CART决策树(4-2)
CART(Classification and Regression Trees)决策树是一种常用的机器学习算法,它既可以用于分类问题,也可以用于回归问题。CART决策树的主要原理是通过递归地将数据集划分为两个子集来构建决策树。在分类问题中,CART决策树通过选择一个能够最大化分裂后各个子集纯度提升的特征进行分裂,从而将数据划分为不同的类别。
CART决策树的构建过程包括以下几个步骤:
- 特征选择:从数据集中选择一个最优特征,用于划分数据集。最优特征的选择基于某种准则,如基尼指数(Gini Index)或信息增益(Information Gain)。
- 决策树生成:根据选定的最优特征,将数据集划分为两个子集,并递归地在每个子集上重复上述过程,直到满足停止条件(如子集大小小于某个阈值、所有样本属于同一类别等)。
- 剪枝:为了避免过拟合,可以对生成的决策树进行剪枝操作,即删除一些子树或叶子节点,以提高模型的泛化能力。
CART决策树的优点包括:
- 计算简单,易于理解,可解释性强。
- 不需要预处理,不需要提前归一化,可以处理缺失值和异常值。
- 既可以处理离散值也可以处理连续值。
- 既可以用于分类问题,也可以用于回归问题。
然而,CART决策树也存在一些缺点:
- 不支持在线学习,当有新样本产生时,需要重新构建决策树模型。
- 容易出现过拟合现象,生成的决策树可能对训练数据有很好的分类能力,但对未知的测试数据却未必有很好的分类能力。
- 对于一些复杂的关系,如异或关系,CART决策树可能难以学习。
CART决策树在许多领域都有广泛的应用,如推荐系统中的商品推荐模型、金融风控中的信用评分和欺诈检测、医疗诊断中的疾病预测等。此外,CART决策树还可以用于社交媒体情感分析等领域。
- 数据
使用Universal Bank数据集。
示例:
| ID | Age | Experience | Income | ZIP Code | Family | CCAvg | Education | Mortgage | Personal Loan | Securities Account | CD Account | Online | CreditCard |
| 1 | 25 | 1 | 49 | 91107 | 4 | 1.6 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2 | 45 | 19 | 34 | 90089 | 3 | 1.5 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 3 | 39 | 15 | 11 | 94720 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 35 | 9 | 100 | 94112 | 1 | 2.7 | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 35 | 8 | 45 | 91330 | 4 | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 1 |
| 6 | 37 | 13 | 29 | 92121 | 4 | 0.4 | 2 | 155 | 0 | 0 | 0 | 1 | 0 |
| 7 | 53 | 27 | 72 | 91711 | 2 | 1.5 | 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 8 | 50 | 24 | 22 | 93943 | 1 | 0.3 | 3 | 0 | 0 | 0 | 0 | 0 | 1 |
| 9 | 35 | 10 | 81 | 90089 | 3 | 0.6 | 2 | 104 | 0 | 0 | 0 | 1 | 0 |
| 10 | 34 | 9 | 180 | 93023 | 1 | 8.9 | 3 | 0 | 1 | 0 | 0 | 0 | 0 |
| 11 | 65 | 39 | 105 | 94710 | 4 | 2.4 | 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 12 | 29 | 5 | 45 | 90277 | 3 | 0.1 | 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 13 | 48 | 23 | 114 | 93106 | 2 | 3.8 | 3 | 0 | 0 | 1 | 0 | 0 | 0 |
| 14 | 59 | 32 | 40 | 94920 | 4 | 2.5 | 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 15 | 67 | 41 | 112 | 91741 | 1 | 2 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 16 | 60 | 30 | 22 | 95054 | 1 | 1.5 | 3 | 0 | 0 | 0 | 0 | 1 | 1 |
| 17 | 38 | 14 | 130 | 95010 | 4 | 4.7 | 3 | 134 | 1 | 0 | 0 | 0 | 0 |
| 18 | 42 | 18 | 81 | 94305 | 4 | 2.4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 19 | 46 | 21 | 193 | 91604 | 2 | 8.1 | 3 | 0 | 1 | 0 | 0 | 0 | 0 |
| 20 | 55 | 28 | 21 | 94720 | 1 | 0.5 | 2 | 0 | 0 | 1 | 0 | 0 | 1 |
| 21 | 56 | 31 | 25 | 94015 | 4 | 0.9 | 2 | 111 | 0 | 0 | 0 | 1 | 0 |
| 22 | 57 | 27 | 63 | 90095 | 3 | 2 | 3 | 0 | 0 | 0 | 0 | 1 | 0 |
| 23 | 29 | 5 | 62 | 90277 | 1 | 1.2 | 1 | 260 | 0 | 0 | 0 | 1 | 0 |
| 24 | 44 | 18 | 43 | 91320 | 2 | 0.7 | 1 | 163 | 0 | 1 | 0 | 0 | 0 |
| 25 | 36 | 11 | 152 | 95521 | 2 | 3.9 | 1 | 159 | 0 | 0 | 0 | 0 | 1 |
| 26 | 43 | 19 | 29 | 94305 | 3 | 0.5 | 1 | 97 | 0 | 0 | 0 | 1 | 0 |
| 27 | 40 | 16 | 83 | 95064 | 4 | 0.2 | 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 28 | 46 | 20 | 158 | 90064 | 1 | 2.4 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| 29 | 56 | 30 | 48 | 94539 | 1 | 2.2 | 3 | 0 | 0 | 0 | 0 | 1 | 1 |
| 30 | 38 | 13 | 119 | 94104 | 1 | 3.3 | 2 | 0 | 1 | 0 | 1 | 1 | 1 |
| 31 | 59 | 35 | 35 | 93106 | 1 | 1.2 | 3 | 122 | 0 | 0 | 0 | 1 | 0 |
| 32 | 40 | 16 | 29 | 94117 | 1 | 2 | 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 33 | 53 | 28 | 41 | 94801 | 2 | 0.6 | 3 | 193 | 0 | 0 | 0 | 0 | 0 |
| 34 | 30 | 6 | 18 | 91330 | 3 | 0.9 | 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 35 | 31 | 5 | 50 | 94035 | 4 | 1.8 | 3 | 0 | 0 | 0 | 0 | 1 | 0 |
| 36 | 48 | 24 | 81 | 92647 | 3 | 0.7 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 37 | 59 | 35 | 121 | 94720 | 1 | 2.9 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 38 | 51 | 25 | 71 | 95814 | 1 | 1.4 | 3 | 198 | 0 | 0 | 0 | 0 | 0 |
| 39 | 42 | 18 | 141 | 94114 | 3 | 5 | 3 | 0 | 1 | 1 | 1 | 1 | 0 |
| 40 | 38 | 13 | 80 | 94115 | 4 | 0.7 | 3 | 285 | 0 | 0 | 0 | 1 | 0 |
| 41 | 57 | 32 | 84 | 92672 | 3 | 1.6 | 3 | 0 | 0 | 1 | 0 | 0 | 0 |
| 42 | 34 | 9 | 60 | 94122 | 3 | 2.3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 43 | 32 | 7 | 132 | 90019 | 4 | 1.1 | 2 | 412 | 1 | 0 | 0 | 1 | 0 |
| 44 | 39 | 15 | 45 | 95616 | 1 | 0.7 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 45 | 46 | 20 | 104 | 94065 | 1 | 5.7 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| 46 | 57 | 31 | 52 | 94720 | 4 | 2.5 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 47 | 39 | 14 | 43 | 95014 | 3 | 0.7 | 2 | 153 | 0 | 0 | 0 | 1 | 0 |
| 48 | 37 | 12 | 194 | 91380 | 4 | 0.2 | 3 | 211 | 1 | 1 | 1 | 1 | 1 |
| 49 | 56 | 26 | 81 | 95747 | 2 | 4.5 | 3 | 0 | 0 | 0 | 0 | 0 | 1 |
| 50 | 40 | 16 | 49 | 92373 | 1 | 1.8 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 51 | 32 | 8 | 8 | 92093 | 4 | 0.7 | 2 | 0 | 0 | 1 | 0 | 1 | 0 |
| 52 | 61 | 37 | 131 | 94720 | 1 | 2.9 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 53 | 30 | 6 | 72 | 94005 | 1 | 0.1 | 1 | 207 | 0 | 0 | 0 | 0 | 0 |
| 54 | 50 | 26 | 190 | 90245 | 3 | 2.1 | 3 | 240 | 1 | 0 | 0 | 1 | 0 |
| 55 | 29 | 5 | 44 | 95819 | 1 | 0.2 | 3 | 0 | 0 | 0 | 0 | 1 | 0 |
| 56 | 41 | 17 | 139 | 94022 | 2 | 8 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 57 | 55 | 30 | 29 | 94005 | 3 | 0.1 | 2 | 0 | 0 | 1 | 1 | 1 | 0 |
| 58 | 56 | 31 | 131 | 95616 | 2 | 1.2 | 3 | 0 | 1 | 0 | 0 | 0 | 0 |
| 59 | 28 | 2 | 93 | 94065 | 2 | 0.2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 60 | 31 | 5 | 188 | 91320 | 2 | 4.5 | 1 | 455 | 0 | 0 | 0 | 0 | 0 |
| 61 | 49 | 24 | 39 | 90404 | 3 | 1.7 | 2 | 0 | 0 | 1 | 0 | 1 | 0 |
| 62 | 47 | 21 | 125 | 93407 | 1 | 5.7 | 1 | 112 | 0 | 1 | 0 | 0 | 0 |
| 63 | 42 | 18 | 22 | 90089 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 64 | 42 | 17 | 32 | 94523 | 4 | 0 | 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 65 | 47 | 23 | 105 | 90024 | 2 | 3.3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 66 | 59 | 35 | 131 | 91360 | 1 | 3.8 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| 67 | 62 | 36 | 105 | 95670 | 2 | 2.8 | 1 | 336 | 0 | 0 | 0 | 0 | 0 |
| 68 | 53 | 23 | 45 | 95123 | 4 | 2 | 3 | 132 | 0 | 1 | 0 | 0 | 0 |
| 69 | 47 | 21 | 60 | 93407 | 3 | 2.1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| 70 | 53 | 29 | 20 | 90045 | 4 | 0.2 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 71 | 42 | 18 | 115 | 91335 | 1 | 3.5 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 72 | 53 | 29 | 69 | 93907 | 4 | 1 | 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 73 | 44 | 20 | 130 | 92007 | 1 | 5 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 74 | 41 | 16 | 85 | 94606 | 1 | 4 | 3 | 0 | 0 | 0 | 0 | 1 | 1 |
| 75 | 28 | 3 | 135 | 94611 | 2 | 3.3 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 76 | 31 | 7 | 135 | 94901 | 4 | 3.8 | 2 | 0 | 1 | 0 | 1 | 1 | 1 |
注意:数据集中的编号(ID)和邮政编码(ZIP CODE)特征因为在分类模型中无意义,所以在数据预处理阶段将它们删除。
- 使用CART决策树对数据进行分类
- 使用留出法划分数据集,训练集:测试集为7:3。
# 使用留出法划分数据集,训练集:测试集为7:3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)- 使用CART决策树对训练集进行训练
# 使用CART决策树对训练集进行训练,深度限制为10层
model = DecisionTreeClassifier(max_depth=10)
model.fit(X_train, y_train)决策树的深度限制为10层,max_depth=10。
- 使用训练好的模型对测试集进行预测并输出预测结果和模型准确度
# 使用训练好的模型对测试集进行预测
y_pred = model.predict(X_test)# 输出预测结果和模型准确度
accuracy = accuracy_score(y_test, y_pred)
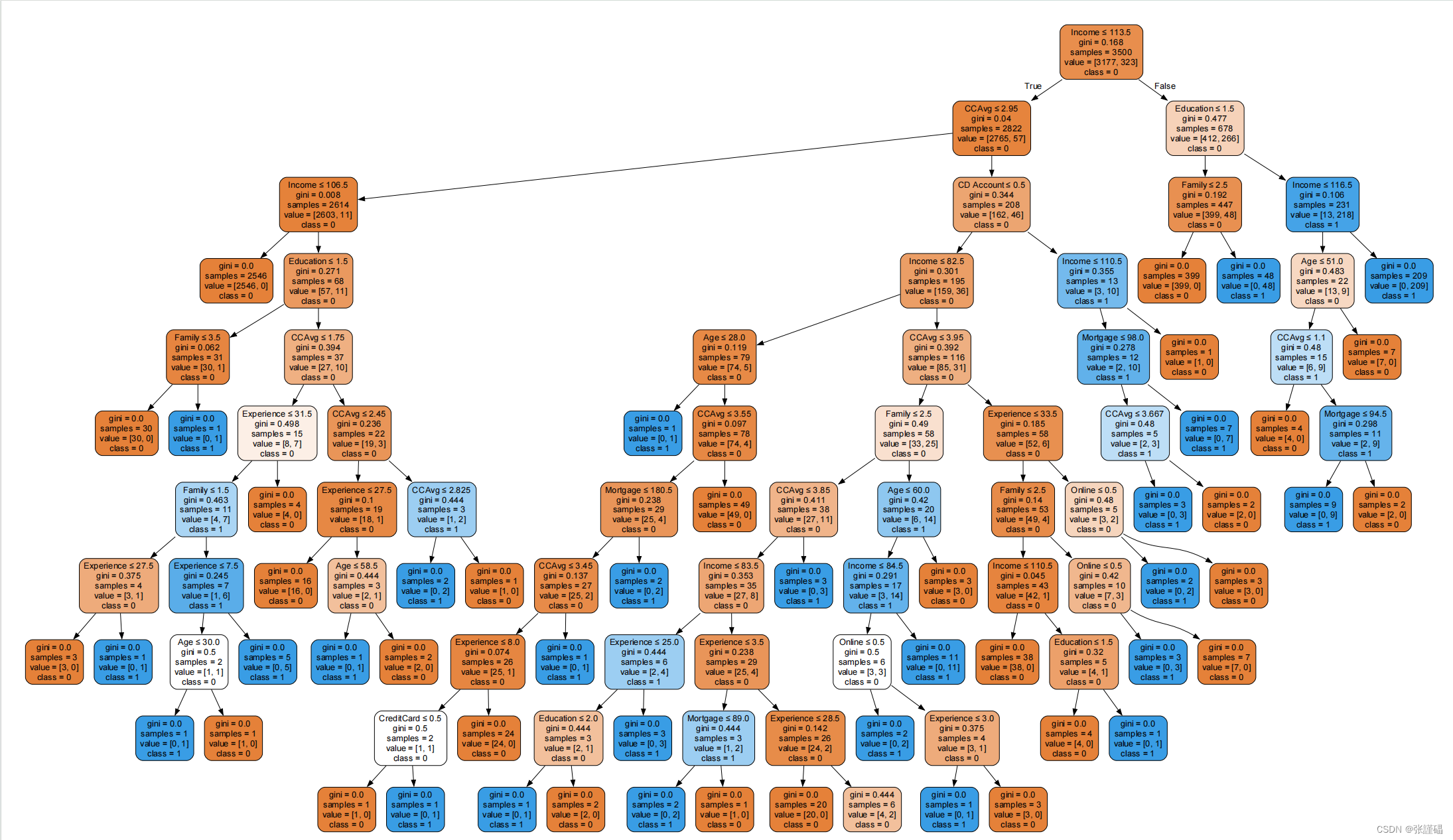
print("模型准确度:", accuracy)- 可视化训练好的CART决策树模型
# 可视化训练好的CART决策树模型
dot_data = export_graphviz(model, out_file=None,feature_names=X.columns,class_names=['0', '1'],filled=True, rounded=True,special_characters=True)
graph = graphviz.Source(dot_data)
graph.render("Universal_Bank_CART") # 保存为PDF文件
- 安装graphviz模块
首先在windows系统中安装graphviz模块
32位系统使用windows_10_cmake_Release_graphviz-install-10.0.1-win32.exe
64位系统使用windows_10_cmake_Release_graphviz-install-10.0.1-win64.exe
注意:安装时使用下图中圈出的选项
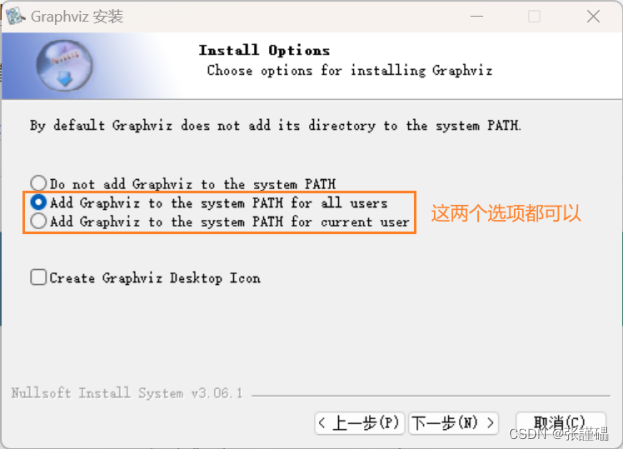
安装完成后使用pip install graphviz指令在python环境中安装graphviz库。
- 使用graphviz模块可视化模型
# 可视化训练好的CART决策树模型
dot_data = export_graphviz(model, out_file=None,feature_names=X.columns,class_names=['0', '1'],filled=True, rounded=True,special_characters=True)
graph = graphviz.Source(dot_data)
graph.render("Universal_Bank_CART") # 保存为PDF文件
完整代码:
# 导入所需的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.tree import export_graphviz
import graphviz# 读取数据集
data = pd.read_csv("universalbank.csv")# 数据预处理:删除无意义特征
data = data.drop(columns=['ID', 'ZIP Code'])# 划分特征和标签
X = data.drop(columns=['Personal Loan'])
y = data['Personal Loan']# 使用留出法划分数据集,训练集:测试集为7:3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 使用CART决策树对训练集进行训练,深度限制为10层
model = DecisionTreeClassifier(max_depth=10)
model.fit(X_train, y_train)# 使用训练好的模型对测试集进行预测
y_pred = model.predict(X_test)# 输出预测结果和模型准确度
accuracy = accuracy_score(y_test, y_pred)
print("模型准确度:", accuracy)# 可视化训练好的CART决策树模型
dot_data = export_graphviz(model, out_file=None,feature_names=X.columns,class_names=['0', '1'],filled=True, rounded=True,special_characters=True)
graph = graphviz.Source(dot_data)
graph.render("Universal_Bank_CART6") # 保存为PDF文件