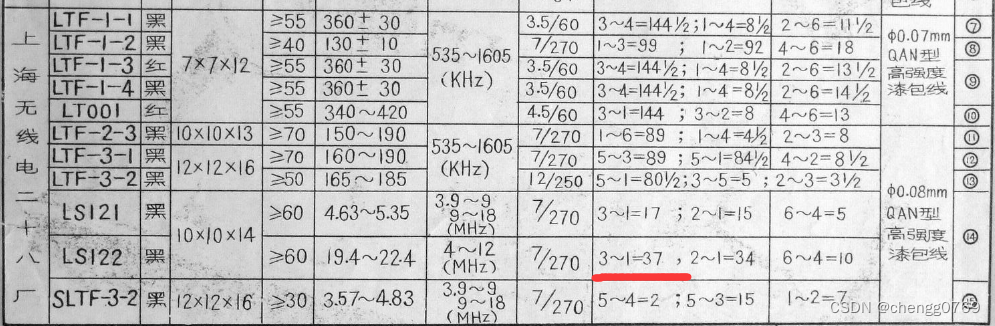
如何理解机器学习数据集的概念
数据集是机器学习的基础,它包括了用于训练和测试模型所需的数据。数据集通常以矩阵的形式存在,其中每一行代表一个样本(或实例),每一列代表一个特征(或属性)。每个样本都包含了对应于各个特征的数值,数据集通常会被划分为训练集和测试集,有时还包括验证集。训练集用于训练模型,测试集用于评估模型的性能,而验证集则用于在训练过程中调整模型的参数。

机器学习中特征的理解
特征选择:原有特征选择出⼦集,不改变原来的特征空间
降维:将原有的特征重组成为包含信息更多的特征,改变了原有的特征空间
降维的主要⽅法
- Principal Component Analysis(主成分分析)
- Singular Value Decomposition(奇异值分解)
特征选择的⽅法
- Filter⽅法:卡⽅检验、信息增益、相关系数
- Wrapper⽅法
- Embedded⽅法
Wrapper其主要思想是:将⼦集的选择看作是⼀个搜索寻优问题,⽣成不同的组合,对组合进⾏评价,再与其他的组合进⾏⽐较。这样就将⼦集的选择看作是⼀个是⼀个优化问题,这⾥有很多的优化算法可以解决,尤其是⼀些启发式的优化算法,如GA,PSO,DE,ABC等,详⻅“优化算法——⼈⼯蜂群算法(ABC)”,“优化算法——粒⼦群算法(PSO)”。
Embedded⽅法主要思想是:在模型既定的情况下学习出对提⾼模型准确性最好的属性,挑选出那些对模型的训练有重要意义的属性。

机器学习的三要素
- 数据:数据是机器学习的基础,它包括原始数据和特征向量。在机器学习中,数据不仅要被收集和整理,还需要通过特征工程来提取有用的信息,以便模型能够更好地学习和理解。
- 模型:模型是对现实世界问题的一种数学抽象,它可以是训练后的函数,用于捕捉数据之间的关系和模式。模型可以是判别式的,如逻辑回归;也可以是生成式的,如深度学习和支持向量机。模型的选择取决于具体问题的需求和数据的特性。
- 算法:算法是指导模型如何从数据中学习的一系列计算步骤。它不仅包括模型的训练过程,还包括模型的评估和最优化。算法的选择会影响到模型的学习效率和最终的性能。

机器学习中的特征选择的⽅法
- 计算每⼀个特征与相应变量的相关性:常⽤的⼿段有计算⽪尔逊系数和互信息系数,⽪尔逊系数只能衡量线性相关性⽽互信息系数能够很好地度量各种相关性,但是计算相对复杂⼀些,toolkit⾥边都包含了这个⼯具,得到相关性之后就可以排序选择特征了。
- 构建单个特征的模型,通过模型的准确性为特征排序,借此来选择特征;
- 通过L1正则项来选择特征:L1正则⽅法具有稀疏解的特性,因此天然具备特征选择的特性,但是L1没有选到的特征不代表不重要,原因是两个具有⾼相关性的特征可能只保留了⼀个,如果要确定哪个特征重要应再通过L2正则⽅法交叉检验*。
- 训练能够对特征打分的预选模型:RandomForest和Logistic Regression等都能对模型的特征打分,通过打分获得相关性后再训练最终模型;
- 通过特征组合后再来选择特征:如对⽤户id和⽤户特征最组合来获得较⼤的特征集再来选择特征,这种做法在推荐系统和⼴告系统中⽐较常⻅,这也是亿级特征的主要来源,原因是⽤户数据⽐较稀疏,组合特征能够同时兼顾全局模型和个性化模型。
- 通过深度学习来进⾏特征选择。

机器学习中的正负样本
在机器学习中,正样本通常指的是那些标签或者类别与模型预测的目标一致的样本,而负样本则是指标签或类别与预测目标不一致的样本。
- 正样本:在分类任务中,正样本是那些属于我们感兴趣的类别的样本。例如,如果我们正在训练一个垃圾邮件检测器,所有标记为垃圾邮件的邮件都是正样本。在目标检测领域,正样本可能指的是包含待检测目标(如人脸)的图像区域。
- 负样本:负样本则是那些不属于我们感兴趣类别的样本。在上述垃圾邮件检测器的例子中,所有非垃圾邮件的邮件都是负样本。在目标检测中,负样本可能是那些不包含待检测目标的图像区域。

如何解决过拟合问题
过拟合:模型在训练集表现好,在真实数据表现不好,即模型的泛化能⼒不够。,模型在达到经验损失最⼩的时候,模型复杂度较⾼,结构⻛险没有达到最优。
- 增加数据量:通过获取更多的训练数据,可以提供更多的信息给模型,帮助它学习到更泛化的特征。
- 正则化:在损失函数中添加正则化项,如L1或L2正则化,以惩罚模型的复杂度,防止过拟合。
- 数据增强:通过对现有数据进行变换(如旋转、缩放等),可以创造出新的训练样本,从而增加数据的多样性。
- 引入随机性:在模型中引入随机性,例如使用随机森林或者在神经网络中使用dropout层,可以帮助模型更好地泛化。
- 降维:当数据集具有高维度时,可以通过降维技术(如PCA)来减少特征数量,从而简化模型并减少过拟合的可能性。

L1和L2正则的区别
- L1正则化:也称为Lasso回归,它通过权值向量中各个元素的绝对值之和来定义。这种形式的正则化倾向于将一些权值缩小到绝对的零,从而实现了特征选择的效果,即某些特征的权重变为零,这些特征就被排除在模型之外。
- L2正则化:也称为Ridge回归,它通过权值向量中各个元素的平方和的平方根来定义。这种形式的正则化倾向于让所有权值都接近于零,但不会完全为零,从而避免了特征选择,而是通过减小权重的大小来防止过拟合。
L1正则化表示各个参数绝对值之和。L1范数的解通常是稀疏性的,倾向于选择数⽬较少的⼀些⾮常⼤的值或者数⽬较多的insignificant的⼩值。L2正则化标识各个参数的平⽅的和的开⽅值。L2范数越⼩,可以使得w的每个元素都很⼩,接近于0,但L1范数不同的是他不会让它等于0⽽是接近于0 。
- L1正则化:由于其倾向于产生稀疏权值矩阵,L1正则化通常用于特征选择,特别是在特征数量很多或者存在多重共线性的情况下。它可以帮助我们识别出对预测目标最重要的特征。
- L2正则化:由于其倾向于让权值均匀地接近零,L2正则化可以帮助模型提高稳定性和泛化能力,尤其是在特征不多或者特征之间相互独立的情况下。

有监督学习和无监督学习
- 有监督学习:对具有概念标记(分类)的训练样本进⾏学习,以尽可能对训练样本集外的数据进⾏标记(分类)预测。只要输入样本集,机器就可以从中推演出制定⽬标变量的可能结果。
- 无监督学习:对没有概念标记(分类)的训练样本进⾏学习,以发现训练样本集中的结构性知识。
监督学习的典型例子就是决策树、神经⽹络以及疾病监测,而无监督学习就是很早之前的⻄洋双陆棋和聚类。