模型参数融合通常指的是在训练过程中或训练完成后将不同模型的参数以某种方式结合起来,以期望得到更好的性能。这种融合可以在不同的层面上进行,例如在神经网络的不同层之间,或者是在完全不同的模型之间。模型参数融合的目的是结合不同模型的优点,减少过拟合的风险,并提高模型的泛化能力。在实际应用中,这通常需要大量的实验来找到最佳的融合策略。
本篇文章只介绍训练完成后的不同模型的参数融合,不涉及训练过程的模型参数融合。
可行性分析
2023 年年初的时候,chatglm 刚推出 glm-130B 模型那会儿,一个令人印象深刻的论述是大模型的参数空间非常稀疏,对于大部分权重可以用 int4 进行量化来减少显存的开销,从而能够在多张消费级显卡上进行部署。当时公司的资源有限,用 3 张 RTX3090 以 int4 方式部署,推理的效果虽然相较 chatgpt 甚远,但比起 T5 也好得多,经过业务数据微调后即可投入到实际的生产业务。
去年 5 月份,LIMA(LIMA:Less Is More for Alignment) 提出了“浅层表征假说”:一个模型的知识和能力几乎完全是在预训练中学习的,而对齐则是教它在与用户交互时应该使用哪种格式的子分布。提高输入多样性和输出质量会产生可衡量的积极影响,而仅提高数量则可能不会(实际上也要训练特定领域的 LLM,或者在 SFT 阶段注入知识,仍然需要大规模的数据,模型是可以在 SFT 阶段学到知识,不过这可能不叫做对齐,这就有点玩文字游戏的嫌疑了)。
此外,去年还看到一篇博客 Can LLMs learn from a single example?,它针对 SFT 多 epoch 训练时,loss 曲线呈现阶梯状做了假设与验证,提出“记忆假说可能是真的”,现代 LLM 的学习速度非常快!当模型的训练速度非常慢时,我们可以使用各种各样的数据对它们进行长时间的训练,并进行多个 epoch 训练,而且我们可以预期,我们的模型将逐渐从我们给它的数据中提取出可概括的信息。但是,当模型的学习速度如此之快时,灾难性遗忘问题可能会突然变得明显得多。例如,如果一个模型看到了十个非常常见关系的示例,然后又看到了一个不太常见的反例,那么它很可能会记住这个反例,而不仅仅是稍微降低它对原来十个示例的记忆权重。从这个角度来说,LLM 的 SFT 非常容易过拟合,模型只是记住了答案,或者数据的难度不足以让模型有新的收获(因此,现在流行各种课程学习,以及数据子集挑选方法中会选择 loss 高的样本)。博客中的一句原文“预训练的大语言模型在接近最小损失的区域具有极其平滑的损失面,而开源社区所做的大量微调工作都是在这一区域”。
综上所述,将这三方面的观点结合:不同任务的微调或许仅仅只是修改了庞大参数空间的一隅,但这些任务数据之间高度的独立同分布,它们各自在各自的参数空间内“各司其职、互不干扰”,就像九头蛇一样,共享同一个身体,通过不同任务的微调,使其长出一个新的头(浅层表征趋向于特定领域)。
模型参数融合的优缺点
- 无需训练,只需要将现有的基于相同基底的模型进行融合即可,例如把基于 mistral-7b 微调的 mistral-7b-math 和 mistral-7b-instruct-v0.1 进行融合,结合指令遵循能力和数学能力。
- 针对单独一个领域训练“偏科”的模型要比训练通用模型要容易得多,不需要考虑数据集内部各类型数据的配比情况,也不需要考虑数据顺序和采样,训练的过程也容易得多,甚至过拟合也未尝不可。
- “查漏补缺”,哪里不行补哪里。
模型参数融合的缺点是不一定有用(滑稽.jpg)。
DARE
阿里提出了一种名为 DARE 的方法,用来将具备不同能力的多个模型融合成拥有全部能力的单个模型。
- 论文地址:https://arxiv.org/abs/2311.03099
- GitHub 仓库:https://github.com/yule-BUAA/MergeLM/tree/main
- 相关文章:https://zhuanlan.zhihu.com/p/668152236
作者发现基于编码器或解码器的语言模型可以通过吸收同源模型的参数来获得新的能力,而无需重新训练。通常,LMs 的新能力可以通过 SFT 实现,这反映在微调后模型参数与预训练参数(即 delta 参数)之间的差距上。作者提出 DARE(Drop And REscale)方法,将大部分的 delta 参数设置为 0,这并不会影响 SFT LM 的能力,并且越大的模型的可以 drop 更多的参数。基于这一观察结果,使用 DARE 进一步稀疏多个 SFT 同源模型的 delta 参数,然后通过参数平均将它们合并为一个模型。
mergekit
现在用的比较多的是 mergekit 这个工具。mergekit 是一个用于合并预训练语言模型的工具包,支持多种合并算法。
- GitHub 仓库:https://github.com/cg123/mergekit
它还能将多个模型融合成 MoE,例如 https://huggingface.co/mlabonne/Beyonder-4x7B-v2。这种 MoE 通常被称为 Franken MoE,即选择几个在特定任务上表现优异的微调模型,将它们组合成一个 MoE 模型。通过一定的训练,可以让路由器学会将不同类型的 token 发送给对应的专家。

- 配置文件示例:
base_model: mlabonne/Marcoro14-7B-slerp experts:- source_model: openchat/openchat-3.5-1210positive_prompts:- "chat"- "assistant"- "tell me"- "explain"- source_model: beowolx/CodeNinja-1.0-OpenChat-7Bpositive_prompts:- "code"- "python"- "javascript"- "programming"- "algorithm"- source_model: maywell/PiVoT-0.1-Starling-LM-RPpositive_prompts:- "storywriting"- "write"- "scene"- "story"- "character"- source_model: WizardLM/WizardMath-7B-V1.1positive_prompts:- "reason"- "math"- "mathematics"- "solve"- "count"
融合效果
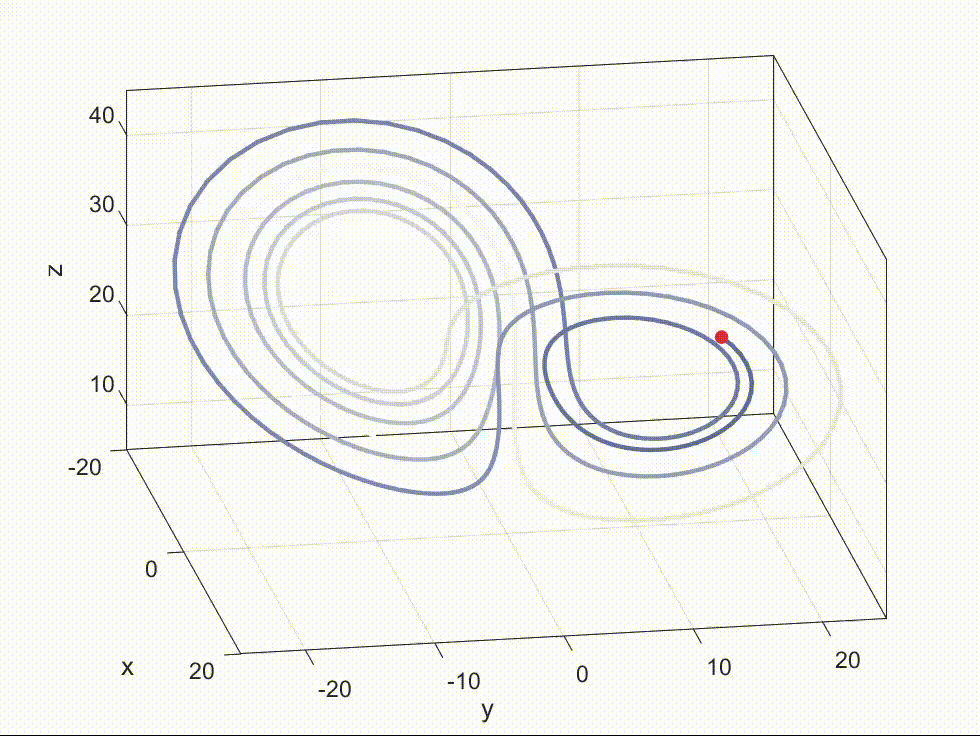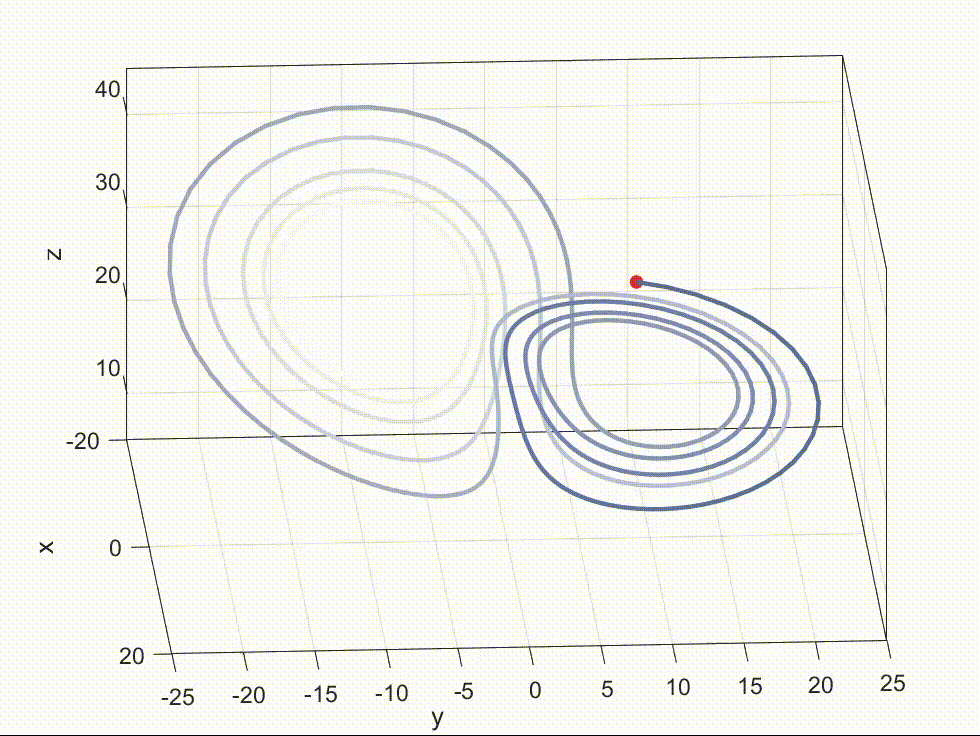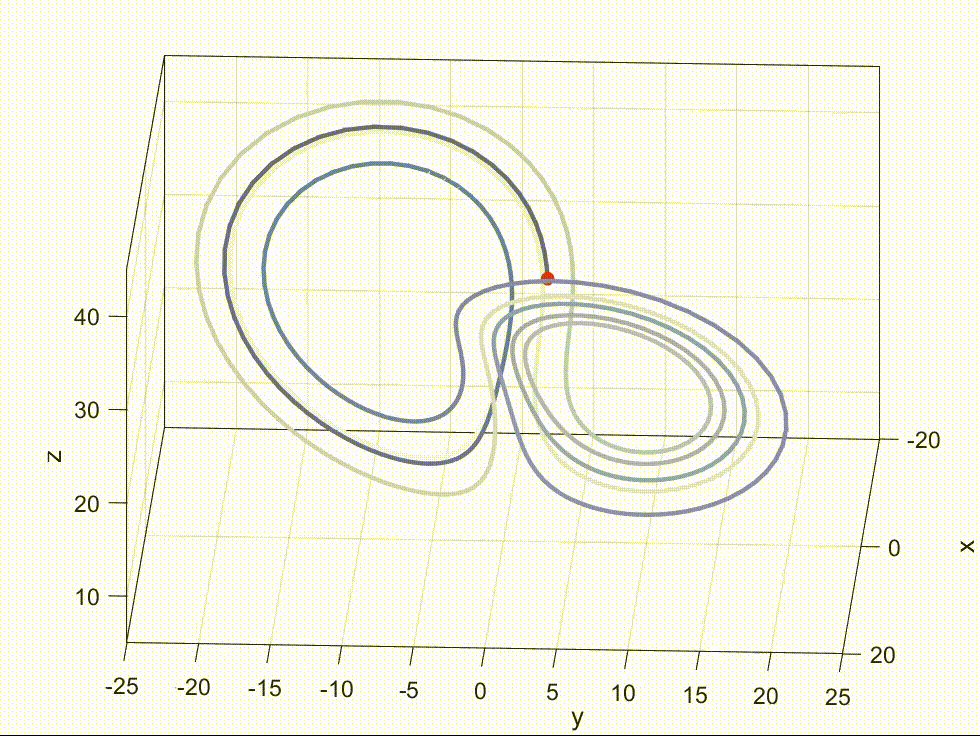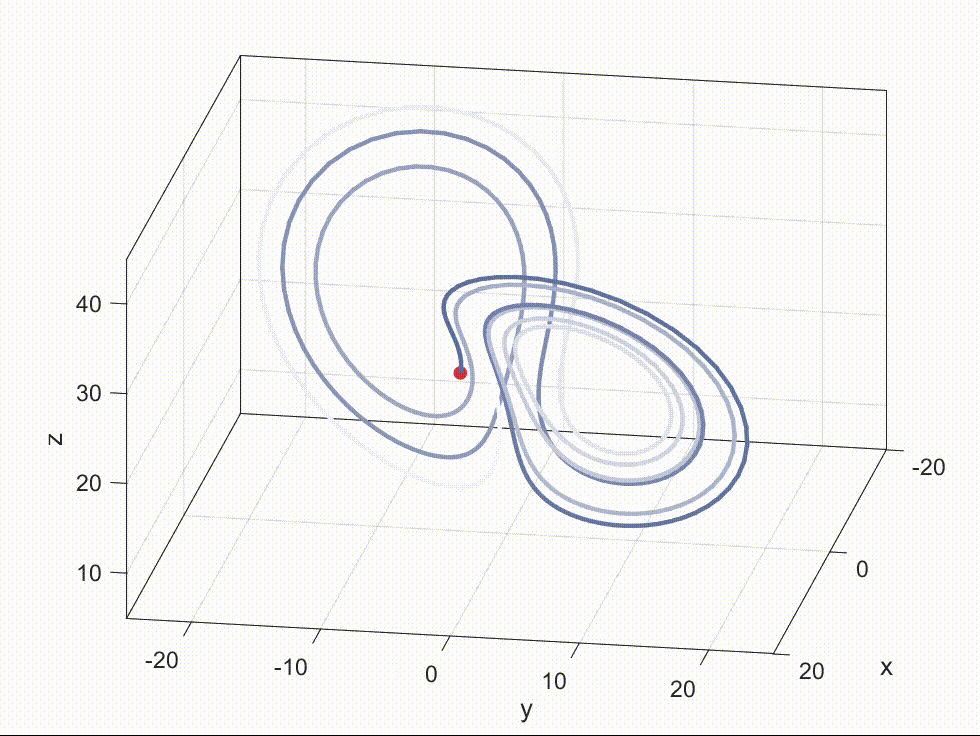
融合的效果(使用阿里提出的 DARE 方法)见下图,去年 11 月份的时候尝试调研一些“奇技”,看看能否提升闲聊模型的能力,由于受到灾难性遗忘的困扰,于是考虑尝试用模型参数融合的方式,可以看到融合后的 mistral-7b-dare-merge-v1 尽可能综合 mistral-7b-instruct-v0.1 和 mistral-7b-math 的长处。

后续尝试将自研模型与一些专长的开源模型进行融合,最后是超越了 GPT-3.5-Turbo-0314,评测是用 fastchat 的代码,工具是自己搭建的一套可视化网页版。由于涉及到公司的一些机密,加上现在离职了(悲),故而无法放出具体的截图,但模型参数融合的确会有效果,值得尝试。
最近有一篇名为《How Good Are Low-bit Quantized LLaMA3 Models? An Empirical Study》的论文:研究人员使用现有的 10 种训练后量化和 LoRA 微调方法,评估了 Llama3 在 1-8 bit 和各种评估数据集上的结果。他们发现:Llama3 在低比特量化下遭受了不可忽视的退化,特别是在超低位宽上。
有一个评论非常有意思:
果然没有免费午餐,llama3-8b 模型用了 15t tokens,模型训练充分,冗余权重应该少很多,再执行量化难度大点。模型越大越容易量化,最朴素道理就是冗余权重过多。gptq 本质就是把其他权重量化损失补偿到另外没量化权重上,相当于一次“平权”。虽然深度学习复杂度是人类无法理解的,但是依旧要服从信息熵规律。
推测:模型训练得越充分,同模型量化一样,模型参数融合起到的作用也越低,甚至可能效果反而下降。

先前做过的一次实验也有同样的结论,如上图所示。当然,具体是否如此还需要更加细致的验证。由于现在手上没卡,也难以得出确切的结论,如果有读者感兴趣的话,可以在评论里说明一二,不胜感激!