一、说明
在使用BERT(1)进行文本分类中,我向您展示了一个BERT如何标记文本的示例。在下面的文章中,让我们更深入地研究是否可以使用 BERT 来预测文本是使用 PyTorch 传达积极还是消极的情绪。首先,我们需要准备数据,以便使用 PyTorch 框架进行分析。
二、什么是 PyTorch
PyTorch 是用于构建深度学习模型的框架,深度学习模型是一种机器学习,通常用于图像识别和语言处理等应用程序。它由Facebook的人工智能研究小组于2016年开发,由于其灵活性,易用性和动态计算图构建而广受欢迎。
PyTorch 提供了一个基于 Python 的科学计算包,它使用图形处理单元 (GPU) 的强大功能来加速张量运算的计算。它具有简单直观的API,允许开发人员快速构建和训练深度学习模型。PyTorch 还支持自动微分,使用户能够计算任意函数的梯度。
三、准备我们的数据集
首先,让我们从Github下载我们的数据。这里有一个关于如何从Github下载CSV文件的小提醒。只需继续并单击以下链接:
github.com
然后,右键单击“原始”,然后左键单击“将链接文件下载为...”。您将看到“垃圾邮件.csv”并下载它。下载后,将其保存到您的首选文件夹中以供以后使用。
现在,让我们导入数据。我们看到一条错误消息,告诉我们部分数据未采用 UTF-8 编码。
import pandas as pd
df = pd.read_csv("spam.csv")ERROR:
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 606-607: invalid continuation byte我们可以通过了解数据包含的字符编码并在读取数据时调用该编码来修复此错误。
# Use chardet to know the character encoding
import chardet
with open("spam.csv", 'rb') as rawdata:result = chardet.detect(rawdata.read(100000))
resultOutput:
{'encoding': 'Windows-1252', 'confidence': 0.7270322499829184, 'language': ''}似乎我们的数据是在“Windows-1252”中编码的。那让我们再读一遍。它奏效了!
df = pd.read_csv("spam.csv", encoding = 'Windows-1252')
df.head()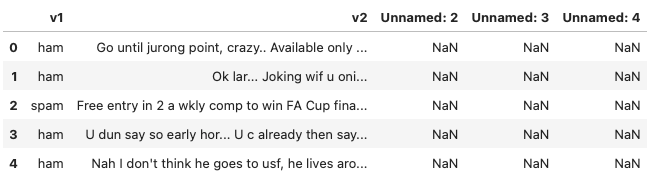
如我们所见,我们实际上并不需要“v1”和“v2”以外的列。此外,如果我们将“v1”和“v2”重命名为“类别”和“消息”,则更容易理解。
df = df.loc[:, ['v1', 'v2']]
df = df.rename(columns={'v1': 'Category', 'v2': 'Message'})
df.head()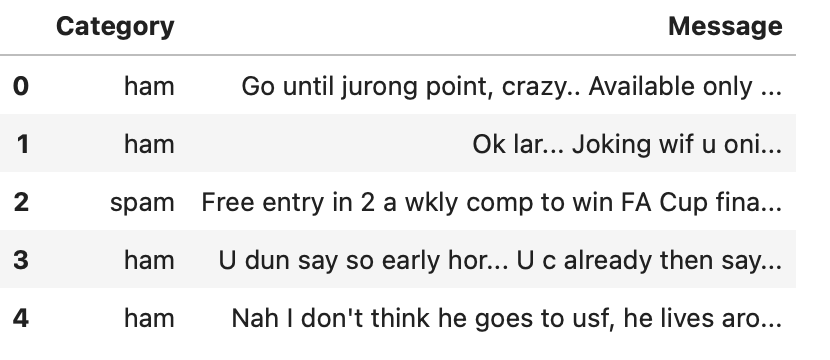
现在,我们应该看看我们的数据集,看看每个类别中有多少条消息。
df['Category'].value_counts()Output:
ham 4825
spam 747
Name: Category, dtype: int64四、创建平衡数据集
事实证明,正常邮件比垃圾邮件多。构建机器学习模型时,如果数据集不平衡,其中一个类中的数据数量明显多于另一个类,则可能会对模型的性能产生各种影响。一些潜在的后果。例如:
-1 有偏差模型:如果数据集不平衡,模型可能会偏向多数类,而对少数类表现不佳。这是因为模型更有可能预测多数类,这将导致少数类的准确性较差。
-2 泛化不良:不平衡的数据集可能导致模型泛化不良。这是因为该模型将在不代表数据真实世界分布的数据集上进行训练,因此它可能无法很好地概括看不见的数据。
-3 评估不准确:如果使用准确性作为指标评估模型,则可能会产生误导性结果。例如,始终预测不平衡数据集中多数类的模型可能具有很高的准确性,但对少数类没有用。
-4 过拟合:由于数据点数量较多,模型可能会过度拟合多数类,从而导致测试数据的性能不佳。
为了解决这些问题,可以使用各种技术来平衡数据集,例如对少数类进行过采样,对多数类进行欠采样,或同时使用两者的组合。在这篇文章中,我将使用欠采样方法。
df_spam = df[df['Category']=='spam']
df_ham = df[df['Category']=='ham']
df_ham_downsampled = df_ham.sample(df_spam.shape[0])
df_balanced = pd.concat([df_ham_downsampled, df_spam])
df_balanced['Category'].value_counts()Output:
ham 747
spam 747
Name: Category, dtype: int64五、标记数据
当数据表示为数字而不是分类为用于训练和测试的模型时,机器学习算法在准确性和其他性能指标方面表现更好。我们需要用数值对分类值进行标签编码。在这里,我们创建了一个新列“标签”,如果邮件是垃圾邮件,我们将其标记为 1,否则为 0。
df_balanced['Label']=df_balanced['Category'].apply(lambda x: 1 if x=='spam' else 0)
df_balanced = df_balanced.reset_index(drop=True)display(df_balanced)
由作者创建
六、训练、验证和测试数据集:谁是谁
要记住的一件事是,当我们使用 train_test_split 库来训练模型时,我们实际上是将数据集拆分为 TRAINING 数据集和 VALIDATION 数据集,而不是 TRAINING 数据集和 TESTING 数据集。下面提醒一下这些数据集的含义。
- 训练集:用于构建我们的模型。我们将使用训练集来找到具有反向传播规则的“最佳”权重和偏差。在此阶段,我们通常会创建多个算法,以便在交叉验证阶段比较它们的性能。
- 交叉验证集:此数据集用于比较基于训练集创建的预测算法的性能。我们选择性能最佳的算法。
- 测试集:这是“未来”数据集。现在我们已经选择了我们喜欢的预测算法,但我们还不知道它将如何在完全看不见的真实世界数据上执行。因此,我们将我们选择的预测算法应用于我们的测试集,以查看它将如何执行,以便我们可以了解我们的算法在野外的性能。
因此,在测试集中,我们没有数据的标签,而是使用我们的模型来预测标签。我们只能将手头的数据集拆分为训练集和验证集,因为我们还没有“未来”数据。
七、拆分为训练数据集和验证数据集
现在我们了解了这三种类型的数据的真正含义,我们可以使用scikit-learn的train_test_split来拆分数据。
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(df_balanced['Message'],df_balanced['Label'], stratify=df_balanced['Label'], test_size=.2)X_train.head()Output:
708 ;-) ok. I feel like john lennon.
1386 Cashbin.co.uk (Get lots of cash this weekend!)...
1492 REMINDER FROM O2: To get 2.50 pounds free call...
119 Back in brum! Thanks for putting us up and kee...
89 Sorry, I can't help you on this.
Name: Message, dtype: object八、总结
我们已经学会了如何下载和拆分数据。在下一篇文章中,我们将首先对其进行标记,并使用DistilBERT训练分类器。达门·