前几天有写过两篇:
【爬虫】爬取A股数据写入数据库(二)
【爬虫】爬取A股数据写入数据库(一)
现在继续完善,分析及爬取股票的历史K线数据通过ORM形式批量写入数据库。
2024/05,本文主要内容如下:
- 对东方财富官网进行分析,并作数据爬取,使用python,使用pip install requests 模拟http数据请求,获取数据。
- 将爬取的数据写入通过 sqlalchemy ORM 写入 sqlite数据库。
- 记录爬取股票的基本信息,如果库中已存在某个股票代码,则进行更新。
- 后续计划:会不断完善,最终目标是做出一个简单的股票查看客户端。
- 本系列所有源码均无偿分享,仅作交流无其他,供大家参考。
python依赖环境如下:
pip install requests==2.31.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pandas==2.2.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install jsonpath==0.8.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install sqlalchemy==2.0.30 -i https://pypi.tuna.tsinghua.edu.cn/simple
1. 对东方财富官网历史K线数据分析
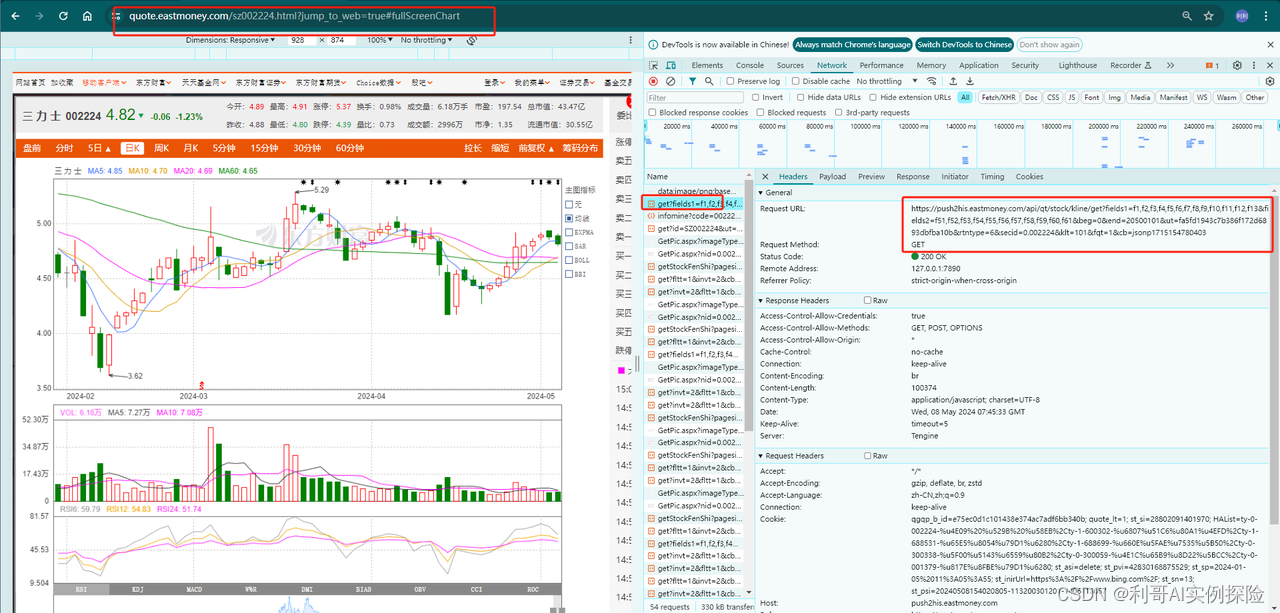
网页地址:https://quote.eastmoney.com/sz002224.html?jump_to_web=true#fullScreenChart
通过分析网页,发现https://push2his.eastmoney.com/api/qt/stock/kline/get?请求后面带着一些参数即可以获取到相应数据,我们不断调试,模拟这类请求即可。分析过程如下图所示,F12调出调试框,不断尝试:
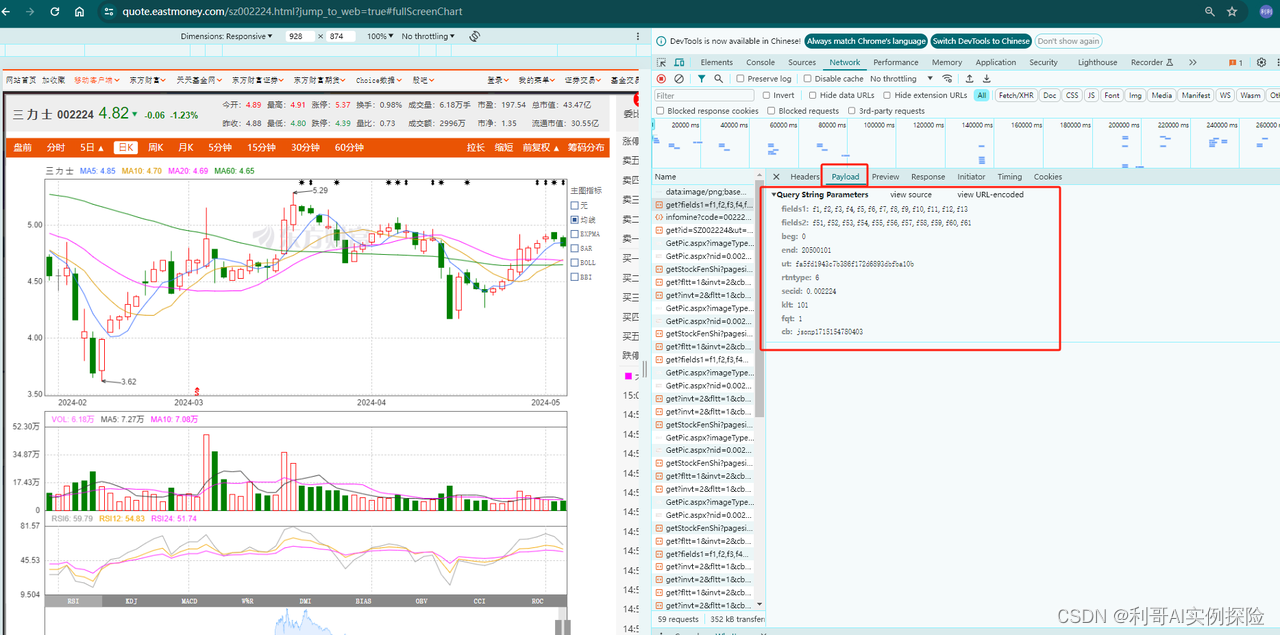
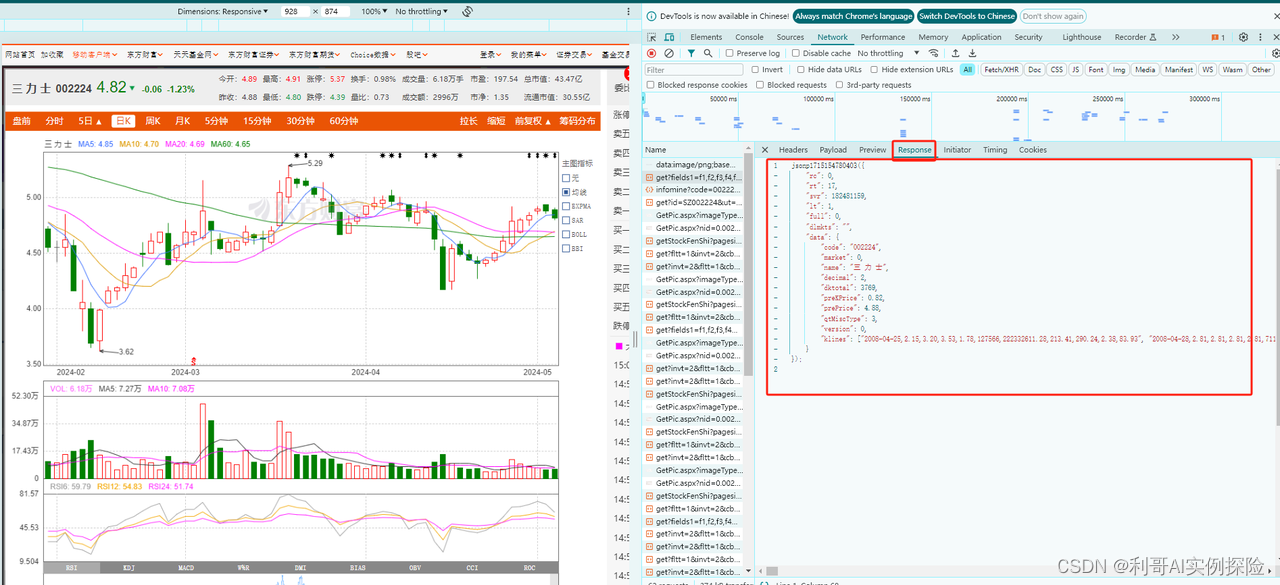
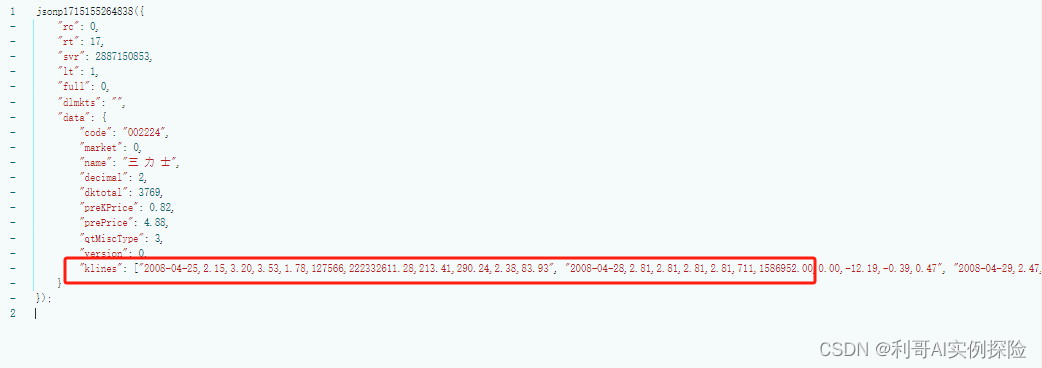
2. 爬取数据代码逻辑
如下即爬取数据的可运行代码,复制后直接能跑:
import pandas as pd
from typing import List
import requests
from jsonpath import jsonpathclass CustomedSession(requests.Session):def request(self, *args, **kwargs):kwargs.setdefault('timeout', 60)return super(CustomedSession, self).request(*args, **kwargs)
session = CustomedSession()
adapter = requests.adapters.HTTPAdapter(pool_connections = 50, pool_maxsize = 50, max_retries = 5)
session.mount('http://', adapter)
session.mount('https://', adapter)# 请求地址
QEURY_URL = 'http://push2his.eastmoney.com/api/qt/stock/kline/get'
# HTTP 请求头
EASTMONEY_REQUEST_HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; Touch; rv:11.0) like Gecko','Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
}"""
获取单只股票的历史K线数据
"""
def get_k_history_data(stock_codes: str, # 股票代码beg: str = '19000101', # 开始日期,19000101,表示 1900年1月1日end: str = '20500101', # 结束日期klt: int = 101, # 行情之间的时间间隔 1、5、15、30、60分钟; 101:日; 102:周; 103:月fqt: int = 1, # 复权方式,0 不复权 1 前复权 2 后复权
):try:# 生成东方财富专用的secidif stock_codes[:3] == '000': # 沪市指数secid = f'1.{stock_codes}'elif stock_codes[:3] == '399': # 深证指数secid = f'0.{stock_codes}'if stock_codes[0] != '6': # 沪市股票secid = f'0.{stock_codes}'else:secid = f'1.{stock_codes}' # 深市股票EASTMONEY_KLINE_FIELDS = {'f51': '日期', 'f52': '开盘', 'f53': '收盘', 'f54': '最高', 'f55': '最低','f56': '成交量', 'f57': '成交额', 'f58': '振幅', 'f59': '涨跌幅', 'f60': '涨跌额', 'f61': '换手率',}fields = list(EASTMONEY_KLINE_FIELDS.keys())# columns = list(EASTMONEY_KLINE_FIELDS.values())fields2 = ",".join(fields)params = (('fields1', 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f12,f13'),('fields2', fields2),('beg', beg),('end', end),('rtntype', '6'),('secid', secid),('klt', f'{klt}'),('fqt', f'{fqt}'),)code = secid.split('.')[-1]json_response = session.get(QEURY_URL, headers=EASTMONEY_REQUEST_HEADERS, params=params, verify=False).json()data_list = []klines: List[str] = jsonpath(json_response, '$..klines[:]')if not klines:return data_listname = json_response['data']['name']rows = [kline.split(',') for kline in klines]# 0 1 2 3 4 5 6 7 8 9 10# 日期, 开盘, 收盘, 最高, 最低, 成交量, 成交额, 振幅, 涨跌幅, 涨跌额, 换手率# 2024-05-08, 4.89, 4.82, 4.91, 4.80, 61811, 29955564.00, 2.25, -1.23, -0.06, 0.98# data_list = [{'code': '002224', 'name': '三力士', 'time': '2024-05-08', 'info': '0,1,2,3,4,5,6,7,8,9,10'}]for row in rows:time, open, close, high, low, vol, quota, mm, change, range, tun = rowline_str = f'{open},{close},{high},{low},{vol},{quota},{mm},{change},{range},{tun}'data_list.append({'id': None,'code': code, 'name': name, 'time': time, 'info': line_str})return data_listexcept Exception as e:print('get_k_history_data error-----------------------', str(e))return data_listif __name__ == "__main__":data = get_k_history_data(stock_codes='002224', beg='20240507', end='20500101')print('----', data)
3. 将爬取的数据通过ORM形式写入数据库
数据库表设计:
from sqlalchemy import create_engine, Column, Integer, String, DateTime, Float, Index, Table
from sqlalchemy.orm import declarative_base, sessionmaker, scoped_session
from sqlalchemy.schema import UniqueConstraint
from datetime import datetime# 声明一个基类,所有的ORM类都将继承自这个基类
DBBase = declarative_base()# 创建引擎
engine = create_engine('sqlite:///a.db', echo=False)
# 绑定引擎
Session = sessionmaker(bind=engine)
# 创建数据库链接池,直接使用session即可为当前线程拿出一个链接对象conn
db_session = scoped_session(Session)'''
股票K线信息表
0 1 2 3 4 5 6 7 8 9 10
日期, 开盘, 收盘, 最高, 最低, 成交量, 成交额, 振幅, 涨跌幅, 涨跌额, 换手率
2024-05-08, 4.89, 4.82, 4.91, 4.80, 61811, 29955564.00, 2.25, -1.23, -0.06, 0.98
data_list = [{'code': '002224', 'name': '三力士', 'time': '2024-05-08', 'info': '1,2,3,4,5,6,7,8,9,10'}]
'''
class tb_k(DBBase):__tablename__ = 'tb_k'id = Column(Integer, primary_key=True, autoincrement=True)code = Column(String, nullable=False, comment="股票代码")name = Column(String, comment="股票名称")time = Column(String, comment="时间")info = Column(String, comment="开盘,收盘,最高,最低,成交量,成交额,振幅,涨跌幅,涨跌额,换手率")__table_args__ = (Index('unique_index', 'code', 'time', unique=True),)
# 创建表, 创建所有class xx(DBBase)
DBBase.metadata.create_all(engine)
写入数据库的逻辑:
# 查询某个股票最近更新K线的日期
def query_latast_K_data(code):result = db_session.query(tb_k).filter(tb_k.code==code).order_by(desc(tb_k.time)).first()if result is None:return '19000101'return str(result.time).replace('-','')# 批量插入或更新某只股票的历史K线数据
def insert_or_update_stock_k(data_list):if len(data_list) <= 0:returntry:db_session.bulk_insert_mappings(tb_k, data_list)db_session.commit()except Exception as e:print('insert_or_update_stock_k error=', str(e))
4. 整体逻辑流程
步骤:
- 输入某个股票代码爬取该股票的历史K线数据
- 将返回结果组成数组,批量写入数据库
- 每次写入前,会根据该股票代码,查询最新的同步日期,从该日期开始进行追加同步
# 更新某个股票的最新日K线数据到数据库
def update_k_info_db(code='002224'):# 根据 code 查询库中已存在的某个股票日K线数据的最近日期,作为开始日期,向后获取beg_time = db_orm.query_latast_K_data(code)data_list = stock.get_k_history_data(stock_codes=code, beg=beg_time, end='20500101')if len(data_list) > 0:db_orm.insert_or_update_stock_k(data_list)if __name__ == "__main__":update_base_info_db()
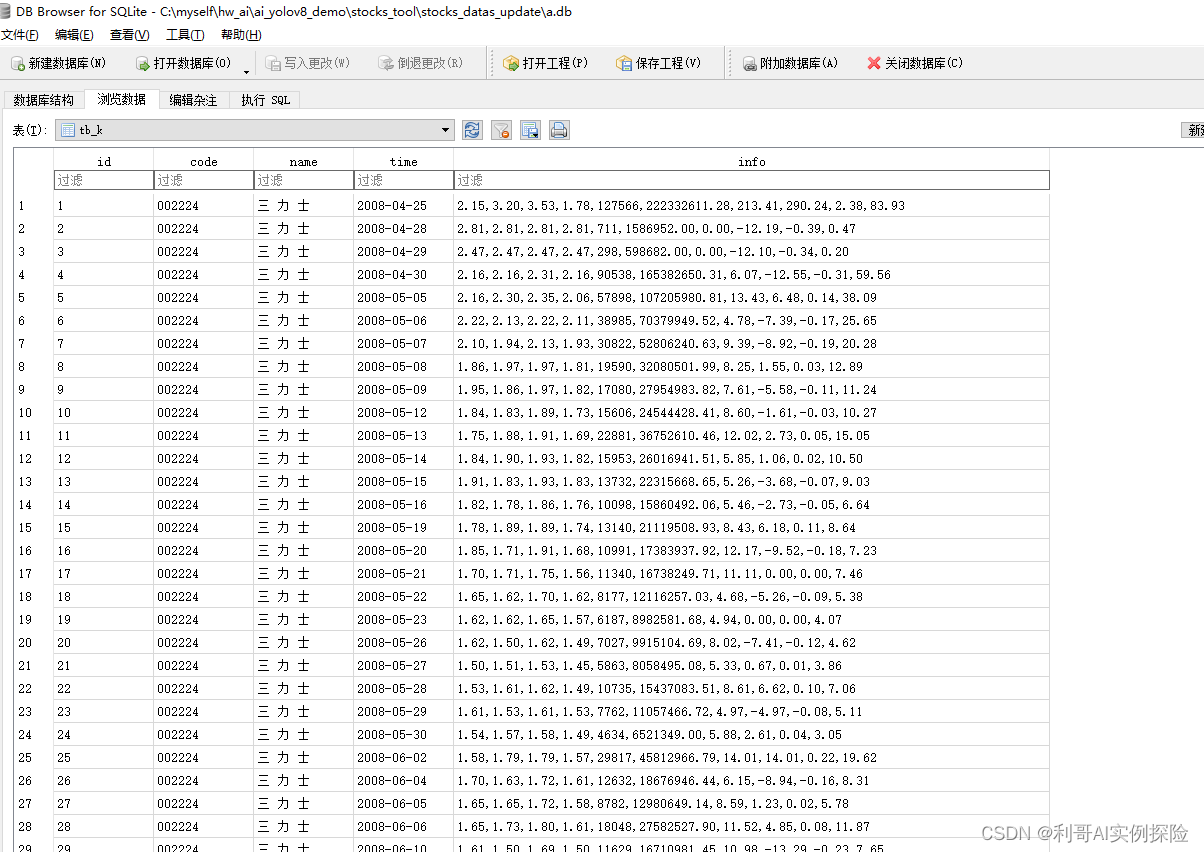
最终结果保存在 a.db中,例如:
更多内容可关注我,后续源码包均在上面回复下载:
【爬虫】爬取A股数据系列工具