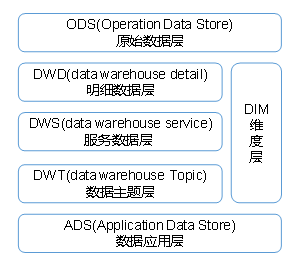
(1)ODS 原始数据层:存放原始数据,直接加载原始日志,数据,数据保持原貌不做处理。
DIM层,维度层,保存维度数据,主要是对业务事实的描述信息,例如何人,何时,何地等
(2)DWD 数据明细层:对 ODS 层数据进行清洗(去除空值,脏数据,超过极限范围的数据)、脱敏等,保存业务事实明细,一行信息代表一次业务行为,例如一次下单。
(3)DWS 数据服务层:对 DWD 层数据按天进行一个轻度的汇总。一行信息代表一个主题对象一天的汇总行为,例如一个用户一天下单次数。
(4)DWT 数据主题层:对 DWS 层数据进行累积汇总。一行信息代表一个主题对象的累积行为,例如一个用户从注册那天开始至今一共下了多少次单。
(5)ADS 数据应用层:面向实际的数据需求,为各种统计报表提供数据。
维度建模的三种模型

范式建模、维度建模
范式建模:较为松散、零碎,物理表数量多。严格遵循第三范式(3NF),数据冗余程度低,数据的一致性容易得到保证。但由于数据分布于众多的表中,查询会相对复杂,在大数据的场景下,查询效率相对较低。
维度建模:维度模型以数据分析作为出发点,不遵循三范式,故数据存在一定的冗余。维度模型面向业务,将业务用事实表和维度表呈现出来。表结构简单,故查询简单,查询效率较高。
维度建模过程,如何确定这些维度 ***
维度建模一般按照以下四个步骤:
选择业务过程→声明粒度→确认维度→确认事实
(1)选择业务过程
在业务系统中,挑选我们感兴趣的业务线,比如下单业务,支付业务,退款业务,物流业务,一条业务线对应一张事实表。
(2)声明粒度
数据粒度指数据仓库的数据中保存数据的细化程度或综合程度的级别。
声明粒度意味着精确定义事实表中的一行数据表示什么,应该尽可能选择最小粒度,以此来应各种各样的需求。
(3)确定维度
确认维度是指确定与事实表中的每个记录相关联的维度。维度是描述事实表中每个记录所描述的事件或过程的属性。
对于订单来说,常见的维度会包含商品、日期、买家、卖家、门店等而每一个维度还可以包含大量的描述信息,比如商品维度表会包含商品名称、标签价、商品品牌、商品类目、商品上线时间等。
(4)确定事实
确认事实是指确定与每个维度相关联的事实。事实是指与每个维度相关联的数值或量度。
维度模型的各个维度之间是怎么聚合的
在维度模型中,不同的维度之间可以通过聚合来建立关联。聚合是指将数据按照某个维度进行汇总,并计算相应的聚合指标,比如总计、平均值、最大值等等。不同维度之间可以通过共同的聚合指标建立联系。
举个例子,假设有一个销售数据的维度模型,其中包含了时间、地点、产品等多个维度。如果想要了解某一地区某一时间段内的产品销售情况,就可以按照时间和地点这两个维度进行聚合,计算出该地区该时间段内每种产品的销售总量、平均销售额等指标。
在维度模型中,常用的聚合方式包括:group by、sum、avg、min、max等等。聚合可以在ETL过程中进行,也可以在BI工具中进行。聚合可以帮助我们更好地理解数据,并发现数据之间的关联和趋势,从而更好地支持决策。
聚合过程的数据倾斜怎么解决?
解决方案:两阶段聚合(局部聚合+全局聚合)
实现原理:在需要聚合的key前加一个随机数的前后缀,这样就能得到非常均匀的key,然后按这个加工之后的key进行第一次聚合之后,接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。
具体原理见下图先将相同key的数据分拆处理,最后进行全局聚合

数据质量是怎么保证的,有哪些方法保证
1)从技术层面来说,需要构建一套高效、健壮的ETL程序,以此保证数据清洗、转换后数据的正确性和一致性。
2)从流程上来说,整个ETL是多个任务,按步骤顺序执行的一个过程,后置任务依赖前置任务,定期执行,整个流程需要自动化,并且哪个环节出现了问题,给予预警,通知相关维护人员及时处理。
3)从管理层面上来说,数据仓库是构建在公司各个业务系统之上,它是一面镜子,很多时候它能反映出业务系统的问题,所以需要管理层的支持和约束,比如通过第一条说的事后自动检验机制反映出业务系统的维护错误,需要相应的业务系统维护人员及时处理。
数据治理
数据治理是指对杂乱、无规范数据的治理,目的就是为了让数据有序,就像是秦始皇统一度量衡一样,“车同轨,书同文“就是最早的一项数据治理工作。数据治理(Data Governance)是组织中涉及数据使用的一整套管理行为。数据治理体系是为了规范业务数据规范、数据标准、数据质量和数据安全中的各类管理任务活动而建立的组织、流程与工具。
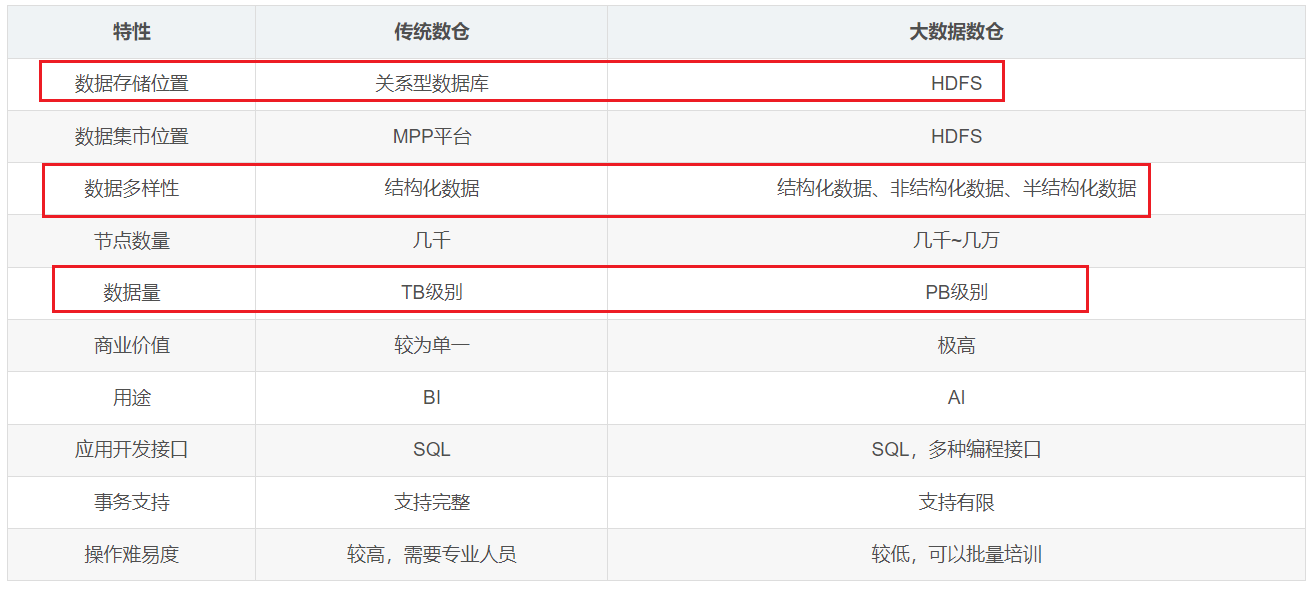
传统数仓和大数据数仓的区别 ***
数据湖
数据湖是一个集中存储各类结构化和非结构化数据的大型数据仓库,它可以存储来自多个数据源、多种数据类型的原始数据,数据无需经过结构化处理,就可以进行存取、处理、分析和传输。数据湖能帮助企业快速完成异构数据源的联邦分析、挖掘和探索数据价值。
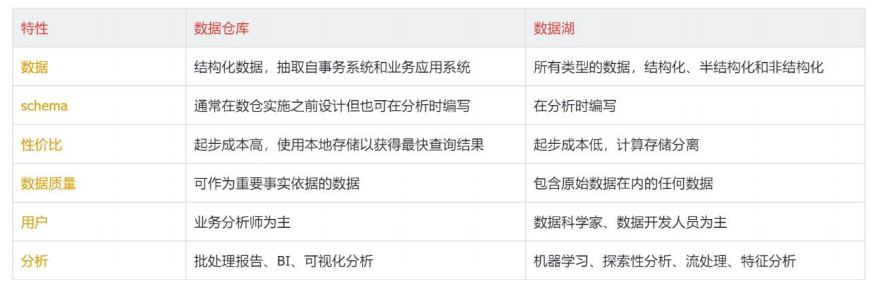
数据湖、数据仓库之间的区别
电商业务常见的数据域
数据域:将业务过程或者维度进行抽象的集合,例如交易域、商品域等都是数据域。
商品数据域:
- 商品信息:包括商品名称、描述、价格、库存、品牌、分类等。
- 商品图片:商品的图片信息,可能包括多个角度的图片、缩略图等。
- 商品属性:商品的各种属性信息,如颜色、尺寸、重量、材质等。
- 商品评论:用户对商品的评价、评分、评论内容等。
订单数据域:
- 订单信息:包括订单号、下单时间、支付方式、订单状态等。
- 订单详情:订单中每个商品的购买数量、价格、总金额等。
- 收货信息:用户的收货地址、联系方式等。
- 物流信息:订单的物流状态、快递公司、运费等。
用户数据域:
- 用户信息:包括用户ID、用户名、手机号码、邮箱、注册时间等。
- 用户行为:用户的浏览记录、搜索记录、点击记录、购买记录等。
- 用户偏好:用户的兴趣标签、关注的品类、购买习惯等。
- 用户反馈:用户对服务、商品的评价、投诉、建议等。