摘要:
如果需要深入理解GRU的话,内部实现的详细代码和计算公式就比较重要,中间的一些过程及中间变量的意义需要详细关注。只有这样,才能准备把握这个模块的内涵和意义,设计初衷和使用方式等等。所以,仔细研究这个模块的实现还是非常有必要的。以此类推,对于其他的模块同样如此,只有把各个经典的模块内部原理、实现和计算调用都搞清楚了,才能更好的去设计和利用神经网络,建立内在的直觉和能力。
本文中介绍GRU内部的代码实现与数学表达式一致,在实际使用中,一般是通过调用API来实现,即语句:self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout),只需要设定相应的参数即可,免除了重新实现的繁琐,并且类似于pytorch框架中的API还做了计算上的优化,使用起来高效方便。
先从输入输出的角度看,即代码中的这一行:output, state = self.rnn(X) 。在 GRU(Gated Recurrent Unit)中,output 和 state 都是由 GRU 层的循环计算产生的,它们之间有直接的关系。state 实际上是 output 中最后一个时间步的隐藏状态。
代码示例
class Seq2SeqEncoder(d2l.Encoder):
"""⽤于序列到序列学习的循环神经⽹络编码器"""def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):super(Seq2SeqEncoder, self).__init__(**kwargs)# 嵌⼊层self.embedding = nn.Embedding(vocab_size, embed_size)self.rnn = nn.GRU(embed_size, num_hiddens, num_layers,dropout=dropout)def forward(self, X, *args):# 输出'X'的形状:(batch_size,num_steps,embed_size)X = self.embedding(X)# 在循环神经⽹络模型中,第⼀个轴对应于时间步X = X.permute(1, 0, 2)# 如果未提及状态,则默认为0output, state = self.rnn(X)# output的形状:(num_steps,batch_size,num_hiddens)# state的形状:(num_layers,batch_size,num_hiddens)return output, stateoutput:在完成所有时间步后,最后⼀层的隐状态的输出output是⼀个张量(output由编码器的循环层返回),其形状为(时间步数,批量⼤⼩,隐藏单元数)。
state:最后⼀个时间步的多层隐状态是state的形状是(隐藏层的数量,批量⼤⼩, 隐藏单元的数量)。
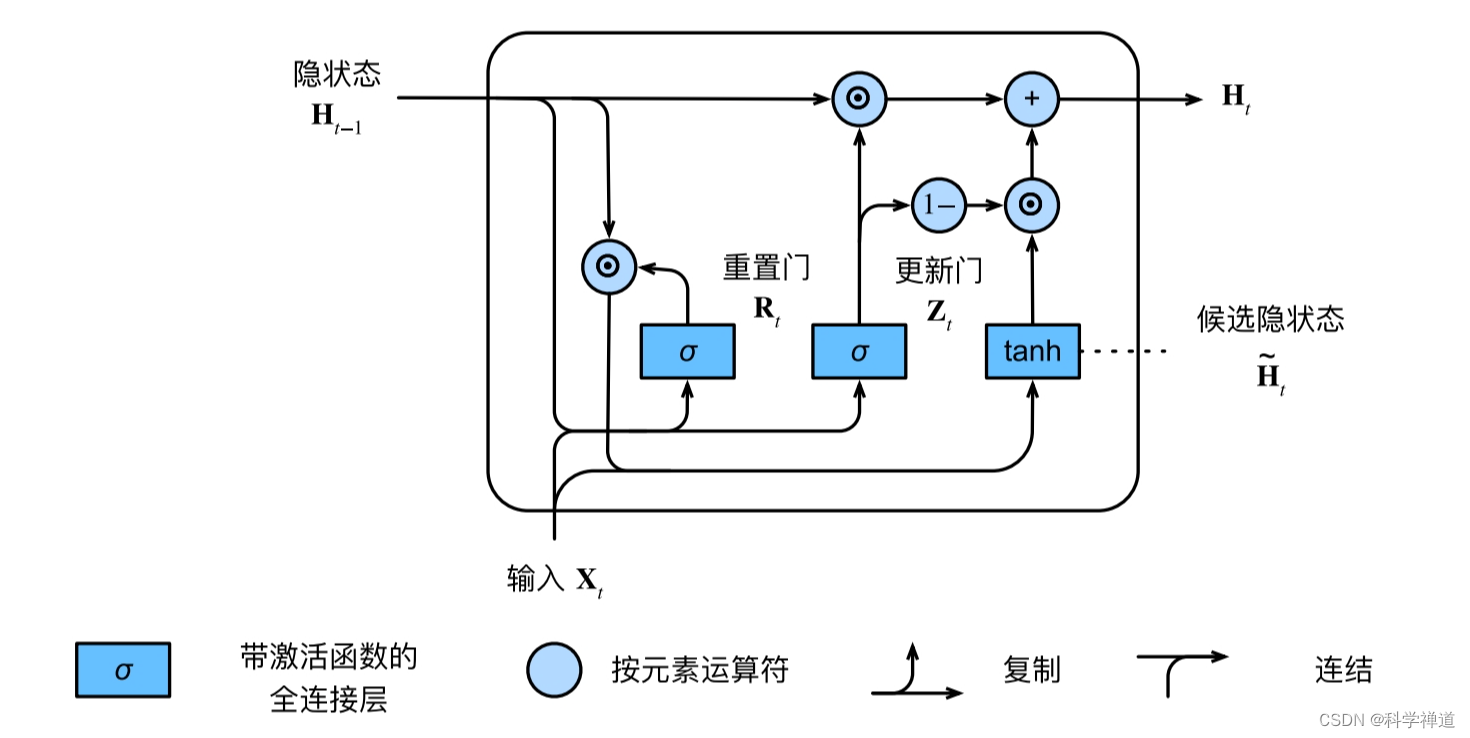
GRU模块的框图
GRU 的基本公式
GRU 的核心计算包括更新门(update gate)和重置门(reset gate),以及候选隐藏状态(candidate hidden state)。数学表达式如下:
-
更新门 \( z_t \): \[ z_t = \sigma(W_z \cdot h_{t-1} + U_z \cdot x_t) \]
其中,\( \sigma \) 是sigmoid 函数,\( W_z \) 和 \( U_z \) 分别是对应于隐藏状态和输入的权重矩阵,\( h_{t-1} \) 是上一个时间步的隐藏状态,\( x_t \) 是当前时间步的输入。 -
重置门 \( r_t \):
\[ r_t = \sigma(W_r \cdot h_{t-1} + U_r \cdot x_t) \]
\( W_r \) 和 \( U_r \) 是更新门中定义的相似权重矩阵。 -
候选隐藏状态 \( \tilde{h}_t \):
\[ \tilde{h}_t = \tanh(W \cdot r_t \odot h_{t-1} + U \cdot x_t) \]
这里,\( \tanh \) 是激活函数,\( \odot \) 表示元素乘法(Hadamard product),\( W \) 和 \( U \) 是隐藏状态的权重矩阵。 -
最终隐藏状态 \( h_t \):
\[ h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t \]
output 和 state 的关系
-
output:在 GRU 中,output 包含了序列中每个时间步的隐藏状态。具体来说,对于每个时间步 \( t \),output 的第 \( t \) 个元素就是该时间步的隐藏状态 \( h_t \)。 -
state:state 是 GRU 层最后一层的隐藏状态,也就是 output 中最后一个时间步的隐藏状态 \( h_{T-1} \),其中 \( T \) 是序列的长度。
数学表达式
如果我们用 \( O \) 表示 output,\( S \) 表示 state,\( T \) 表示时间步的总数,那么:
\[ O = [h_0, h_1, ..., h_{T-1}] \]
\[ S = h_{T-1} \]
因此,state 实际上是 output 中最后一个元素,即 \( S = O[T-1] \)。
在 PyTorch 中,output 和 state 都是由 GRU 层的 `forward` 方法计算得到的。`output` 是一个三维张量,包含了序列中每个时间步的隐藏状态,而 `state` 是一个二维张量,仅包含最后一个时间步的隐藏状态。
GRU的内部实现
上面一节的代码示例,是通过调用API实现的,即self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)。那么,GRU内部是如何实现的呢?
分为模型、模型参数初始化和隐状态初始化三个部分:
模型定义(模型定义与数学表示式一致,也可以参考上图):
def gru(inputs, state, params):W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = paramsH, = stateoutputs = []for X in inputs:Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)H = Z * H + (1 - Z) * H_tildaY = H @ W_hq + b_qoutputs.append(Y)return torch.cat(outputs, dim=0), (H,)模型参数初始化(权重是从标准差0.01的高斯分布中提取的,超参数num_hiddens定义隐藏单元的数量,偏置项设置为0):
def get_params(vocab_size, num_hiddens, device):num_inputs = num_outputs = vocab_sizedef normal(shape):return torch.randn(size=shape, device=device)*0.01def three():return (normal((num_inputs, num_hiddens)),normal((num_hiddens, num_hiddens)),torch.zeros(num_hiddens, device=device))W_xz, W_hz, b_z = three() # 更新⻔参数W_xr, W_hr, b_r = three() # 重置⻔参数W_xh, W_hh, b_h = three() # 候选隐状态参数
# 输出层参数W_hq = normal((num_hiddens, num_outputs))b_q = torch.zeros(num_outputs, device=device)
# 附加梯度params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]for param in params:param.requires_grad_(True)return params隐状态初始化函数(此函数返回一个形状为(批量大小,隐藏单元个数)的张量,张量的值都为0
def init_gru_state(batch_size, num_hiddens, device):return (torch.zeros((batch_size, num_hiddens), device=device), )最后由一个函数统一起来,实现模型:
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params, init_gru_state, gru)小结
总体上说,内部的代码实现与数学表达式一致,在实际使用中,一般是通过调用API来实现,即self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout),只需要设定相应的参数即可,免除了重新实现的繁琐,并且类似于pytorch框架中的API还做了计算上的优化,使用起来高效方便。但是,如果需要深入理解GRU的话,那么内部实现的详细代码和计算公式就比较重要,中间的一些过程和变量的意义需要详细关注,只有这样,才能准备把握这个模块的内涵和意义,设计初衷和使用方式等等,所以,仔细研究这个模块的实现还是非常有必要的。对于其他的模块同样如此,只有把各个经典的模块内部原理、实现和计算调用都搞清楚了,才能更好的去设计和利用神经网络,建立内在的直觉和能力。